






推荐博客:https://blog.csdn.net/ogebgvictor/article/details/129784503,关于yolov5训练提前resize,打开cache,batch size的设置等做了很多对比实验。

问题记录及解决
1、使用ddp训练,生成标签的cache报错,等待时间过长。
方法:先使用dp训练,生成标签的cache,停掉再使用ddp方式训练。
2、
[E ProcessGroupNCC
L.cpp:828] [Rank 6] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=438621, OpType=BROADCAST, Timeout(ms)=1800000) ran for 1806330 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:828] [Rank 4] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=438621, OpType=BROADCAST, Timeout(ms)=1800000) ran for 180633
7 milliseconds before timing out.
参考:https://stackoverflow.com/questions/69693950/error-some-nccl-operations-have-failed-or-timed-out
修改:
# dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
torch.distributed.init_process_group(backend='nccl', timeout=datetime.timedelta(seconds=36000))
速度优化
参考:https://blog.csdn.net/weixin_41012399/article/details/133307450?spm=1001.2014.3001.5501
300万张提前resize好的图片,训练11个小时/epoch
方法一:提前resize
参考:https://blog.csdn.net/ogebgvictor/article/details/129784503
https://blog.csdn.net/ogebgvictor/article/details/132529353
这里需要注意,如果你的训练图片都很大,比如分辨率高,或者压缩率低,你都可以根据训练用到的分辨率直接把原图resize一下,保存为jpg格式,直接保存到npy文件中(具体见续篇),比如你训练的分辨率用的是640(yolov5默认就是640),那你就把图片resize到640(保持宽高比例)就行了,这样你的图片就变小了,那读图时间自然就少了。并且有可能变小之后你的内存装的下了,那速度就起飞了!
此处修正:
1.保存为640jpg会对图片有一定损失,可以保存为640分辨率的npy,npy完全无损,但是速度较慢。经过测试,取折中方式,保存为640jpg选择质量100%(默认80%),图片损失对模型训练影响可接受,还可以提高训练速度。
方法二:开启图片缓存
参考:https://blog.csdn.net/ogebgvictor/article/details/129784503
(‘–cache’, type=str, nargs=‘?’, const=‘ram’, help=‘image --cache ram/disk’)
 图片的缓存文件是对应npy,占用的空间是原始图片的10倍以上。可以选择缓存到系统RAM空间,也可以缓存到硬盘。我这里数据量太大,系统RAM空间不够。可以选择缓存到disk。
图片的缓存文件是对应npy,占用的空间是原始图片的10倍以上。可以选择缓存到系统RAM空间,也可以缓存到硬盘。我这里数据量太大,系统RAM空间不够。可以选择缓存到disk。
开启缓存的适用情况:
如果训练图片总量不大,或者服务器内存超高,即完全可以把解码后的图片放内存里,那就充分利用,直接加上–cache参数完事。如果读图片的时间不长,它的耗时只占总时间的很少一部分,没什么优化意义那就不用管它。
参照上述博客的结论,如果resize之后再用缓存,那速度更是快的飞起。我这里系统内存不够,只能缓存到硬盘,但是我这里硬盘读取速度不快,需要测试一下效果。


方法二:查看内存和gpu使用情况。
htop
nvidia-smi
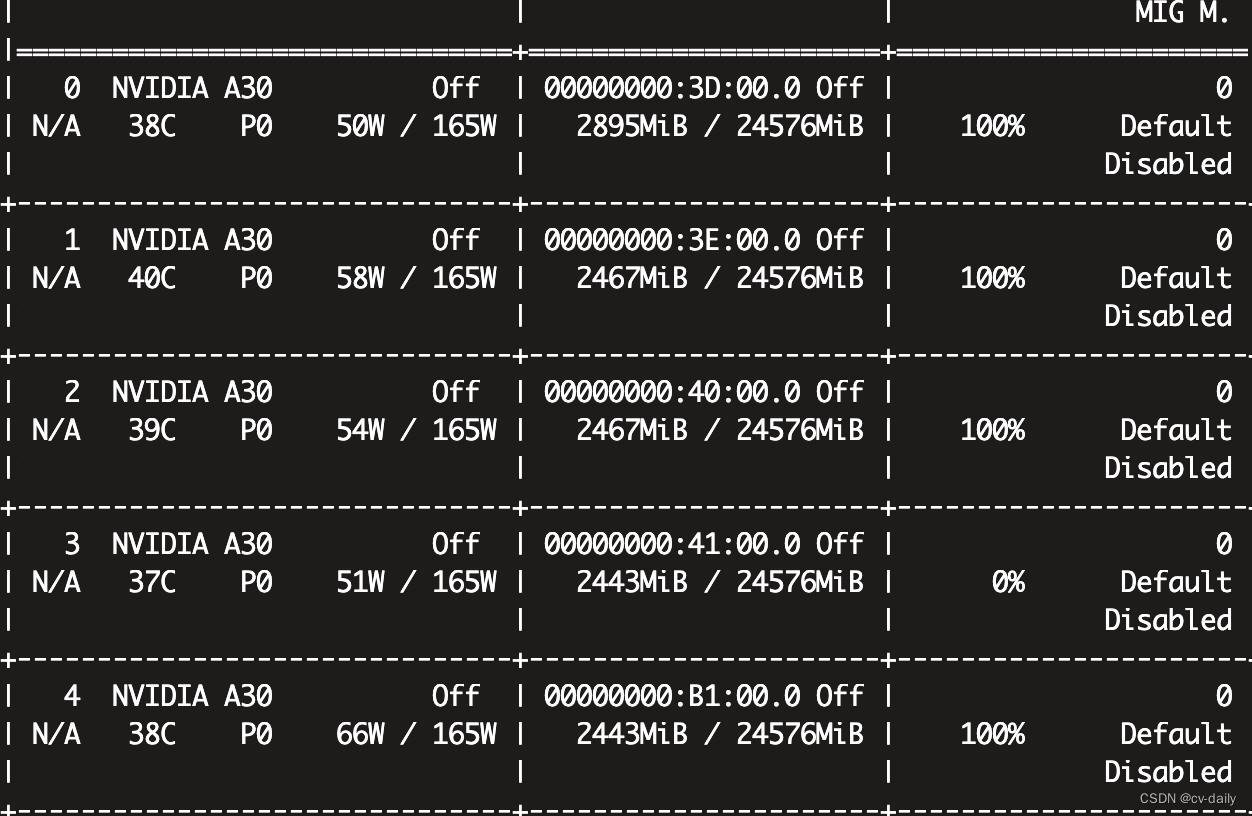

显存和cpu使用率都不高,参考:https://blog.csdn.net/flamebox/article/details/123011129
修改workers和batchsize,提高cpu和gpu使用率。
目前的workers是8,bs是32.
修改workers=16,bs=64。提高cpu和gpu使用率,但是会使用更多的内存,需要关注系统内存使用情况,目前是167G/252G。查看cpu使用情况,以及训练速度。
训练速度有一点提高,10.5个小时/epoch,效果不明显。
cpu使用率没有提高,gpu使用率有一定提高。

分析原因,增加workers没有提高cpu使用率,猜测瓶颈是在读取数据的磁盘io上,读取数据跟不上,workers增大也没有意义。gpu使用率可以尝试进一步提升一下。改为workers=16,bs=128。
读图和训练是并行进行的,需要看一下瓶颈在cpu读图还是gpu训练,如果两个都不是瓶颈,可以增加gpu和cpu使用率。
















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









