







1、初识go
1.1、go语言
Go适合用来做什么?
- 服务器编程,以前你如果使用C或者C++做的那些事情,用Go来做很合适,例如处理日志、数据打包、虚拟机处理、文件系统等。
- 分布式系统,数据库代理器等。 网络编程,这一块目前应用最广,包括Web应用、API应用、下载应用。
- 内存数据库,如google开发的groupcache,couchbase的部分组建。
- 云平台,目前国外很多云平台在采用Go开发,CloudFoundy的部分组建,前VMare的技术总监自己出来搞的apcera云平台。
学习网站:Go语言中文网
视频课:黑马程序员快速入门go语言
1.2 第一个Go程序
// hello.go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello Go!")
}
每个Go源代码文件的开头都是一个package声明,表示该Go代码所属的包。包是Go语言里最基本的分发单位,也是工程管理中依赖关系的体现。
要生成Go可执行程序,必须建立一个名字为main的包,并且在该包中包含一个叫main()的函数(该函数是Go可执行程序的执行起点)。
Go语言的main()函数不能带参数,也不能定义返回值。
在包声明之后,是一系列的import语句,用于导入该程序所依赖的包。由于本示例程序用到了Println()函数,所以需要导入该函数所属的fmt包。
所有Go函数以关键字func开头。一个常规的函数定义包含以下部分:
func 函数名(参数列表)(返回值列表) {
// 函数体
}
Go程序并不要求开发者在每个语句后面加上分号表示语句结束,这是与C和C++的一个明显不同之处。
注意:强制左花括号{的放置位置,如果把左花括号{另起一行放置,这样做的结果是Go编译器报告编译错误。
命令行运行程序

2、基础类型
2.1、命名
Go语言中的函数名、变量名、常量名、类型名、语句标号和包名等所有的命名,都遵循一个简单的命名规则:一个名字必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。
大写字母和小写字母是不同的:heapSort和Heapsort是两个不同的名字。
2.2、变量
变量是几乎所有编程语言中最基本的组成元素,变量是程序运行期间可以改变的量。
从根本上说,变量相当于是对一块数据存储空间的命名,程序可以通过定义一个变量来申请一块数据存储空间,之后可以通过引用变量名来使用这块存储空间。
2.2.1 变量声明
Go语言的变量声明方式与C和C++语言有明显的不同。对于纯粹的变量声明, Go语言引入了关键字var,而类型信息放在变量名之后,示例如下:
var v1 int
var v2 int
//一次定义多个变量
var v3, v4 int
var (
v5 int
v6 int
)
2.2.2 变量初始化
对于声明变量时需要进行初始化的场景, var关键字可以保留,但不再是必要的元素,如下所示:
var v1 int = 10 // 方式1
var v2 = 10 // 方式2,编译器自动推导出v2的类型
v3 := 10 // 方式3,编译器自动推导出v3的类型
fmt.Println("v3 type is ", reflect.TypeOf(v3)) //v3 type is int
//出现在 := 左侧的变量不应该是已经被声明过,:=定义时必须初始化
var v4 int
v4 := 2 //err
2.2.3 变量赋值
var v1 int
v1 = 123
var v2, v3, v4 int
v2, v3, v4 = 1, 2, 3 //多重赋值
i := 10
j := 20
i, j = j, i //交换,i=20, j=10
fmt.Printf("i = %d, j = %d\n", i, j)
2.2.4 匿名变量
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃
_, i, _, j := 1, 2, 3, 4
func test() (int, string) {
return 250, "hello"
}
_, str := test()
2.3、常量
在Go语言中,常量是指编译期间就已知且不可改变的值。常量可以是数值类型(包括整型、浮点型和复数类型)、布尔类型、字符串类型等。
2.3.1 字面常量(常量值)
所谓字面常量(literal),是指程序中硬编码的常量,如:
123 // 整型的常量
3.1415 // 浮点类型的常量
3.2+12i // 复数类型的常量
true // 布尔类型的常量
"foo" // 字符串常量
2.3.2 常量定义
const Pi float64 = 3.14
const zero = 0.0 // 浮点常量, 自动推导类型
const ( // 常量组
size int64 = 1024
eof = -1 // 整型常量, 自动推导类型
)
const u, v float32 = 0, 3 // u = 0.0, v = 3.0,常量的多重赋值
const a, b, c = 3, 4, "foo"
// a = 3, b = 4, c = "foo" //err, 常量不能修改
2.3.3 iota枚举
常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。
在一个const声明语句中,在第一个声明的常量所在的行,iota将会被置为0,然后在每一个有常量声明的行加一。
const (
x = iota // x == 0
y = iota // y == 1
z = iota // z == 2
w // 这里隐式地说w = iota,因此w == 3。其实上面y和z可同样不用"= iota"
)
const v = iota // 每遇到一个const关键字,iota就会重置,此时v == 0
const (
h, i, j = iota, iota, iota //h=0,i=0,j=0 iota在同一行值相同
)
const (
a = iota //a=0
b = "B"
c = iota //c=2
d, e, f = iota, iota, iota //d=3,e=3,f=3
g = iota //g = 4
)
const (
x1 = iota * 10 // x1 == 0
y1 = iota * 10 // y1 == 10
z1 = iota * 10 // z1 == 20
)
2.4、基础数据类型
2.4.1 分类
Go语言内置以下这些基础类型:
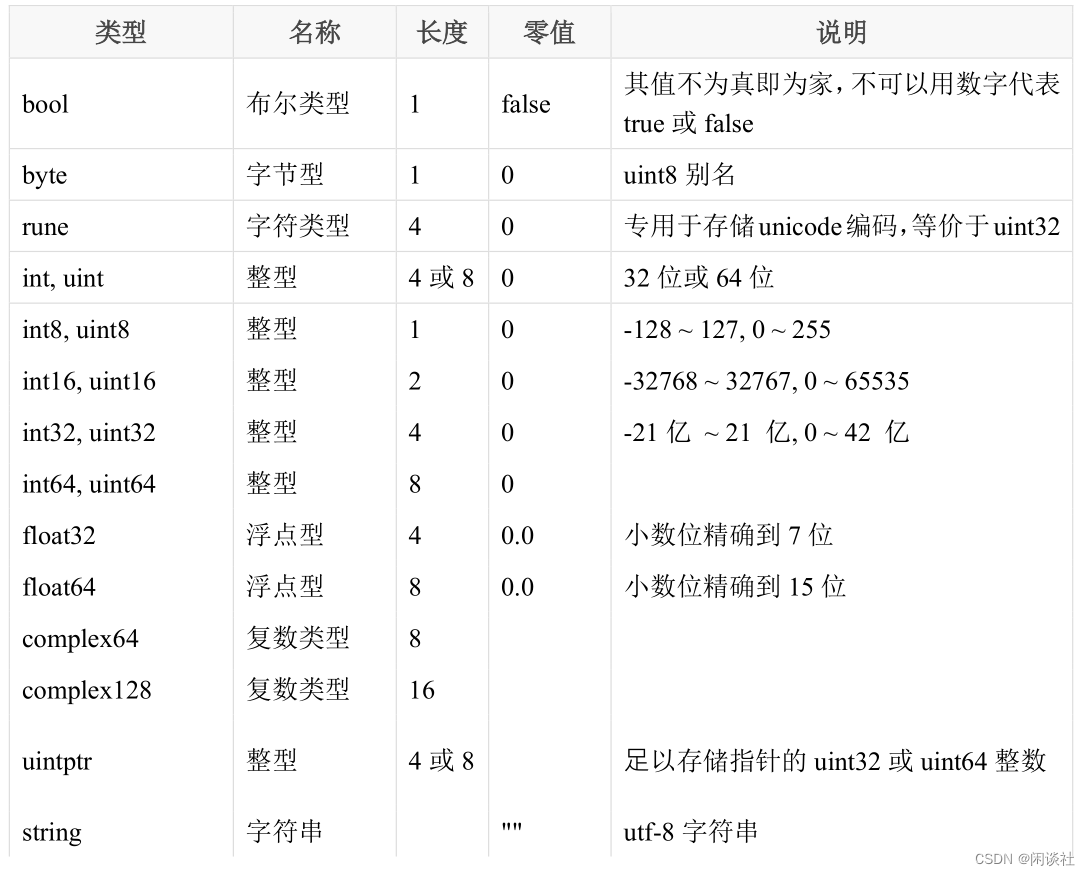
2.4.2 布尔类型
var v1 bool
v1 = true
v2 := (1 == 2) // v2也会被推导为bool类型
//布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换
var b bool
b = 1 // err, 编译错误
b = bool(1) // err, 编译错误
2.4.3 整型
var v1 int32
v1 = 123
v2 := 64 // v1将会被自动推导为int类型
2.4.4 浮点型
var f1 float32
f1 = 12
f2 := 12.0 // 如果不加小数点, f2会被推导为整型而不是浮点型,float64
2.4.5 字符类型
在Go语言中支持两个字符类型,一个是byte(实际上是uint8的别名),代表utf-8字符串的单个字节的值;另一个是rune,代表单个unicode字符。
var ch1, ch2, ch3 byte
ch1 = 'a' //字符赋值
ch2 = 97 //字符的ascii码赋值
ch3 = '\n' //转义字符
fmt.Printf("ch1 = %c, ch2 = %c, ch3 = %c", ch1, ch2, ch3) // ch1 = a, ch2 = a, ch3 =
2.4.6 字符串
在Go语言中,字符串也是一种基本类型
var str string // 声明一个字符串变量
str = "abc" // 字符串赋值
ch := str[0] // 取字符串的第一个字符
fmt.Printf("str = %s, len = %d\n", str, len(str)) //内置的函数len()来取字符串的长度
fmt.Printf("str[0] = %c, ch = %c\n", str[0], ch)
//`(反引号)括起的字符串为Raw字符串,即字符串在代码中的形式就是打印时的形式,它没有字符转义,换行也将原样输出。
str2 := `hello
mike \n \r测试
`
fmt.Println("str2 = ", str2)
/*
str2 = hello
mike \n \r测试
*/
2.4.7 复数类型
复数实际上由两个实数(在计算机中用浮点数表示)构成,一个表示实部(real),一个表示虚部(imag)
var v1 complex64 // 由2个float32构成的复数类型
v1 = 3.2 + 12i
v2 := 3.2 + 12i // v2是complex128类型
v3 := complex(3.2, 12) // v3结果同v2
fmt.Println(v1, v2, v3)
//内置函数real(v1)获得该复数的实部
//通过imag(v1)获得该复数的虚部
fmt.Println(real(v1), imag(v1))
2.5、fmt包的格式化输出输入
2.5.1 格式说明
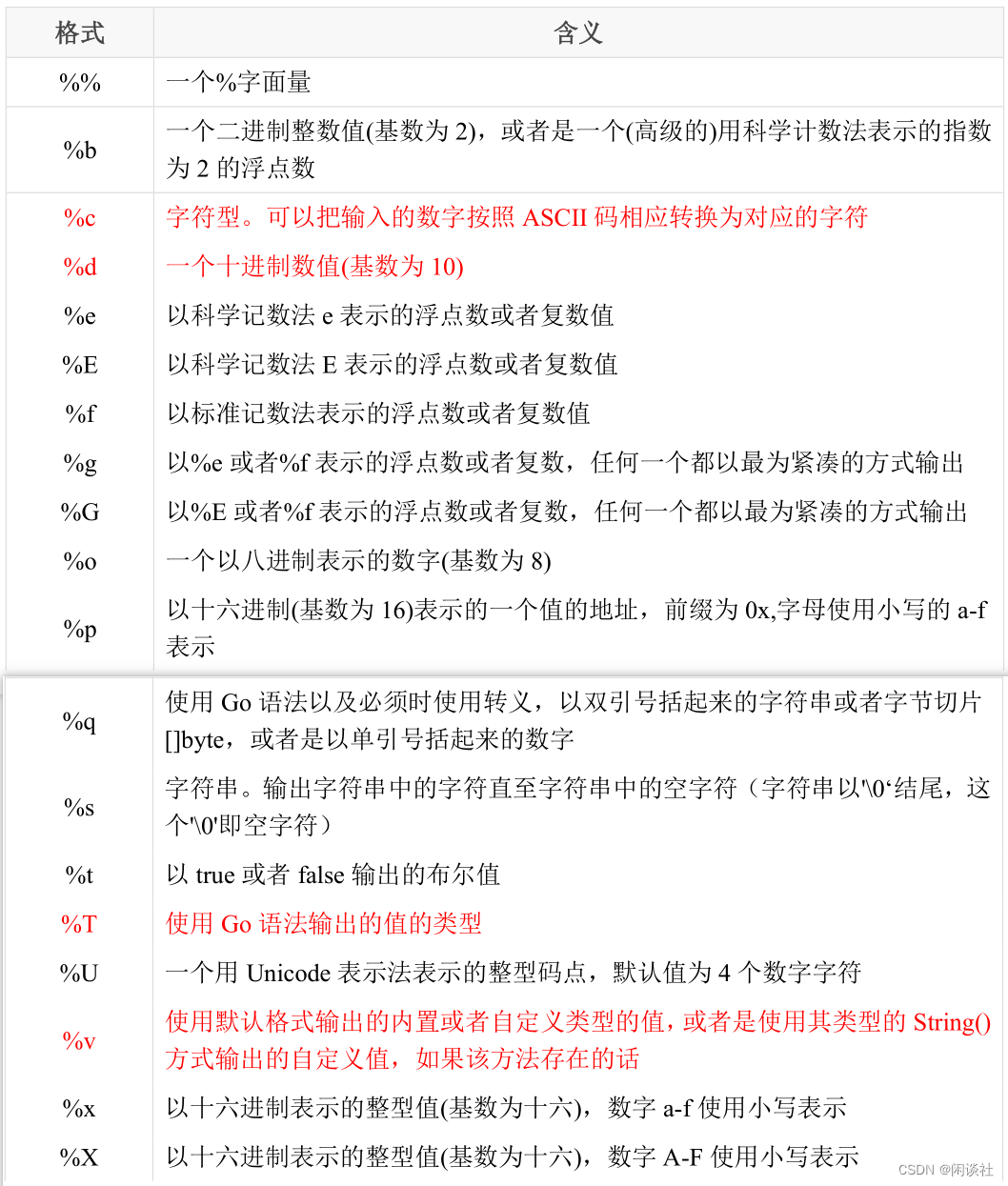
2.5.2 输出
//整型
a := 15
fmt.Printf("a = %b\n", a) //a = 1111
fmt.Printf("%%\n") //只输出一个%
//字符
ch := 'a'
fmt.Printf("ch = %c, %c\n", ch, 97) //a, a
//浮点型
f := 3.14
fmt.Printf("f = %f, %g\n", f, f) //f = 3.140000, 3.14
fmt.Printf("f type = %T\n", f) //f type = float64
//复数类型
v := complex(3.2, 12)
fmt.Printf("v = %f, %g\n", v, v) //v = (3.200000+12.000000i), (3.2+12i)
fmt.Printf("v type = %T\n", v) //v type = complex128
//布尔类型
fmt.Printf("%t, %t\n", true, false) //true, false
//字符串
str := "hello go"
fmt.Printf("str = %s\n", str) //str = hello go
2.5.3 输入
var v int
fmt.Println("请输入一个整型:")
fmt.Scanf("%d", &v)
// fmt.Scan(&v)
fmt.Println("v = ", v)
2.6、类型转换
Go语言中不允许隐式转换,所有类型转换必须显式声明,而且转换只能发生在两种相互兼容的类型之间。
var ch byte = 97
//var a int = ch //err, cannot use ch (type byte) as type int in assignment
var a int = int(ch)
2.7、类型别名
type bigint int64 //int64类型改名为bigint
var x bigint = 100
type (
myint int //int改名为myint
mystr string //string改名为mystr
)
3、运算符
3.1、算术运算符
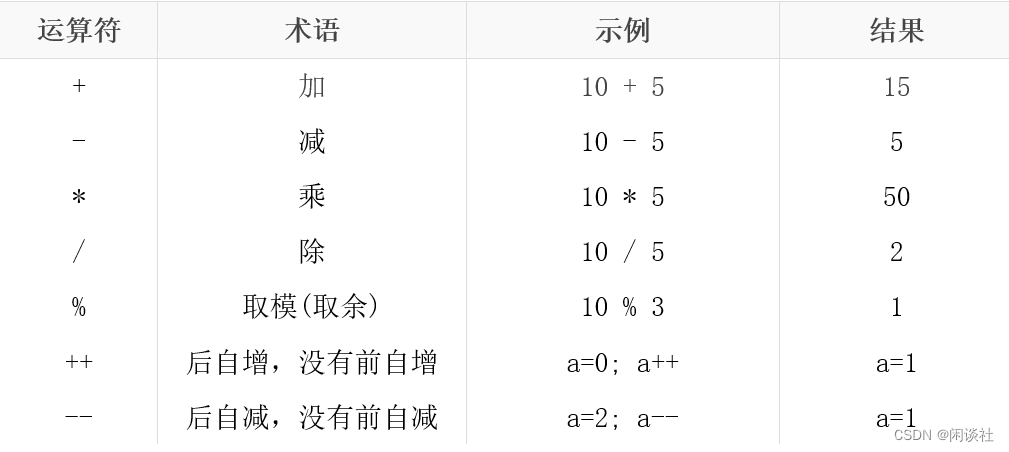
3.2、关系运算符
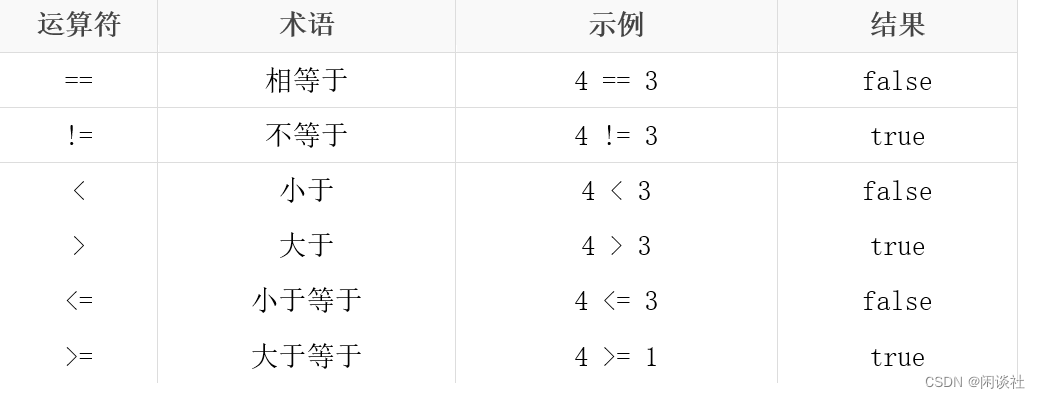
3.3、逻辑运算符

3.4、位运算符

3.5、赋值运算符
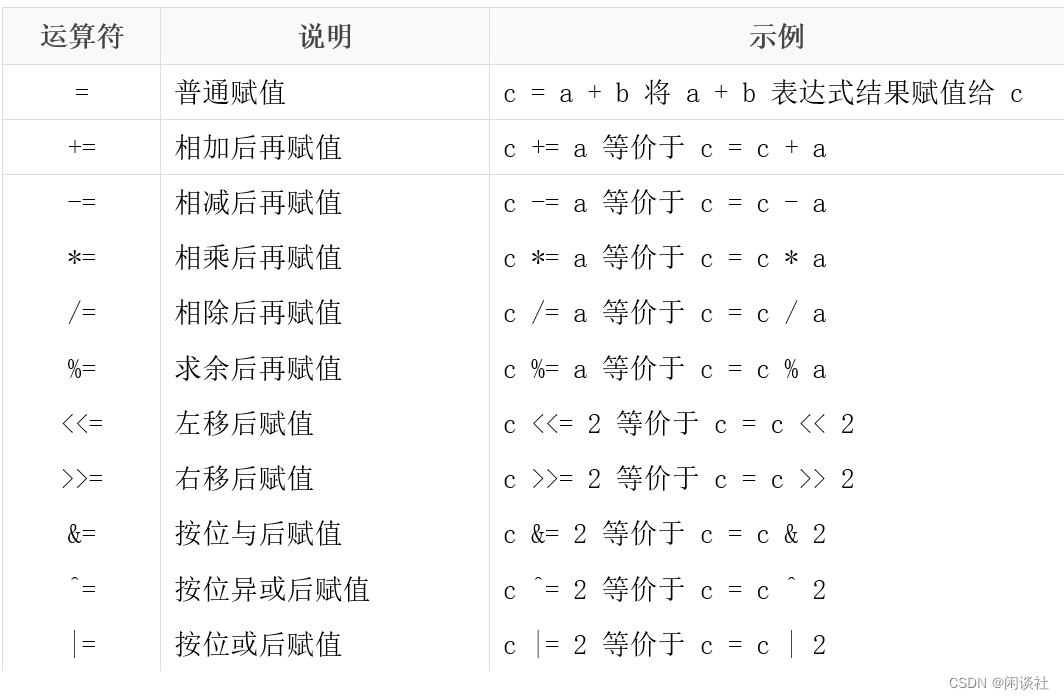
3.6、其他运算符

3.7、运算符优先级
在Go语言中,一元运算符拥有最高的优先级,二元运算符的运算方向均是从左至右。
下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:

4、流程控制
Go 语言支持最基本的三种程序运行结构:顺序结构、选择结构、循环结构。
4.1、顺序结构
4.1.2 if语句
if ... else if ... else
package main
import "fmt"
func main() {
var num1 int = 10;
if num1 == 10 {
fmt.Println("num1 == 10")
}
// 支持一个初始化表达式, 初始化字句和条件表达式直接需要用分号分隔
if num2 := 10; num2 == 10 {
fmt.Println("num2 == 10")
}
// if ... else if ... else
if num3 := 20; num3 < 20 {
fmt.Println("num3 < 20")
} else if num3 > 20 {
fmt.Println("num3 > 20")
} else {
fmt.Println("num3 == 20")
}
}
4.1.3 switch语句
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个 switch, 但是可以使用 fallthrough 强制执行后面的 case 代码
package main
import "fmt"
func main() {
// 默认相当于每个case最后带有break
var score int = 90
switch score {
case 90:
fmt.Println("优秀")
//fallthrough
case 80:
fmt.Println("良好")
//fallthrough
case 60:
fmt.Println("及格")
//fallthrough
default:
fmt.Println("不及格")
}
// 可以使用任何类型或表达式作为条件语句。且支持一个初始化表达式
switch num1 := 90; {
case num1 >= 90:
fmt.Println("90以上")
case num1 >= 80:
fmt.Println("80-90")
default:
fmt.Println("低于80")
}
}
4.2、循环语句
4.2.1 for 语句
package main
import "fmt"
func main() {
var sum int = 0
for i := 0; i < 100; i++ {
sum +=i
}
fmt.Printf("sum = %d\n", sum)
var str string = "abc"
for i := 0; i < len(str); i++ {
fmt.Printf("str[%d] = %c\n", i, str[i])
}
}
4.2.2 range
关键字 range 会返回两个值,第一个返回值是元素的数组下标,第二个返回值是元素的值:
package main
import "fmt"
func main() {
var str string = "abc"
// 1
for i := range str {
fmt.Printf("str[%d] = %c \n", i, str[i])
}
// 2
for _, data := range str{ // 忽略 index
fmt.Printf("%c\n", data)
}
// 3
for i, data := range str {
fmt.Printf("str[%d] = %c \n", i, data)
}
}
4.3、跳转语句
4.3.1 break 和 和 continue
在循环里面有两个关键操作 break 和 continue,break 操作是跳出当前循环,continue 是跳过本次循环.
