









Abstract & Introduction & Related Work
- 研究任务
- NER同一建模模型(flat,nested,discontinuous)
- 已有方法和相关工作
- 序列标注
- 基于超图的方法
- seq2seq方法
- 基于span的方法
- 现有方法focus如何准确识别实体边界
- 面临挑战
- 在推理过程中同时存在假结构和结构模糊的问题
- 解码效率
- 曝光偏差
- 基于span的方法受限于最大span长度,模型复杂度
- 创新思路
- 提出了一种基于word-word关系分类的统一NER建模模型,称之为 W 2 N E R W^2NER W2NER
- 该架构通过对实体词之间的相邻关系进行有效建模,用Next-Neighboring-Word(NNW)和Tail-Head-Word-(THW-)关系来解决统一NER的内核瓶颈问题
- 实验结论
- 在14个数据集上sota
嵌套NER和不连续NER的示意图,比flat更加的复杂

W
2
N
E
R
W^2NER
W2NER 模型总览图,可以看到整个模型是比较复杂的
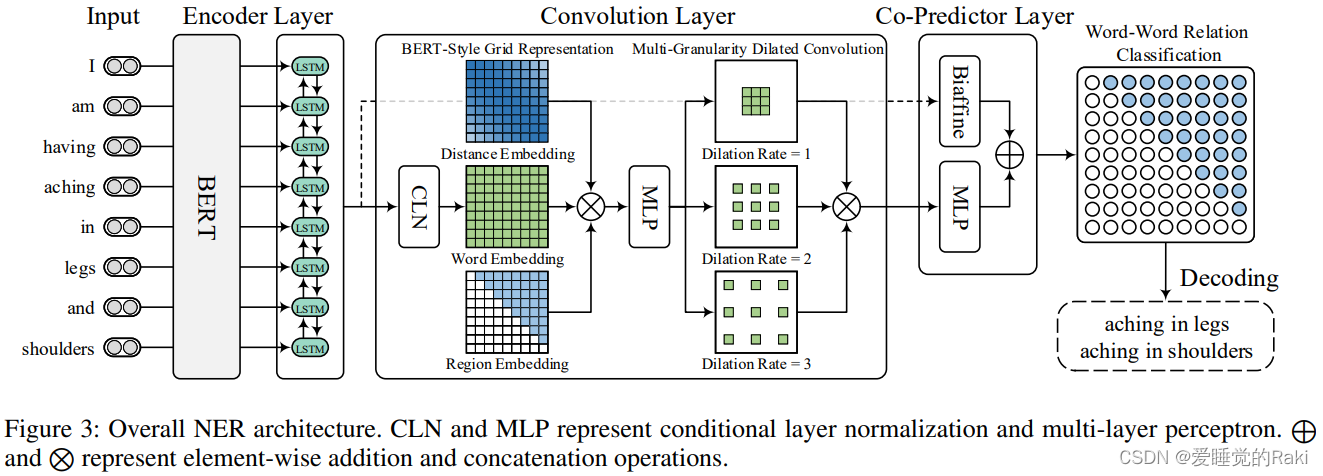
NER as Word-Word Relation Classification
在所有token对中,存在以下三种关系

