







查找算法
在对数据的日常处理中,查找是一项基本操作。通常,查找算法都是基于对比的,比如在一条链表中有nn个节点,要找到其中的某个节点,最基本的思路就是从头到尾依次遍历每个节点,依次对比每个节点是否是想要的节点,这样的查找方式,称为顺序查找。
很显然,顺序查找并不会给查找效率带来任何惊喜,其时间复杂度是O(n)O(n)
提高查找效率的办法有很多,比如可以将这些数据按照二叉搜索树的逻辑结构组织起来,那么从根部开始查找某节点的时间复杂度就变成O(\log_2n)O(log2n),又或者使用顺序存储并将节点排序,那么每次查找可以从中间开始,进行折半查找,时间复杂度也是O(\log_2n)O(log2n)。
不管是顺序查找,还是改良后的BST、折半算法,查找一个节点都需要花一定的时间,之所以要花时间是因为存储节点的时候,节点的位置与节点的字段之间没有对应关系,因此我们需要一个个比对每一个节点,上述算法的差异只是改变了比对的规则,使得效率提高,但仍然是一个一个比对的过程。如果查找节点不需要比对,那就可以节省大量的时间。
哈希表
为了避免节点比对,我们可以在存储节点的时候,让节点的位置和节点本身做一个映射关系,这样一来就可以直接根据节点本身的特征值计算得到节点的位置了,注意:此时节点的位置不是“找”出来的,而是计算出来的。
这种存储数据的方式,被称为哈希表(Hash Table),也被称为散列表。时间复杂度是O(1)O(1),即查找任何一个数据理论上不需要时间,直接给出数据所在的位置。
基本概念
哈希表的思路简单易懂,将相关的概念陈述如下:
- 键(Key):即用来作为节点特征的字段。比如学生的姓名、分数、学号等。
- 值(Value):节点存储的位置,也被称为哈希地址。
- 哈希函数(Hash Function):将键转换为值的映射关系。
- 冲突(Conflict):当不同的键映射到相同的值时,称为冲突
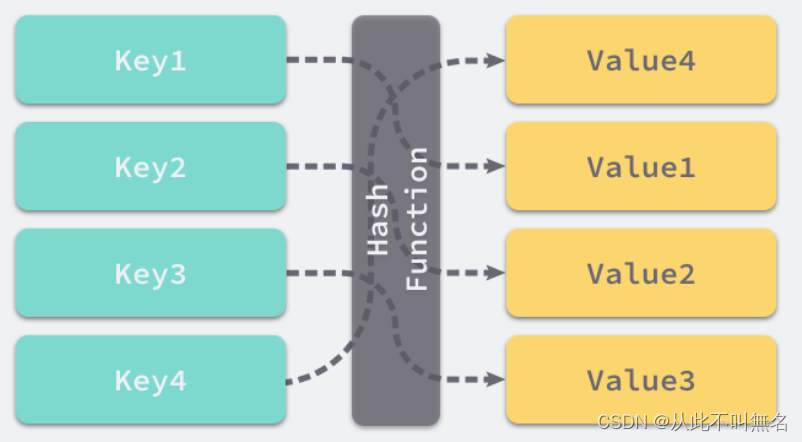
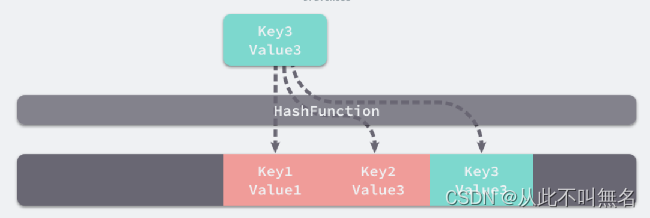
如上图所示,所谓的哈希存储就是将键映射为哈希地址,存入右侧的某个空位中。右侧实际上是一个数组,所谓的哈希地址一般指的是数组的下标,哈希表一般指的是该数组。
