






一、现阶段其他方法存在的问题
1、一些基于区域建议的方法很依赖生成的建议框的质量,但是生成高质量的建议框又不是容易的。
2、在一些元学习方法中,聚合查询特征和支持特征时,只能独立地聚合一类,这忽视了不同类别间的相关性,限制了相似类别之间的辨别能力,以及有相关联类别之间的泛化能力。
二、提出的解决办法
1、提出了图像级预测的Meta-DETR,不再需要生成建议框,使用基于Transformer的方法,对新类有更好的泛化性能
2、设计一种新的用于元学习的相关性策略,可以同时处理多个支持集种类,可以探索类间的相关性减少错误分类以及泛化能力。 否则对于每一张支持集都要重复C次,每一类都单独检测时,容易因为过于相似而产生误检,但是将他们信息融合起来,就可以提高检测的正确性。
三、相关工作
1、通用目标检测:Faster R-CNN,DETR
2、少样本目标检测:
迁移学习:LSTD(AAAI2018)、TFA(ICML2020)、MPSR(ECCV2020)、FSCE(CVPR2021)。迁移学习的思路主要是通过微调进行学习。
元学习:众多方法,主要通过不同情景下的任务去学习变化多样的任务之间的通用知识,去学习如何学习。
Meta-DETR是一种将元学习和DETR进行融合的方法
四、方法
1、整体框架
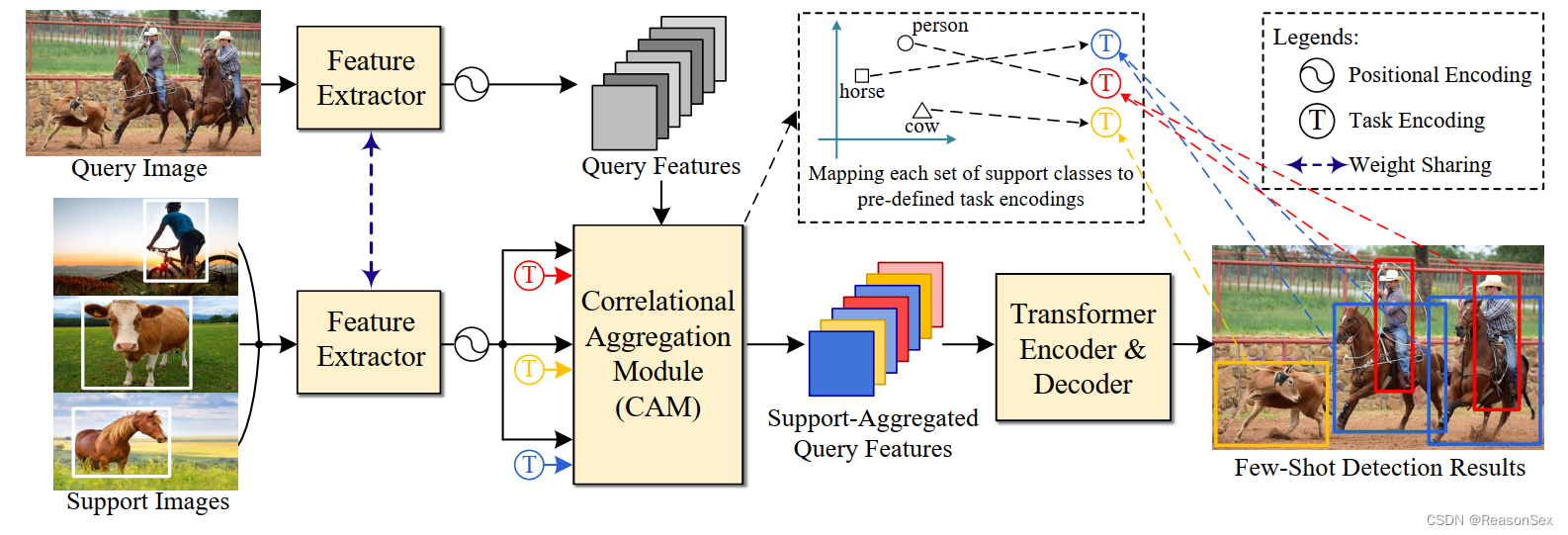
整体框架,可以看出主要贡献是两处。一个是将FSOD和Transformer结合,实现端到端的检测,并且这个主干网络是Deformer DETR。此外,引入了CAM模块,利用类间的相关性,减少误检误分类,提高性能。
2、CAM
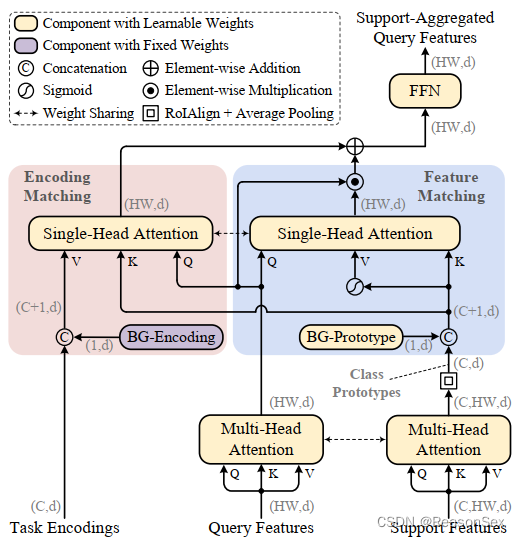
(1)、首先支持特征和查询特征都通过权重共享的多头注意力模块,把他们编码到相同的嵌入空间,然后通过ROI align得到每个支持特征的原型特征,然后对支持特征进行平均池化,其中ROI align保证从包含相应支持物体的相关区域得到类原型特征。
(2)、然后,CAM执行特征匹配以及编码匹配,分别是用于查询特征和由支持集生成的类原型特征和任务编码。
(3)、最后将匹配结果加起来传入FFN产生最终输出。
特征匹配:目的是过滤掉与支持类无关的特征。
其中,C是类别维度,d是特征的维度,W是线性映射层,保证将查询特征和原型特征映射到同一空间.