word-word矩阵,表示token对之间的关系,非对称,表示第行个token和第列个token之间的关系

Unified NER Framework
- Encoder:用BERT和LSTM来从输入句子中得到上下文词表示
- 卷积层:用来建立和精炼词对矩阵,用于后续的word-word关系分类
- 最后一个双线性层和多层感知机共同用于推理token对的关系
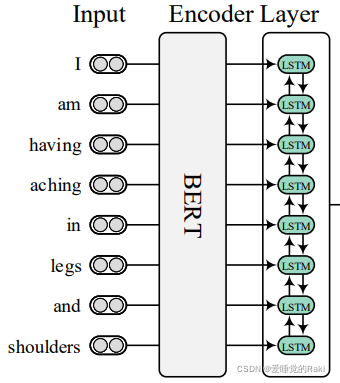
Encoder Layer
BERT得到word embedding之后送入LSTM得到上下文表示,没什么好说的
Convolution Layer
CNN层有三个不同的模组
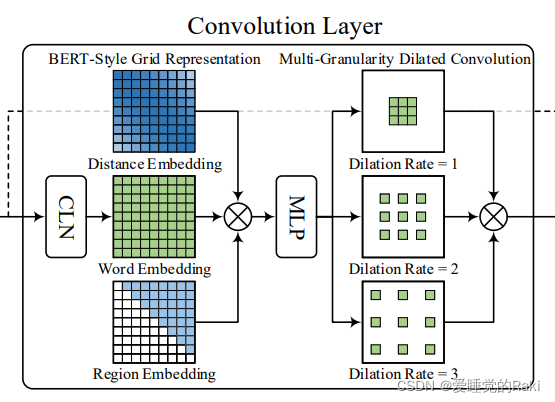
Conditional Layer Normalization
V i j \mathbf{V}_{ij} Vij 表示词对之间的的表示,使用条件层归一化来计算
γ
\gamma
γ 和
λ
\lambda
λ 通过对隐状态投影得到

BERT-Style Grid Representation Build-Up
V
\mathbf{V}
V 代表词信息
E
d
\mathbf{E}^d
Ed 代表token对的相对位置信息
E
t
\mathbf{E}^t
Et 代表代表区域信息,用于区分矩阵中的下三角和上三角区域
最后拼接起来经过一个线性层
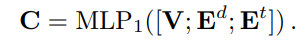
Multi-Granularity Dilated Convolution
对
C
\mathbf{C}
C 使用三个空洞卷积,并拼接起来得到
Q
\mathbf{Q}
Q

Co-Predictor Layer
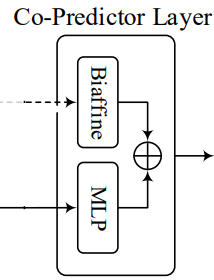
Biaffine Predictor
利用了之前LSTM得到的上下文表示
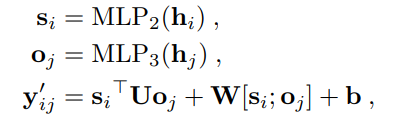
MLP Predictor
把Q投影,再跟双线性层的输出一起输入softmax层进行得到每一类的概率

Decoding
我们模型的预测是单词和它们之间的关系,这可以被视为一个方向性的单词图。解码的目的是利用NNW关系找到图中从一个词到另一个词的某些路径。每条路径都对应于一个实体提及。除了用于NER的类型和边界识别,THW关系也可以作为消歧义的辅助信息。图4说明了四种从易到难的解码情况

- (a)中,两条路径 "A→B "和 "D→E "对应于平面实体,THW关系表示它们的边界和类型
- (b)中,如果没有THW关系,我们只能找到一条路径,因此 "BC "就不见了。相反,在THW关系的帮助下,我们很容易发现 "BC "被嵌套在 "ABC "中,这表明了THW关系的必要性
- (c)显示了如何识别不连续的实体。可以找到两条路径 "A→B→C "和 “A→B→D”,而NNW关系有助于连接不连续的跨度 "AB "和 “D”
- 考虑到一个复杂而罕见的情况(d),不可能解码出正确的实体 "ACD "和 “BCE”,因为在这个模糊的情况下,我们只用NNW关系就能找到4条路径。相反,只使用THW关系会识别出连续实体(如 “ABCD”),而不是正确的不连续实体(如 “ACD”)。因此,我们可以通过协作使用两种关系来获得正确的答案
Learning
优化以下损失函数