哈希表主要就是解决两件事情:
- 确定一个哈希函数
- 解决可能会出现的冲突问题
哈希函数
将节点某字段(即键)转换为哈希地址(值)的过程,就是哈希映射。举个例子,假设要将班级里的学生用哈希表的方式来存储,将姓名作为键,可以有如下哈希映射:
- 将姓名笔画数,作为节点的哈希地址。
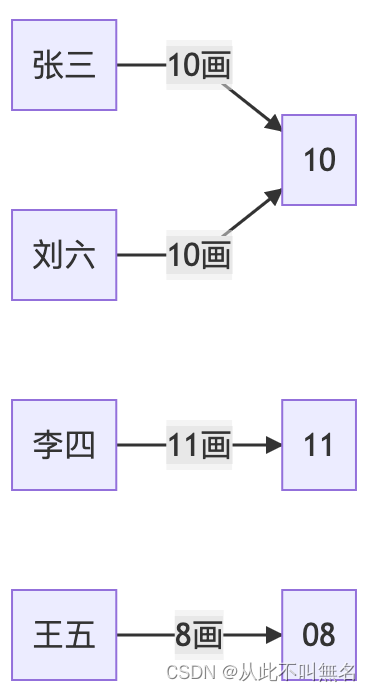
从上面的例子可以看到,以笔画数作为映射规则是很不理想的,因为大多数人的姓名笔画数都集中在10-20之间,这不利于将各个元素均匀地分布在哈希表中,并且这种算法很容易有冲突。
哈希函数的选取没有一定之规,但一个大的原则是:尽量充分地使用键的信息,尽量使得值均匀分布。符合这个大原则的其中一种哈希函数,称为除留余数法,即:将键对不大于哈希表长度的最大质数求余,将其结果作为哈希地址。
以上面学生为例,假设班级中学生人数在50人左右,将哈希表数组的长度定为50,那么哈希函数可以是:
H(key) = key%47H(key)=key%47
此处,47是不大于50的最大的质数,之所以不能大于50,是因为哈希地址最终是数组的下标,如果比数组的长度还大的话就可能会越界。选取质数则有利于值域分布更加均匀。另外,为了让数据分布更加均匀,可以使用姓名拼音的ASCII码之和来作为键。
采取这种除留余数法获得哈希地址后,映射关系变成:
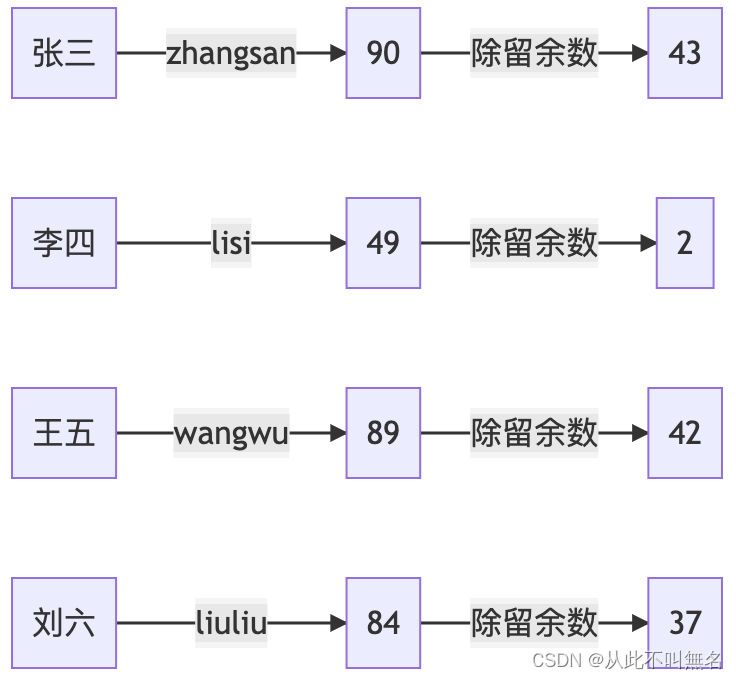
可见,经过对哈希函数的改良,使得哈希地址分布更加均匀了,冲突概率也降低了。但从另一方面讲,冲突就像物理实验中的误差,可以被降低,但很多时候无法根除,比如上述例子,假如现在入学一位名字为马化腾的学生,那么将会出现:
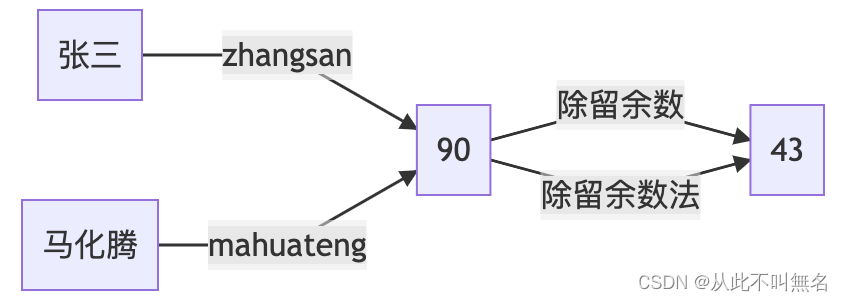
此时,马化腾跟张三虽然姓名信息毫不相干,但是计算出来的哈希地址却是冲突的。如何解决冲突?这是哈希表的第二项重要工作。
「练习」
假设有如下数据:
23,34,14,38,46,16,68,15,07,31,26
请先构建一个空的哈希表,假设哈希表的总大小为20。使用除留余数法获得这些数据的对应的哈希地址,并将这些数据妥善放入哈希表中,思考如果两个元素的哈希地址冲突了,可以怎么解决?
