







Abstract & Introduction & Related Work
- 研究任务
unsupervised continual learning (UCL) - 已有方法和相关工作
- 面临挑战
现有的方法都限于监督学习,限制了在现实世界中的使用 - 创新思路
- 我们提出了Lifelong Unsupervised Mixup(LUMP),这是一种简单而有效的技术,在当前任务和以前任务的实例之间进行插值,以减轻无监督表征的灾难性遗忘
- 我们试图弥合持续学习和表征学习之间的差距,并解决无标签数据的持续学习和一连串任务的表征学习这两个关键问题
- 实验结论
- 表明对注释数据的依赖并不是持续学习的必要条件
- 超越了有监督持续学习的sota
- 我们提供了表征和损失景观的可视化,这表明UCL学习了具有辨别力的人类知觉模式,并实现了更平坦和更平滑的loss landscape

PRELIMINARIES
PROBLEM SETUP
有监督,交叉熵

LEARNING PROTOCOL AND EVALUATION METRICS
当前传统的持续学习策略是用标准的训练方案,学习一系列任务的网络表示
而我们的模板是学习特征表示,分为两个步骤
- 在一系列任务上预训练得到表示
- 用KNN来衡量预训练表示的质量

用两种metrics- 平均准确率
- 平均遗忘

UNSUPERVISED CONTINUAL LEARNING
CONTINUOUS REPRESENTATION LEARNING WITH SEQUENTIAL TASKS
对比学习可以将相似的样本的表示的相似度最大化,而将不同样本的表示的相似度最小化,然而这些方法需要大批量,负样本对,或者结构上的修改,或者非微分运算符,让其难以应用到持续学习的场景
我们focus on SimSiam 和 BarlowTwins
SimSiam

BarlowTwins

PRESERVING REPRESENTATIONAL CONTINUITY: A VIEW OF EXISTING SCL METHODS

LIFELONG UNSUPERVISED MIXUP
标准Mixup训练基于邻域风险最小化构造的虚拟样本
最小化插值样本项
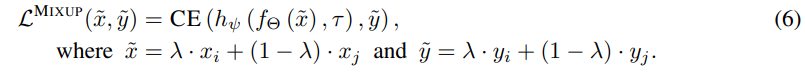
通过将先前任务中存储在重放缓冲区的实例纳入临近分布,利用Mixup来进行无监督的持续学习
LUMP在当前任务 ( x i , τ ) ∈ U τ (x_i,τ)∈U_τ (xi,τ)∈Uτ的例子和从 replay 缓冲器中使用均匀抽样选择的随机样本之间进行插值,鼓励模型在一连串的任务中表现为线性
LUMP在当前任务的插值实例上优化优化等式2和3
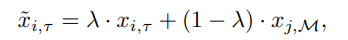
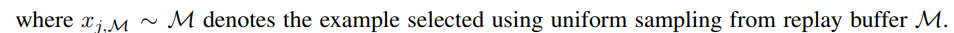
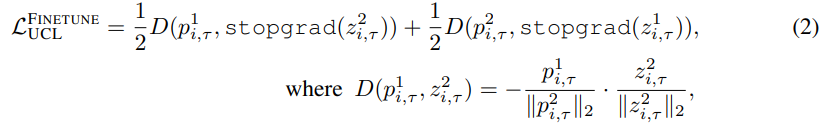
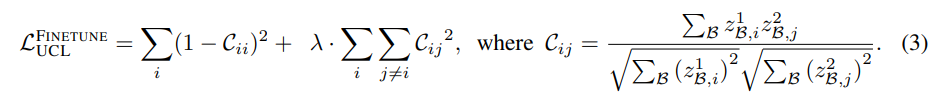
插值的例子不仅增强了重放缓冲区中过去的任务实例,而且还接近于正则化的损失最小化(Zhang等人,2021)。在UCL期间,LUMP通过重访与当前任务相似的过去任务的属性,增强了学习到的表征的鲁棒性。为此,LUMP相继缓解了灾难性遗忘,并学习了辨别性&人类感知特征,与目前最先进的SCL策略相比,性能有了显著提高(见表1和图4)。此外,与现有的基于演练的方法不同,它不需要调整额外的超参数
EXPERIMENTS





DISCUSSION AND CONCLUSION
这项工作试图弥补无监督表示学习和持续学习之间的差距。特别是,我们为无监督的持续学习建立了以下发现:
超越有监督的持续学习。我们对各种持续学习策略和数据集的实证评估表明,UCL表征比SCL表征对灾难性遗忘更强大。此外,我们注意到,UCL对OOD任务的概括性更好,并且
在少量的学习任务中取得了更强的性能。我们提出了Lifelong unsupervised mixup (LUMP),它在当前任务和过去任务之间插补了无监督的实例,并在广泛的任务中获得了更高的性能和更低的灾难性遗忘。
剖析学习到的表征。我们进行了系统的分析,以了解UCL和SCL策略学到的表征之间的差异。通过调查表征之间的相似性,我们观察到UCL和SCL策略在低层有很高的相似性,但在高层是不一样的。我们还表明,与SCL相比,UCL表征能学习到连贯的、有鉴别力的模式和更平滑的损失景观。
限制和未来的工作。在这项工作中,我们没有考虑CL的高分辨率任务。我们打算在未来的工作中评估在ImageNet上学习的表征的遗忘情况(Deng等人,2009),因为UCL显示出较低的灾难性遗忘,并且在过去的几年中,表征学习在ImageNet上取得了重大进展。在后续工作中,我们打算进行进一步的分析,以了解UCL的行为,并开发复杂的方法,在不同的设置下持续学习无监督的表征,如类增量或任务诊断的CL
Remark
利用对比学习达到了无监督超过有监督的效果,我觉得可能主要是SimSiam的功劳?内容比较侧重对比学习,在持续学习上…不知道咋说,总之ICLR的paper的数学要求我还需要努努力orz















 1744
1744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