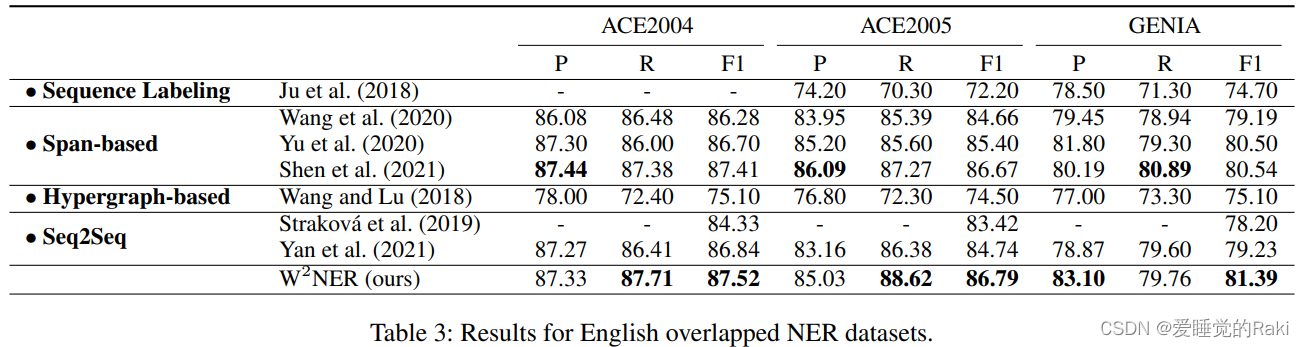
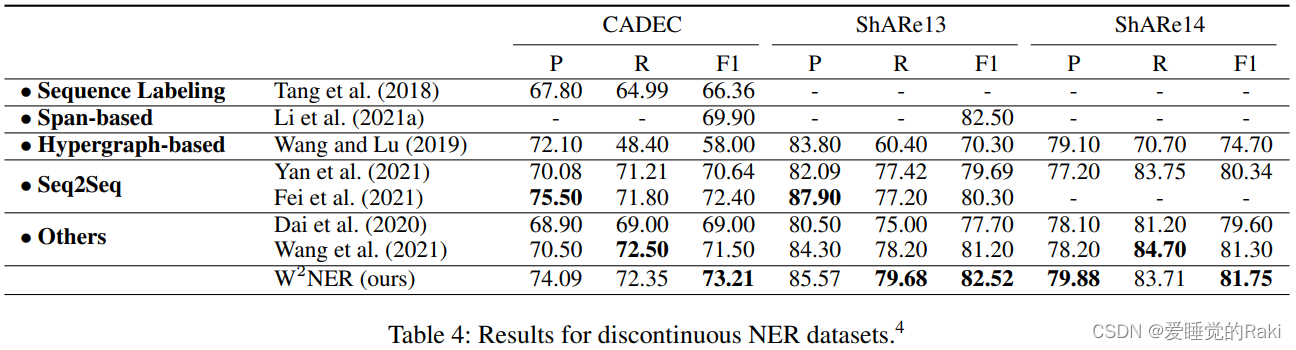
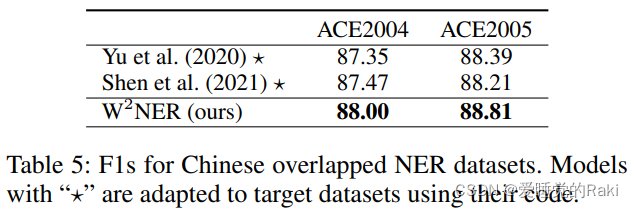
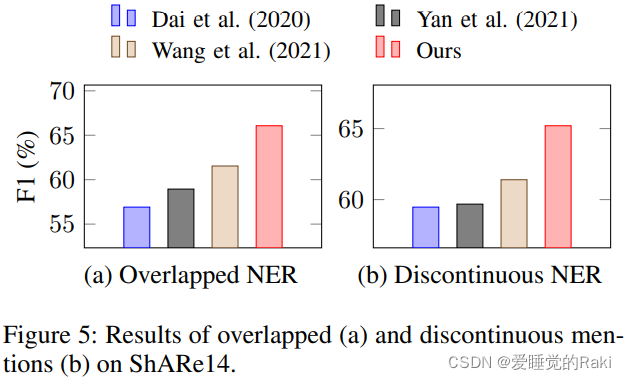
Experimental Results
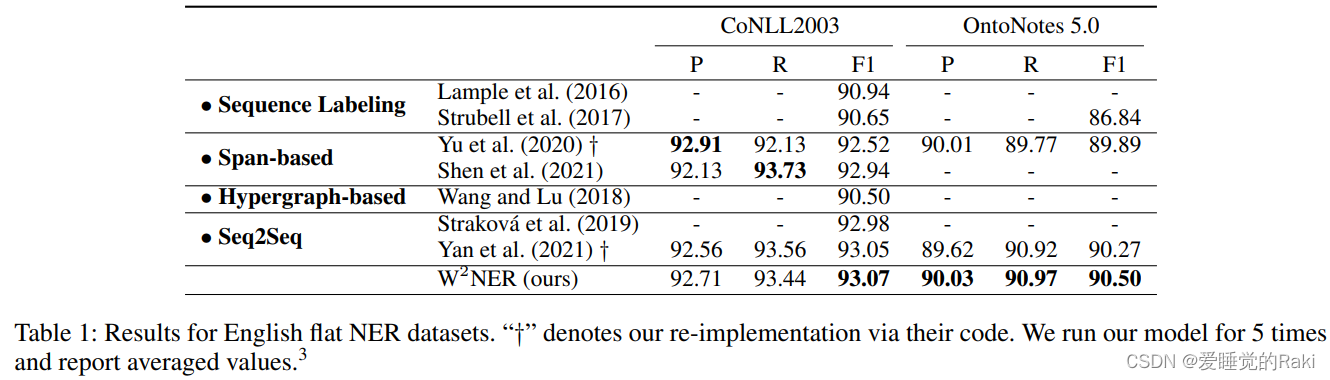
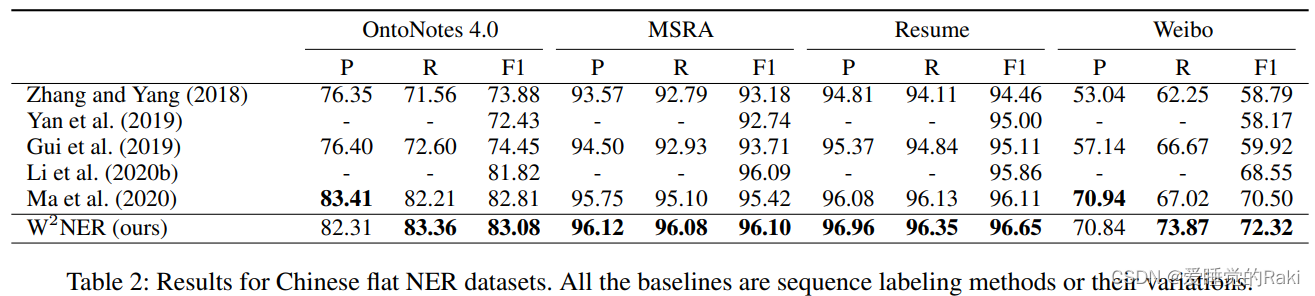
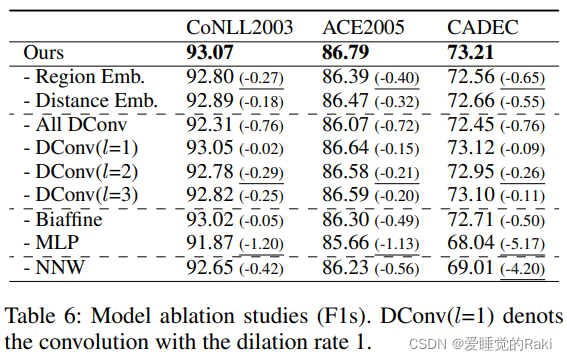
Conclusion
在本文中,我们提出了一个新的基于词-词关系分类的统一NER框架,以解决统一NER的并发问题。词对之间的关系被预先定义为下一个邻接词关系和尾部词头关系。我们发现,我们的框架对各种NER相当有效,在14个广泛使用的基准数据集上达到了SoTA的性能。此外,我们提出了一个新的骨干模型,包括一个BERT-BiLSTM编码器层,一个用于建立和完善词对网格表示的卷积层,以及一个用于联合推理关系的协同预测层。通过消融研究,我们发现我们的以卷积为中心的模型表现良好,几个提议的模块,如联合预测器和网格表示丰富化也很有效。我们的框架和模型易于操作,这将促进NER研究的发展
Remark
虽然模型有一点点复杂,组件比较多,但是效果牛逼,那只能说 好!














 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