注意:break 可⽤于 for、switch、select,⽽continue 仅能⽤于 for 循环。
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
if i == 2 {
// break // break 操作是跳出当前循环
continue // continue 是跳过本次循环
}
fmt.Println(i)
}
}
4.3.2 goto
用 goto 跳转到必须在当前函数内定义的标签:
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
for {
fmt.Println(i)
goto LABEL
}
}
fmt.Println("This is test")
LABEL:
fmt.Println("It is over")
}
5、函数
5.1、定义格式
在 Go 语言中,函数的基本组成为:关键字 func、函数名、参数列表、返回值、函数体和返回语句。
func FuncName(/*参数列表*/) (o1 type1, o2 type2/*返回类型*/) {
//函数体
return v1, v2 //返回多个值
}
函数定义说明:
- func:函数由关键字 func 开始声明
- FuncName:函数名称,根据约定,函数名首字母小写即为 private,大写即为 public
- 参数列表:函数可以有 0 个或多个参数,参数格式为:变量名 类型,如果有多个参数
通过逗号分隔,不支持默认参数 - 返回类型:
① 上面返回值声明了两个变量名 o1 和 o2(命名返回参数),这个不是必须,可以只有
类型没有变量名
② 如果只有一个返回值且不声明返回值变量,那么你可以省略,包括返回值的括号
③ 如果没有返回值,那么就直接省略最后的返回信息
④ 如果有返回值, 那么必须在函数的内部添加 return 语句
5.2、例子
5.2.1 无参无返回值
func Test() {
a := 20;
fmt.Println("a = ", a)
}
func main() {
Test()
}
5.2.2 有参无返回值
5.2.2.1 普通参数列表
func Test01(v1 int, v2 int) { // 方式1
fmt.Printf("v1 = %d, v2 = %d\n", v1, v2)
}
func Test02(v1, v2 int){ // 方式2,v1、v2都是int类型
fmt.Printf("v1 = %d, v2 = %d\n", v1, v2)
}
func main() {
Test01(10, 20)
Test02(11, 21)
}
5.2.2.2 不定参数列表
1)不定参数类型
不定参数是指函数传入的参数个数为不定数量。为了做到这点,首先需要将函数定于为接受不定参数类型:
// 形如 ... type 格式的类型,为不定参数类型。并且必须是形参中的最后一个参数
func Test(args ...int) {
for _, n := range args { // 遍历参数
fmt.Println(n)
}
}
func main() {
Test()
Test(1)
Test(1, 2, 3, 4)
}
2) 不定参数的传递
func myFunc1(args ...int) {
for _, data := range args {
fmt.Println("data = ", data)
}
}
func myFunc2(agrs ...int) {
for _, data := range agrs {
fmt.Println("data = ", data)
}
}
func Test(args ...int){
// 按原样传递, Test()的参数原封不动传递给 myFunc1
fmt.Println("======test1======")
myFunc1(args ...)
// 把args[0] ~ args[2](不包括args[2]),传递给myFunc2
fmt.Println("======test2======")
myFunc2(args[:2]...)
// 把args[2] 开始(包括本身)到最后的所有元素,传递给myFunc2
fmt.Println("======test3======")
myFunc2(args[2:]...)
}
func main() {
Test(1, 2, 3, 4, 5, 6)
}
5.2.3 无参有返回值
有返回值的函数,必须有明确的终止语句,否则会引发编译错误。
//方式 1
func Test01() int {
return 666
}
//方式 2, 给返回值命名
//官方建议:最好命名返回值,因为不命名返回值,虽然使得代码更加简洁了,但是会造成生成的文档可读性差
func Test02() (value int) {
value = 666
return value // 也可省略 value,直接 return
}
//方式 3 多个返回值
func Test03() (a int, str string) {
a = 666
str = "hello"
return
}
func main() {
v1 := test01()
v2 := test02()
v3, v4 := test03()
fmt.Printf("v1 = %d, v2 = %d, v3 = %d, v4 = %s\n", v1, v2, v3, v4)
}
5.2.4 有参有返回值
求 2 个数的最小值和最大值
func MinAndMax (num1 int, num2 int) (min int, max int) {
if num1 > num2 {
min = num2
max = num1
} else {
min = num1
max = num2
}
return
}
func main() {
min, max := minAndMax(33, 72)
fmt.Printf("min = %d, max = %d \n", min, max)
}
5.3、递归函数
递归指函数可以直接或间接的调用自身。
递归函数通常有相同的结构:一个跳出条件和一个递归体。
所谓跳出条件就是根据传入的参数判断是否需要停止递归,而递归体则是函数自身所做的一些处理。
//实现 1+2+3……+100
//1、通过循环实现
func Test01() (sum int) {
sum = 0
for i := 1; i <= 100; i++ {
sum += i
}
return
}
//2、通过递归实现
func Test02(num int) int {
if num == 1 {
return 1
}
return num + Test02(num - 1)
}
func main() {
fmt.Println("Test01 sum = ", Test01())
fmt.Println("Test02 sum = ", Test02(100))
}
5.4、函数类型
在 Go 语言中,函数也是一种数据类型,我们可以通过 type 来定义它,它的类型就是所有拥有相同的参数,相同的返回值的一种类型。
// 函数也是一种数据类型,通过 type 给一个函数类型起别名
type FuncType func(int, int) int // func 后面没有函数名
func Test(a int, b int, f FuncType) (result int) {
result = f(a, b)
return
}
func Add(a int, b int) (result int) {
result = a + b
return
}
func Minus(a int, b int) (result int) {
result = a - b
return
}
func main() {
addRes := Test(10, 5, Add)
fmt.Println("addRes = ", addRes)
var f FuncType = Minus
fmt.Println("minusRes = ", f(10, 5))
}
5.5、匿名函数与闭包
所谓闭包就是一个函数“捕获”了和它在同一作用域的其它常量和变量。这就意味着当闭包被调用的时候,不管在程序什么地方调用,闭包能够使用这些常量或者变量。它不关心这些捕获了的变量和常量是否已经超出了作用域,所以只有闭包还在使用它,这些变量就还会存在。
在 Go 语言里,所有的匿名函数(Go 语言规范中称之为 函数字面量)都是闭包。
func main() {
i := 0
str := "hello world"
// 方式 1 -- 匿名函数,无参无返回
f1 := func() {
// 引用函数外的变量
fmt.Printf("方式1:i = %d, str = %s \n", i , str)
}
f1() // 函数调用
// 方式 1 的另一种方式,通过函数类型接收
type FuncType func()
var f2 FuncType = f1
f2() // 函数调用
// 方式 2
var f3 FuncType = func() {
fmt.Printf("方式2:i = %d, str = %s \n", i , str)
}
f3()
// 方式 3
func() {
fmt.Printf("方式3:i = %d, str = %s \n", i , str)
} () //别忘了后面的(), ()的作用是,此处直接调用此匿名函数
// 方式 4 -- 有参有返回值
v := func(a, b int) (result int) {
result = a + b
return
} (5, 10) //别忘了后面的(1, 1), (1, 1)的作用是,此处直接调用此匿名函数,并传参数
fmt.Println("v = ", v)
}
闭包捕获外部变量特点:
func main() {
i := 0
str := "hello world"
func() {
// 闭包以引用方式捕获外部变量
i = 10
str = "bey bey"
fmt.Printf("i = %d, str = %s \n", i , str)
} ()
fmt.Printf("i = %d, str = %s \n", i , str)
}
// i = 10, str = bey bey
// i = 10, str = bey bey
函数返回值为匿名函数:
// 返回一个匿名函数类型 func() int
func squares() func() int {
var x int
return func() int { // 返回匿名函数
x++ // 捕获外部变量
return x * x
}
}
func main() {
f := squares()
fmt.Println(f())
fmt.Println(f())
fmt.Println(f())
fmt.Println(f())
fmt.Println(f())
}
函数 squares 返回另一个类型为func() int的函数。对 squares 的一次调用会生成一个局部变量 x 并返回一个匿名函数。每次调用时匿名函数时,该函数都会先使 x 的值加 1,再返回 x的平方。第二次调用 squares 时,会生成第二个 x 变量,并返回一个新的匿名函数。新匿名函数操作的是第二个 x 变量。
通过这个例子,我们看到变量的生命周期不由它的作用域决定:squares 返回后,变量 x 仍然隐式的存在于 f 中。它不关心这些捕获了的变量和常量是否已经超出了作用域,所以只有闭包还在使用它,这些变量就还会存在。
5.6、延迟调用 defer
5.6.1 defer 作用
关键字 defer ⽤于延迟一个函数或者方法(或者当前所创建的匿名函数)的执行。注意,defer语句只能出现在函数或方法的内部。
func main() {
defer fmt.Println("This is 1") //main 结束前调用
fmt.Println("This is 2")
}
/*
This is 2
This is 1
*/
defer 语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。通过defer 机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。释放资源的 defer应该直接跟在请求资源的语句后。
5.6.2 多个 defer 执行顺序
如果一个函数中有多个 defer 语句,它们会以 LIFO(后进先出)的顺序执行。哪怕函数或某个延迟调用发生错误,这些调用依旧会被执行。
func Test(x int) {
fmt.Println(100 / x) // x = 0 时,产生错误
}
func main() {
defer fmt.Println("aaaa")
defer fmt.Println("bbbb")
defer Test(0)
defer fmt.Println("ccc")
}
/*
ccc
bbbb
aaaa
panic: runtime error: integer divide by zero
*/
5.6.3 defer 和匿名函数结合使用
func main() {
a := 10
b := 20
defer func() {
fmt.Printf("a = %d, b = %d \n", a, b)
} ()
a = 111
b = 222
fmt.Printf("外部:a = %d, b = %d \n", a, b)
}
/*
外部:a = 111, b = 222
a = 111, b = 222
*/
func main() {
a := 10
b := 20
defer func(a, b int) {
fmt.Printf("a = %d, b = %d \n", a, b)
} (a, b) // 有参数的匿名函数,是已经先传递了参数,只是没有调用。相当于已经传入了 (10, 20)
a = 111
b = 222
fmt.Printf("外部:a = %d, b = %d \n", a, b)
}
/*
外部:a = 111, b = 222
a = 10, b = 20
*/
5.7、获取命令行参数
package main
import (
"fmt"
"os"
)
func main() {
args := os.Args // 获取用户输入的所有参数
// 如果用户没有输入,或者参数个数不够,则调用该函数提示用户
if args == nil || len(args) < 2 {
fmt.Println("err: xxx ip port")
return
}
ip := args[1] // 获取输入的第一个参数
port := args[2] // 获取输入的第二个参数
fmt.Printf("ip = %s, port = %s\n", ip, port)
}
/*
输入:go run hello.go 127.0.0.1 8888
输出:ip = 127.0.0.1, port = 8888
*/
5.8、作用域
作用域为已声明标识符所表示的常量、类型、变量、函数或包在源代码中的作用范围。
5.8.1 局部变量
在函数体内声明的变量、参数和返回值变量就是局部变量,它们的作用域只在函数体内:
func test(a, b int) {
var c int
a, b, c = 1, 2, 3
fmt.Printf("a = %d, b = %d, c = %d", a, b, c)
}
func main() {
// a, b, c = 3, 2, 1 // error:a,b,c 不属于此作用域
{
var i int
i = 10
fmt.Printf("i = %d\n", i)
}
// i = 20 // error:i 不属于此作用域
if a := 3; a == 3 {
fmt.Println("a = ", a)
}
// a = 4 // error:a只能在if内部使用
}
5.8.2 全局变量
在函数体外声明的变量称之为全局变量,全局变量可以在整个包甚至外部包(被导出后)使用。
var a int // 全部变量的声明
func test() {
fmt.Printf("a = %d\n", a)
}
func main() {
a = 10
fmt.Printf("main a = %d\n", a)
test()
}
/*
main a = 10
a = 10
*/
5.8.3 不同作用域同名变量
在不同作用域可以声明同名的变量,其访问原则为:在同一个作用域内,就近原则访问最近的变量,如果此作用域没有此变量声明,则访问全局变量,如果全局变量也没有,则报错。
var a int
func test01(a float32) {
fmt.Printf("a type = %T\n", a) // a type = float32
}
func test02() {
fmt.Printf("a type = %T\n", a) // a type = int
}
func main() {
fmt.Printf("a type = %T\n", a) // a type = int
var a uint8
{
var a float64
fmt.Printf("a type = %T\n", a) // a type = float64
}
fmt.Printf("a type = %T\n", a) // a type = uint8
test01(3.14)
test02()
}
/*
a type = int
a type = float64
a type = uint8
a type = float32
a type = int
*/
6、工程管理
在实际的开发工作中,直接调用编译器进行编译和链接的场景是少而又少,因为在工程中不会简单到只有一个源代码文件,且源文件之间会有相互的依赖关系。Go 命令行工具完全用目录结构和包名来推导工程结构和构建顺序。
6.1、工作区
6.1.1 工作区介绍
Go 代码必须放在工作区中。工作区其实就是一个对应于特定工程的目录,它应包含 3 个子目录:src 目录、pkg 目录和 bin 目录。
- src 目录:用于以代码包的形式组织并保存 Go 源码文件。(比如:.go .c .h .s 等)
- pkg 目录:用于存放经由 go install 命令构建安装后的代码包(包含 Go 库源码文件)的“.a”归档文件。
- bin 目录:与 pkg 目录类似,在通过 go install 命令完成安装后,保存由 Go 命令源码文
件生成的可执行文件。
6.2、包
所有 Go 语言的程序都会组织成若干组文件,每组文件被称为一个包。这样每个包的代码都可以作为很小的复用单元,被其他项目引用。
一个包的源代码保存在一个或多个以.go 为文件后缀名的源文件中,通常一个包所在目录路径的后缀是包的导入路径。
6.2.1 自定义包
对于一个较大的应用程序,我们应该将它的功能性分隔成逻辑的单元,分别在不同的包里实现。我们创建的的自定义包最好放在 GOPATH 的 src 目录下(或者 GOPATH src 的某个子
目录)。
在 Go 语言中,代码包中的源码文件名可以是任意的。但是,这些任意名称的源码文件都必须以包声明语句作为文件中的第一行,每个包都对应一个独立的名字空间:
package calc
包中成员以名称首字母大小写决定访问权限
- public: 首字母大写,可被包外访问
- private: 首字母小写,仅包内成员可以访问
注意:同一个目录下不能定义不同的 package。
6.2.2 main 包
在 Go 语言里,命名为 main 的包具有特殊的含义。 Go 语言的编译程序会试图把这种名字的包编译为二进制可执行文件。所有用 Go 语言编译的可执行程序都必须有一个名叫 main的包。一个可执行程序有且仅有一个 main 包。
当编译器发现某个包的名字为 main 时,它一定也会发现名为 main()的函数,否则不会创建可执行文件。 main()函数是程序的入口,所以,如果没有这个函数,程序就没有办法开始执行。程序编译时,会使用声明 main 包的代码所在的目录的目录名作为二进制可执行文件的文件名。
6.2.3 main 函数和 init 函数
Go里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。这两个函数在定义时不能有任何的参数和返回值。虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
Go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package main就必须包含一个main函数。
每个包可以包含任意多个 init 函数,这些函数都会在程序执行开始的时候被调用。所有被
编译器发现的 init 函数都会安排在 main 函数之前执行。 init 函数用在设置包、初始化变量或者其他要在程序运行前优先完成的引导工作。
程序的初始化和执行都起始于main包。如果main包还导入了其它的包,那么就会在编译时将它们依次导入。
有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。
当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:
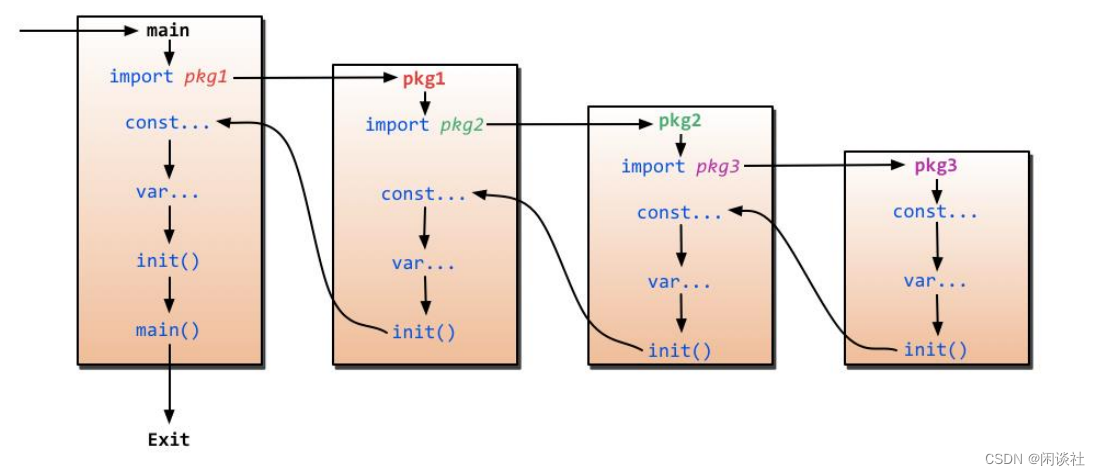
6.2.4 导入包
导入包需要使用关键字import,它会告诉编译器你想引用该位置的包内的代码。包的路径可以是相对路径,也可以是绝对路径。
//方法1
import "calc"
import "fmt"
//方法2
import (
"calc"
"fmt"
)
6.2.4.1 点操作
点操作的含义是这个包导入之后在你调用这个包的函数时,可以省略前缀的包名。
注意:这种方法不推荐
package main
import (
. "fmt" // 点操作
)
func main() {
Println("This is test")
}
6.2.4.2 别名操作
在导⼊时,可指定包成员访问⽅式,⽐如对包重命名,以避免同名冲突:
import (
io "fmt"
)
func main() {
io.Println("This is test")
}
6.2.4.3 _操作
有时,用户可能需要导入一个包,但是不需要引用这个包的标识符。在这种情况,可以使用空白标识符_来重命名这个导入:
import (
_ "fmt"
)
_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数。
6.3、工程管理的例子
因为Go的改进,不用传统配置GOPATH方式而是使用Go mod进行工程管理。
GOPATH配置资料很多,就不过多介绍。
Go.mod是Golang1.11版本新引入的官方包管理工具用于解决之前没有地方记录依赖包具体版本的问题,方便依赖包的管理。
Go.mod其实就是一个Modules,关于Modules的官方定义为:
Modules是相关Go包的集合,是源代码交换和版本控制的单元。go命令直接支持使用Modules,包括记录和解析对其他模块的依赖性。Modules替换旧的基于GOPATH的方法,来指定使用哪些源文件。
Modules和传统的GOPATH不同,不需要包含例如src,bin这样的子目录,一个源代码目录甚至是空目录都可以作为Modules,只要其中包含有go.mod文件。
6.3.1 同模块同目录同包
1、目录结构
目录dir:
- 文件a.go
- 文件b.go
2、操作
1)命令执行
cd dir
go mod init modu
这个命令用于在当前目录下初始化一个新的 Go 模块。在这个命令中,go mod 是指示 Go 工具链进行模块管理的命令前缀,init 是告诉 Go 工具链要初始化一个新模块的指令,而 modu 则是新模块的名称。
执行该命令后,Go 工具链将会在当前目录下创建一个新的 go.mod 文件,该文件包含了模块的基本信息以及依赖项管理等相关信息。这样就可以利用 Go 模块的特性来管理项目的依赖关系了。
2)编写文件 b.go
package main
import "fmt"
// 同包中,函数名首字母无需大写指定公有访问权限
func test() {
fmt.Println("This is b")
}
3)编写文件 a.go
package main
// 同包中,无需导入路径
import "fmt"
func main() {
fmt.Println("This is a")
// 同包中,可以直接调用相应函数
test()
}
4)命令行执行:
# 方式1
go run a.go b.go
# 方式2
go run .
3、总结
- 同模块:使用
go mod init初始化一个模块,模块名为modu - 同目录:多个go文件在同一目录下
- 同包:多个go文件在同包,包名为main
文件名为a.go,b.go,函数名为test。
同包中,函数名首字母无需大写指定公有访问权限。
无需导入路径,可直接调用相应函数。
6.3.2 同模块不同目录不同包
1、目录结构
目录dir:
- 文件a.go
- 目录dir_b
目录dir_b:
- 文件b.go
2、操作
1)编写文件b.go:
package pkg_b
import "fmt"
// 不同包中,函数名首字母需大写指定公有访问权限
func Test() {
fmt.Println("This is b")
}
2)命令行执行:
cd dir
go mod init modu
3)编写文件a.go:
package main
import (
"fmt"
"modu/dir_b" // 当前模块名/目录名
)
/*
格式:当前模块名/目录名
实际上,import是导入路径,而不是导入包名。所以是dir_b而不是pkg_b
奇怪的引用方式,应该把包名命名为目录名才能统一,不过一般同一目录下是同一个包,命名相同。
这里为了突显导入格式,目录名和包名命名不同
*/
func main() {
fmt.Println("This is a")
pkg_b.Test() // 使用函数需要用包名引用
}
4)命令行执行:
# 方式一
go run .
# 方式二
go run a.go
3、总结
- 同模块:使用
go mod init初始化一个模块,模块名为modu - 不同目录:多个go文件在不同一目录下,目录名为dir和dir_b
- 不同包:多个go文件在不同包,包名为main和pkg_b
文件名为a.go,b.go,函数名为Test。
不同包中,函数名首字母需大写指定公有访问权限。
导入依赖包路径的形式:import 当前模块名/目录名
使用依赖函数的形式:包名.函数名()
6.3.3 不同模块不同目录不同包1
1、目录结构
目录dir:
- 文件a.go
- 目录dir_b
目录dir_b:
- 文件b.go
2、操作
1)编写文件b.go:
package pkg_b
import "fmt"
// 不同包中,函数名首字母需大写指定公有访问权限
func Test() {
fmt.Println("This is b")
}
2)命令行执行:
cd dir_b
go mod init modu_b
3)命令行执行:
cd dir
go mod init modu
4)修改dir下的go.mod文件:
module modu
go 1.20
require modu_b v0.0.0 // 需要用的模块名,版本
replace modu_b => D:\go\dir_b // 指定查找路径,导入该模块实际上是导入该路径
5)编写a.go
package main
import (
"fmt"
"modu_b" // 需要用的模块名
)
func main() {
fmt.Println("This is a")
pkg_b.Test() // 使用函数需要用包名引用
}
5)命令行执行:
cd dir
# 方式一
go run .
# 方式二
go run a.go
3、总结
- 不同模块:使用
go mod init初始化多个模块,模块名为modu和modu_b - 不同目录:多个go文件在不同一目录下,目录名为dir和dir_b
- 不同包:多个go文件在不同包,包名为main和pkg_b
文件名为a.go,b.go,函数名为Test。
不同包中,函数名首字母需大写指定公有访问权限,使用函数需要用包名引用。
导入依赖模块路径的形式:import 模块名。
使用依赖函数的形式:包名.函数名()。
6.3.4 不同模块不同目录不同包2 – go work
上面的方法有个很明显的缺陷,就是如果把代码包发给别人,需要同步修改go.mod中的replace 。
Go 1.18引入的工作区模式,可以让你不用修改每个Go Module的go.mod,就能同时跨多个Go Module进行开发。
1、目录结构
目录dir:
- 目录dir_a
- 目录dir_b
目录dir_a:
- 文件a.go
目录dir_b:
- 文件b.go
2、操作
1)编写文件b.go:
package pkg_b
import "fmt"
// 不同包中,函数名首字母需大写指定公有访问权限
func Test() {
fmt.Println("This is b")
}
2)命令行执行:
cd dir_b
go mod init modu_b
3)编写a.go
package main
import (
"fmt"
"modu_b" // 需要用的模块名
)
func main() {
fmt.Println("This is a")
pkg_b.Test() // 使用函数需要用包名引用
}
4)命令行执行:
cd dir_a
go mod init modu_a
5)修改dir_a下的go.mod文件:
module modu_a
go 1.20
6)命令行执行:
// 回到主目录
cd ..