提示:
哈希表实际上就是一个数组,为了方便,一般使用一个管理结构体来管理所有的信息,比如:
typedef struct
{
datatype *data; // 存储某种数据的哈希表(数组)
int capacity; // 哈希表总容量
int size; // 哈希表当前元素个数
}hashTable;
解决冲突
- 开放地址法
解决冲突跟选取哈希函数一样,是可以很灵活的。最简单的想法是:既然某个哈希地址已经有别的数据了,那就换一个位置。比如将数据挪到已冲突的位置的旁边,如果旁边还是冲突那么再试试旁边,这就是所谓的开发地址法解决冲突。
这种看似简单的做法,有很多弊端:
- 必须保证哈希表的总大小要大于数据节点数目,否则如果数据填满了整张哈希表,那么除非扩充哈希存储数组,否则不管怎么调整位置,都不可能找到空余的地方。
- 多个哈希值冲突的数据节点会在冲突点附近形成“堆积”,每个形成冲突的节点都要将前面冲突所走过的路线再走一遍。
- 由于节点所处的真实位置与其从哈希函数计算出来的理论位置可能不一致(被冲突就不一致了),这就导致一个位置的状态不是两种,而必须是三种:有节点、无节点、之前有现在无节点。
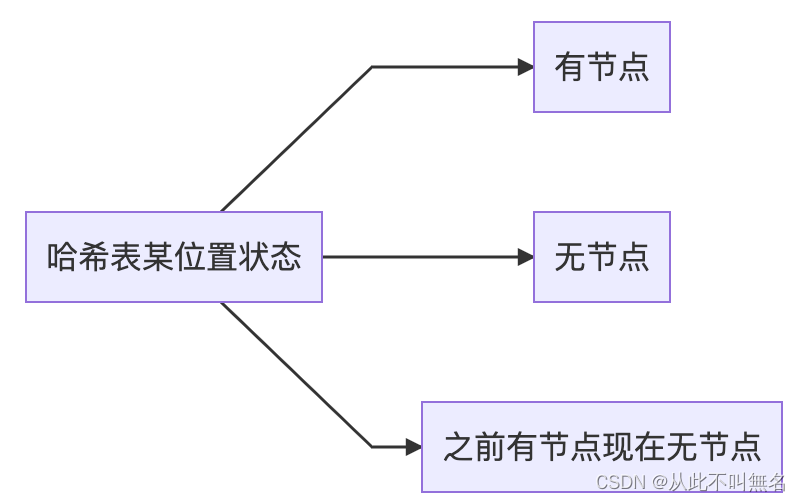
关于上述第3个弊端再解释一下,假设:
张三入学时,根据哈希函数计算被安排到了43号桌,然后马化腾入学时计算出来的哈希地址也是43号,于是小马同学只能乖乖地坐在小张的旁边,44号桌。然后,小张退学了。
然后,我们要查找小马同学,根据哈希函数,计算出来的哈希地址是43,此时43号桌的状态如果是“没人”的话,那么就会误判以为班级里面没有小马这位同学,于是产生了错误。
解决这个谬误的办法,要将这样的43号做标记为“之前有人但现在无人”的状态,这样才能顺着解决冲突的办法挨个找去,最终才能找到小马同学。
- 链地址法
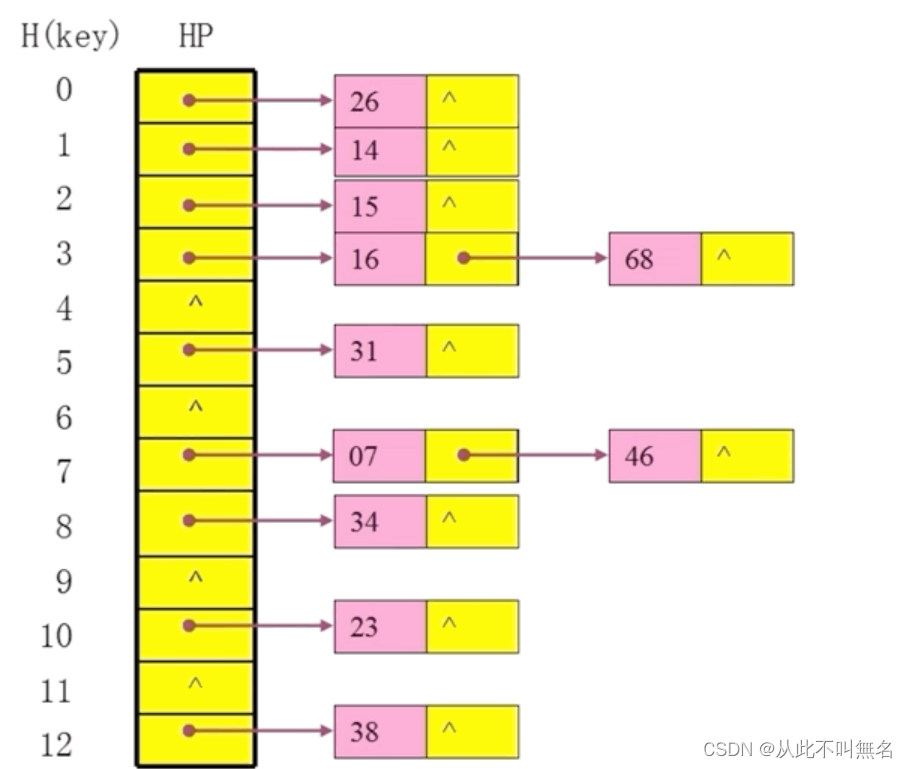
为了解决开放地址法的弊端,可以在冲突点处设置一条链表,让所有哈希地址冲突的节点链起来,这样就既无需担心节点数量超过哈希表大小,也无需设置节点的第三种状态。
假设有如下数据节点:
23,34,14,38,46,16,68,15,07,31,26
假设按照如下除留余数法得到它们的哈希地址:
H(key) = key%13H(key)=key%13
那么它们在存储进入哈希表的过程如下图所示:
「小题目6」
假设有如下数据:
23,34,14,38,46,16,68,15,07,31,26
请先构建一个空的哈希表,假设哈希表的总大小为20。使用除留余数法获得这些数据的对应的哈希地址,并使用链地址法解决冲突。造表完成后,通过用户输入来查表。
总结
哈希表是一种为了提高查找效率的数据存储方式,其核心思想就是将节点的存储位置与节点本身对应起来,让我们在查找数据时无需通过比对就能直接计算得到它的位置。
要想使用哈希值来查找数据,就必须先造表,造表的过程主要解决以下两个问题:
- 哈希函数
- 解决冲突
造表完成后,按照完全一样的哈希函数和解决冲突的办法,就可以查表,这种方式下查找的效率平均是O(1)O(1),也就是常数级,即查找所需时间与节点个数无关。
哈希表适用场景:
- 节点的个数相对稳定
- 对查找效率极度敏感
哈希表代码实现:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
// 函数指针,将key转为hash数组的下标
typedef int (*hash_func_t)(int,void *);
// hash节点类型
typedef struct hash_node
{
void *key; // 通过key可以快速找到value
void *value;
struct hash_node *pre;
struct hash_node *next;
}hash_node_t;
// 哈希表管理结构体
typedef struct hash
{
int buckets; // 数组大小
hash_node_t **nodes; // 哈希数组的首地址
hash_func_t hash_func; // 哈希函数指针,将key转为哈希数组下标
}hash_t;
// 将key转为哈希数组下标
int hash_func_int(int buckets, void *key)
{
return (*(int *)key) % buckets;
}
