







使用工具
pycharm,python语言编译
使用的包和驱动
selenium、chromedriver(与自己的谷歌版本对应)
设置selenium来接管使用中的浏览器,
- 否则就会出现错误,错误提示如下:10001:请求参数异常,请升级客户端后重试"
- 首先先将谷歌的路径添加到环境当中,选择谷歌浏览器,右击打开文件位置,复制路径
- 右击我的电脑,选择属性—高级系统—新建path将路径复制进去
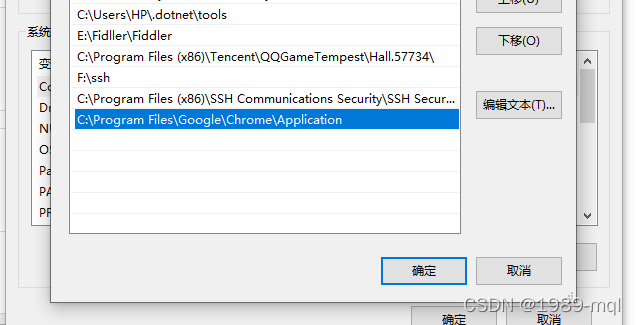
-
打开控制窗口,输入 cmd回车,在命令窗口输入如下命令,当输入chrome.exe时会打开一个小窗口,再输入命令
chrome.exe --remote-debugging-port=9222 --user-data-dir=“F:\selenium_data”,F:\selenium_data
为数据存储的地方
-
保留这个浏览器的窗口,当运行代码的时候观察这个窗口的变化即可
实现的基本步骤
1. 初始化ChromeDriver
2. 打开知乎登录页面
3. 切换密码登录界面
4. 设置selenium来接管使用中的浏览器,否则就会出现错误,错误提示如下:10001:请求参数异常,请升级客户端后重试"
3. 找到用户名框,输入用户名
4. 找到密码框,输入密码
5. 按下enter键
6. 手动滑动验证码
代码实现
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
#驱动
driver=webdriver.Chrome(options=chrome_options)
driver.get("https://www.zhihu.com/signin?next=%2F")
time.sleep(1)
#点击密码登录界面
driver.find_element_by_css_selector("div[class='SignFlow-tab']").click()
#找到用户框,输入用户名
elem=driver.find_element_by_name("username")
elem.clear()
#输入账号
elem.send_keys("13471479481")
#找到密码框,输入密码
password=driver.find_element_by_name("password")
password.clear()
password.send_keys("moqiaoli123926")
#
##模拟键盘回车
elem.send_keys(Keys.RETURN)
time.sleep(4)
print(driver.page_source)
driver.quit()















 3290
3290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