// 创建一个workspace,go.work里列出了该workspace需要用到的Go Module所在的目录
go work init dir_a
//给workspace新增Go Module,可以用go work use,或者第7)步的手动修改
go work use dir_b
7)手动修改dir下的go.work文件:
go 1.20
use (
./dir_a
./dir_b
)
8)命令行执行:
cd dir_a
go run a.go
3、总结
- 不同模块:使用
go mod init初始化多个模块,模块名为modu_a和modu_b - 不同目录:多个go文件在不同一目录下,目录名为dir_a和dir_b
- 不同包:多个go文件在不同包,包名为main和pkg_b
7、复合类型
7.1、分类
| 类型 | 名称 | 长度 | 默认值 | 说明 |
|---|---|---|---|---|
| pointer | 指针 | nil | ||
| array | 数组 | 0 | ||
| slice | 切片 | nil | 引⽤类型 | |
| map | 字典 | nil | 引⽤类型 | |
| struct | 结构体 |
7.2、指针
指针是一个代表着某个内存地址的值。这个内存地址往往是在内存中存储的另一个变量的值的起始位置。Go语言对指针的支持介于Java语言和C/C++语言之间,它既没有想Java语言那样取消了代码对指针的直接操作的能力,也避免了C/C++语言中由于对指针的滥用而造成的安全和可靠性问题。
7.2.1 基本操作
Go语言虽然保留了指针,但与其它编程语言不同的是:
- 默认值
nil,没有NULL常量 - 操作符
&取变量地址,*通过指针访问目标对象 - 不支持指针运算,不支持
->运算符,直接用.访问目标成员
func main() {
var a int = 10
fmt.Printf("&a = %p\n", &a) // & 取地址
var p *int = nil // 声明一个变量p,类型为 *int,指针类型
p = &a
fmt.Printf("p = %p\n", p)
fmt.Printf("a = %d, *p = %d\n", a, *p)
*p = 20 // *p操作指针所指向的内存,即为a
fmt.Printf("a = %d, *p = %d\n", a, *p)
}
/*
&a = 0xc000018098
p = 0xc000018098
a = 10, *p = 10
a = 20, *p = 20
*/
7.2.2 new函数
表达式new(T)将创建一个T类型的匿名变量,所做的是为T类型的新值分配并清零一块内存空间,然后将这块内存空间的地址作为结果返回,而这个结果就是指向这个新的T类型值的指针值,返回的指针类型为*T。
func main() {
var p1 *int = new(int)
fmt.Println("p1 = ", *p1) // *p1 = 0
p2 := new(int)
*p2 = 11
fmt.Println("p2 = ", *p2) // *p2 = 11
}
我们只需使用new()函数,无需担心其内存的生命周期或怎样将其删除,因为Go语言的内存管理系统会帮我们打理一切。
7.2.3 指针做函数参数
func swap01(a, b int) {
a, b = b, a
}
func swap02(x, y *int) {
*x, *y = *y, *x
}
func main() {
a := 10
b := 20
// swap01(a, b) // 值传递 a = 10, b = 20
swap02(&a, &b) // 地址传递 a = 20, b = 10
fmt.Printf("a = %d, b = %d\n", a, b)
}
7.3、数组
7.3.1 概述
数组是指一系列同一类型数据的集合。数组中包含的每个数据被称为数组元素(element),一个数组包含的元素个数被称为数组的长度。
数组长度必须是常量,且是类型的组成部分。 [2]int 和 [3]int 是不同类型。
var n int = 10
var a [n]int //err, non-constant array bound n
var b [10]int //ok
7.3.2 操作数组
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。
func main() {
var a [10]int
// 方式1
for i := 0; i < 10; i++ {
a[i] = i + 1
fmt.Printf("a[%d] = %d \n", i, a[i])
}
// 方式2
for i, data := range a {
fmt.Printf("a[%d] = %d \n", i, data)
}
}
内置函数 len(长度) 和 cap(容量) 都返回数组⻓度 (元素数量):
a := [10]int{}
fmt.Println(len(a), cap(a))//10 10
初始化:
func main() {
a := [3]int{1, 2} // 未初始化元素值为 0
fmt.Println("数组a:", a)
b := [...]int{1, 2, 3} // 通过初始化值确定数组长度
fmt.Println("数组b:", b)
c := [5]int{2: 100, 4: 200} // 通过索引号初始化元素,将索引为2的位置赋值为100,将索引为4的位置赋值为200
fmt.Println("数组c:", c)
}
/*
数组a: [1 2 0]
数组b: [1 2 3]
数组c: [0 0 100 0 200]
*/
多维数组
func main() {
d := [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
fmt.Println("数组d:", d)
e := [...][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}} //第二维不能写"..."
fmt.Println("数组e:", e)
f := [4][2]int{1: {20, 21}, 3: {40, 41}}
fmt.Println("数组f:", f)
g := [4][2]int{1: {0: 20}, 3: {1: 41}}
fmt.Println("数组g:", g)
}
/*
数组d: [[10 11] [20 21] [30 31] [40 41]]
数组e: [[10 11] [20 21] [30 31] [40 41]]
数组f: [[0 0] [20 21] [0 0] [40 41]]
数组g: [[0 0] [20 0] [0 0] [0 41]]
*/
相同类型的数组之间可以使用 == 或 != 进行比较,但不可以使用 < 或 >,也可以相互赋值:
a := [3]int{1, 2, 3}
b := [3]int{1, 2, 3}
c := [3]int{1, 2}
fmt.Println(a == b, b == c) //true false
var d [3]int
d = a
fmt.Println(d) //[1 2 3]
7.3.3 在函数间传递数组
根据内存和性能来看,在函数间传递数组是一个开销很大的操作。在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。
func modify(array [5]int) {
array[0] = 10
fmt.Println("In modify, array = ",array)
}
func main() {
array := [5]int{1, 2, 3, 4, 5}
modify(array)
fmt.Println("In main, array = ",array)
}
/*
In modify, array = [10 2 3 4 5]
In main, array = [1 2 3 4 5]
*/
数组指针做函数参数:
func modify(array *[5]int) {
(*array)[0] = 10
fmt.Println("In modify, array = ",*array)
}
func main() {
array := [5]int{1, 2, 3, 4, 5}
modify(&array) // 数组指针
fmt.Println("In main, array = ",array)
}
/*
In modify, array = [10 2 3 4 5]
In main, array = [10 2 3 4 5]
*/
7.3.4 产生随机数
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
// // rand.Seed is deprecated
// rand.Seed(time.Now().UnixMilli())
// for i := 0; i < 5; i++ {
// fmt.Println("rand = ", rand.Intn(100))
// }
// 以当前系统时间作为种子参数
r := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < 5; i++ {
fmt.Println("rand = ", r.Intn(100)) // 产生100以内的随机数
}
}
7.3.4 冒泡排序
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
r := rand.New(rand.NewSource(time.Now().UnixMilli()))
var array [10]int
n := len(array)
for i := 0; i < n; i++ {
array[i] = r.Intn(100)
}
fmt.Println("排序前:",array)
for i := 0; i < n; i++ {
for j := 0; j < n - 1 - i; j++ {
if array[j] > array[j + 1] {
array[j], array[j + 1] = array[j + 1], array[j]
}
}
}
fmt.Println("排序后:", array)
}
7.4、切片slice
7.4.1 概述
数组的长度在定义之后无法再次修改;数组是值类型,每次传递都将产生一份副本。显然这种数据结构无法完全满足开发者的真实需求。Go语言提供了数组切片(slice)来弥补数组的不足。
切片并不是数组或数组指针,它通过内部指针和相关属性引⽤数组⽚段,以实现变⻓⽅案。
slice并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array,slice的声明也可以像array一样,只是不需要长度。
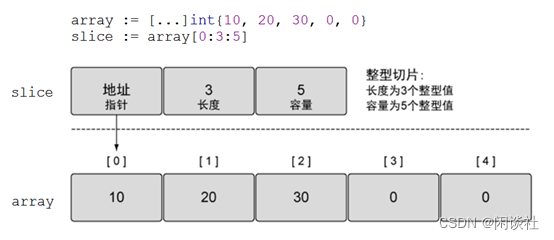
func main() {
array := [5]int{1, 2, 3, 4, 5}
slice := array[1:3:5] // 取 [array[1], array[3]),左闭右开。最大容量为5
fmt.Println("slice:", slice)
fmt.Println("slice's len:", len(slice)) // 长度为 5 - 3
fmt.Println("slice's cap:", cap(slice)) // 容量为 5 - 1
}
/*
slice: [2 3]
slice's len: 2
slice's cap: 4
*/
7.4.2 切片的创建和初始化
slice和数组的区别:声明数组时,方括号内写明了数组的长度或使用...自动计算长度,而声明slice时,方括号内没有任何字符。
func main() {
// 数组[]里面的长度时固定的一个常量,数组不能修改长度, len和cap永远都是5
array := [5]int{}
fmt.Printf("len = %d, cap = %d\n", len(array), cap(array)) // 5 5
//切片, []里面为空,或者为...,切片的长度或容易可以不固定
s := []int{}
fmt.Printf("len = %d, cap = %d\n", len(s), cap(s)) // 0 0
s = append(s, 11) //给切片末尾追加一个成员
fmt.Printf("len = %d, cap = %d\n", len(s), cap(s)) // 1 1
}
切片的初始化方式
(切片的长度就是它所包含的元素个数,切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。)
func main() {
// 初始化方式
// 方式 1,自动推到类型,同时初始化
s1 := []int{1, 2, 3, 4}
fmt.Println("s1 = ", s1)
// 方式 2,借助make函数,格式:make(切片类型, 长度, 容量)
s2 := make([]int, 3, 5)
fmt.Printf("len = %d, cap = %d\n", len(s2), cap(s2))
// 方式 3,make不指定容量,则容量和长度一样
s3 := make([]int, 3)
fmt.Printf("len = %d, cap = %d\n", len(s3), cap(s3))
}
/*
s1 = [1 2 3 4]
len = 3, cap = 5
len = 3, cap = 3
*/
7.4.3 切片的操作
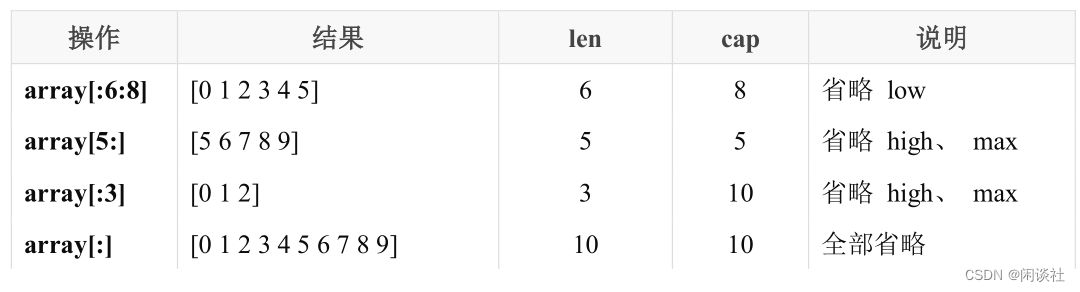
7.4.3.1 切片截取
| 操作 | 含义 |
|---|---|
| s[n] | 切片s中索引位置为n的项 |
| s[:] | 从切片s的索引位置0到len(s)-1处所获得的切片 |
| s[low:] | 从切片s的索引位置low到len(s)-1处所获得的切片 |
| s[:high] | 从切片s的索引位置0到high处所获得的切片,len=high |
| s[low:high] | 从切片s的索引位置low到high处所获得的切片,len=high-low |
| s[low:high:max] | 从切片s的索引位置low到high处所获得的切片,len=high-low,cap=max-low |
| len(s) | 切片s的长度,总是<=cap(s) |
| cap(s) | 切片s的容量,总是>=len(s) |
示例说明:
array := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
7.4.3.2 切片和底层数组关系
func main() {
s := []int{0,1,2,3,4,5,6,7,8,9}
s1 := s[2:5] //[2 3 4]
s1[2] = 100 //修改切片某个元素改变底层数组
fmt.Println(s1) //[2 3 100]
fmt.Println(s) //[0 1 2 3 100 5 6 7 8 9]
s2 := s1[2:6] // 新切片依旧指向原底层数组,取[s1[2], s1[6]) = [100,5,6,7]
s2[3] = 200
fmt.Println(s2) //[100 5 6 200]
fmt.Println(s) //[0 1 2 3 100 5 6 200 8 9]
}
7.4.3.3 内建函数
1) append
append函数向 slice 尾部添加数据,返回新的 slice 对象:
func main() {
s1 := []int{}
s1 = append(s1, 1) // 追加一个元素
fmt.Println("s1 = ", s1) // s1 = [1]
s1 = append(s1, 2, 3) // 追加两个元素
fmt.Println("s1 = ", s1) // s1 = [1 2 3]
s2 := make([]int, 3)
s2 = append(s2, 8, 9)
fmt.Println("s2 = ", s2) // s2 = [0 0 0 8 9]
}
append函数会智能地底层数组的容量增长,一旦超过原底层数组容量,通常以2倍容量重新分配底层数组,并复制原来的数据:
func main() {
s := make([]int, 0, 1)
oldCap := cap(s)
for i := 0; i < 20; i++ {
s = append(s, i)
if newCap := cap(s); oldCap < newCap {
fmt.Printf("cap: %d ==> %d\n", oldCap, newCap)
oldCap = newCap
}
}
}
/*
cap: 1 ==> 2
cap: 2 ==> 4
cap: 4 ==> 8
cap: 8 ==> 16
cap: 16 ==> 32
*/
2) copy
函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准,两个 slice 可指向同一底层数组。
copy(dst, src),把源 src 拷贝给目的 dst
func main() {
data := []int{0,1,2,3,4,5,6,7,8,9}
s1 := data[8:] // [8,9]
s2 := data[:5] // [0,1,2,3,4]
copy(s2, s1) // copy(dst, src) ,把源 src 拷贝给目的 dst
fmt.Println("s2 = ", s2) // s2 = [8 9 2 3 4]
fmt.Println("data = ", data) // data = [8 9 2 3 4 5 6 7 8 9]
}
7.4.4 切片做函数参数
切片做函数参数传递是引用传递
package main
import (
"fmt"
"math/rand"
"time"
)
func InitData(s []int){
r := rand.New(rand.NewSource(time.Now().UnixMilli()))
for i := 0; i < len(s); i++ {
s[i] = r.Intn(100)
}
}
func bubbleSort(s []int) {
n := len(s)
for i := 0; i < n; i++ {
for j := 0; j < n - i - 1; j++ {
if s[j] > s[j + 1] {
s[j], s[j + 1] = s[j + 1], s[j]
}
}
}
}
func main() {
n := 10
s := make([]int, n)
InitData(s)
fmt.Println("排序前:s = ", s)
bubbleSort(s)
fmt.Println("排序后:s = ", s)
}
/*
排序前:s = [43 34 79 99 42 86 18 3 14 60]
排序后:s = [3 14 18 34 42 43 60 79 86 99]
*/
7.5、map
7.5.1 概述
Go语言中的map(映射、字典)是一种内置的数据结构,它是一个无序的key—value对的集合,比如以身份证号作为唯一键来标识一个人的信息。
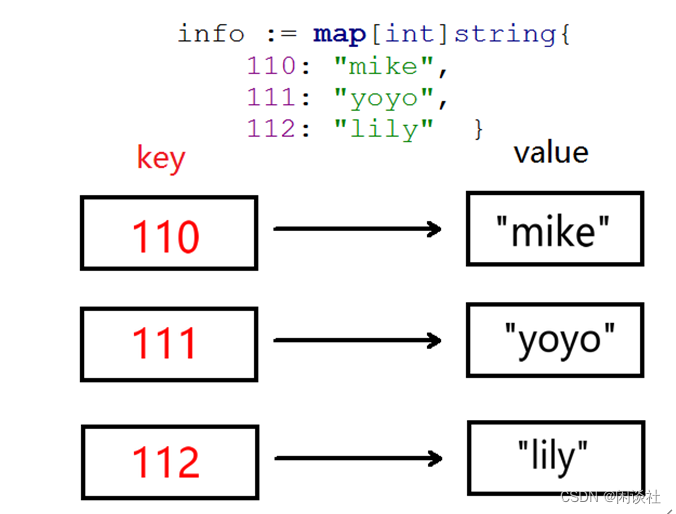
map格式为:map[keyType]valueType
在一个map里所有的键都是唯一的,而且必须是支持==和!=操作符的类型,切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的键,使用这些类型会造成编译错误:
dict := map[ []string ]int{} //err, invalid map key type []string
map值可以是任意类型,没有限制。
注意:map是无序的,我们无法决定它的返回顺序,所以,每次打印结果的顺利有可能不同。
7.5.2 创建和初始化
7.5.2.1 map的创建
func main() {
// 定义一个变量,类型为map[int]string
var m1 map[int]string
fmt.Println("m1 = ", m1)
// 对于map只有len,没有cap
fmt.Println("len = ", len(m1))
// 通过make创建,可以指定长度。但一开始里面没有数据
m2 := make(map[int]string, 3)
fmt.Println("m2 = ", m2)
fmt.Println("len = ", len(m2))
m2[1] = "zxm"
m2[2] = "27"
m2[3] = "man"
fmt.Println("m2 = ", m2)
fmt.Println("len = ", len(m2))
}
/*
m1 = map[]
len = 0
m2 = map[]
len = 0
m2 = map[1:zxm 2:27 3:man]
len = 3
*/
7.5.2.2 初始化
func main() {
// 1、定义同时初始化
var m1 map[int]string = map[int]string{1: "zxm", 2: "28", 3: "man"}
fmt.Println("m1 = ", m1)
// 2、自动推到类型
m2 := map[int]string{1: "zxm", 2: "28", 3: "man"}
fmt.Println("m2 = ", m2)
}
7.5.3 常用操作
7.5.3.1 赋值
func main() {
m1 := map[int]string{1: "zxm", 2: "28", 3: "man"}
m1[1] = "xjp" // 修改
m1[4] = "happy" // 追加,go底层会自动为map分配空间
fmt.Println("m1 = ", m1) // m1 = map[1:xjp 2:28 3:man 4:happy]
}
7.5.3.2 遍历
func main() {
m1 := map[int]string{1: "zxm", 2: "28", 3: "man"}
// 迭代遍历 1
for k, v := range m1 {
fmt.Printf("%d: %s\n", k, v)
}
// 迭代遍历 2
for k := range m1 {
fmt.Printf("%d: %s\n", k, m1[k])
}
// 判断某个key所对应的value是否存在, 第一个返回值是value(如果存在的话)
value, ok := m1[1]
fmt.Printf("value = %s, ok = %t\n", value, ok) // value = zxm, ok = true
value2, ok2 := m1[5]
fmt.Printf("value2 = %s, ok2 = %t\n", value2, ok2) // value2 = , ok2 = false
}
7.5.3.3 删除
func main() {
m1 := map[int]string{1: "zxm", 2: "28", 3: "man"}
fmt.Println("删除前")
for key, value := range m1 {
fmt.Printf("%d: %s\n", key, value)
}
delete(m1,2) // 删除key值为2的map
fmt.Println("删除后")
for key, value := range m1 {
fmt.Printf("%d: %s\n", key, value)
}
}
7.5.4 map做函数参数
在函数间传递映射并不会制造出该映射的一个副本,不是值传递,而是引用传递:
func DeleteMap(m map[int]string, key int) {
delete(m, key)
}
func main() {
m1 := map[int]string{1: "zxm", 2: "28", 3: "man"}
fmt.Println("删除前")
for key, value := range m1 {
fmt.Printf("%d: %s\n", key, value)
}
DeleteMap(m1,2)
fmt.Println("删除后")
for key, value := range m1 {
fmt.Printf("%d: %s\n", key, value)
}
}
7.6、结构体
7.6.1 结构体类型
有时我们需要将不同类型的数据组合成一个有机的整体

结构体是一种聚合的数据类型,它是由一系列具有相同类型或不同类型的数据构成的数据集合。每个数据称为结构体的成员。
7.6.2 结构体初始化
7.6.2.1 普通变量
type Student struct {
id int
name string
sex byte
age int
addr string
}
func main() {
// 1、顺序初始化,必须每个成员都初始化
var s1 Student = Student{1, "zxm", 'm', 18, "M78星云"}
s2 := Student{2, "gq", 'w', 17, "奥特星云"}
// s3 := Student{2, "tom", 'm', 20} //err, too few values in struct initializer
// 2、指定初始化某个成员,没有初始化的成员为零值
s4 := Student{id: 2, name: "lily"}
fmt.Println("s1 = ", s1)
fmt.Println("s2 = ", s2)
fmt.Println("s4 = ", s4)
}
/*
s1 = {1 zxm 109 18 M78星云}
s2 = {2 gq 119 17 奥特星云}
s4 = {2 lily 0 0 }
*/
7.6.2.2 指针变量
func main() {
var s5 *Student = &Student{1, "zxm", 'm', 18, "M78星云"}
s6 := &Student{2, "gq", 'w', 17, "奥特星云"}
fmt.Println("s5 = ", *s5)
fmt.Println("s6 = ", *s6)
}
7.6.3 结构体成员的使用
7.6.3.1 普通变量
func main() {
// 1、打印成员
var s1 Student = Student{1, "zxm", 'm', 18, "M78星云"}
fmt.Printf("id = %d, name = %s, sex = %c, age = %d, addr = %s \n", s1.id, s1.name, s1.sex, s1.age,s1.addr)
// 2、成员变量赋值
var s2 Student
s2.id = 2
s2.name = "guoqin"
s2.sex = 'w'
s2.age = 18
s2.addr = "奥特星云"
fmt.Println("s2 = ", s2)
}
7.6.3.2 指针变量
type Student struct {
id int
name string
sex byte
age int
addr string
}
func main() {
// 1、先分配空间,再赋值
s3 := new(Student)
s3.id = 3
s3.name = "guoq,"
fmt.Println("s3 = ", s3)
// 2、普通变量和指针变量类型打印
var s4 Student
var p *Student = &s4
// p.成员 和(*p).成员 操作是等价的
p.id = 5
(*p).name = "zzz"
p.sex = 'm'
p.age = 18
p.addr = "地球"
fmt.Println(p, *p, s4)
}
/*
s3 = &{3 guoq, 0 0 }
&{5 zzz 109 18 地球} {5 zzz 109 18 地球} {5 zzz 109 18 地球}
*/
7.6.4 结构体比较
如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用==或!=运算符进行比较,但不支持 > 或 < 。
type Student struct {
id int
name string
sex byte
age int
addr string
}
func main() {
s1 := Student{1, "mike", 'm', 18, "sz"}
s2 := Student{1, "mike", 'm', 18, "sz"}
fmt.Println("s1 == s2", s1 == s2) //s1 == s2 true
fmt.Println("s1 != s2", s1 != s2) //s1 != s2 false
}
7.6.5 结构体作为函数参数
7.6.5.1 值传递
type Student struct {
id int
name string
sex byte
age int
addr string
}
func PrintStudentValue(data Student) {
data.age = 25000
fmt.Println("PrintStudentValue data = ", data) // PrintStudentValue data = {1 mike 109 25000 sz}
}
func main() {
s1 := Student{1, "mike", 'm', 18, "sz"}
PrintStudentValue(s1) // 值传递,形参的修改不会影响到实参
fmt.Println("main s1 = ", s1) // main s1 = {1 mike 109 18 sz}
}
7.6.5.2 引用传递
func PrintStudentValue(data *Student) {
data.age = 25000
fmt.Println("PrintStudentValue data = ", *data) // PrintStudentValue data = {1 mike 109 25000 sz}
}
func main() {
s1 := Student{1, "mike", 'm', 18, "sz"}
PrintStudentValue(&s1) // 引用(地址)传递,形参的修改会影响到实参
fmt.Println("main s1 = ", s1) // main s1 = {1 mike 109 25000 sz}
}
7.6.6 可见性
Go语言对关键字的增加非常吝啬,其中没有private、 protected、 public这样的关键字。
要使某个符号对其他包(package)可见(即可以访问),需要将该符号定义为以大写字母
开头。
1、目录结构
目录dir:
- 文件a.go
- 目录dir_b
目录dir_b:
- 文件b.go
2、操作
1)编写文件b.go:
package pkg_b
//student01只能在本文件件引用,因为首字母小写
type student01 struct {
Id int
Name string
}
//Student02可以在任意文件引用,因为首字母大写
type Student02 struct {
Id int
name string
}
2)命令行执行:
cd dir
go mod init modu
3)编写文件a.go:
package main
import (
"fmt"
"modu/dir_b"
)
func main() {
var s1 dir_b.Student02
s1.Id = 1
// s1.name = "mike" // err, s1.name的 name 不是大写开头
fmt.Println("s1 =", s1)
// s2 := dir_b.student01{1, "mike"} //err, student01 是大写开头
}
8、面向对象编程
8.1、概述
对于面向对象编程的支持Go 语言设计得非常简洁而优雅。因为, Go语言并没有沿袭传统面向对象编程中的诸多概念,比如继承(不支持继承,尽管匿名字段的内存布局和行为类似继承,但它并不是继承)、虚函数、构造函数和析构函数、隐藏的this指针等。
尽管Go语言中没有封装、继承、多态这些概念,但同样通过别的方式实现这些特性:
- 封装:通过方法实现
- 继承:通过匿名字段实现
- 多态:通过接口实现
8.2、匿名组合
8.2.1 匿名字段
一般情况下,定义结构体的时候是字段名与其类型一一对应,实际上Go支持只提供类型,而不写字段名的方式,也就是匿名字段,也称为嵌入字段。
当匿名字段也是一个结构体的时候,那么这个结构体所拥有的全部字段都被隐式地引入了当前定义的这个结构体。
type Person struct {
name string
sex byte
age int
}
type Student struct {
Person // 匿名字段,那么默认Student就包含了Person的所有字段
id int
addr string
}
8.2.2 初始化
type Person struct {
name string
sex byte
age int
}
type Student struct {
Person // 匿名字段,那么默认Student就包含了Person的所有字段
