






2023 HDR Imaging with Spatially Varying Signal-to-Noise Ratios
一、Abstract
一次曝光范围内,动态范围很窄。在光照限制的情况下,成像的动态范围会变的很窄,而且低光带来的噪声也是随着空间变化的。
高光会丢失高亮细节,低光呢,相对于高光是更好恢复吗
短曝HDR,很关键的一点是去噪吧,低光带来的读出噪声和ADC噪声
读取噪声是在原始数据进行处理的过程中产生的,所以读取噪声不取决于捕获的光子量,二十取决于拍摄的帧数(在连拍的过程中,当然也和isp处理相关)
所以,每多拍摄一帧,都会增加额外的固定读取噪声
由此,弱光下的HDR会受到严重的限制
1.过暗导致的噪声
2.较宽的亮度范围
文章将这个描述为空间变化的信噪比问题SNR ,较亮的像素具有较高的信噪比,较暗的像素具有较低的信噪比
所以其实文章的出发点就是,在过暗环境下HDR,还要去噪。以前的去噪方法都是在归一化到[0,1]的色调映射图像,并不那么适用于较宽的动态范围
文章提出了一种空间变化的高动态范围(SV-HDR)融合网络,同时去噪和融合图像,并将三次曝光混合成一个HDR图像。
文章提出的网络是一种基于变压器的方法,有三种定制的设计:
① 一个多曝光的transformer块来提取特征(不同的transformer块适用于不同的信噪比)
② 引入一个曝光共享块来混合上面得到的三个曝光的特性
③ 我们采用一个多尺度混合策略来捕获全部和局部的变化。
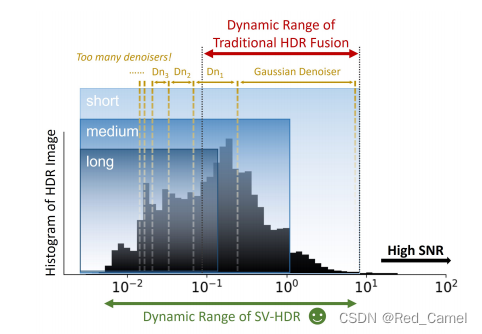
文章说,传统的HDR方法其实是适用于高信噪比的情况下。上图的Dn1,Dn2,Dn3都是去噪器,很显然,这些去噪器的适用范围其实很窄。文章提出的去噪的动态范围就很广
>去噪的动态范围???????
二、Related Work
1.真实成像建模
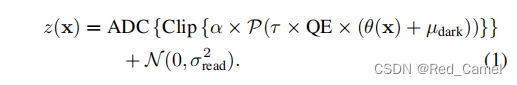
场景辐照度的
θ
(
x
)
\theta(x)
θ(x),
μ
d
a
r
k
\mu_{dark}
μdark是暗电流,这两个相加就是获得的原始数据,然后*QE(量化效率),然后再*曝光时间τ,总的就是下面这个表
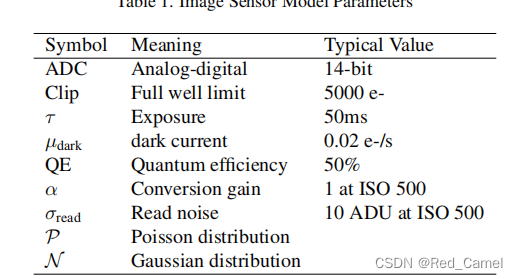
该模型没有考虑其他“高阶”效应,如ADC阈值的不稳定性、死像素(包括无响应、过灵敏、随机电报信号、串扰等)、像素响应的不均匀性、下流偏移等。
此外,这个模型成立还需要假设使用的是一个完美的彩色滤光片阵列,即电子和光学的交叉对话是可以忽略不计的。
2.Related Work
① 传统HDR fusion 方法
标注一下,一种方法是标注动态部分的图像并拒绝一定量的像素。
另外一种方法是基于注册的,就是像素首先先相对于参考系对齐,对齐可以是基于光流的,基于能量优化的,基于秩最小化的等。
这些方法可以解决小运动,但是解决不了大运动。
② 深度学习方法
③ 低光HDR和新传感器
随着量子图像传感器(QIS)和单光子雪崩二极管(SPAD)的普及,人们开始探索在弱光条件下使用新的HDR传感器。[10]和[2]显示了QIS的理论性能,而[6,15,25,42]用SPAD显示了相应的结果。[3]还报道了一种新的双曝光传感器,它演示了HDR视频的去噪和去模糊。