特征匹配的输出为Q_F
其中结合结构图可以看出,就是Single-Head-Attention的输入V,A是Single-Head-Attention的输出,再与Q逐像素相乘得到特征匹配的输出
作用:σ(S)作为每个支持类的特征过滤器,只从查询特征中提取与类相关的特征。通过将匹配系数A应用到σ(S),有了过滤器,可以过滤掉与任何支持类不匹配的查询特征,生成一个过滤后的查询特征映射QF,它只突出显示属于给定支持类的对象。
编码匹配:建立类间关系
通过引入一系列的预定义任务编码,并分配给支持集中的每一类,然后匹配查询特征和对应的任务编码,最后是预测任务编码而不是具体的某一类别。通过余弦函数建立任务编码,类似于Transformer的位置编码
3、训练目标
前提:每一次可以预测N个种类,代表查询图片,
代表在查询图片中存在的目标,每个目标
由类别以及bounding box组成,如果没有这个目标
,那么
指的是支持集中的C个类别,并且将这C个类别通过映射函数
从类别标签映射为任务编码标签,即
,这只是其中一种映射函数的形式。
Meta-DETR的检测目的为:
![]()
其中:
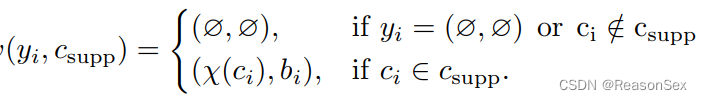
损失函数:
对预测得到的分类和真实的分类使用二分图匹配,指的是一种排列,代表最优的预测和真实之间的分配
其中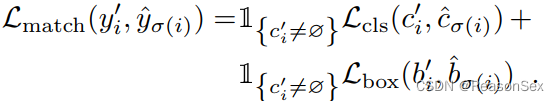
得到最优的后优化网络的损失函数如下,
![]()
在类别损失函数中,还使用了focal loss函数,在预测框损失函数中,使用了l1 loss和GIoU的线性组合。此外,还用了度量学习的方法,引入余弦相似度交叉熵函数去区分原型特征,使得不同类别的特征能够分的更开,减少误检。
4、训练与推理步骤
训练包含两步,首先在基类数据集中训练,然后是在加入新类后的既包含基类又包含新类的的数据集上训练,这相当于微调。包含基类是为了避免在基类上灾难遗忘。
推理时,首先一次性计算每个支持类别的原型特征,然后直接把它们用在每个查询图片上进行检测,这是高效的。

















 5124
5124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









