






笔者关注了一篇基于多视角图像的3D目标检测工作——StreamPETR(这篇工作我感觉非常的优秀以及作者非常愿意帮助小白比如我)。之前在基于训练集上训练时,在按照配置都没有问题,但是希望将训练集和测试集融合起来用于提高在nuScenes榜单上test的性能,于是将测试集val也包含进来当作训练的一部分。
但是,连续几次训练都会因为超时而中断,具体报错信息参考如下:
[E ProcessGroupNCCL.cpp:566] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1808453 mill
iseconds before timing out.
[E ProcessGroupNCCL.cpp:566] [Rank 2] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1808498 mill
iseconds before timing out.
[E ProcessGroupNCCL.cpp:566] [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1808594 mill
iseconds before timing out.
[E ProcessGroupNCCL.cpp:325] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations mi
ght run on corrupted/incomplete data. To avoid this inconsistency, we are taking the entire process down.
terminate called after throwing an instance of 'std::runtime_error'
what(): [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1808453 milliseconds before ti
ming out.最终Traceback 还指向了分布式的一处:
File "/StreamPETR-main/mmdetection-2.28.2/mmdet/core/utils/dist_utils.py", line 73, in reduce_mean
dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
File "/home/student/.conda/envs/streampetr/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 1206, in all_reduce
work = default_pg.allreduce([tensor], opts)
RuntimeError: NCCL communicator was aborted on rank 3.于是我去找关于分布式的错误,发现了很多探讨。
例如和我这个问题最相似的是:

我尝试了 NCCL_P2P_LEVEL=NVL 以及NCCL_P2P_DISABLE=1之后并没有用,我一直以为是NCCL通信问题,pytorch分布式DDP卡死,最终也没能解决问题。
之后,求助了作者,作者表明或许是因为val中的场景存在empty groud truth 问题,也就是当当前sample无法获得gt时,导致陷入死循环。(非常感谢作者的建议!)
通过debug,我们发现在runner中,会通过索引提取数据集中相应的信息,在nuscenes_dataset.py文件中sample数据:
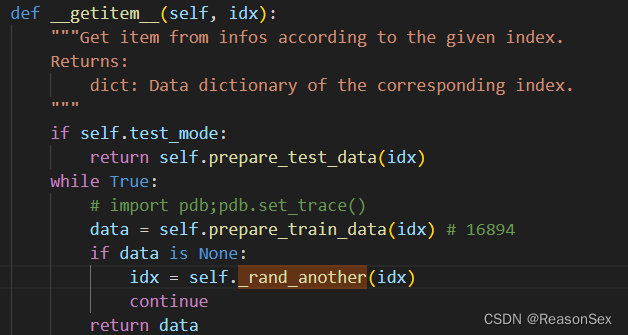
如果得到的data非空就返回到train_step并进一步送入检测器,如果是None,则会通过self._rand_another进行重新采样。

而在_rand_another实现的是,还是在当前场景idx下进行选取,但是当前场景(20 帧)中可能仍然没有真实框,导致无法跳出while,也就陷入了死循环。
实际上,我们可以通过在限定场景下的重新取值换成在整个数据集下重新随机取值,也就是修改后的结果。
最终,笔者仅是将val set丢进去训练发现解决了这个问题,而未修改前还是会卡死。
实际上这并不是NCCL的锅,只是它将超时也就是陷入死循环这个问题raising出来。
感谢StreamPETR作者,解决了一个我一开始就找错方向的问题。















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