3.为什么去噪不行
现在的HDR融合算法无法混合夜间捕获的图像—>文章的推测是散粒噪声和动态范围较大。
① 消融实验一
噪声对HDR融合的影响
上面一行是100个光子的图像,效果还行(结果是合理的,尽管有一些轻微的音调差异);
下面一行是10个光子的,效果很差。
但是我个人感觉这个消融实验有点奇怪

②消融实验二
动态范围对去噪的影响
构建一个包含四个子去噪器的toy denoiser(去噪器是REDNet模型)。
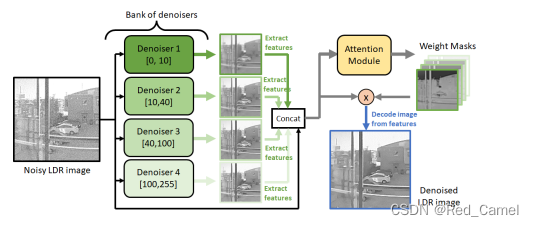
实验将一张图像发送给四个子去噪器处理,然后把去噪完的子图像concat输入到attention模块,生成五个权重掩膜。!针对的是一张图像
这5个权重mask和concat出来的数据结合,得到去噪后的LDR image。
对于包含三个或更以上曝光的曝光支架,每次曝光都需要一个这样的去噪系统。为了缓解需要多次去噪的问题,本文提出了一种替代设计方法。

第一张就是噪声图像合成的HDR。第二张是用3个去噪器的合成的hdr。第三张是用了上面的网络的12个去噪器的合成的图像。
三、模型
1.整体结构
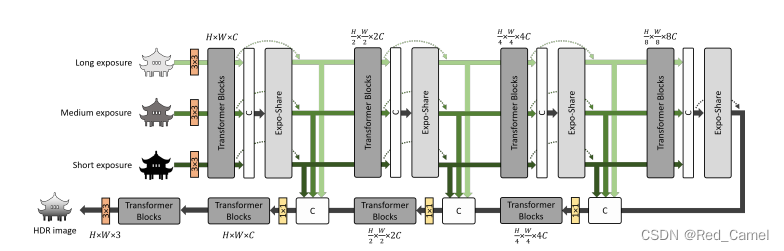
整体上是一个Unet结构(编码器-解码器结构)。给定一组LDR图像,用编码器提取特征,然后用解码器生成HDR结果。
以前的HDR融合方法会使用不同的分支来处理短、中和长曝光图像。
**文章提出一个单编码器(来处理不同曝光的图像),单编码器可以在处理空间变化的信噪比场景θ(x)时降低网络容量。**具体实现如下:
1.这个单编码器是通过transformer中的自注意力实现的。用这个区分exposure(曝光), gain(增益), and noise variance.(噪声方差)
2.此外,还提出一个Expo-share moodule ,实现在不同曝光图像之间的信息交互。
在编码器的最后,连接了三组特征。解码器将它们合并并执行HDR融合。
① 多尺度
input 是LDR image rgb图像。方法首先会把图像映射到HDR域上
三个LDR image(不同曝光),用逆gamma校正和曝光归一化
I
^
i
=
I
i
γ
t
i
\hat{I}_i=\frac{I_i^{\gamma}}{t_i}
I^i=tiIiγ(ti是曝光时间),然后把这个作为附加的channel,加到
I
i
I_i
Ii上。
SV-HDR从卷积获取浅层特征,然后在一系列的transformer块获得深层特征
这边的transformer块的编码器部分,会在每个level后使用了Expo-Share块(帮助特征交换和运动缓解))。
编码器的不同级别之间的下采样是通过3*3卷积和pixel-shuffling
用了skip connection
最后用transformer block和3*3卷积重建HDR
②损失函数
HDR成像是关于从广泛的信号水平上聚集信息。标准的损失函数,如均方误差是偏向于明亮的像素。在黑暗区域,像素值的细微变化不会反映在这种损失中,但与信号水平相比,可能会产生显著的影响。因此,我们需要计算调映射HDR图像T(ˆH)和调映射地面真实HDR T (H)之间的损失函数。我们在[17,36]之后使用可微的音调映射。