id int
addr string
}
func main() {
// 1、顺序初始化
s1 := Student{Person{"zxm", 'm', 18}, 1, "hangzhou"}
fmt.Printf("s1 = %v\n", s1)
// 2、部分成员初始化
s2 := Student{Person: Person{name: "lily"}, id: 2}
// %+v 显示更详细
fmt.Printf("s2 = %+v\n", s2)
s3 := Student{Person: Person{"zxm", 'm', 18}, addr: "hangzhou"}
fmt.Printf("s3 = %+v\n", s3)
}
/*
s1 = {{zxm 109 18} 1 hangzhou}
s2 = {Person:{name:lily sex:0 age:0} id:2 addr:}
s3 = {Person:{name:zxm sex:109 age:18} id:0 addr:hangzhou}
*/
8.2.3 成员的操作
type Person struct {
name string
sex byte
age int
}
type Student struct {
Person // 匿名字段,那么默认Student就包含了Person的所有字段
id int
addr string
}
func main() {
var s1 Student
s1.name = "zxm" //等价于 s1.Person.name = "mike"
s1.sex = 'm'
s1.age = 18
s1.id = 1
s1.addr = "shanghai"
fmt.Println("s1 = ",s1)
var s2 Student
s2.Person = Person{"gq", 'w', 18}
s2.id = 2
s2.addr = "hangzhou"
fmt.Println("s2 = ",s2)
}
/*
s1 = {{zxm 109 18} 1 shanghai}
s2 = {{gq 119 18} 2 hangzhou}
*/
8.2.4 同名字段
type Person struct {
name string
sex byte
age int
}
type Student struct {
Person // 匿名字段,那么默认Student就包含了Person的所有字段
id int
addr string
name string //和Person中的name同名
}
func main() {
//默认只会给最外层的成员赋值
var s1 Student
s1.name = "mike"
fmt.Printf("s1 = %+v\n", s1)
//给匿名同名成员赋值,需要显示调用
s1.Person.name = "heihei"
fmt.Printf("s1 = %+v\n", s1)
}
/*
s1 = {Person:{name: sex:0 age:0} id:0 addr: name:mike}
s1 = {Person:{name:heihei sex:0 age:0} id:0 addr: name:mike}
*/
8.2.5 其它匿名字段
8.2.5.1 非结构体类型
所有的内置类型和自定义类型都是可以作为匿名字段的:
type mystr string
type Person struct {
name string
sex byte
age int
}
type Student struct {
Person // 匿名字段,那么默认Student就包含了Person的所有字段
int
mystr
}
func main() {
// 初始化
s1 := Student{Person{"zxm", 'm', 18}, 1, "hangzhou"}
fmt.Printf("s2 = %+v\n", s1)
// 打印成员
fmt.Printf("%s, %c, %d, %d, %s\n", s1.name, s1.sex, s1.age, s1.int,s1.mystr)
}
/*
s2 = {Person:{name:zxm sex:109 age:18} int:1 mystr:hangzhou}
zxm, m, 18, 1, hangzhou
*/
8.2.5.2 结构体指针类型
type Person struct {
name string
sex byte
age int
}
type Student struct {
*Person // 匿名字段,结构体指针类型
id int
addr string
}
func main() {
// 初始化
s1 := Student{&Person{"zxm", 'm', 18}, 1, "hangzhou"}
fmt.Printf("s2 = %+v\n", s1)
// 打印成员
fmt.Printf("%s, %c, %d\n", s1.name, s1.sex, s1.age)
var s2 Student
s2.Person = new(Person) //分配空间
s2.name = "gq"
s2.sex = 'w'
s2.age = 18
s2.id = 2
s2.addr = "zj"
fmt.Println(s2.name, s2.sex, s2.age, s2.id, s2.age)
}
/*
s2 = {Person:0xc00005e3c0 id:1 addr:hangzhou}
zxm, m, 18
gq 119 18 2 18
*/
8.3、方法
8.3.1 概述
在面向对象编程中,一个对象其实也就是一个简单的值或者一个变量,在这个对象中会包含一些函数,这种带有接收者的函数,我们称为方法(method)。 本质上,一个方法则是一个和特殊类型关联的函数。
一个面向对象的程序会用方法来表达其属性和对应的操作,这样使用这个对象的用户就不需要直接去操作对象,而是借助方法来做这些事情。
在Go语言中,可以给任意自定义类型(包括内置类型,但不包括指针类型)添加相应的方法。
⽅法总是绑定对象实例,并隐式将实例作为第一实参 (receiver),方法的语法如下:
func (receiver ReceiverType) funcName(parameters) (results)
- 参数 receiver 可任意命名。如方法中未曾使用,可省略参数名。
- 参数 receiver 类型可以是 T 或 *T。基类型 T 不能是接口或指针。
- 不支持重载方法,也就是说,不能定义名字相同但是不同参数的方法。
8.3.2 为类型添加方法
8.3.2.1 基础类型作为接收者
type MyInt int // 自定义类型,给 int 改名为 MyInt
// 在函数定义时,在其名字之前加一个变量,即是一个方法
func (a MyInt) Add(b MyInt) MyInt { // 面向对象
return a + b
}
// 传统方式的定义
func Add(a, b MyInt) MyInt { // 面向过程
return a + b
}
func main() {
var a MyInt = 1
var b MyInt = 2
// 调用func (a MyInt) Add(b MyInt)
fmt.Println("a.Add(b) = ", a.Add(b))
// 调用func Add(a, b MyInt)
fmt.Println("Add(a, b) = ", Add(a, b))
}
通过上面的例子可以看出,面向对象只是换了一种语法形式来表达。方法是函数的语法糖,因为receiver其实就是方法所接收的第1个参数。
注意:虽然方法的名字一模一样,但是如果接收者不一样,那么方法就不一样。
8.3.2.2 结构体作为接收者
方法里面可以访问接收者的字段,调用方法通过点.访问,就像struct里面访问字段一样:
type Person struct {
name string
sex byte
age int
}
func (p Person) PrintInfo() { // 给Person添加方法
fmt.Println(p.name, p.sex, p.age)
}
func main() {
p := Person{"zxm", 'm', 18}
p.PrintInfo()
}
8.3.3 值语义和引用语义
type Person struct {
name string
sex byte
age int
}
// 指针作为接收者,引用语义
func (p *Person) SetInfoPointer() {
p.name = "zxm"
(*p).sex = 'm' // 另一种赋值方式
p.age = 19
}
//值作为接收者,值语义
func (p Person) SetInfoValue() {
p.name = "zxm"
p.sex = 'm'
p.age = 19
}
func main() {
//指针作为接收者,引用语义
p1 := Person{"mike", 'm', 30}
fmt.Println("函数调用前 = ", p1)
(&p1).SetInfoPointer()
fmt.Println("函数调用后 = ", p1)
fmt.Println("==========================")
//值作为接收者,值语义
p2 := Person{"mike", 'm', 30}
fmt.Println("函数调用前 = ", p2)
p2.SetInfoValue()
fmt.Println("函数调用后 = ", p2)
}
/*
函数调用前 = {mike 109 30}
函数调用后 = {zxm 109 19}
==========================
函数调用前 = {mike 109 30}
函数调用后 = {mike 109 30}
*/
8.3.4 方法集
类型的方法集是指可以被该类型的值调用的所有方法的集合。
用实例 value 和 pointer 调用方法(含匿名字段)不受方法集约束,编译器编总是查找全部方法,并自动转换 receiver 实参。
*8.3.4.1 类型 T 方法集
一个指向自定义类型的值的指针,它的方法集由该类型定义的所有方法组成,无论这些方法接受的是一个值还是一个指针。
如果在指针上调用一个接受值的方法,Go语言会聪明地将该指针解引用,并将指针所指的底层值作为方法的接收者。
类型 *T方法集包含全部 receiver T + *T 方法:
type Person struct {
name string
sex byte
age int
}
func (p *Person) SetInfoPointer() {
fmt.Println("SetInfoPointer")
}
//值作为接收者,值语义
func (p Person) SetInfoValue() {
fmt.Println("SetInfoValue")
}
func main() {
// 结构体变量是一个指针变量,它能够调用哪些方法,这些方法就是一个集合,简称方法集
p := &Person{"lili", 'w', 18}
p.SetInfoPointer() // 调用SetInfoPointer
(*p).SetInfoPointer() // 调用SetInfoPointer,它是把(*p)转换成p后再调用,等同上面
p.SetInfoValue() // 调用SetInfoValue,它是把p转换成(*p)后再调用
(*p).SetInfoValue() // 调用SetInfoValue
}
8.3.4.2 类型 T 方法集
一个自定义类型值的方法集则由为该类型定义的接收者类型为值类型的方法组成,但是不包含那些接收者类型为指针的方法。
但这种限制通常并不像这里所说的那样,因为如果我们只有一个值,仍然可以调用一个接收者为指针类型的方法,这可以借助于Go语言传值的地址能力实现。
type Person struct {
name string
sex byte
age int
}
func (p *Person) SetInfoPointer() {
fmt.Println("SetInfoPointer")
}
//值作为接收者,值语义
func (p Person) SetInfoValue() {
fmt.Println("SetInfoValue")
}
func main() {
// p为普通值类型
p := Person{"lili", 'w', 18}
(&p).SetInfoPointer() // 调用SetInfoPointer
p.SetInfoPointer() // 调用SetInfoPointer,它是把p转换成(&p)后再调用
p.SetInfoValue() // 调用SetInfoValue
(&p).SetInfoValue() // 调用SetInfoValue,它是把(&p)转换成(*&p)后再调用
}
8.3.5 匿名字段
8.3.5.1 方法的继承
如果匿名字段实现了一个方法,那么包含这个匿名字段的struct也能调用该方法。
type Person struct {
name string
sex byte
age int
}
// Person定义了方法
func (p *Person) PrintInfo() {
fmt.Printf("%s, %c, %d\n", p.name, p.sex, p.age)
}
type Student struct {
Person
id int
addr string
}
func main() {
p := Person{"mike", 'm', 18}
p.PrintInfo()
s := Student{Person{"lily", 'w', 33}, 2, "shanghai"}
s.PrintInfo() // 继承了Person的方法
}
8.3.5.2 方法的重写
type Person struct {
name string
sex byte
age int
}
// Person定义了方法
func (p *Person) PrintInfo() {
fmt.Printf("Person: %s, %c, %d\n", p.name, p.sex, p.age)
}
type Student struct {
Person
id int
addr string
}
// Student定义了方法
func (s *Student)PrintInfo() {
fmt.Printf("Student: %s, %c, %d\n", s.name, s.sex, s.age)
}
func main() {
p := Person{"mike", 'm', 18}
p.PrintInfo() // Person: mike, m, 18
s := Student{Person{"lily", 'w', 33}, 2, "shanghai"}
s.PrintInfo() // Student: lily, w, 33
s.Person.PrintInfo() // Person: lily, w, 33
}
8.3.6 表达式
类似于我们可以对函数进行赋值和传递一样,方法也可以进行赋值和传递。
根据调用者不同,方法分为两种表现形式:方法值和方法表达式。两者都可像普通函数那样赋值和传参,区别在于方法值绑定实例,而方法表达式则须显式传参。
8.3.6.1 方法值
type Person struct {
name string
sex byte
age int
}
// Person定义了方法
func (p *Person) PrintInfoPointer() {
fmt.Printf("%p, %v\n", p, p)
}
func (p Person) PrintInfoValue() {
fmt.Printf("%p, %v\n", &p, p)
}
func main() {
p := Person{"mike", 'm', 18}
p.PrintInfoPointer() // 传统调用方式
// 保存方式入口地址 -- 方法值
pFunc := p.PrintInfoPointer // 这个就是方法值,调用函数时,无需再传递接收者。隐藏了接收者
pFunc() // 等价于 p.PrintInfoPointer()
vFunc := p.PrintInfoValue
vFunc() // 等价于 p.PrintInfoValue()
}
8.3.6.2 方法表达式
type Person struct {
name string
sex byte
age int
}
// Person定义了方法
func (p *Person) PrintInfoPointer() {
fmt.Printf("%p, %v\n", p, p)
}
func (p Person) PrintInfoValue() {
fmt.Printf("%p, %v\n", &p, p)
}
func main() {
p := Person{"mike", 'm', 18}
p.PrintInfoPointer() // 传统调用方式
// 方法表达式, 须显式传参
f := (*Person).PrintInfoPointer
f(&p) // 需要显示把接收者传递过去,等价于 p.PrintInfoPointer()
f2 := Person.PrintInfoValue
f2(p) // 需要显示把接收者传递过去,等价于 p.PrintInfoValue()
}
8.4、接口
8.4.1 概述
在Go语言中,接口(interface)是一个自定义类型,接口类型具体描述了一系列方法的集合。
接口类型是一种抽象的类型,它不会暴露出它所代表的对象的内部值的结构和这个对象支持的基础操作的集合,它们只会展示出它们自己的方法。因此接口类型不能将其实例化。
Go通过接口实现了鸭子类型(duck-typing):“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子”。我们并不关心对象是什么类型,到底是不是鸭子,只关心行为。
8.4.2 接口的使用
8.4.2.1 接口定义
type Humaner interface {
SayHi()
}
- 接⼝命名习惯以 er 结尾
- 接口只有方法声明,没有实现,没有数据字段
- 接口可以匿名嵌入其它接口,或嵌入到结构中
8.4.2.2 接口实现
接口是用来定义行为的类型。这些被定义的行为不由接口直接实现,而是通过方法由用户定义的类型实现,一个实现了这些方法的具体类型是这个接口类型的实例。
如果用户定义的类型实现了某个接口类型声明的一组方法,那么这个用户定义的类型的值就可以赋给这个接口类型的值。这个赋值会把用户定义的类型的值存入接口类型的值。
package main
import (
"fmt"
)
// 定义接口类型
type Humaner interface {
// 方法:只有生命,没有实现,由别的类型(自定义类型)实现
SayHi()
}
type Student struct {
name string
score int
}
func (s *Student) SayHi() { // Student实现SayHi()方法
fmt.Printf("Student[%s, %d] say hi!\n", s.name, s.score)
}
type Teacher struct {
name string
group string
}
func (t *Teacher) SayHi() { // Teacher实现SayHi()方法
fmt.Printf("Student[%s, %s] say hi!\n", t.name, t.group)
}
type MyStr string
func (str MyStr) SayHi() { // MyStr实现SayHi()方法
fmt.Printf("MyStr[%s] say hi!\n", str)
}
// 定义一个普通函数,函数参数为接口类型
// 只有一个函数,但可以有不同表现 --》 多态
func WhoSayHi(i Humaner) {
i.SayHi()
}
func main() {
s := &Student{"mike", 95}
t := &Teacher{"tony", "1班"}
var str MyStr = "数学"
s.SayHi()
t.SayHi()
str.SayHi()
//多态,调用同一接口,不同表现
WhoSayHi(s)
WhoSayHi(t)
WhoSayHi(str)
//这三个都是不同类型的元素,但是他们实现了interface同一个接口
x := make([]Humaner, 3)
x[0], x[1],x[2] = s, t, str
for _, value := range x {
value.SayHi()
}
}
通过上面的代码,你会发现接口就是一组抽象方法的集合,它必须由其他非接口类型实现,而不能自我实现。
8.4.3 接口组合
8.4.3.1 接口嵌入
如果一个interface1作为interface2的一个嵌入字段,那么interface2隐式的包含了interface1里面的方法。
package main
import (
"fmt"
)
type Humaner interface {
SayHi()
}
type Personer interface {
Humaner // 匿名字段,继承了 SayHi()
Sing(SongName string)
}
type Student struct { // 学生
name string
score int
}
// 学生实现 SayHi() 方法
func (s *Student) SayHi() {
fmt.Printf("Student[%s, %d] say hi!\n", s.name, s.score)
}
// 学生实现 Sing() 方法
func (s *Student) Sing(SongName string) {
fmt.Printf("Student sing[%s]\n", SongName)
}
func main() {
s := &Student{"mike", 95}
var i Personer = s
i.SayHi()
i.Sing("欢乐颂")
}
8.4.3.2 接口转换
超集接⼝对象可转换为子集接口,反之出错
type Humaner interface {
SayHi()
}
type Personer interface {
Humaner // 匿名字段,继承了 SayHi()
Sing(SongName string)
}
type Student struct { // 学生
name string
score int
}
// 学生实现 SayHi() 方法
func (s *Student) SayHi() {
fmt.Printf("Student[%s, %d] say hi!\n", s.name, s.score)
}
// 学生实现 Sing() 方法
func (s *Student) Sing(SongName string) {
fmt.Printf("Student sing[%s]\n", SongName)
}
func main() {
// 超集可以转换为子集,反之不行
// Personer 是超集,Humaner 是子集
var iPro Personer // 超集
iPro = &Student{"mike", 99}
var i Humaner
// iPro = i // err
i = iPro
i.SayHi()
}
8.4.4 空接口
空接口(interface{})不包含任何的方法,正因为如此,所有的类型都实现了空接口,因此空接口可以存储任意类型的数值。它有点类似于C语言的void *类型。
func main() {
var v1 interface{} = 1 // 将int类型赋值给interface{}
var v2 interface{} = "abc" // 将string类型赋值给interface{}
var v3 interface{} = &v2 // 将*interface{}类型赋值给interface{}
var v4 interface{} = struct{ X int }{1} // 将一个匿名结构体实例赋值给interface{}。这个结构体包含一个整数字段 X,并将其初始化为 1。
var v5 interface{} = &struct{ X int }{1}
fmt.Println(v1, v2, v3, v4, v5)
}
/*
1 abc 0xc00005c270 {1} &{1}
*/
当函数可以接受任意的对象实例时,我们会将其声明为interface{},最典型的例子是标准库fmt中PrintXXX系列的函数,例如:
func Printf(fmt string, args ...interface{})
func Println(args ...interface{})·
8.4.5 类型查询
我们知道interface的变量里面可以存储任意类型的数值(该类型实现了interface)。那么我们怎么反向知道这个变量里面实际保存了的是哪个类型的对象呢?目前常用的有两种方法:
- comma-ok断言
- switch测试
8.4.5.1 comma-ok断言
Go语言里面有一个语法,可以直接判断是否是该类型的变量: value, ok = element.(T)
这里value就是变量的值,ok是一个bool类型,element是interface变量,T是断言的类型。
如果element里面确实存储了T类型的数值,那么ok返回true,否则返回false。
type Emlemnt interface{}
type Person struct {
name string
age int
}
func main() {
list := make([]Emlemnt, 3)
list[0] = 1
list[1] = "Hello"
list[2] = Person{"mike", 19}
for index, element := range list {
if value, ok := element.(int); ok == true {
fmt.Printf("list[%d] 类型为 int, 内容为 %d\n", index, value)
} else if value, ok := element.(string); ok == true {
fmt.Printf("list[%d] 类型为 string 内容为 %s\n", index, value)
} else if value, ok := element.(Person); ok == true {
fmt.Printf("list[%d] 类型为 Person 内容为 [%s, %d]\n", index, value.name, value.age)
} else {
fmt.Printf("list[%d] 是其他类型", index)
}
}
}
/*
list[0] 类型为 int, 内容为 1, 1
list[1] 类型为 string 内容为 Hello
list[2] 类型为 Person 内容为 [mike, 19]
*/
8.4.5.2 switch测试
type Emlemnt interface{}
type Person struct {
name string
age int
}
func main() {
list := make([]Emlemnt, 3)
list[0] = 1
list[1] = "Hello"
list[2] = Person{"mike", 19}
for index, element := range list {
switch value := element.(type) {
case int :
fmt.Printf("list[%d] 类型为 int, 内容为 %d\n", index, value)
case string :
fmt.Printf("list[%d] 类型为 string 内容为 %s\n", index, value)
case Person :
fmt.Printf("list[%d] 类型为 Person 内容为 [%s, %d]\n", index, value.name, value.age)
default :
fmt.Printf("list[%d] 是其他类型", index)
}
}
}
9、 异常处理
9.1、error接口
Go语言引入了一个关于错误处理的标准模式,即error接口,它是Go语言内建的接口类型,该接口的定义如下:
type error interface {
Error() string
}
Go语言的标准库代码包errors为用户提供如下方法:
package errors
type errorString struct {
text string
}
func New(text string) error {
return &errorString{text}
}
func (e *errorString) Error() string {
return e.text
}
另一个可以生成error类型值的方法是调用fmt包中的Errorf函数:
package fmt
import "errors"
func Errorf(format string, args ...interface{}) error {
return errors.New(Sprintf(format, args...))
}
举个例子
import (
"errors"
"fmt"
)
func main() {
// var err1 error = errors.New("This is a normal err1")
err1 := errors.New("This is a normal err1")
fmt.Println(err1)
err2 := fmt.Errorf("%s", "This is a normal err2")
fmt.Println(err2)
}
/*
This is a normal err1
This is a normal err1
*/
函数通常在最后的返回值中返回错误信息:
import (
"errors"
"fmt"
)
func Divide(a, b float64) (result float64, err error) {
if b == 0 {
result = 0.0
err = errors.New("runtime error: divide by zero")
return
}
result = a / b
err = nil
return
}
func main() {
result, err := Divide(0, 0)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(result)
}
}
/*
runtime error: divide by zero
*/
9.2、panic
在通常情况下,向程序使用方报告错误状态的方式可以是返回一个额外的error类型值。
但是,当遇到不可恢复的错误状态的时候,如数组访问越界、空指针引用等,这些运行时错误会引起painc异常。这时,上述错误处理方式显然就不适合了。反过来讲,在一般情况下,我们不应通过调用panic函数来报告普通的错误,而应该只把它作为报告致命错误的一种方式。当某些不应该发生的场景发生时,我们就应该调用painc。
一般而言,当panic异常发生时,程序会中断运行,并立即执行在该goroutine(可以先理解成线程,在中被延迟的函数(defer 机制)。随后,程序崩溃并输出日志信息。日志信息包括panic value和函数调用的堆栈跟踪信息。
不是所有的painc异常都来自运行时,直接调用内置的panic函数也会引发panic异常;panic函数接受任何值作为参数。
func panic(v interface{})
调用panic函数引发的panic异常
func TestA() {
fmt.Println("func TestA()")
}
func TestB() {
panic("func TestB(): panic")
}
func TestC() {
fmt.Println("func TestC()")
}
func main() {
TestA()
TestB() // TestB() 发生异常,中断程序
TestC()
}
/*
func TestA()
panic: func TestB(): panic
goroutine 1 [running]:
main.TestB(...)
D:/go/a.go:12
main.main()
D:/go/a.go:21 +0x66
exit status 2
*/
内置的panic函数引发的panic异常:
func TestA() {
fmt.Println("func TestA()")
}
func TestB(x int) {
var a [10]int
a[x] = 222 // 当 x >= 11时,数组越界
}
func TestC() {
fmt.Println("func TestC()")
}
func main() {
TestA()
TestB(11) // TestB() 发生异常,中断程序
TestC()
}
/*
func TestA()
panic: runtime error: index out of range [11] with length 10
goroutine 1 [running]:
main.TestB(...)
