






Datawhale 2024年AI夏令营的第五期学习活动聚焦于深度学习,第三阶段主要内容是机器学习框架&实践。
本篇笔记为第三阶段的笔记,这也是本期夏令营最后一个阶段。
本阶段的主要学习任务为学习了解实践方法论。
一、模型偏差及其影响
模型偏差指的是模型本身的设计过于简单,无法充分捕捉数据中的复杂关系或规律。在书中给出的例子中,如果模型的函数集合太小,无法包含任何能显著降低损失的函数,那么无论怎么调整模型的参数(θ),都无法使损失降低到理想水平。这就像是试图用一个直线方程去拟合一个高度非线性的数据集,无论如何调整直线的斜率和截距,都无法完美匹配数据点。
二、优化问题
书中提到可以使用梯度下降法,梯度下降法可能由于陷入局部最小值而无法找到全局最优解,导致模型的损失函数值较高。但是,高损失并不一定完全归咎于模型偏差,还需要考虑优化过程本身是否存在问题。为了区分这两种情况,可以通过比较不同复杂度的模型在训练集上的表现来进行分析。如果更复杂的模型在训练集上的损失反而高于较简单的模型,且这种差异不能通过模型偏差来解释(因为理论上更复杂的模型应该能够轻松达到或超越较简单模型的效果),那么这通常表明是优化问题导致的。
三、过拟合的问题
过拟合是指模型在训练数据上表现很好,但在测试数据上表现不佳的现象。书中用一个极端的例子来说明过拟合的情况,也就是模型完全记住训练数据中的每一个点,导致在新数据上无法泛化。
过拟合的一个原因是模型过于灵活,能够拟合训练数据中的噪声。书中为了防止过拟合,提出可以用增加训练数据、数据增强、限制模型的复杂度的方法来解决。
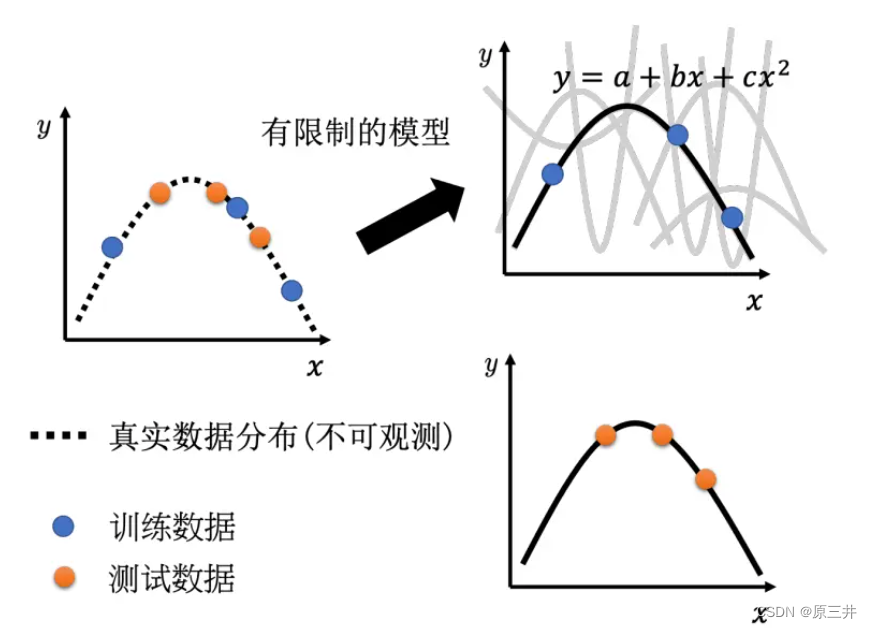
图1 对模型增加限制
四、交叉限制
针对过拟合的问题,建议使用交叉验证方法,特别是k折交叉验证。k折交叉验证将数据集分为k个子集,每次使用k-1个子集进行训练,剩下的一个子集进行验证,重复k次,最后取平均值作为最终的验证结果。
五、不匹配的问题
针对于不匹配的问题,给出的例子提到了一个从2021年1月1日开始的预测模型,其中红色的线表示真实的数字,蓝色的线表示预测的结果。2月26日是2021年观看人数最多的一天,但模型的预测结果与实际数据相差很大,误差达到了2580。模型在这一天的表现不佳,有可能是因为模型没有考虑到这一天的特殊情况,导致预测结果与实际情况不匹配。
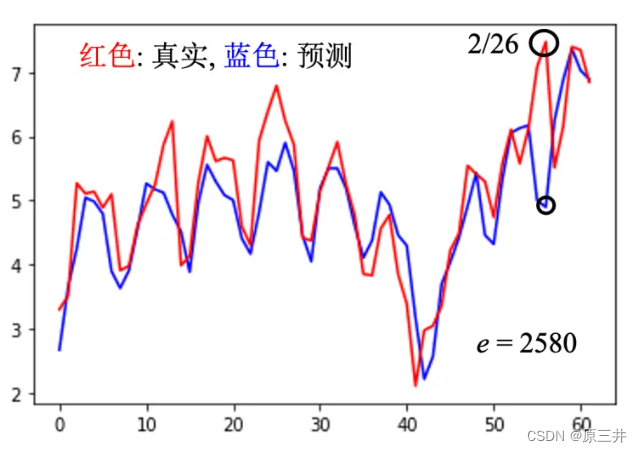
图2
不匹配问题与过拟合不同,过拟合可以通过收集更多的数据来解决,但不匹配问题需要对数据分布有更深入的理解。如果训练数据和测试数据的分布不同,即使增加数据量也无法解决不匹配问题。
以上为本次Task3学习内容的笔记。感谢Datawhale提供丰富的学习资源。















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