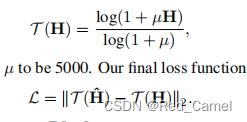
2.Transformer Block
用来SW-MSA和MLP,还使用了skip connection。用来GELU激活函数
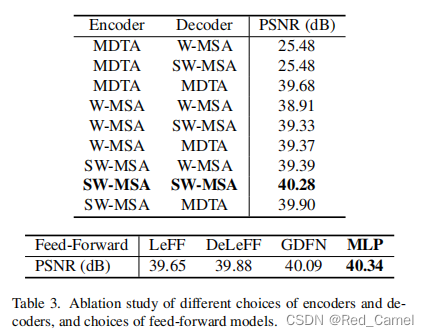
消融实验决定的。
SV-HDR has a serial of transformer blocks at each downsample level. We use 4, 6, 6, and 8 transformer blocks for
the four levels with down-sample ratios 1×, 2×, 4×, and 8×, respectively. The numbers of heads of MSA are 1, 2,
4, and 8 in the four levels. In the final refinement stage,four additional transformer blocks are used. The number of
channels of features, C, is selected to be 48.
3.Expo-share Block
促进不同曝光之间的信息交互,这个block会在每个level之后共同处理所有曝光的特征。
在第l个level,在特征在channel维度concat,
F
i
F_i
Fi。然后再split ,定义为
F
i
F_i~
Fi 。
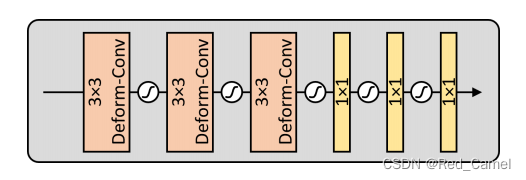
因为场景在不同帧之间是动态的,文章使用了可变性卷积,增加空间采样区域并隐式地对齐特征。
每个Expo-Share 包含3个33的可变性卷积,然后是3个11的卷积层(聚合跨通道的像素级信息,用GELU激活)
四、实验
我们使用卡兰塔里数据集[17]来训练我们的模型。该数据集包含大量的LDR图像与地面真实HDR图像与中间曝光对齐。我们首先通过随机旋转和翻转图像将数据增加8次,将图像降采样2×,将图像中心随机裁剪到128×128块,从中心向下采样和裁剪确保这些块包含动态前景对象。然后,我们按照我们的传感器模型来合成有噪声的LDR图像。为了使我们的模型适用于广泛的光照条件,我们对τ进行随机采样,使每个像素的最大光子计数在4到256之间的三角形分布,模式为8。对于400-700nm波长[29]的光,这大约等于0.005到0.0.1/50秒,像素间距为6微米。我们将量化宽松固定为50%,α固定为1。短、中、长曝光的读取噪声σread分别设置为0.0292、0.1798、1.4384,与索尼ILCE-7M2相机在ISO为200、1600和12800时的特性相匹配,以便对真实图像进行测试。我们用一批s训练模型每时代300个时代1184次迭代















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