// "abc" (97+98+99) % buckets
int hash_func_str(int buckets, void *key)
{
char *temp = (char *)key;
int sum = 0;
while ((*temp) != '\0')
{
sum+=*temp;
temp++;
}
return sum % buckets;
}
// 初始化哈希表
hash_t *init_hash(int buckets, hash_func_t hash_func)
{
hash_t *hash = malloc(sizeof(hash_t));
if(hash == NULL)
return NULL;
hash->buckets = buckets;
hash->hash_func = hash_func;
hash->nodes = calloc(buckets, sizeof(hash_node_t *));
if(hash->nodes == NULL)
return NULL;
return hash;
}
hash_node_t *init_node(void *key, int keySize, void *value, int valueSize)
{
// 创建节点
hash_node_t *node = malloc(sizeof(hash_node_t));
if(node == NULL)
return false;
node->next = NULL;
node->pre = NULL;
node->key = malloc(keySize);
node->value = malloc(valueSize);
if(node->key == NULL || node->value == NULL)
return false;
memcpy(node->key,key,keySize);
memcpy(node->value,value,valueSize);
return node;
}
// 获取哈希数组下标
hash_node_t **hash_get_bucket(hash_t *hash, void *key)
{
// 获取数组下标是右用户选择key的类型决定
// 回调产生数组下标的方法
int bucket = hash->hash_func(hash->buckets,key);
return &hash->nodes[bucket];
}
// 添加数据
bool hash_add_data(hash_t *hash, void *key, int keySize,void *value, int valueSize)
{
// 创建新节点
hash_node_t *pnew = init_node(key,keySize,value,valueSize);
if(pnew == NULL)
{
return false;
}
// 找数组下标node地址插入
hash_node_t **bucket = hash_get_bucket(hash,key);
if(*bucket == NULL) // 数组对应的下标空间没有节点,直接插入,从无到有
{
*bucket = pnew;
}
else // 从少到多,头插,节约插入时间
{
pnew->next = *bucket;
(*bucket)->pre = pnew;
(*bucket) = pnew;
}
return true;
}
// 输出int
void print_int(hash_t *hash)
{
hash_node_t **nodes = hash->nodes;
int count = 0;
// 查找数组下标是否为空,不为空表示有节点
for(int i = 0; i < hash->buckets; i++)
{
if(nodes[i] == NULL) // 对应数组的下标位置没有节点
{
count++;
//printf("%d\n",__LINE__);
continue;
}
while (nodes[i] != NULL)
{
printf("key : %d value : %d\n", *(int *)nodes[i]->key, *(int *)nodes[i]->value);
nodes[i] = nodes[i]->next;
}
}
printf("empty bucket : %d\n",count);
}
// 输出str