D:/go/a.go:13
main.main()
D:/go/a.go:22 +0x65
exit status 2
*/
9.3、recover
运行时panic异常一旦被引发就会导致程序崩溃。这当然不是我们愿意看到的,因为谁也不能保证程序不会发生任何运行时错误。
不过,Go语言为我们提供了专用于“拦截”运行时panic的内建函数——recover。它可以是当前的程序从运行时panic的状态中恢复并重新获得流程控制权。
func recover() interface{}
注意:recover只有在defer调用的函数中有效。
如果调用了内置函数recover,并且定义该defer语句的函数发生了panic异常,recover会使程序从panic中恢复,并返回panic value。导致panic异常的函数不会继续运行,但能正常返回。在未发生panic时调用recover,recover会返回nil。
func TestA() {
fmt.Println("func TestA()")
}
func TestB(x int){
// 在发生异常时,设置恢复
defer func() {
if err := recover(); err != nil { // 如果产生了 panic 异常
fmt.Printf("internal error: %v\n", err)
}
} ()
var a [10]int
a[x] = 222 // 当 x >= 11时,数组越界
}
func TestC() {
fmt.Println("func TestC()")
}
func main() {
TestA()
TestB(11)
TestC()
}
/*
func TestA()
internal error: runtime error: index out of range [11] with length 10
func TestC()
*/
10、文本文件处理
10.1、字符串处理
字符串在开发中经常用到,包括用户的输入,数据库读取的数据等,我们经常需要对字符串进行分割、连接、转换等操作,我们可以通过Go标准库中的strings和strconv两个包中的函数进行相应的操作。
10.1.1 字符串操作
下面这些函数来自于strings包
10.1.1.1 Contains
功能:字符串s中是否包含substr,返回bool值
func Contains(s, substr string) bool
例子
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Contains("hello world", "hello")) // true
fmt.Println(strings.Contains("hello world", "sea")) // false
}
10.1.1.2 Join
功能:字符串链接,把slice a通过sep链接起来
func Join(a []string, sep string) string
例子
func main() {
s := []string{"zxm", "is", "handsome", "guy"}
a := "-"
fmt.Println(strings.Join(s, a)) // zxm-is-handsome-guy
}
10.1.1.3 Index
功能:在字符串s中查找sep所在的位置,返回位置值,找不到返回-1
func Index(s, sep string) int
func main() {
fmt.Println(strings.Index("chicken", "ken")) // 4
fmt.Println(strings.Index("chicken", "jen")) // -1
}
10.1.1.5 Replace
功能:在s字符串中,把old字符串替换为new字符串,n表示替换的次数,小于0表示全部替换
func Replace(s, old, new string, n int) string
例子
func main() {
fmt.Println(strings.Replace("hello hello hello", "e", "py", 2)) // hpyllo hpyllo hello
fmt.Println(strings.Replace("hello hello hello", "hello", "world", -1)) // world world world
}
10.1.1.6 Split
功能:把s字符串按照sep分割,返回slice
func Split(s, sep string) []string
例子
func main() {
fmt.Printf("%q\n", strings.Split("a,b,c", ","))
fmt.Printf("%q\n", strings.Split("a man a plan a canal panama", "a "))
fmt.Printf("%q\n", strings.Split(" xyz ", ""))
fmt.Printf("%q\n", strings.Split("", "Bernardo O'Higgins"))
}
/*
["a" "b" "c"]
["" "man " "plan " "canal panama"]
[" " "x" "y" "z" " "]
[""]
*/
10.1.1.7 Trim
功能:在s字符串的头部和尾部去除cutset指定的字符串
func Trim(s string, cutset string) string
func main() {
fmt.Printf("%q\n", strings.Trim("abcdcba", "ab")) // 去掉首尾的a和b
fmt.Printf("%q\n", strings.Trim("abcdcba", "ba"))
}
/*
"cdc"
"cdc"
*/
10.1.1.8 Fields
功能:去除s字符串的空格符,并且按照空格分割返回slice
func Fields(s string) []string
例子
func main() {
fmt.Printf("Fieids are : %q\n", strings.Fields(" food hello wrold ")) // Fieids are : ["food" "hello" "wrold"]
}
10.1.2 字符串转换
字符串转化的函数在strconv中
10.1.2.1 Append
Append 系列函数将整数等转换为字符串后,添加到现有的字节数组中。
func main() {
str := make([]byte, 0, 100) // 创建了一个切片(slice)str,其中元素类型为 byte。切片的长度为 0,容量为 100
fmt.Println(string(str)) // 注意要转化成字符串打印
str = strconv.AppendInt(str, 4567, 10) //以10进制方式追加
fmt.Println(string(str))
str = strconv.AppendBool(str, false)
fmt.Println(string(str))
str = strconv.AppendQuote(str, "hello")
fmt.Println(string(str))
str = strconv.AppendQuoteRune(str, '单')
fmt.Println(string(str))
}
/*
4567
4567false
4567false"hello"
4567false"hello"'单'
*/
10.1.2.2 Format
Format 系列函数把其他类型的转换为字符串。
func main() {
a := strconv.FormatBool(false)
b := strconv.FormatInt(1234, 10)
// "f' 指打印格式,以小数方式,-1指小数点位数(紧缩模式), 64以float64处理
c := strconv.FormatFloat(1.234, 'f', -1, 64)
// 柜跋整型转字符串
d := strconv.Itoa(1023)
fmt.Println(a, b, c, d) // false 1234 1.234 1023
}
10.1.2.3 Parse
Parse 系列函数把字符串转换为其他类型。
func checkError( e error) {
if e != nil {
fmt.Println(e)
}
}
func main() {
a, err := strconv.ParseBool("false")
checkError(err)
b, err := strconv.Atoi("1023") // 将字符串转换为整型,是ParseInt(s, 10, 0)的简写。
checkError(err)
c, err := strconv.ParseFloat("123.455", 64)
checkError(err)
d, err := strconv.ParseInt("234", 10, 64)
checkError(err)
fmt.Println(a, b, c, d) // false 1023 123.455 234
}
10.2、正则表达式
正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合。
Go语言通过regexp标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对Go语言版本的不会太陌生,但是它们之间也有一些小的差异,因为Go实现的是RE2标准,除了\C,详细的语法描述参考:https://studygolang.com/pkgdoc
其实字符串处理我们可以使用strings包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果strings包能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都会比正则好。
例子:匹配小数
package main
import (
"fmt"
"regexp"
)
func main() {
context1 := "3.14 123123 .68 haha 1.0 abc 6.66 123."
// 1、解释规则
// MustCompile解析并返回一个正则表达式。如果成功返回,该Regexp就可用于匹配文本。解析失败时会产生panic
// \d 匹配数字[0-9],d+ 重复>=1次匹配d,越多越好(优先重复匹配d)
exp1 := regexp.MustCompile(`\d+\.\d+`) // 匹配小数
if exp1 == nil {
fmt.Println("regexp error")
return
}
// 2、根据规则提取关键信息
// result1 := exp1.FindAllString(context1, -1) // result1 = [3.14 1.0 6.66]
result1 := exp1.FindAllStringSubmatch(context1, -1) // result1 = [[3.14] [1.0] [6.66]]
fmt.Println("result1 = ", result1)
}
例子:匹配标签内的内容
package main
import (
"fmt"
"regexp"
)
func main() {
context1 := `
<title>标题</title>
<div>你好</div>
<div>进击的巨人</div>
<div>hello
Eren
Mikasa
Armin
Levi</div>
<body>未来</body>
`
// 1、解释规则
// MustCompile解析并返回一个正则表达式。如果成功返回,该Regexp就可用于匹配文本。解析失败时会产生panic
// 只需要匹配开始标签<div>和结束标签<div>之间的内容 (.*?)
// s 可以让.可以匹配\n(默认关闭)
exp1 := regexp.MustCompile(`<div>(?s:(.*?))</div>`)
if exp1 == nil {
fmt.Println("regexp error")
return
}
// 2、根据规则提取关键信息
result1 := exp1.FindAllStringSubmatch(context1, -1) //
fmt.Println("result1 = ", result1)
fmt.Printf("\n------------------------------------\n\n")
for _, text := range result1 {
fmt.Println(text[0]) //带有div
}
fmt.Printf("\n------------------------------------\n\n")
for _, text := range result1 {
fmt.Println(text[1]) //不带带有div
}
}
/*
result1 = [[<div>你好</div> 你好] [<div>进击的巨人</div> 进击的巨人] [<div>hello
Eren
Mikasa
Armin
Levi</div> hello
Eren
Mikasa
Armin
Levi]]
------------------------------------
<div>你好</div>
<div>进击的巨人</div>
<div>hello
Eren
Mikasa
Armin
Levi</div>
------------------------------------
你好
进击的巨人
hello
Eren
Mikasa
Armin
Levi
*/
10.3、JSON处理
JSON (JavaScript Object Notation)是一种比XML更轻量级的数据交换格式,在易于人们阅读和编写的同时,也易于程序解析和生成。尽管JSON是JavaScript的一个子集,但JSON采用完全独立于编程语言的文本格式,且表现为键/值对集合的文本描述形式(类似一些编程语言中的字典结构),这使它成为较为理想的、跨平台、跨语言的数据交换语言。

开发者可以用 JSON 传输简单的字符串、数字、布尔值,也可以传输一个数组,或者一个更复杂的复合结构。在 Web 开发领域中, JSON被广泛应用于 Web 服务端程序和客户端之间的数据通信。
Go语言内建对JSON的支持。使用Go语言内置的encoding/json 标准库,开发者可以轻松使用Go程序生成和解析JSON格式的数据。
JSON官方网站:http://www.json.org/
在线格式化:http://www.json.cn/
10.3.1 编码JSON
10.3.1.1 通过结构体生成JSON
使用json.Marshal()函数可以对一组数据进行JSON格式的编码。 json.Marshal()函数的声明如下:
func Marshal(v interface{}) ([]byte, error)
还有一个格式化输出:
// MarshalIndent 很像 Marshal,只是用缩进对输出进行格式化
func MarshalIndent(v interface{}, prefix, indent string) ([]byte, error)
1)编码JSON
package main
import (
"fmt"
"encoding/json"
)
// 成员变量首字母必须大写
type MOVIE struct {
Company string
Subjects []string
Isok bool
Price float64
}
func main() {
m1 := MOVIE{"进击的巨人", []string{"Eren", "Mikasa", "Armin", "Levi"}, true, 222.222}
//生成一段JSON格式的文本,如果编码成功, err 将赋于零值 nil,变量b 将会是一个进行JSON格式化之后的[]byte类型
// buf, err := json.Marshal(m1)
buf, err := json.MarshalIndent(m1, "", " ") // 对输出进行格式化
if err != nil {
fmt.Println("json err: ", err)
}
fmt.Println(string(buf))
}
/*
json.Marshal(m1)的结果是 {"Company":"进击的巨人","Subjects":["Eren","Mikasa","Armin","Levi"],"Isok":true,"Price":222.222}
json.MarshalIndent(m1, "", " ")的结果是
{
"Company": "进击的巨人",
"Subjects": [
"Eren",
"Mikasa",
"Armin",
"Levi"
],
"Isok": true,
"Price": 222.222
}
*/
2) struct tag
我们看到上面的输出字段名的首字母都是大写的,如果你想用小写的首字母怎么办呢?把结构体的字段名改成首字母小写的?
JSON输出的时候必须注意,只有导出的字段(首字母是大写)才会被输出,如果修改字段名,那么就会发现什么都不会输出,所以必须通过struct tag定义来实现。
针对JSON的输出,我们在定义struct tag的时候需要注意的几点是:
- 字段的tag是"-",那么这个字段不会输出到JSON
- tag中带有自定义名称,那么这个自定义名称会出现在JSON的字段名中
- tag中如果带有"omitempty"选项,那么如果该字段值为空,就不会输出到JSON串中
- 如果字段类型是bool, string, int, int64等,而tag中带有",string"选项,那么这个字段在输出到JSON的时候会把该字段对应的值转换成JSON字符串
// 成员变量首字母必须大写
type MOVIE struct {
Company string `json:"-"`
Subjects []string `json:"subjects"`
Isok bool `json:",string"`
Price float64 `json:"price, omitempty"`
}
func main() {
m1 := MOVIE{"进击的巨人", []string{"Eren", "Mikasa", "Armin", "Levi"}, true, 222.222}
//生成一段JSON格式的文本,如果编码成功, err 将赋于零值 nil,变量b 将会是一个进行JSON格式化之后的[]byte类型
// buf, err := json.Marshal(m1)
buf, err := json.MarshalIndent(m1, "", " ") // 对输出进行格式化
if err != nil {
fmt.Println("json err: ", err)
}
fmt.Println(string(buf))
}
/*
{
"subjects": [
"Eren",
"Mikasa",
"Armin",
"Levi"
],
"Isok": "true",
"price": 222.222
}
*/
10.3.1.2 通过map生成JSON
func main() {
m1 := make(map[string]interface{})
m1["company"] = "进击的巨人"
m1["subjects"] = []string{"Eren", "Mikasa", "Armin", "Levi"}
m1["isok"] = "true"
m1["price"] = 666.666
buf, err := json.Marshal(m1)
if err != nil {
fmt.Println("json err: ", err)
}
fmt.Println(string(buf))
}
/*
{"company":"进击的巨人","isok":"true","price":666.666,"subjects":["Eren","Mikasa","Armin","Levi"]}
*/
10.3.2 解码JSON
可以使用json.Unmarshal()函数将JSON格式的文本解码为Go里面预期的数据结构。
json.Unmarshal()函数的原型如下
func Unmarshal(data []byte, v interface{}) error
该函数的第一个参数是输入,即JSON格式的文本(比特序列),第二个参数表示目标输出容器,用于存放解码后的值。
10.3.2.1 解析到结构体
type MOVIE struct {
Company string `json:"company"`
Subjects []string `json:"subjects"`
Isok bool `json:"isok"`
Price float64 `json:"price"`
}
func main() {
jsonBuf := `{
"company": "进击的巨人",
"subjects": [
"Eren",
"Mikasa",
"Armin",
"Levi"
],
"isok": true,
"price": 666.666
}`
var m1 MOVIE
err := json.Unmarshal([]byte(jsonBuf), &m1)
if err != nil {
fmt.Println("json err:", err)
}
fmt.Println(m1) // {进击的巨人 [Eren Mikasa Armin Levi] true 666.666}
//只想要Subjects字段
type MOVIE2 struct {
Subjects []string `json:"subjects"`
}
var m2 MOVIE2
err2 := json.Unmarshal([]byte(jsonBuf), &m2)
if err2 != nil {
fmt.Println("json err:", err2)
}
fmt.Println(m2) // {[Eren Mikasa Armin Levi]}
}
10.3.2.2 解析到map
package main
import (
"encoding/json"
"fmt"
)
func main() {
jsonBuf := `{
"company": "进击的巨人",
"subjects": [
"Eren",
"Mikasa",
"Armin",
"Levi"
],
"isok": true,
"price": 666.666
}`
m := make(map[string]interface{}, 4)
err := json.Unmarshal([]byte(jsonBuf), &m)
if err != nil {
fmt.Println("json err:", err)
}
fmt.Printf("m = %+v\n", m) // m = map[company:进击的巨人 isok:true price:666.666 subjects:[Eren Mikasa Armin Levi]]
fmt.Println("\n-------------解析字段-------------\n")
// 解析每个字段
for key, value := range m {
//使用断言判断类型
switch data := value.(type) {
case string:
fmt.Printf("map[%s]的值的类型是string, value = %s\n", key, data)
case bool:
fmt.Printf("map[%s]的值的类型是bool, value = %t\n", key, data)
case float64:
fmt.Printf("map[%s]的值的类型是float64, value = %f\n", key, data)
// case []string: // 切片类型不是[]string
// fmt.Printf("map[%s]的值的类型是[]string, value = %v\n", key, data)
case []interface{}:
fmt.Printf("map[%s]的值的类型是interface, value = %v\n", key, data)
for i, u := range data {
fmt.Printf("subjects[%d] = %v\n", i, u)
}
default:
fmt.Println(key, "is of a type I don't know how to handle")
}
}
}
/*
m = map[company:进击的巨人 isok:true price:666.666 subjects:[Eren Mikasa Armin Levi]]
-------------解析字段-------------
map[company]的值的类型是string, value = 进击的巨人
map[subjects]的值的类型是interface, value = [Eren Mikasa Armin Levi]
subjects[0] = Eren
subjects[1] = Mikasa
subjects[2] = Armin
subjects[3] = Levi
map[isok]的值的类型是bool, value = true
map[price]的值的类型是float64, value = 666.666000
*/
10.4、文件操作
10.4.1 建立与打开文件
1、新建文件可以通过如下两个方法:
1)根据提供的文件名创建新的文件,返回一个文件对象,默认权限是0666的文件,返回的文件对象是可读写的。
func Create(name string) (file *File, err Error)
2)根据文件描述符创建相应的文件,返回一个文件对象
func NewFile(fd uintptr, name string) *File
2、通过如下两个方法来打开文件:
1)该方法打开一个名称为name的文件,但是是只读方式,内部实现其实调用了OpenFile。
func Open(name string) (file *File, err Error)
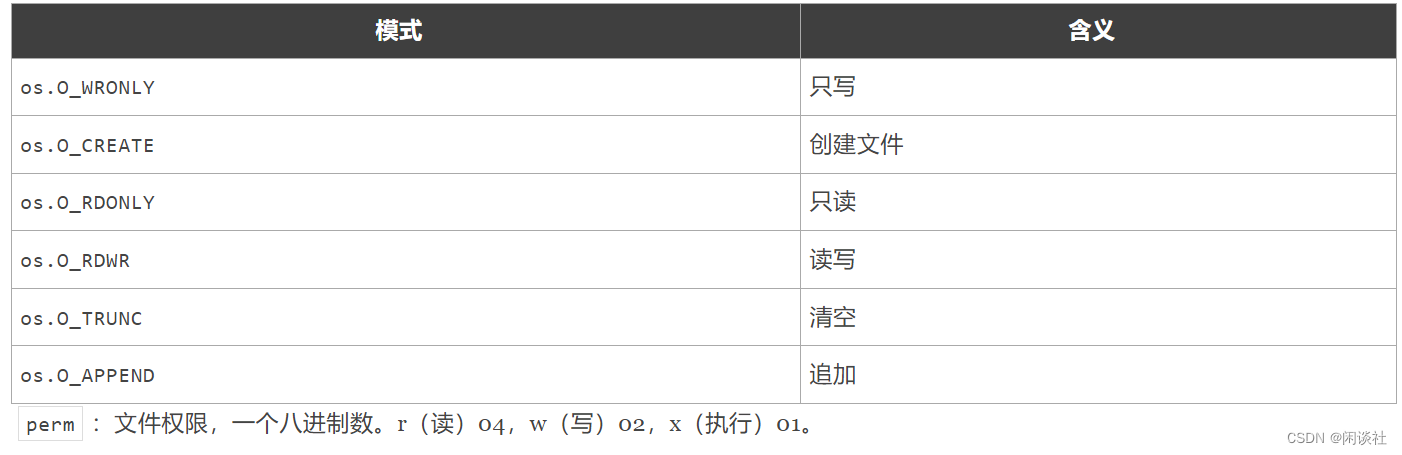
2)打开名称为name的文件,flag是打开的方式,只读、读写等,perm是权限
func OpenFile(name string, flag int, perm uint32) (file *File, err Error)
10.4.2 写文件
1)写入byte类型的信息到文件
func (file *File) Write(b []byte) (n int, err Error)
2)在指定位置开始写入byte类型的信息
func (file *File) WriteAt(b []byte, off int64) (n int, err Error)
3)写入string信息到文件
func (file *File) WriteString(s string) (ret int, err Error)
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Create("hello.txt") // 新建文件
// fout, err := os.OpenFile("hello.txt", os.O_CREATE, 0666) // 打开文件, os.O_CREATE表示如果文件不存在,则创建
if err != nil {
fmt.Println("os.Create err: ", err)
return
}
defer file.Close() //main函数结束前, 关闭文件
for i := 0; i < 5; i++ {
outStr := fmt.Sprintf("%s: %d\n", "hello world", i)
file.WriteString(outStr)
file.Write([]byte("abcd\n"))
}
}
4)利用bufio 是通过缓冲来提高效率。
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
// 0666 表示一个普通文件,所有者、同一群组的用户以及其他用户都具有读取、写入和执行权限。
file, err := os.OpenFile("./hello.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println(" os.OpenFile err = ", err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
outStr := fmt.Sprintf("%s: %d\n", "hello zxm", i)
writer.WriteString(outStr) //将数据先写入缓存
}
writer.Flush() // 将缓存中的内容写入文件
}
10.4.3 读文件
1)读取数据到b中,读到文件末尾时会返回 n == 0和 err == io.EOF
func (file *File) Read(b []byte) (n int, err Error)
2)从off开始读取数据到b中
func (file *File) ReadAt(b []byte, off int64) (n int, err Error)
package main
import (
"fmt"
"os"
)
func main() {
fin, err := os.Open("hello.txt")
if err != nil {
fmt.Println("os.Open err: ", err)
return
}
defer fin.Close()
// 循环读取文件
var content []byte
buf := make([]byte, 1024)
for {
n, err := fin.Read(buf) // 读文件
if n == 0 { // 0表示已经到文件结束
fmt.Println("文件读取结束")
break
}
if err != nil {
fmt.Println("fin.Read err : ", err)
return
}
//"..."是Go语言的扩展语法,用于将切片的每个元素作为单独的参数传递给函数。
// 因此,这行代码将buf[:n]中的每个字节都添加到content切片中。
content = append(content, buf[:n]...)
