







有时候文件做成的tfrecord可能会有几十G,想先直接从众多的图像文件构建Dataset ?
下面的内容应该能帮到你
简介看下面参考文献第一个,他讲的很清楚了
本篇笔记脉络如下
- 1 创建
- 2 变换
- 3 获取 样本Tensors
- 4 使用
- 5 Performance Considerations
- reference
1 创建
因为图像很多,我们不能将图像全部读到Dataset里,所以这一步我们先在Dataset里存放所有文件路径
filelist = os.listdir(img_dir)
# lable_list = ... # 标签列表根据自己的情况获取
# 两个tensor
t_flist = tf.constant(filelist)
t_labellist = tf.constant(lable_list)
# 构造 Dataset
dataset = tf.data.Dataset().from_tensor_slices(t_flist, t_labellist)至此构造完成,set里面就是一个个样本 [file, label]
2 变换
常用的有这么几个,逐一介绍
- cache
- map
- shuffle
- repeat
- batch
- prefetch
最后给出常用组合
cache
将dataset缓存在内存或者本地硬盘
cache(filename='')就一个参数 tf.string类型的tf.Tensor,表示文件系统里的一个文件路径,默认是内存
map
map(
map_func,
num_parallel_calls=None
)两个参数
- 第一个map函数,用来变换样本
- 并发数,一般填cpu线程数
针对上面的图像,我们需要将 [file, label] 变换到 [img_data, label],所以函数形式如下
def _mapfunc(file, label):
with tf.device('/cpu:0'):
img_raw = tf.read_file(file)
decoded = tf.image.decode_bmp(img_raw)
resized = tf.image.resize_images(decoded, [h, w])
return resized, label
# 上面return还可以加上文件名,这里的个数随意
# 下面 Iter.get_next().run 返回的每个成员和这里对应GPU和CPU异步处理整个计算图,GPU集中于各种大数据量的计算,所以图像解码的任务交给CPU,这是google的建议
shuffle
打乱set里的样本,各种样本混在一起后必须要的操作
shuffle(
buffer_size,
seed=None,
reshuffle_each_iteration=None
)reshuffle_each_iteration 默认 True
buffer_size 比样本数+1
常用组合
dset = dataset.map(_mapfunc)3 获取 样本Tensors
先是迭代器
- make_one_shot_iterator()
- make_initializable_iterator(shared_name=None)
还有俩没列出来,用到的时候再加进来吧
然后是 样本Tensors
get_next(name=None)- Returns a nested structure of tf.Tensors containing the next element.
样例代码
_iter = dset.make_one_shot_iterator()
next_one = _iter.get_next() # type: tuple4 使用
把next_one 当成 tensor 开始构建图
比如算个全局平均池化
img, label = next_one
# tf 1.4 这个tensor没有dim的信息,各种op都报dim的错误
# 一般会报 channel 最后这个维度为 None
# 必须加这个reshape
out.set_shape([-1, -1, -1, 3])
out = tf.reshape(img, [-1, h, w, c])
out = tf.reduce_mean(out, axis=(1, 2)) # channels last
# out shape: (n, c)ValueError: The channel dimension of the inputs should be defined. Found `None`.5 Performance Considerations
上面那些变换很好用,但是顺序对性能有些影响
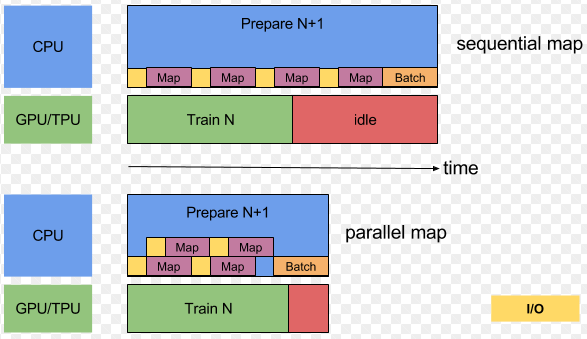
Map and Batch
map用到了自定义函数,如果很短就会导致调用开销(overhead)大,所以推荐batch之后map
不过map函数要处理batch,就要加循环了,针对我上面的map,我只能想到用tf.while_loop
Map and Cache
官方言:如果map函数开销大,只要你内存或者硬盘放得下,就map -> cache。
因为不用cache时,这个map每次都在GPU需要前计算,如果mapfunc开销大,
确实会拖慢GPU的脚步,提前算好并缓存能减少突发需求的等待时间
不过上面prefetch里也提到了,n达到一定值就够了,不需要全部。
这个Cache的作用可能会沦为减少频繁的硬盘读
Map and Interleave / Prefetch / Shuffle
后面仨会一直占用一块缓存(缓存了dataset里的元素),如果map改变了样本的大小,
这个顺序就会影响内存使用
Repeat and Shuffle
官方推荐用 tf.contrib.data.shuffle_and_repeat,不行就
shuffle -> repeat
reference
TensorFlow全新的数据读取方式:Dataset API入门教程
https://zhuanlan.zhihu.com/p/30751039
Importing Data
https://www.tensorflow.org/programmers_guide/datasets
Module: tf.data
https://www.tensorflow.org/versions/master/api_docs/python/tf/local_variables
Introduction to TensorFlow Datasets and Estimators
https://developers.googleblog.com/2017/09/introducing-tensorflow-datasets.html
Input Pipeline Performance Guide
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/performance/datasets_performance.md

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