void print_str(hash_t *hash)
{
hash_node_t **nodes = hash->nodes;
int count = 0;
// 查找数组下标是否为空,不为空表示有节点
for(int i = 0; i < hash->buckets; i++)
{
if(nodes[i] == NULL) // 对应数组的下标位置没有节点
{
count++;
//printf("%d\n",__LINE__);
continue;
}
while (nodes[i] != NULL)
{
printf("key : %s value : %d\n", (char *)nodes[i]->key, *(int *)nodes[i]->value);
nodes[i] = nodes[i]->next;
}
}
printf("empty bucket : %d\n",count);
}
// 释放哈希节点
void hash_freeNode(hash_t *hash, void *key, int keySize)
{
// 查找数组下标
hash_node_t **bucket = hash_get_bucket(hash,key);
hash_node_t *node = *bucket;
if(node == NULL)
{
printf("node NULL\n");
return;
}
// 查找数组位置对应的链表的节点
while(node != NULL && memcmp(node->key,key,keySize) != 0)
{
node = node->next;
}
//printf("node : %d\n",node->value);
free(node->key);
free(node->value);
// 判断删除的节点是否头节点
if(node->pre)
{
node->pre->next = node->next;
}
else
{
hash_node_t **bucket = hash_get_bucket(hash,key);
*bucket = node->next;
}
// 从链表中剔除node
if(node->next != NULL)
{
node->pre->next = node->next;
}
free(node);
}
int main(int argc, char const *argv[])
{
// 初始化哈希表
hash_t *hash = init_hash(3,hash_func_int);
//hash_t *hash = init_hash(3,hash_func_str);
if(hash == NULL)
{
printf("init hash failed:\n");
return -1;
}
int key1 = 1;
// 输入中文的时候要注意编码格式,不能乱码,linux平台就是utf-8
//char key1[] = "烤鸡";
int value1 = 100;
//char key2[] = "坑德基";
int key2 = 2;
int value2 = 200;
//char key3[] = "烤鸭";
int key3= 3;
int value3 = 300;
hash_add_data(hash,&key1,sizeof(key1),&value1,sizeof(value1));
hash_add_data(hash,&key2,sizeof(key2),&value2,sizeof(value2));
hash_add_data(hash,&key3,sizeof(key3),&value3,sizeof(value3));
// 输出
//print_int(hash);
//print_str(hash);
// 剔除节点
hash_freeNode(hash,&key1,sizeof(key1));
hash_freeNode(hash,&key2,sizeof(key2));
//hash_freeNode(hash,&key3,sizeof(key3));
print_int(hash);
//print_str(hash);
return 0;
}















 40万+
40万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