}
fmt.Println(string(content)) // 输出读取的内容
}
/*
文件读取结束
hello world
hello zxm
hello guoqin
*/
3)bufio包
bufio 是通过缓冲来提高效率。
io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
读取文件,建议使用 bufio.NewReader 和 Reader.ReadString,减少磁盘的操作
NewReader(rd io.Reader) *Reader获取一个有缓冲区的 Reader 指针变量,缓冲区默认大小为 4096 字节。通过变量可以对数据进行读操作。ReadString(delim byte) (string, error)读取数据,直到第一次遇到分隔符 delim 为止。读取过程中发生错误会返回 EOF 错误信息。ReadLine() (line []byte, isPrefix bool, err error)用于从输入流中读取一行内容并返回一个字节切片以及一个表示是否读到行尾的布尔值。具体解释如下:lineContent 是一个 []byte 类型的变量,用于存储读取到的字节内容。isPrefix 是一个 bool 类型的变量,用于表示读取到的内容是否以换行符结尾。如果为 true,则表示读取到的内容没有结束,还需要继续读取后面的内容;如果为 false,则表示读取到的内容已经结束,可以进行后续处理。err 是一个 error 类型的变量,用于存储可能发生的错误信息。
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
file, err := os.Open("hello.txt")
if err != nil {
fmt.Println("os.Open err: ", err)
return
}
defer file.Close()
reader := bufio.NewReader(file)
for {
lineContent, err := reader.ReadString('\n')
if err == io.EOF {
if len(lineContent) != 0 {
fmt.Println(lineContent)
}
fmt.Println("文件读完了")
break
}
if err != nil {
fmt.Println("reader.ReadString err = ", err)
return
}
fmt.Print(lineContent)
}
}
fmt.Println("=============ReadLine=============")
reader := bufio.NewReader(file)
for {
lineContent, _, err := reader.ReadLine()
if err == io.EOF {
if len(lineContent) != 0 {
fmt.Println(lineContent)
}
fmt.Println("文件读完了")
break
}
if err != nil {
fmt.Println("reader.ReadString err = ", err)
return
}
fmt.Println(string(lineContent))
}
10.4.4 直接读取整个文件、写入文件
os包的ReadFile方法能够读取完整的文件,只需要将文件名作为参数传入。
package main
import (
"os"
"fmt"
)
func main() {
content, err := os.ReadFile("./hello.txt")
if err != nil {
fmt.Println("os.ReadFile err = ", err)
return
}
fmt.Println(string(content))
}
package main
import (
"fmt"
"os"
)
func main() {
str := "hello 沙河"
err := os.WriteFile("./hello.txt", []byte(str), 0666)
if err != nil {
fmt.Println("write file failed, err:", err)
return
}
}
10.4.5 删除文件
调用该函数就可以删除文件名为name的文件
func Remove(name string) Error
10.4.2 案例:拷贝文件
package main
import (
"fmt"
"os"
"io"
)
func main() {
// 1、接收参数
list := os.Args
if len(list) < 3{
fmt.Println("需要输入三个参数")
return
}
srcFileName := list[1]
dstFileName := list[2]
if srcFileName == dstFileName {
fmt.Println("源文件和目的文件的文件名字不能一样")
return
}
// 2、只读方式打开源文件
sF, err1 := os.Open(srcFileName)
if err1 != nil {
fmt.Println("Open err ", err1)
return
}
// 3、新建目的文件
dF, err2 := os.Create(dstFileName)
if err2 != nil {
fmt.Println("Create err ", err2)
return
}
// 4、从源文件读取内容,往目的文件写,读多少写多少
buf := make([]byte, 1024 * 4)
for {
n, err := sF.Read(buf) // //从源文件读取内容,n为读取文件内容的长度
if err != nil && err != io.EOF { // EOF代表文件读取完毕
fmt.Println("Read err ", err)
break
}
if n == 0 {
fmt.Println("文件处理完毕")
break
}
// 往目的文件写,读多少写多少
dF.Write(buf[:n])
}
// 5、关闭文件
sF.Close()
dF.Close()
}
把文件 x1.png 拷贝到文件y1.png,执行
go run a.go x1.png y2.png
11、并发编程
11.1、概述
11.1.1 并行和并发
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
- 并行是两个队列同时使用两台咖啡机
- 并发是两个队列交替使用一台咖啡机
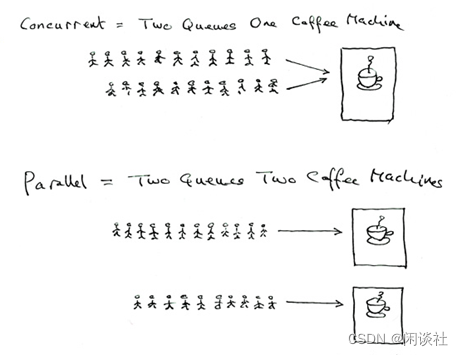
11.1.2 Go语言并发优势
有人把Go比作21世纪的C语言,第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持了并行。同时,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制。
Go语言为并发编程而内置的上层API基于CSP(communicating sequential processes, 顺序通信进程)模型。这就意味着显式锁都是可以避免的,因为Go语言通过相册安全的通道发送和接受数据以实现同步,这大大地简化了并发程序的编写。
一般情况下,一个普通的桌面计算机跑十几二十个线程就有点负载过大了,但是同样这台机器却可以轻松地让成百上千甚至过万个goroutine进行资源竞争。
11.2、goroutine
11.2.1 goroutine是什么
goroutine是Go并发设计的核心。goroutine说到底其实就是协程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
11.2.2 创建goroutine
只需在函数调用语句前添加 go 关键字,就可创建并发执行单元。开发人员无需了解任何执⾏细节,调度器会自动将其安排到合适的系统线程上执行。
在并发编程里,我们通常想讲一个过程切分成几块,然后让每个goroutine各自负责一块工作。当一个程序启动时,其主函数即在一个单独的goroutine中运行,我们叫它main goroutine。新的goroutine会用go语句来创建。
package main
import (
"fmt"
"time"
)
func newTask() {
i := 0
for {
i++
fmt.Printf("newTask go routine: i = %d\n", i)
time.Sleep(1 * time.Second) // 延时1秒
}
}
func main() {
go newTask()
i := 0
for {
i++
fmt.Printf("main go routine: i = %d\n", i)
time.Sleep(1 * time.Second) // 延时1秒
}
}
/*
main go routine: i = 1
newTask go routine: i = 1
newTask go routine: i = 2
main go routine: i = 2
main go routine: i = 3
newTask go routine: i = 3
newTask go routine: i = 4
main go routine: i = 4
main go routine: i = 5
newTask go routine: i = 5
newTask go routine: i = 6
main go routine: i = 6
*/
11.2.3 主goroutine先退出
主goroutine退出后,其它的工作goroutine也会自动退出:
func newTask() {
i := 0
for {
i++
fmt.Printf("newTask go routine: i = %d\n", i)
time.Sleep(1 * time.Second) // 延时1秒
}
}
func main() {
go newTask()
fmt.Println("main goroutine exit")
}
/*
main goroutine exit
*/
11.2.4 runtime包
11.2.4.1 Gosched
runtime.Gosched() 用于让出CPU时间片,让出当前goroutine的执行权限,调度器安排其他等待的任务运行,并在下次某个时候从该位置恢复执行。
这就像跑接力赛,A跑了一会碰到代码runtime.Gosched() 就把接力棒交给B了,A歇着了,B继续跑。
import (
"fmt"
"runtime"
)
func main() {
go func() {
for i := 0; i < 5; i++ {
fmt.Println("world")
}
} ()
for i := 0; i < 2; i++ {
// 让出时间片,先让别的协程执行,然后再回来执行此协程
runtime.Gosched()
fmt.Println("hello")
}
}
/*
不加 runtime.Gosched()的结果
hello
hello
加 runtime.Gosched()的结果
world
world
world
world
world
hello
hello
*/
11.2.4.2 Goexit
调用 runtime.Goexit() 将立即终止当前 goroutine 执行,调度器确保所有已注册 defer延迟调用被执行。
看下面几段代码
代码1:
func test() {
defer fmt.Println("C")
fmt.Println("D")
}
func main() {
go func() {
fmt.Println("A")
test()
fmt.Println("B")
} ()
//死循环,目的不让主goroutine结束
for {
}
}
/*
A
D
C
B
*/
代码2,修改test()函数
func test() {
defer fmt.Println("C")
return
fmt.Println("D")
}
func main() {
go func() {
fmt.Println("A")
test()
fmt.Println("B")
} ()
//死循环,目的不让主goroutine结束
for {
}
}
/*
A
C
B
*/
代码3,利用runtime.Goexit(),终止当前 goroutine
func test() {
defer fmt.Println("C")
runtime.Goexit() // 终止当前 goroutine, import "runtime"
fmt.Println("D")
}
func main() {
go func() {
fmt.Println("A")
test()
fmt.Println("B")
} ()
//死循环,目的不让主goroutine结束
for {
}
}
/*
A
C
*/
11.2.4.3 GOMAXPROCS
调用 runtime.GOMAXPROCS() 用来设置可以并行计算的CPU核数的最大值,并返回之前的值。
n := runtime.GOMAXPROCS(1) // 设置为单核
11.3、channel
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel 是 CSP 模式的具体实现,用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
11.3.1 channel类型
和map类似,channel也一个对应make创建的底层数据结构的引用。
当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
定义一个channel时,也需要定义发送到channel的值的类型。channel可以使用内置的make()函数来创建:
make(chan Type) //等价于make(chan Type, 0)
make(chan Type, capacity)
当 capacity= 0 时,channel 是无缓冲阻塞读写的,当capacity> 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入。
channel通过操作符<-来接收和发送数据,发送和接收数据语法:
channel <- value //发送value到channel
<-channel //接收并将其丢弃
x := <-channel //从channel中接收数据,并赋值给x
x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空
默认情况下,channel接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得goroutine同步变的更加的简单,而不需要显式的lock。
1)例子:通过channel实现分别打印
package main
import (
"fmt"
"time"
)
// 全局变量,创建一个channel
var ch = make(chan int)
//定义一个打印机,参数为字符串,按每个字符打印
func Printer(str string) {
for _, data := range str {
fmt.Printf("%c", data)
time.Sleep(time.Second)
}
fmt.Println("\n")
}
// person1执行完后,才能到person2执行
func person1() {
Printer("hello")
ch <- 1 //给管道写数据,发送
}
func person2() {
<- ch //从管道取数据,接收,如果通道没有数据就会阻塞
Printer("world")
}
func main() {
//新建2个协程,代表2个人,2个人同时使用打印机
go person1()
go person2()
for {
}
}
2)例子:通过channel实现先执行协程,再执行主协程
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan string)
go func() {
defer fmt.Println("子协程调用完毕")
for i := 0; i < 2; i++ {
fmt.Println("子协程 i =" , i)
time.Sleep(time.Second)
}
ch <- "子协程工作完毕"
}()
str := <-ch // 没有数据前,阻塞
fmt.Println("str = ", str)
fmt.Println("主协程结束")
}
/*
子协程 i = 0
子协程 i = 1
子协程调用完毕
str = 子协程工作完毕
主协程结束
*/
11.3.2 无缓冲的channel
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。
这种类型的通道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。如果两个goroutine没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值:
- 在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
- 在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
- 在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
- 在第 4 步和第 5 步,进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做别的事情了。
无缓冲的channel创建格式:
make(chan Type) //等价于make(chan Type, 0)
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int) //无缓冲的通道
fmt.Printf("len(ch) = %d, cap(ch) = %d\n", len(ch), cap(ch))
go func() {
defer fmt.Println("子协程调用完毕")
for i := 0; i < 3; i++ {
ch <- i // 往无缓冲的通道写内容,管道内有内容会阻塞
fmt.Printf("子协程[%d]正在运行:len(ch) = %d, cap(ch) = %d\n", i, len(ch), cap(ch))
}
}()
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <- ch // 读无缓冲的通道中内容,没内容会阻塞
fmt.Println("num = ", num)
}
fmt.Println("主协程结束")
}
/*
len(ch) = 0, cap(ch) = 0
num = 0
子协程[0]正在运行:len(ch) = 0, cap(ch) = 0
子协程[1]正在运行:len(ch) = 0, cap(ch) = 0
num = 1
num = 2
主协程结束
*/
11.3.3 有缓冲的channel
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。
这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
- 在第 1 步,右侧的 goroutine 正在从通道接收一个值。
- 在第 2 步,右侧的这个 goroutine独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。
- 在第 3 步,左侧的goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。
- 最后,在第 4 步,所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。
有缓冲的channel创建格式:
make(chan Type, capacity)
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 3) //有缓冲的通道
fmt.Printf("len(ch) = %d, cap(ch) = %d\n", len(ch), cap(ch))
go func() {
defer fmt.Println("子协程调用完毕")
for i := 0; i < 3; i++ {
ch <- i
fmt.Printf("子协程[%d]正在运行:len(ch) = %d, cap(ch) = %d\n", i, len(ch), cap(ch))
}
}()
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <- ch
fmt.Println("num = ", num)
}
fmt.Println("主协程结束")
}
/*
len(ch) = 0, cap(ch) = 3
子协程[0]正在运行:len(ch) = 1, cap(ch) = 3
子协程[1]正在运行:len(ch) = 2, cap(ch) = 3
子协程[2]正在运行:len(ch) = 3, cap(ch) = 3
子协程调用完毕
num = 0
num = 1
num = 2
主协程结束
*/
11.3.4 无缓冲channel和有缓冲channel的对比
无缓冲channel
package main
import (
"fmt"
"time"
)
func main() {
ch:= make(chan string)
//写数据协程
go func() {
fmt.Println("写协程开启:",time.Now())
time.Sleep(2*time.Second) //等待2秒
ch<-"1"
fmt.Println("写入成功 :",time.Now())
}()
//读数据协程
go func() {
fmt.Println("读协程开启:",time.Now())
<-ch
fmt.Println("读取成功 :",time.Now())
}()
time.Sleep(5*time.Second) //等待5秒,让所有协程跑完再退出
fmt.Println("ok")
}
运行结果是
读协程开启: 2023-12-09 12:02:30.9883366 +0800 CST m=+0.003072801
写协程开启: 2023-12-09 12:02:30.9883366 +0800 CST m=+0.003072801
写入成功 : 2023-12-09 12:02:33.0092825 +0800 CST m=+2.024018701
读取成功 : 2023-12-09 12:02:33.0092825 +0800 CST m=+2.024018701
ok
可以从结果看出:写协程和读协程是同时执行的,打印的时间是一致的。而写协程中间有个两秒的等待,正常情况下,读协助程的退出时间要比写程退出时间要早两秒。但是从结果上看,它们是同一时间退出的。说明无缓部通道中,读取时如果没有数据写入,协程会阻塞至有数据写入。
有缓冲channel
package main
import (
"fmt"
"time"
)
func main() {
ch:= make(chan string, 5)
//写数据协程
go func() {
fmt.Println("写协程开启:",time.Now())
ch<-"1"
fmt.Println("写入成功 :",time.Now())
}()
//读数据协程
go func() {
fmt.Println("读协程开启:",time.Now())
time.Sleep(2*time.Second) //等待2秒
<-ch
fmt.Println("读取成功 :",time.Now())
}()
time.Sleep(5*time.Second) //等待5秒,让所有协程跑完再退出
fmt.Println("ok")
}
运行结果是
读协程开启: 2023-12-09 12:07:09.1589227 +0800 CST m=+0.002673901
写协程开启: 2023-12-09 12:07:09.1589227 +0800 CST m=+0.002673901
写入成功 : 2023-12-09 12:07:09.1768065 +0800 CST m=+0.020557701
读取成功 : 2023-12-09 12:07:11.1798902 +0800 CST m=+2.023641401
ok
从结果中可以看出,两个goroutine的开启时间是一致的,而两个goroutine的结束时间有2秒的时间差,也就是说,写协程往channel写完数据便退出了。因此可以确定,有缓冲的通道是没有阻塞等待的。
以送信为例,邮递员和收信人就是两个goroutine,而信箱就是一个channel。无缓存的channel就像是快邮递员必须要等收件员准备好才会把信放进信箱。如果收信人不在,或没有准备好,则会一直等到收信人准备好才把信放进信箱。而有缓存的channel则是,邮递员把信放进信箱就走了,至于收信人什么时候过来取,他不会关心。
11.3.5 range和close
如果发送者知道,没有更多的值需要发送到channel的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close函数来关闭channel实现。
func main() {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch <- i // 往通道写内容
}
// 不需要再写数据时,关闭channel
close(ch)
//把 close(ch) 注释掉,程序会一直阻塞在 if data, ok := <-ch; ok 那一行
}()
for {
// 如果 ok == true ,说明管道没有关闭
if num, ok := <- ch; ok {
fmt.Println("num = ", num)
} else { // 管道关闭
break
}
}
fmt.Println("Finished")
}
/*
num = 0
num = 1
num = 2
num = 3
num = 4
Finished
*/
注意点:
- channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束range循环之类的,才去关闭channel;
- 关闭channel后,无法向channel 再发送数据(引发 panic 错误后导致接收立即返回零值);
- 关闭channel后,可以继续向channel接收数据;
可以使用 range 来迭代不断操作channel:
func main() {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch <- i // 往通道写内容
}
// 不需要再写数据时,关闭channel
close(ch)
}()
for data := range ch {
fmt.Println("num = ", data)
}
fmt.Println("Finished")
}
/*
num = 0
num = 1
num = 2
num = 3
num = 4
Finished
*/
11.3.6 单方向的channel
默认情况下,通道是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而值希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。
单向channel变量的声明非常简单,如下:
var ch1 chan int // ch1是一个正常的channel,不是单向的
var ch2 chan<- float64 // ch2是单向channel,只用于写float64数据
var ch3 <-chan int // ch3是单向channel,只用于读取int数据
chan<-表示数据进入管道,要把数据写进管道,对于调用者就是输出。<-chan表示数据从管道出来,对于调用者就是得到管道的数据,当然就是输入。
可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为普通 channel:
func main() {
ch := make(chan int, 3)
var send chan<- int = ch // 单向 -- 发送
var recv <-chan int = ch // 单向 -- 接收
send <- 1
// <- send //invalid operation: <-send (receive from send-only type chan<- int)
<-recv
// recv<- 2 //invalid operation: recv <- 2 (send to receive-only type <-chan int)
//不能将单向 channel 转换为普通 channel
d1 := (chan int)(send) // cannot convert send (type chan<- int) to type chan int
d2 := (chan int)(recv) // cannot convert recv (type <-chan int) to type chan int
}
示例代码:
func counter(out chan<- int) {
defer close(out)
for i := 0; i < 5; i++ {
out <- i // 如果对方不读 会阻塞
}
}
func printer(in <-chan int) {
for num := range in {
fmt.Println("num = ", num)
}
}
func main() {
ch := make(chan int)
go counter(ch) // 生产者,生产数字,写入channel
printer(ch) // 消费者,从channel读取内容,打印
fmt.Println("finish")
}
/*
num = 0
num = 1
num = 2
num = 3
num = 4
finish
*/
11.3.6 定时器
11.3.6.1 Timer
Timer是一个定时器,代表未来的一个单一事件,你可以告诉timer你要等待多长时间,它提供一个channel,在将来的那个时间那个channel提供了一个时间值。
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个定时器,设置时间为2s,2s后,往time通道写内容(当前时间)
timer := time.NewTimer(2 * time.Second)
fmt.Println("当前时间:", time.Now())
// 2s后,往timer.C写数据,有数据后,就可以读取
t := <-timer.C // channel没有数据时前后阻塞
fmt.Println("当前时间:", t)
}
/*
当前时间: 2023-11-17 15:30:55.5956502 +0800 CST m=+0.005449701
当前时间: 2023-11-17 15:30:57.6006969 +0800 CST m=+2.010496401
*/
1、Time实现延时功能的几种方法
1)
func main() {
timer := time.NewTimer(2 * time.Second)
<-timer.C
fmt.Println("时间到")
}
2)
func main() {
time.Sleep(2 * time.Second)
fmt.Println("时间到")
}
3)
func main() {
<-time.After(2 * time.Second) //定时2s,阻塞2s,2s后产生一个事件,往channol写内容
fmt.Println("时间到")
}
2、停止定时器
func main() {
timer := time.NewTimer(3 * time.Second)
go func () {
<-timer.C
fmt.Println("3s时间到,定时器timer过期")
}()
stop := timer.Stop()
if stop {
fmt.Println("定时器timer已经停止")
}
}
3、重置定时器
func main() {
timer := time.NewTimer(3 * time.Second)
timer.Reset(1 * time.Second) // 重新设置为 1s
<-timer.C
fmt.Println("时间到,定时器timer过期")
}
11.3.6.2 Ticker
Ticker是一个定时触发的计时器,它会以一个间隔(interval)往channel发送一个事件(当前时间),而channel的接收者可以以固定的时间间隔从channel中读取事件
func main() {
//创建定时器,每隔1秒后,定时器就会给channel发送一个事件(当前时间)
ticker := time.NewTicker(1 * time.Second)
i := 0
for {
<-ticker.C
i++
fmt.Println("i = ", i)
if i == 5 {
ticker.Stop() //停止定时器
break
}
}
}
11.4 select
11.4.1 select作用
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
与switch语句可以选择任何可使用相等比较的条件相比, select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作,大致的结构如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
在一个select语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况:
- 如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。
- 如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以进行下去。
利用select实现斐波那契数列
unc fibonacci(ch chan<- int, quit <-chan bool) {
x, y := 1, 1
for {
select {
case ch <- x:
x, y = y ,x + y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
ch := make(chan int) // 数字通信
quit := make(chan bool) // 程序是否结束的标记
// 消费者,从channel读取内容
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-ch) // 阻塞,知道channel有内容
}
quit <- false
}()
// 生产者,产生数字,写入channel
fibonacci(ch, quit)
}
11.4.2 超时
有时候会出现goroutine阻塞的情况,那么我们如何避免整个程序进入阻塞的情况呢?我们可以利用select来设置超时,通过如下的方式实现:
例子:3s没有输入,超时退出
func main() {
ch := make(chan int)
quit := make(chan bool)
go func() {
for {
select {
case num := <-ch:
fmt.Println("num = ", num)
case <-time.After(3 * time.Second):
fmt.Println("超时")
quit <- true
}
}
} ()
<- quit
fmt.Println("程序结束")
}
12、网络编程
12.1、网络概述
12.1.1 网络协议
从应用的角度出发,协议可理解为“规则”,是数据传输和数据的解释的规则。
假设,A、B双方欲传输文件。规定:
- 第一次,传输文件名,接收方接收到文件名,应答OK给传输方;
- 第二次,发送文件的尺寸,接收方接收到该数据再次应答一个OK;
- 第三次,传输文件内容。同样,接收方接收数据完成后应答OK表示文件内容接收成功。
由此,无论A、B之间传递何种文件,都是通过三次数据传输来完成。A、B之间形成了一个最简单的数据传输规则。双方都按此规则发送、接收数据。A、B之间达成的这个相互遵守的规则即为协议。
这种仅在A、B之间被遵守的协议称之为原始协议。
当此协议被更多的人采用,不断的增加、改进、维护、完善。最终形成一个稳定的、完整的文件传输协议,被广泛应用于各种文件传输过程中。该协议就成为一个标准协议。最早的ftp协议就是由此衍生而来。
12.1.2 分层模型
12.1.2.1 网络分层架构
为了减少协议设计的复杂性,大多数网络模型均采用分层的方式来组织。每一层都有自己的功能,就像建筑物一样,每一层都靠下一层支持。每一层利用下一层提供的服务来为上一层提供服务,本层服务的实现细节对上层屏蔽。

越下面的层,越靠近硬件;越上面的层,越靠近用户。
12.1.2.2 层与协议
每一层都是为了完成一种功能,为了实现这些功能,就需要大家都遵守共同的规则。大家都遵守这规则,就叫做“协议”(protocol)。
网络的每一层,都定义了很多协议。这些协议的总称,叫“TCP/IP协议”。TCP/IP协议是一个大家族,不仅仅只有TCP和IP协议,它还包括其它的协议,如下图:
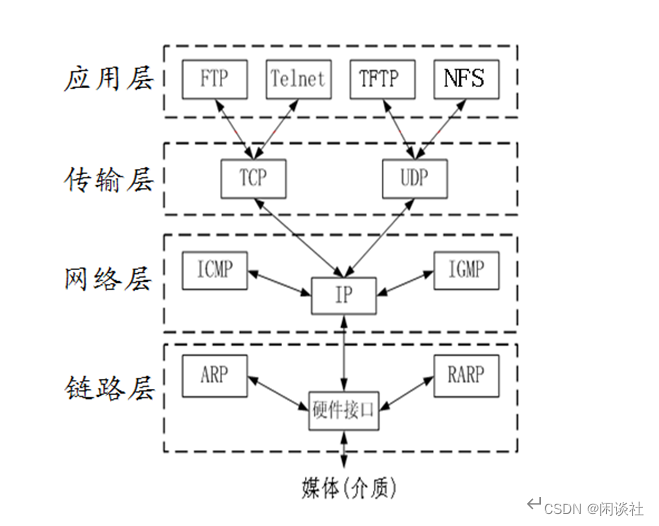
- ARP:是正向地址解析协议(Address Resolution Protocol),通过已知的IP,寻找对应主机的MAC 地址。
- RARP:是反向地址转换协议,通过 MAC 地址确定IP 地址。
- IP:是因特网互联协议 (Intemet Protocol)
- ICMP:是Internet 控制报文协议(Internet Control Message Protocol) 它是 TCP/IP 协议族的一个子协议,用于在IP主机、路由器之间传递控制消息。
- IGMP:是 Intemet 组管理协议 (Intemet Group Management Protocol),是因特网协议家族中的一个组播协议。该协议运行在主机和组播路由器之间。
- TCP:传输控制协议(Transmission ControlProtocol),是一种面向连接的、可靠的、基于字节流的传输层通信协议。
- UDP:用户数据报协议(User Datagram Protocol),是OSI 参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。HTTP:超文本传输协议(Hyper Text Transfer Protocol),是互联网上应用最为广泛的一种网络协议。
- FTP:文件传输协议(File Transfer Protocol)
12.1.2.3 每层协议的功能
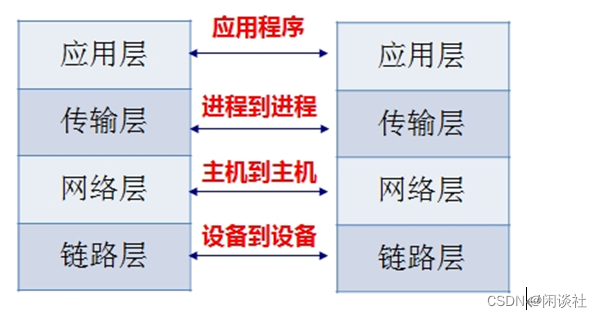
1)链路层
以太网规定,连入网络的所有设备,都必须具有“网卡”接口。数据包必须是从一块网卡,传送到另一块网卡。通过网卡能够使不同的计算机之间连接,从而完成数据通信等功能。网卡的地址——MAC 地址,就是数据包的物理发送地址和物理接收地址。
2)网络层
网络层的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做“网络地址”,这是我们平时所说的IP地址。这个IP地址好比我们的手机号码,通过手机号码可以得到用户所在的归属地。
网络地址帮助我们确定计算机所在的子网络,MAC 地址则将数据包送到该子网络中的目标网卡。网络层协议包含的主要信息是源IP和目的IP。
于是,“网络层”出现以后,每台计算机有了两种地址,一种是 MAC 地址,另一种是网络地址。两种地址之间没有任何联系,MAC 地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合在一起。
网络地址帮助我们确定计算机所在的子网络,MAC 地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理 MAC 地址。
3)传输层
当我们一边聊QQ,一边聊微信,当一个数据包从互联网上发来的时候,我们怎么知道,它是来自QQ的内容,还是来自微信的内容?
