







文章目录
Transformer结构
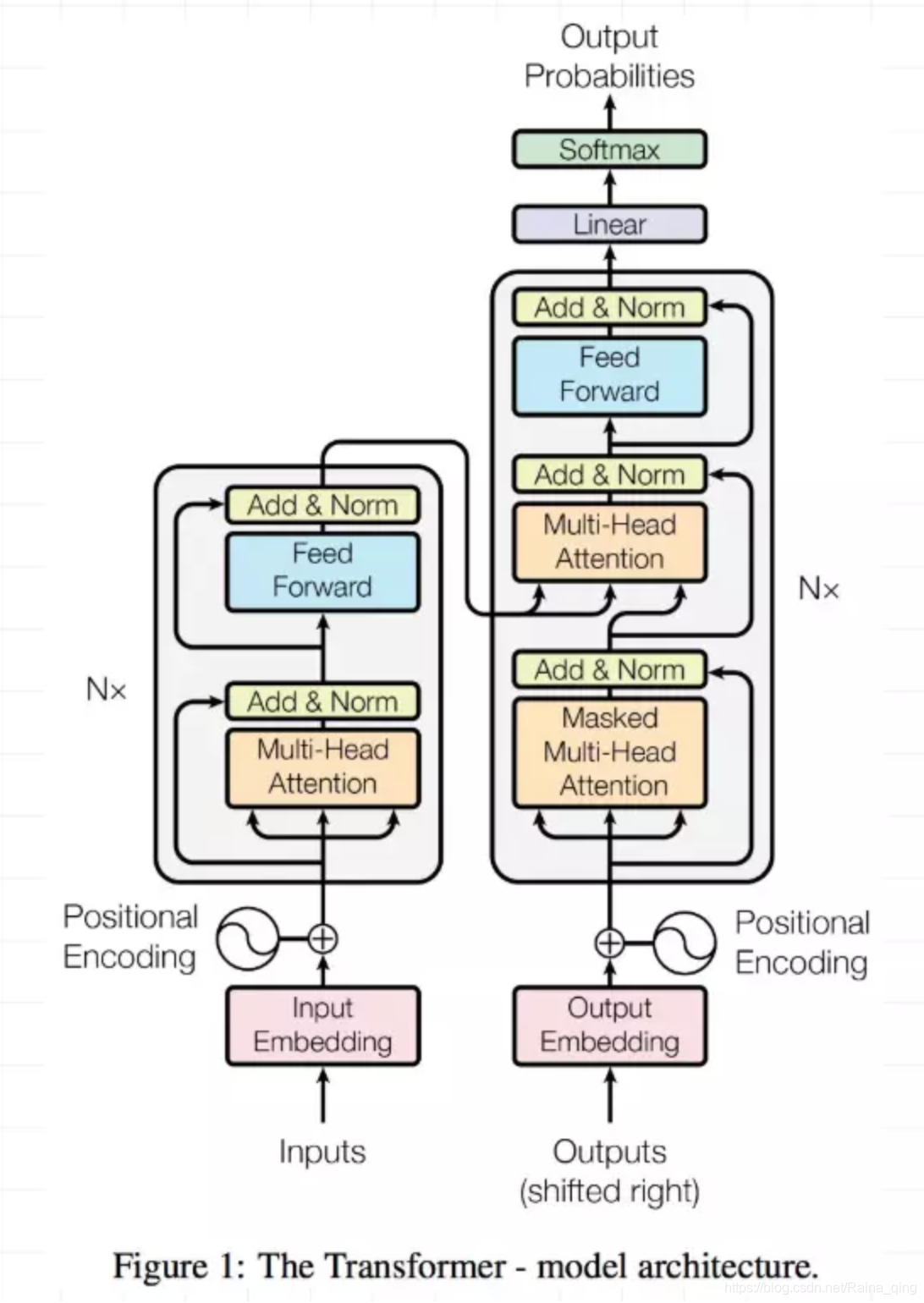
与Bert论文相关,Bert中也插入了相关连接。
0. RNN的缺点
RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
1. 整体结构域
论文中的验证Transformer的实验是基于机器翻译的,下面我们就以机器翻译为例子详细剖析Transformer的结构,在机器翻译中,Transformer可概括为如图:

Transformer的本质上是一个Encoder-Decoder的结构,那么上可以表示为下图的结构:
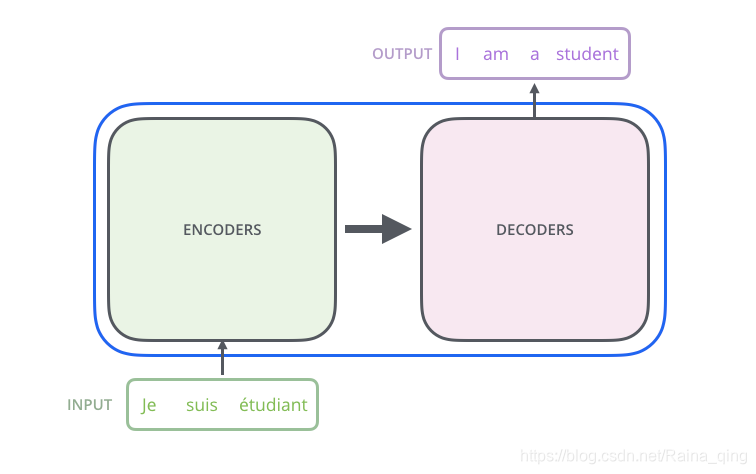
Transformer 整体结构宏观上看是一个Encoder-Decoder结构,其中Encoder和Decoder各有6层。
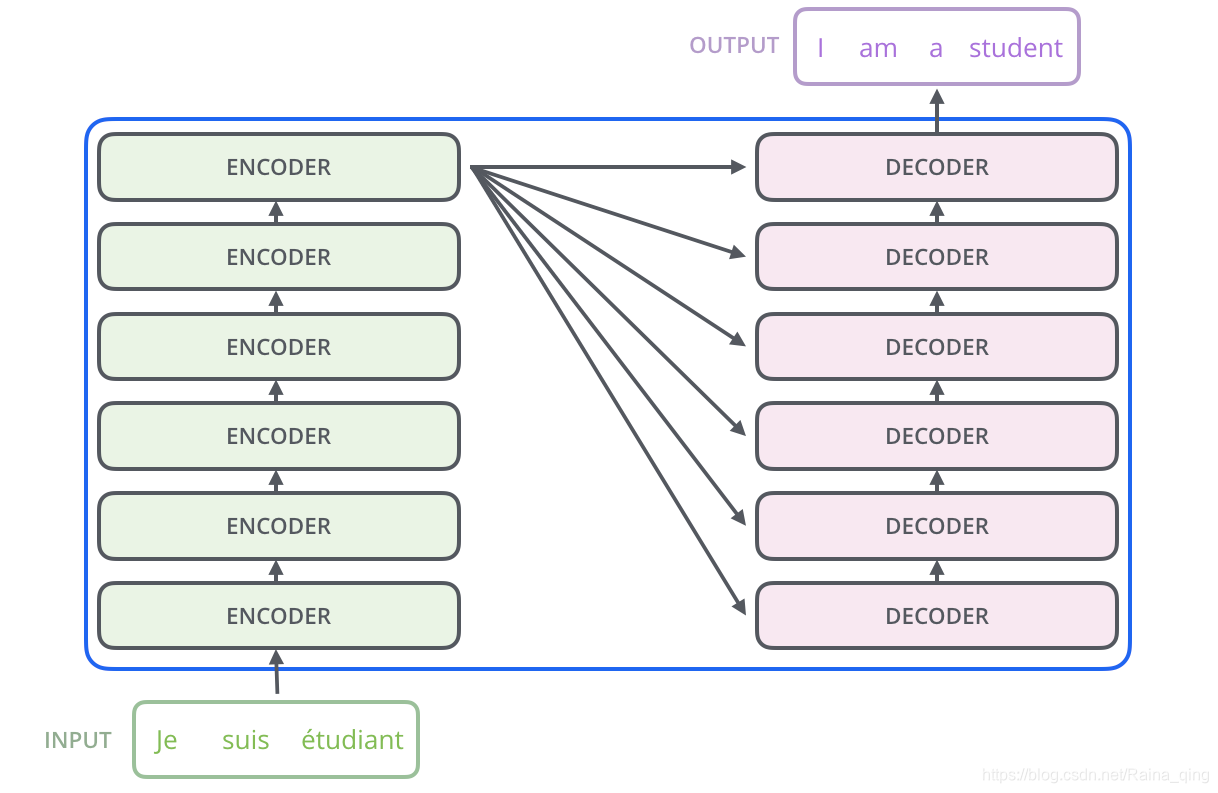
2. Encoder部分
对于Encoder部分来说,整个的Encoder结构里包含6层,每一层里面有两层。分别是一层self-attention层和一层全连接层。
2.1. multi-head-Attention层
需要注意的是,这里的self-attention并不是只有一层。模型中使用的是multi-head-Attention。其实就是多个self-attention,可以把每个self-attention理解为一个head,多个self-attention自然就是多头了。在上一篇文章中我们已经提到了self-attention的计算,经过计算,一个self-attention会输出一个结果z。
A t t e n s i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attension(Q,K,V)=softmax(\frac{QK^T}{\sqrt {d_k}})V Attension(Q,K,V)=softmax(dkQKT)V
这一段暂时将其叫做 Z Z Z,那么,multi-head-attention的输出是什么呢? 答案是把每一个self-attention的输出结果拼接起来。然后输入给后面的全连接网络。
2.1.1 插入讲解self-attention
首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为 d m o d e l = 512 d_{model}=512 dmodel
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8328
8328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