也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做“端口”(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
端口特点:
对于同一个端口,在不同系统中对应着不同的进程
对于同一个系统,一个端口只能被一个进程拥有
4)应用层
应用程序收到“传输层”的数据,接下来就要进行解读。由于互联网是开放架构,数据来源五花八门,必须事先规定好格式,否则根本无法解读。“应用层”的作用,就是规定应用程序的数据格式。

12.2、Socket编程
12.2.1 什么是Socket
Socket起源于Unix,而Unix基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,网络的Socket数据传输是一种特殊的I/O,Socket也是一种文件描述符。Socket也具有一个类似于打开文件的函数调用:Socket(),该函数返回一个整型的Socket描述符,随后的连接建立、数据传输等操作都是通过该Socket实现的。
常用的Socket类型有两种:流式Socket(SOCK_STREAM)和数据报式Socket(SOCK_DGRAM)。流式是一种面向连接的Socket,针对于面向连接的TCP服务应用;数据报式Socket是一种无连接的Socket,对应于无连接的UDP服务应用。
12.2.2 TCP的C/S架构
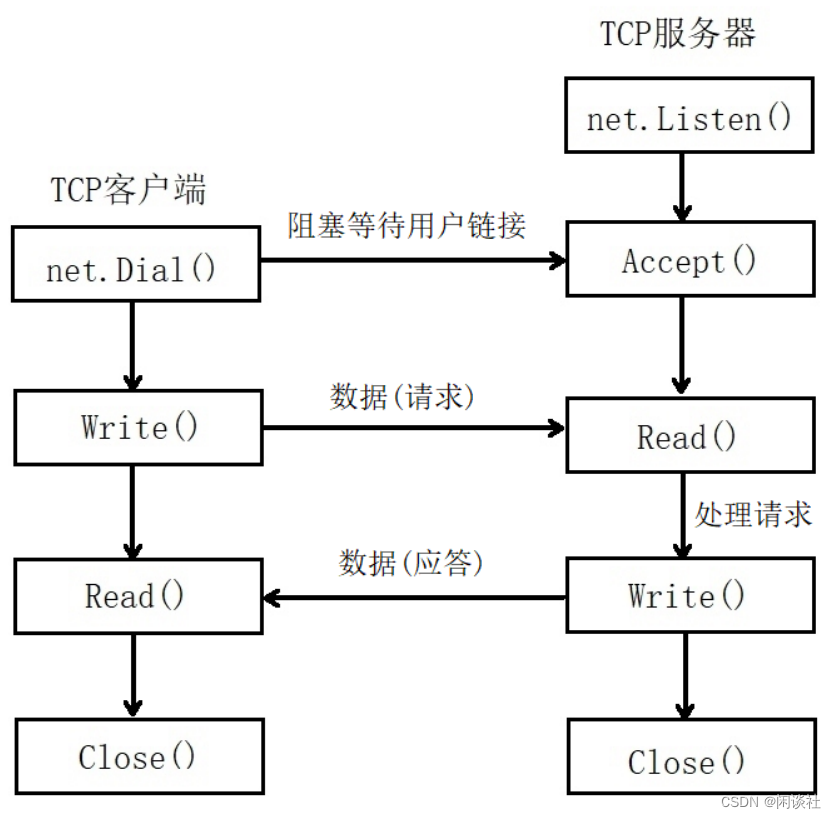
12.2.3 C/S示例程序
实现功能:
1、客户端发送消息
2、服务端接收消息,并转为大写字母,回发给客户端
3、客户端接收服务端回发的消息
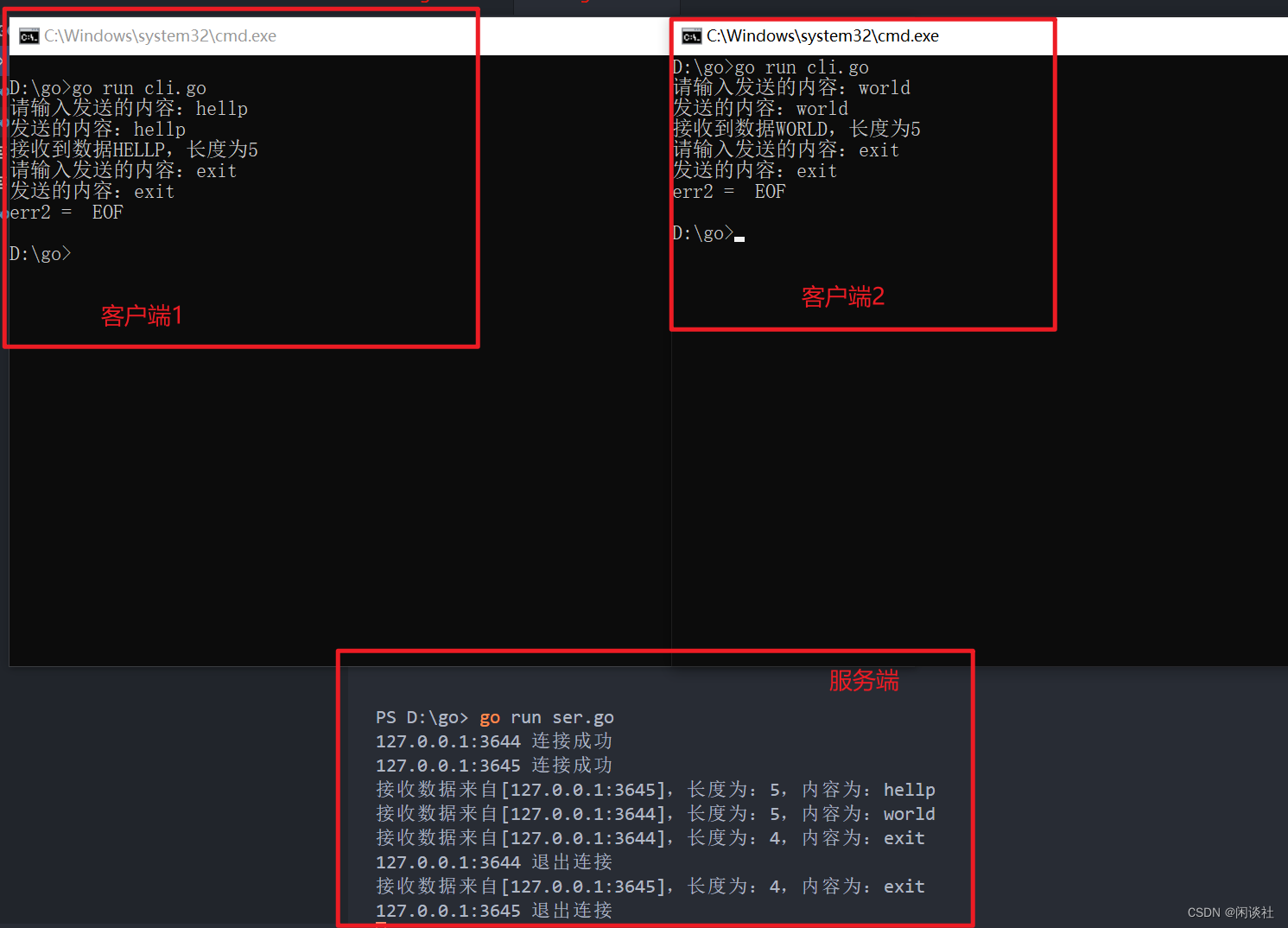
**12.2.3.1 服务器代码 **
package main
import (
"fmt"
"net"
"strings"
)
func Handleconn(conn net.Conn) {
//此函数结束时,关闭连接套接字
defer conn.Close()
// conn.RemoteAddr().String():获取连接客服端的网络地址
addr := conn.RemoteAddr().String()
fmt.Println(addr, "连接成功")
//缓冲区,用于接收客户端发送的数据
buf := make([]byte, 1024*2)
for {
//阻塞等待用户发送的数据
n, err3 := conn.Read(buf)
if err3 != nil {
fmt.Println("err3 = ", err3)
return
}
//切片截取,只截取有效数据
result := buf[:n]
fmt.Printf("接收数据来自[%s],长度为:%d,内容为:%s\n", addr, n, string(result))
//如果对方发送"exit",退出此连接
if string(result) == "exit" {
fmt.Println(addr, "退出连接")
return
}
//把接收到的数据转换为大写,再给客户端发送
conn.Write([]byte(strings.ToUpper(string(result))))
}
}
func main() {
//创建、监听socket
listener, err1 := net.Listen("tcp", "127.0.0.1:8000")
if err1 != nil {
fmt.Println("err = ", err1)
return
}
defer listener.Close()
for {
//阻塞等待客户端连接
conn, err2 := listener.Accept()
if err2 != nil {
fmt.Println("err2 = ", err2)
continue
}
go Handleconn(conn)
}
}
12.2.3.2 客服端代码
package main
import (
"fmt"
"net"
)
func main() {
conn, err1 := net.Dial("tcp", "127.0.0.1:8000")
if err1 != nil {
fmt.Println("err1 = ", err1)
return
}
defer conn.Close()
buf := make([]byte, 1024)
for {
fmt.Printf("请输入发送的内容:")
fmt.Scan(&buf)
fmt.Printf("发送的内容:%s\n", buf)
conn.Write(buf)
n, err2 := conn.Read(buf)
if err2 != nil {
fmt.Println("err2 = ", err2)
return
}
result := buf[:n]
fmt.Printf("接收到数据%s,长度为%d\n", string(result), n)
}
}
12.2.4 文件传输示例程序
实现功能:
1、客户端发送文件
2、服务端接收保存文件
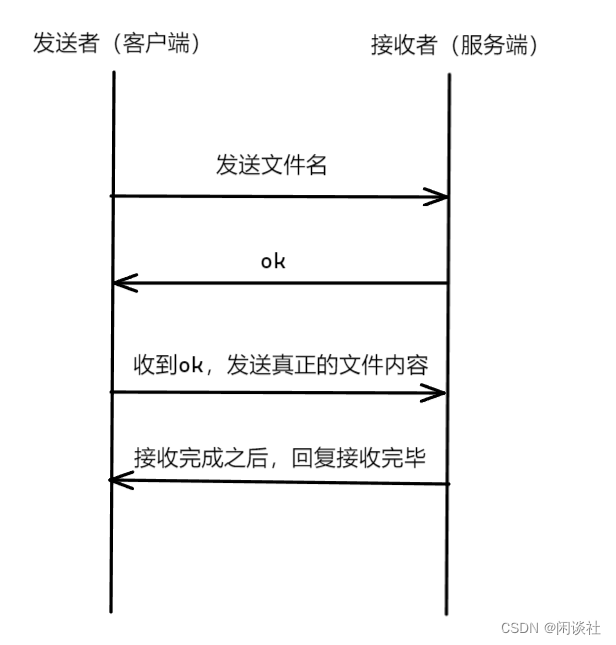

12.2.4.1 服务端代码
package main
import (
"fmt"
"io"
"net"
"os"
)
// 接收具体的文件内容
func RecvFile(fileName string, conn net.Conn) {
file, err4 := os.Create(fileName)
if err4 != nil {
fmt.Println("os.Create err4 = ", err4)
return
}
defer file.Close()
// 接收多少,写多少
buf := make([]byte, 4*1024)
for {
n, err5 := conn.Read(buf)
if err5 != nil {
if err5 == io.EOF {
fmt.Println("文件接收完毕")
} else {
fmt.Println("conn.Read err5 = ", err5)
}
return
}
result := buf[:n]
conn.Write(result)
}
}
func main() {
// 监听
Listener, err1 := net.Listen("tcp", "127.0.0.1:8000")
if err1 != nil {
fmt.Println("net.Listen err1 = ", err1)
return
}
defer Listener.Close()
// 阻塞等待连接
conn, err2 := Listener.Accept()
if err2 != nil {
fmt.Println("Listener.Accept err2 = ", err2)
return
}
defer conn.Close()
// 读取文件内容,一开始接收的是文件名,然后回复ok
buf := make([]byte, 1024)
n, err3 := conn.Read(buf)
if err3 != nil {
fmt.Println("conn.Read err3 = ", err3)
return
}
fileName := string(buf[:n])
conn.Write([]byte("ok"))
// 接收具体的文件内容
RecvFile(fileName, conn)
}
12.2.4.2 客服端代码
package main
import (
"fmt"
"io"
"net"
"os"
)
func SendFile(path string, conn net.Conn) {
// 打开文件,只读
file, err5 := os.Open(path)
if err5 != nil {
fmt.Println("os.Open err5 = ", err5)
return
}
defer file.Close()
// 读多少,写多少
bufFile := make([]byte, 1024*4)
for {
n, err6 := file.Read(bufFile)
if err6 != nil {
if err6 == io.EOF {
fmt.Println("文件发送完毕")
} else {
fmt.Println("file.Read err5 = ", err6)
}
return
}
result := bufFile[:n]
// 发送文件内容
file.Write(result)
}
}
func main() {
// 提示输入文件
fmt.Println("请输入要传输的文件路径:")
var path string
fmt.Scan(&path)
// 获取文件属性,为了后续使用文件名
info, err1 := os.Stat(path)
if err1 != nil {
fmt.Println("os.Stat err1 = ", err1)
return
}
// 主动连接服务器
conn, err2 := net.Dial("tcp", "127.0.0.1:8000")
if err2 != nil {
fmt.Println("net.Dial err2 = ", err1)
return
}
defer conn.Close()
// 给接收方发送文件名
_, err3 := conn.Write([]byte(info.Name()))
if err3 != nil {
fmt.Println("conn.Write err3 = ", err3)
return
}
// 接收对方的回复,如果回复“ok”,说明对方做好准备,可以发送文件
buf := make([]byte, 1024)
n, err4 := conn.Read(buf)
if err4 != nil {
fmt.Println("conn.Read err4 = ", err4)
return
}
if string(buf[:n]) == "ok" {
// 发送文件内容
SendFile(path, conn)
}
}
12.2.5 并发聊天室示例程序
并发聊天室服务器 功能:
1、聊天室
2、某个用户上线或者下线,大家都能收到通知
3、”who“命令,查看当前在线用户
4、60s没有消息,该用户自动退出
5、”rename: newName”命令重命名
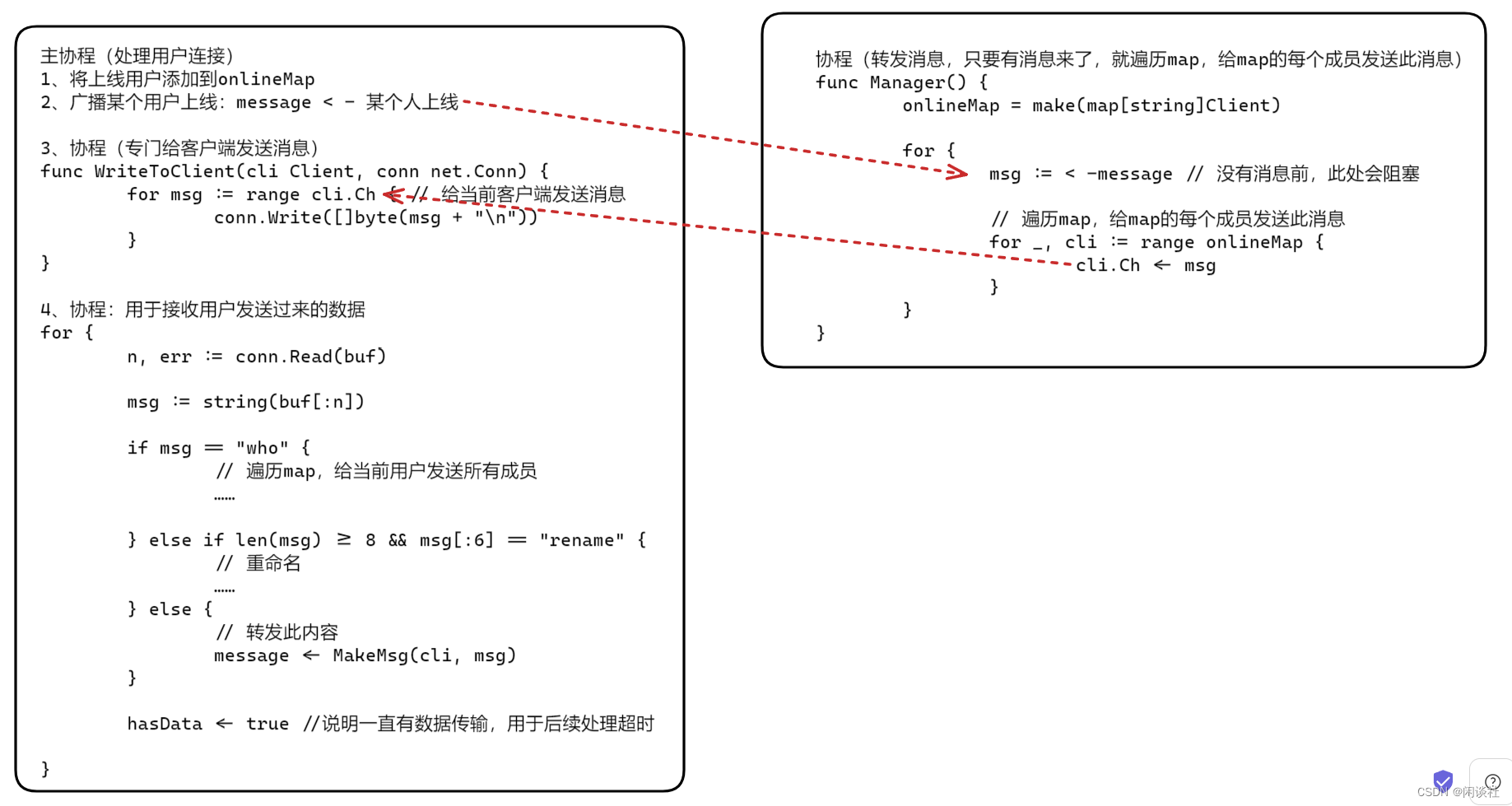
12.2.5.1 服务器代码
package main
import (
"fmt"
"net"
"strings"
"time"
)
type Client struct {
Ch chan string // 用户发送数据的管道
Name string // 用户名
Addr string // 网络地址
}
// 保存在线用户
var onlineMap map[string]Client
var message = make(chan string)
// 新开一个协程,用于转发消息,只要有消息来了,就遍历map,给map的每个成员发送此消息
func Manager() {
onlineMap = make(map[string]Client)
for {
msg := <-message // 没有消息前,此处会阻塞
// 遍历map,给map的每个成员发送此消息
for _, cli := range onlineMap {
cli.Ch <- msg
}
}
}
func WriteToClient(cli Client, conn net.Conn) {
for msg := range cli.Ch { // 给当前客户端发送消息
conn.Write([]byte(msg + "\n"))
}
}
func MakeMsg(cli Client, msg string) (buf string) {
buf = "[" + cli.Addr + "]" + cli.Name + ": " + msg
return
}
// 处理用户连接
func HandleConn(conn net.Conn) {
defer conn.Close()
// 获取客户端的网络地址
cliAddr := conn.RemoteAddr().String()
// 创建一个结构体,默认用户名和网络地址一样
cli := Client{make(chan string), cliAddr, cliAddr}
// 把结构体添加到map
onlineMap[cliAddr] = cli
// 新开一个协程,专门给客户端发送消息
go WriteToClient(cli, conn)
// 广播某个用户登录
message <- MakeMsg(cli, "login")
// 判读对方是否主动退出
isQuit := make(chan bool)
// 判断对方是否有数据传输
hasData := make(chan bool)
// 新建协程,用于接收用户发送过来的数据
go func() {
buf := make([]byte, 2*2048)
for {
n, err := conn.Read(buf)
if n == 0 { // 对方断开或者出问题
isQuit <- true
fmt.Println("conn.Read err = ", err)
return
}
msg := string(buf[:n])
if msg == "who" {
// 遍历map,给当前用户发送所有成员
conn.Write([]byte("list of online users: \n"))
for _, tmp := range onlineMap {
msg = tmp.Addr + ": " + tmp.Name + "\n"
conn.Write([]byte(msg))
}
} else if len(msg) >= 8 && msg[:6] == "rename" {
name := strings.Split(msg, ":")[1]
cli.Name = name
onlineMap[cliAddr] = cli
conn.Write([]byte("he rename succeeded\n"))
} else {
// 转发此内容
message <- MakeMsg(cli, msg)
}
hasData <- true //说明一直有数据传输
}
}()
for {
select {
case <-isQuit:
delete(onlineMap, cliAddr) // 将当前用户从map删除
message <- MakeMsg(cli, "this user has logged out")
return
case <-hasData:
case <-time.After(10 * time.Second):
delete(onlineMap, cliAddr) // 将当前用户从map删除
message <- MakeMsg(cli, "this user has logged out after a timeout")
return
}
}
}
func main() {
// 监听
listener, err := net.Listen("tcp", "127.0.0.1:8000")
if err != nil {
fmt.Println("net.Listen err = ", err)
return
}
defer listener.Close()
// 新开一个协程,用于转发消息,只要有消息来了,就遍历map,给map的每个成员发送此消息
go Manager()
// 主协程,循环阻塞等待用户输入
for {
conn, err1 := listener.Accept()
if err1 != nil {
fmt.Println("listener.Accept err1 = ", err1)
return
}
// 处理用户连接
go HandleConn(conn)
}
}
执行服务器程序
go run ser.go
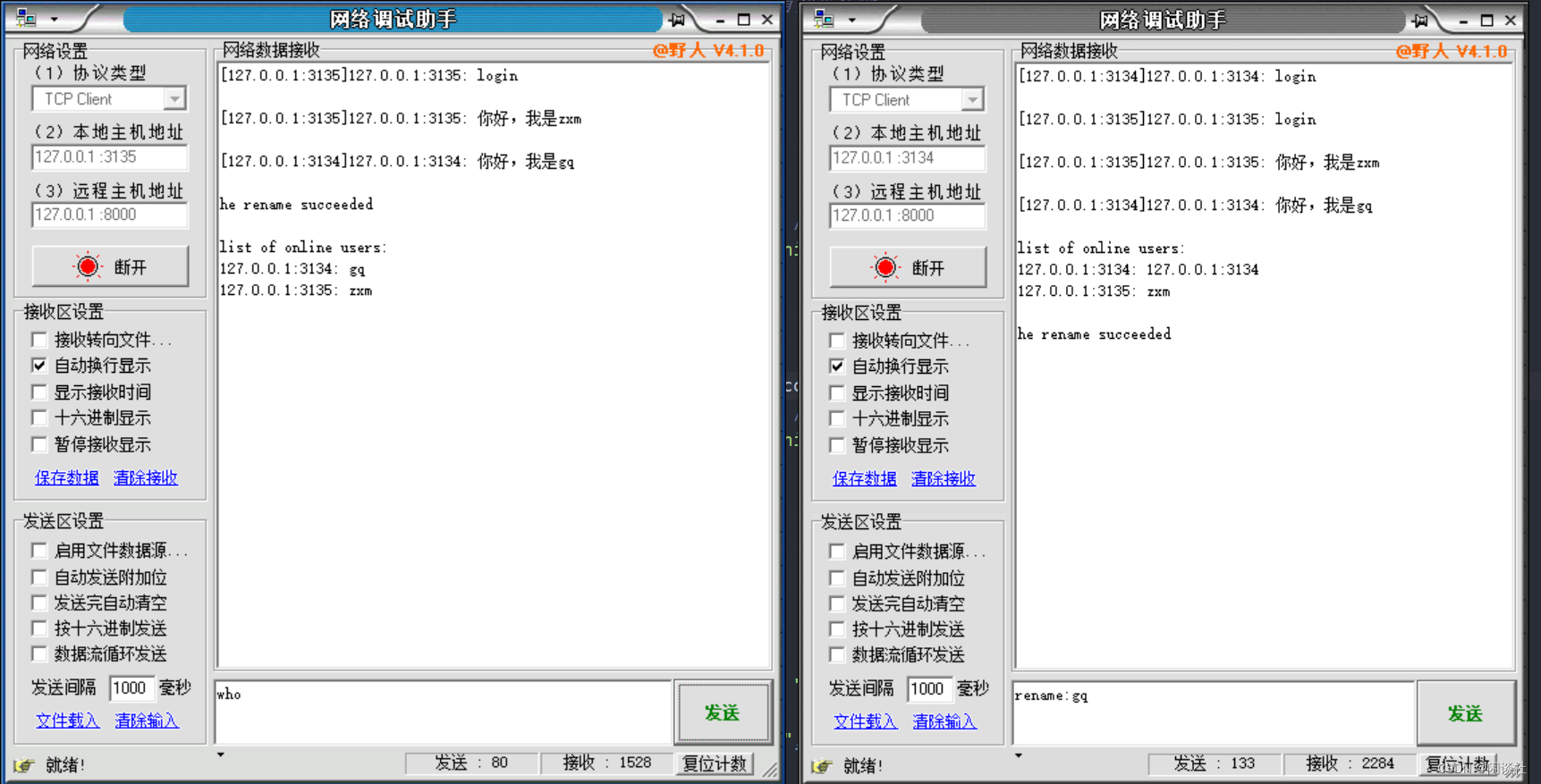
12.3、HTTP编程
12.3.1 概述
12.3.1.1 Web工作方式
我们平时浏览网页的时候,会打开浏览器,输入网址后按下回车键,然后就会显示出你想要浏览的内容。
对于普通的上网过程,系统其实是这样做的:浏览器本身是一个客户端,当你输入URL的时候,
- 首先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP
- 然后通过IP地址找到IP对应的服务器后,要求建立TCP连接,等浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回HTTP Response(响应)包
- 客户端收到来自服务器的响应后开始渲染这个Response包里的主体(body),等收到全部的内容随后断开与该服务器之间的TCP连接。
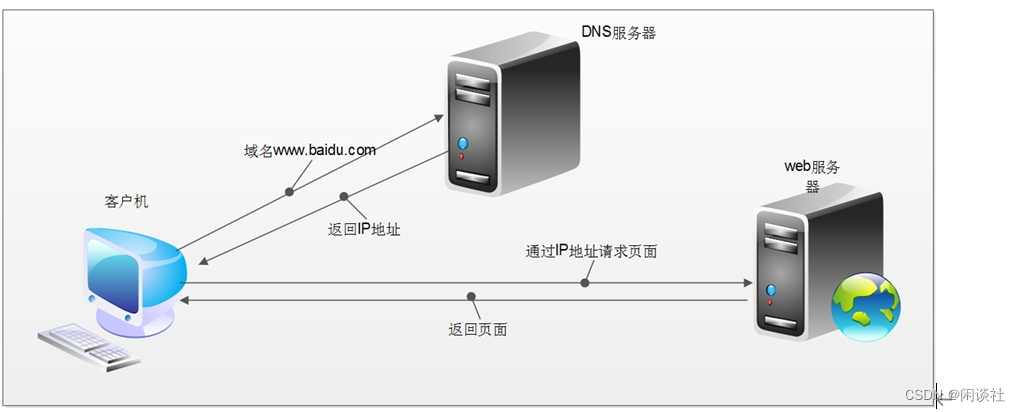
一个Web服务器也被称为HTTP服务器,它通过HTTP协议与客户端通信。这个客户端通常指的是Web浏览器(其实手机端客户端内部也是浏览器实现的)。
Web服务器的工作原理可以简单地归纳为:
- 客户机通过TCP/IP协议建立到服务器的TCP连接
- 客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档
- 服务器向客户机发送HTTP协议应答包,如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理“动态内容”,并将处理得到的数据返回给客户端
- 客户机与服务器断开。由客户端解释HTML文档,在客户端屏幕上渲染图形结果
12.3.1.2 HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议,它详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:
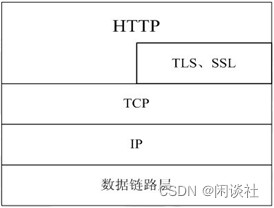
12.3.2 HTTP报文浅析
12.3.2.1 请求报文格式
1)测试代码
服务器测试代码:
package main
import (
"fmt"
"net"
)
func main() {
listener, err1 := net.Listen("tcp", "127.0.0.1:8000")
if err1 != nil {
fmt.Println("net.Listen err1 = ", err1)
return
}
defer listener.Close()
conn, err2 := listener.Accept()
if err2 != nil {
fmt.Println("listener.Accept err2 = ", err2)
return
}
defer conn.Close()
ipAddr := conn.RemoteAddr().String()
buf := make([]byte, 1024)
n, err3 := conn.Read(buf)
if n == 0 {
fmt.Println("conn.Read err3 = ", err3)
return
}
result := buf[:n]
fmt.Printf("接收到数据来自[%s] -->: \n%s\n", ipAddr, string(result))
}
浏览器输入url地址:http://127.0.0.1:8000/mike
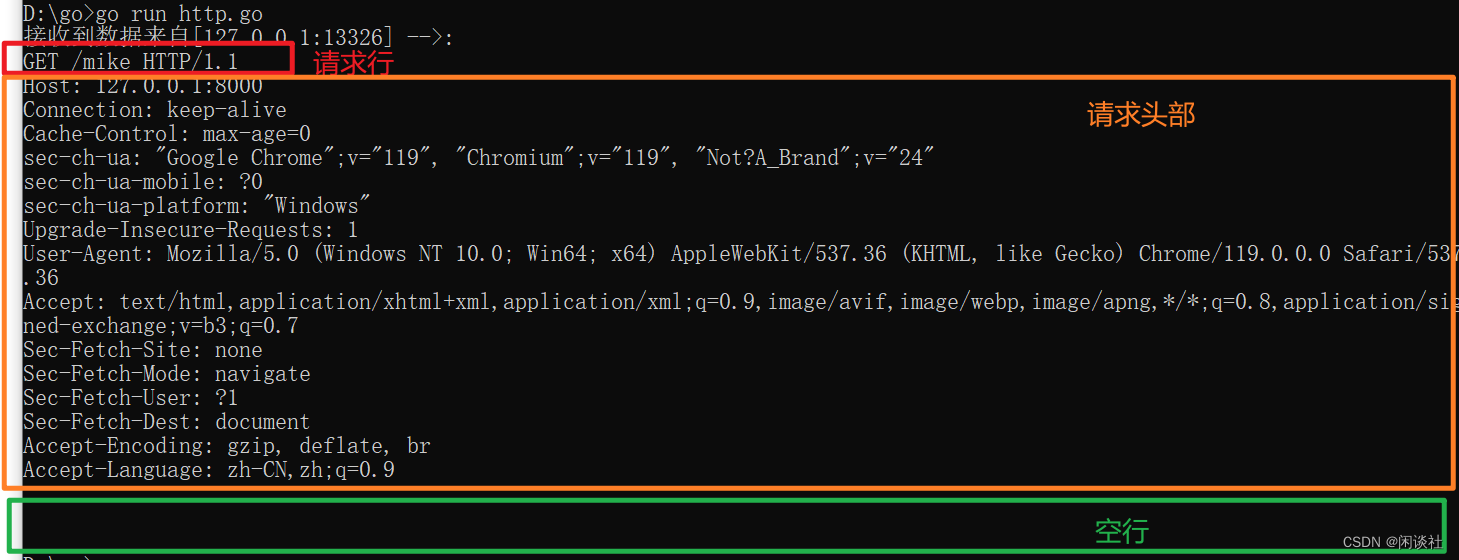
2)请求报文格式说明
HTTP 请求报文由请求行、请求头部、空行、请求包体4个部分组成,如下图所示:
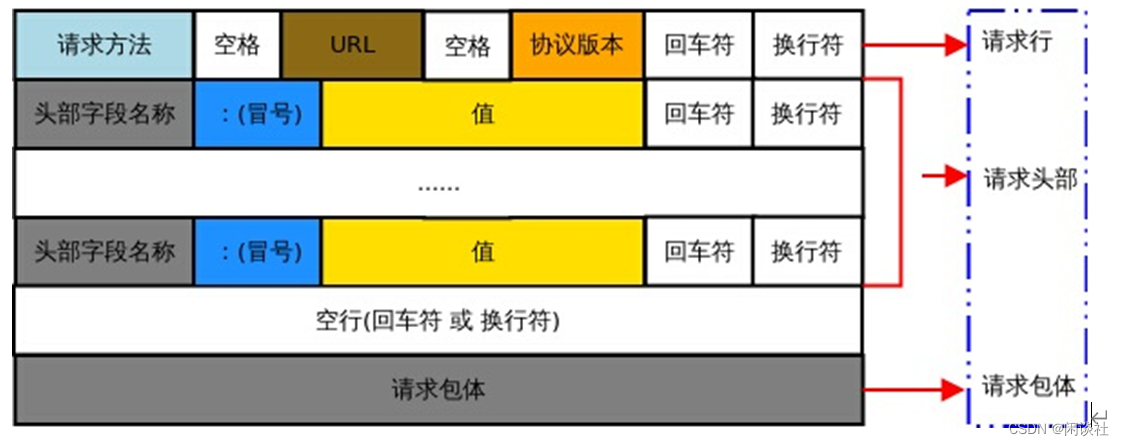
2.1)请求行
请求行由方法字段、URL 字段 和HTTP 协议版本字段 3 个部分组成,他们之间使用空格隔开。常用的 HTTP 请求方法有 GET、POST。
GET:
- 当客户端要从服务器中读取某个资源时,使用GET 方法。GET 方法要求服务器将URL 定位的资源放在响应报文的数据部分,回送给客户端,即向服务器请求某个资源。
- 使用GET方法时,请求参数和对应的值附加在 URL 后面,利用一个问号(“?”)代表URL 的结尾与请求参数的开始,传递参数长度受限制,因此GET方法不适合用于上传数据。
- 通过GET方法来获取网页时,参数会显示在浏览器地址栏上,因此保密性很差。
POST:
- 当客户端给服务器提供信息较多时可以使用POST 方法,POST 方法向服务器提交数据,比如完成表单数据的提交,将数据提交给服务器处理。
- GET 一般用于获取/查询资源信息,POST 会附带用户数据,一般用于更新资源信息。POST 方法将请求参数封装在HTTP 请求数据中,而且长度没有限制,因为POST携带的数据,在HTTP的请求正文中,以名称/值的形式出现,可以传输大量数据。
2.2) 请求头部
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
请求头部通知服务器有关于客户端请求的信息,典型的请求头有:

2.3) 空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
2.4) 请求包体
请求包体不在GET方法中使用,而是POST方法中使用。
POST方法适用于需要客户填写表单的场合。与请求包体相关的最常使用的是包体类型Content-Type和包体长度Content-Length。
12.3.2.2 响应报文格式
1)测试代码
服务器示例代码:
package main
import (
"fmt"
"net/http"
)
//服务端编写的业务逻辑处理程序
func myHandler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "hello world")
}
func main() {
http.HandleFunc("/go", myHandler)
//在指定的地址进行监听,开启一个HTTP
http.ListenAndServe("127.0.0.1:8000", nil)
}
启动服务器程序:
go run ser.go
客户端测试示例代码:
package main
import (
"fmt"
"log"
"net"
)
func main() {
//客户端主动连接服务器
conn, err := net.Dial("tcp", "127.0.0.1:8000")
if err != nil {
log.Fatal(err) //log.Fatal()会产生panic
return
}
defer conn.Close() //关闭
requestHeader := "GET /go HTTP/1.1\r\nAccept: image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, application/x-ms-xbap, */*\r\nAccept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729)\r\nAccept-Encoding: gzip, deflate\r\nHost: 127.0.0.1:8000\r\nConnection: Keep-Alive\r\n\r\n"
//先发送请求包
conn.Write([]byte(requestHeader))
buf := make([]byte, 4096) //缓冲区
//阻塞等待服务器回复的数据
n, err := conn.Read(buf) //n代码接收数据的长度
if err != nil {
fmt.Println(err)
return
}
//切片截取,只截取有效数据
result := buf[:n]
fmt.Printf("接收到数据[%d]:\n%s\n", n, string(result))
}
启动程序,测试http的成功响应报文:
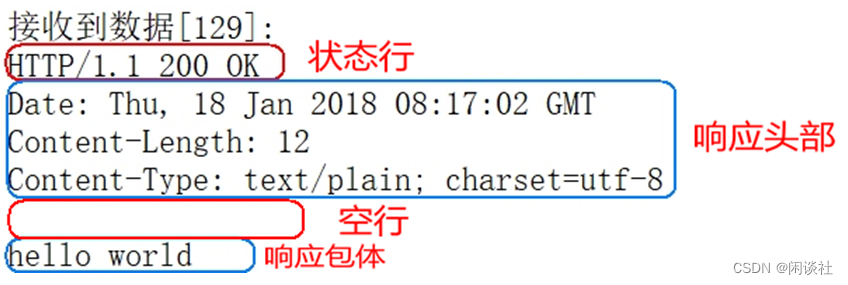
启动程序,测试http的失败响应报文:
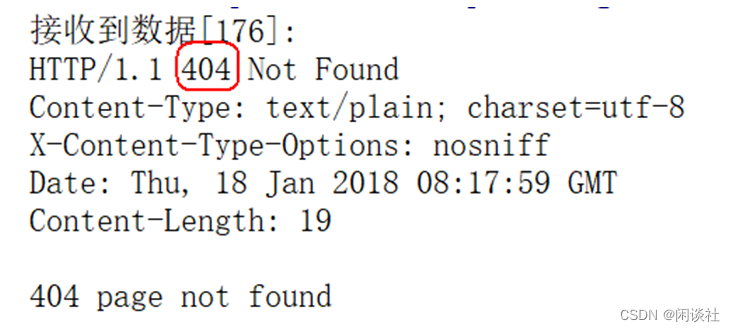
2)响应报文格式说明
HTTP 响应报文由状态行、响应头部、空行、响应包体4个部分组成,如下图所示
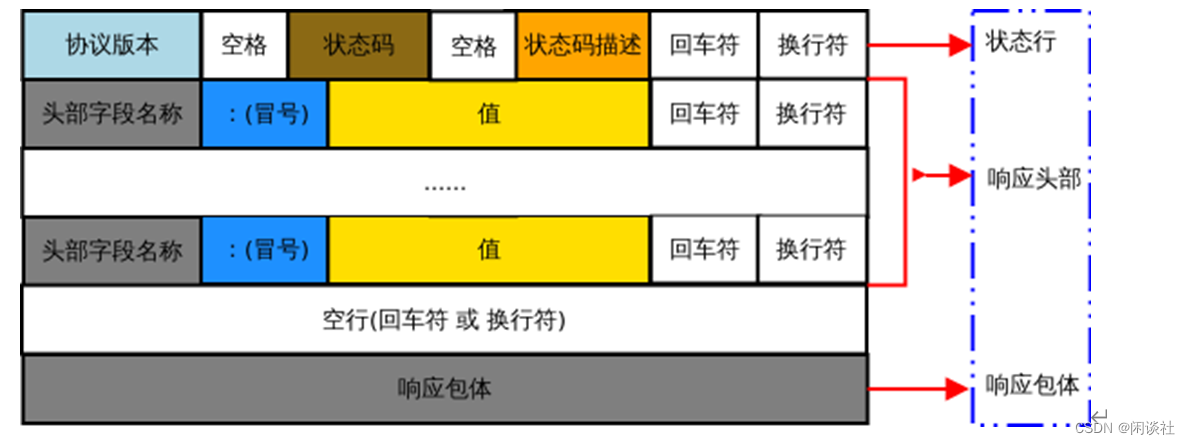
2.1)状态行
状态行由 HTTP 协议版本字段、状态码和状态码的描述文本3个部分组成,他们之间使用空格隔开。
状态码:
状态码由三位数字组成,第一位数字表示响应的类型,常用的状态码有五大类如下所示:
| 状态码 | 含义 |
|---|---|
| 1xx | 表示服务器已接收了客户端请求,客户端可继续发送请求 |
| 2xx | 表示服务器已成功接收到请求并进行处理 |
| 3xx | 表示服务器要求客户端重定向 |
| 4xx | 表示客户端的请求有非法内容 |
| 5xx | 表示服务器未能正常处理客户端的请求而出现意外错误 |
常见的状态码举例
| 状态码 | 含义 |
|---|---|
| 200 OK | 客户端请求成功 |
| 400 Bad Request | 请求报文有语法错误 |
| 401 Unauthorized | 未授权 |
| 403 Forbidden | 服务器拒绝服务 |
| 404 Not Found | 请求的资源不存在 |
| 500 Internal Server Error | 服务器内部错误 |
| 503 Server Unavailable | 服务器临时不能处理客户端请求(稍后可能可以) |
2.2)响应头部
响应头可能包括
| 响应头 | 含义 |
|---|---|
| Location | Location响应报头域用于重定向接受者到一个新的位置 |
| Server | Server 响应报头域包含了服务器用来处理请求的软件信息及其版本 |
| Vary | 指示不可缓存的请求头列表 |
| Connection | 连接方式 |
2.3)空行
最后一个响应头部之后是一个空行,发送回车符和换行符,通知服务器以下不再有响应头部。
2.4)响应包体
服务器返回给客户端的文本信息。
12.3.3 HTTP编程
Go语言标准库内建提供了net/http包,涵盖了HTTP客户端和服务端的具体实现。使用
net/http包,我们可以很方便地编写HTTP客户端或服务端的程序。
12.3.3.1 HTTP服务端
package main
import (
"fmt"
"net/http"
)
// 服务端编写的业务逻辑处理程序,hander函数:具有func(w http.ResponseWriter, r *http.Requests)签名的函数
// w: 给客户端回复数据
// r: 读取客户端发送的数据
func HandConn(w http.ResponseWriter, r *http.Request) {
fmt.Println(r.RemoteAddr, "连接成功")
fmt.Println("Method = ", r.Method)
fmt.Println("Url = ", r.URL.Path)
fmt.Println("Header = ", r.Header)
fmt.Println("Body = ", r.Body)
// 给客户端回复数据
w.Write([]byte("hello go"))
}
func main() {
// 注册处理函数、用户连接,自动调用指定的处理函数
http.HandleFunc("/go", HandConn)
// 监听绑定
// 该方法用于在指定的 TCP 网络地址 addr 进行监听,然后调用服务端处理程序来处理传入的连接请求。
// 该方法有两个参数:第一个参数 addr 即监听地址;第二个参数表示服务端处理程序,通常为空
// 第二个参数为空意味着服务端调用 http.DefaultServeMux 进行处理
http.ListenAndServe("127.0.0.1:8000", nil)
}
浏览器输入url地址:
服务器运行结果:

12.3.3.2 HTTP客户端
package main
import (
"fmt"
"net/http"
)
func main() {
resp, err1 := http.Get("http://www.baidu.com")
if err1 != nil {
fmt.Println("http.Get err1 = ", err1)
return
}
defer resp.Body.Close()
fmt.Println("Status = ", resp.Status)
fmt.Println("StatusCode = ", resp.StatusCode)
fmt.Println("Header = ", resp.Header)
buf := make([]byte, 1024)
var tmp string
for {
n, err2 := resp.Body.Read(buf)
if n == 0 {
fmt.Println("resp.Body.Read err2 = ", err2)
break
}
result := string(buf[:n])
tmp += result
}
fmt.Println("tmp = ", tmp)
}
执行命令
go run http_cli.go
12.3.4 爬虫
爬百度贴吧
https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=0
获取里面讨论的标题
12.3.4.1 同步
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url)
if err1 != nil {
err = err1
return
}
defer resp.Body.Close()
// 读取网页body内容
buf := make([]byte, 1024*4)
for {
n, err3 := resp.Body.Read(buf)
if n == 0 {
fmt.Println("resp.Body.Read err3= ", err3)
break
}
result += string(buf[:n])
}
return
}
func DoWork(startIndex, endIndex int) {
fmt.Printf("正在爬取%d到%d的页面\n", startIndex, endIndex)
for i := startIndex; i <= endIndex; i++ {
// 1.明确目标,到哪个网站查询哪些范围
url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" + strconv.Itoa((i-1)*50)
fmt.Println("url = ", url)
// 2.爬
result, err1 := HttpGet(url)
if err1 != nil {
fmt.Println("http.Get err1 = ", err1)
continue
}
// 解析 target="_blank" class="j_th_tit ">title</a>
var content string
reTitle := regexp.MustCompile(`target="_blank" class="j_th_tit ">(?s:(.*?))</a>`)
if reTitle == nil {
fmt.Println("regexp.MustCompile err")
return
}
title := reTitle.FindAllStringSubmatch(result, -1)
for _, data := range title {
content += (data[1] + "\n")
}
// 3.爬下的内容写到文件
fileName := strconv.Itoa(i) + ".html"
f, err2 := os.Create(fileName)
if err2 != nil {
fmt.Println("os.Create err2 = ", err2)
return
}
f.WriteString(content)
f.Close()
}
}
func main() {
var startIndex, endIndex int
fmt.Printf("请输入起始页(>= 1): ")
fmt.Scan(&startIndex)
fmt.Printf("请输入终止页(>= 起始页): ")
fmt.Scan(&endIndex)
DoWork(startIndex, endIndex)
}
12.3.4.2 异步(协程)
关键在于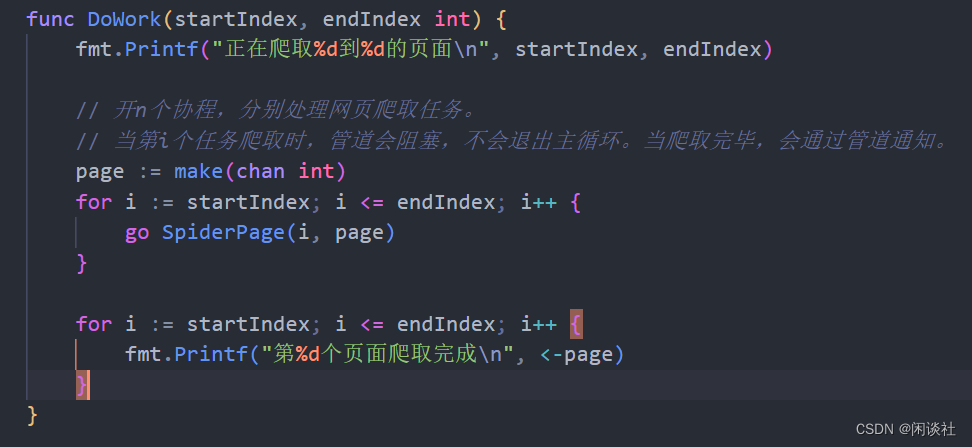
package main
import (
"fmt"
"io"
//"io"
"net/http"
"os"
"regexp"
"strconv"
)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url)
if err1 != nil {
err = err1
return
}
defer resp.Body.Close()
// 读取网页body内容
buf := make([]byte, 1024*4)
for {
n, err3 := resp.Body.Read(buf)
if err3 != nil {
if err3 == io.EOF {
break
} else {
fmt.Println("resp.Body.Read err3= ", err3)
break
}
}
// if n == 0 {
// fmt.Println("resp.Body.Read err3= ", err3)
// break
// }
result += string(buf[:n])
}
return
}
func SpiderPage(i int, page chan int) {
// 1.明确目标,到哪个网站查询哪些范围
url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" + strconv.Itoa((i-1)*50)
fmt.Println("url = ", url)
// 2.爬
result, err1 := HttpGet(url)
if err1 != nil {
fmt.Println("http.Get err1 = ", err1)
return
}
// 解析 target="_blank" class="j_th_tit ">title</a>
var content string
reTitle := regexp.MustCompile(`target="_blank" class="j_th_tit ">(?s:(.*?))</a>`)
if reTitle == nil {
fmt.Println("regexp.MustCompile err")
return
}
title := reTitle.FindAllStringSubmatch(result, -1)
for _, data := range title {
content += (data[1] + "\n")
}
// 3.爬下的内容写到文件
fileName := strconv.Itoa(i) + ".html"
f, err2 := os.Create(fileName)
if err2 != nil {
fmt.Println("os.Create err2 = ", err2)
return
}
f.WriteString(content)
f.Close()
page <- i
}
func DoWork(startIndex, endIndex int) {
fmt.Printf("正在爬取%d到%d的页面\n", startIndex, endIndex)
// 开n个协程,分别处理网页爬取任务。
// 当第i个任务爬取时,管道会阻塞,不会退出主循环。当爬取完毕,会通过管道通知。
page := make(chan int)
for i := startIndex; i <= endIndex; i++ {
go SpiderPage(i, page)
}
for i := startIndex; i <= endIndex; i++ {
fmt.Printf("第%d个页面爬取完成\n", <-page)
}
}
func main() {
var startIndex, endIndex int
fmt.Printf("请输入起始页(>= 1): ")
fmt.Scan(&startIndex)
fmt.Printf("请输入终止页(>= 起始页): ")
fmt.Scan(&endIndex)
DoWork(startIndex, endIndex)
}
















 2400
2400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











