







循环神经网络RNN
提示:本文默认读者具备基本的深度学习知识,如加权激活,链式求导,权重矩阵等信息。

文章目录
前言
RNN非常适合"具备序列特性的特征",因此能够挖掘特征中的时序信息和语义信息。利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
序列特性,即符合时间顺序,逻辑顺序,或者其他顺序就叫序列特性,举几个例子:
- 拿人类的某句话来说,也就是人类的自然语言,是不是符合某个逻辑或规则的字词拼凑排列起来的,这就是符合序列特性。
- 语音,我们发出的声音,每一帧每一帧的衔接起来,才凑成了我们听到的话,这也具有序列特性、
- 股票,随着时间的推移,会产生具有顺序的一系列数字,这些数字也是具有序列特性。
一、循环神经网络结构

其中,
x:特征输入向量,
x
t
−
1
,
x
t
,
x
t
+
1
x_{t-1}, x_t, x_{t+1}
xt−1,xt,xt+1分别代表t-1, t, t+1时刻的特征输入向量。
U:输入层到隐含层的权重矩阵,对于全连接神经网络而言,隐含层的状态=
U
∗
x
U*x
U∗x
W: 上一时刻隐含层的值,作为本次输入之一的权重矩阵
s
t
=
f
(
U
∗
x
t
+
W
∗
s
t
−
1
)
s_t = f(U* x_t+W*s_{t-1})
st=f(U∗xt+W∗st−1)
现在看上去就比较清楚了,这个网络在t时刻接收到输入 x t x_t xt之后,隐藏层的值是 s t s_t st,输出值是 o t o_t ot 。
关键一点是, s t s_t st的值不仅仅取决于 x t x_t xt,还取决于 s t − 1 s_{t-1} st−1。
两种变形

Elman Network
隐层的输出作为下一时刻隐层的输入,即我们上文提到的最质朴的RNN
Jordan Network
区别:输出层的输出(即o的输出)作为下一时刻隐层的输入,这样就包含了隐含层到输出层权重矩阵的信息
至于两种RNN孰好孰劣,差别甚微,没有定论,取决于业务本身是否需要隐层到输出层的信息,可作为尝试。但实际上,这两种RNN已不再被工业界使用,而使用LSTM或Attention机制,这是后话!
缺点
举例来说,如下图的机器翻译场景。当最后时刻,即RNN的输入为French这个词时,网络上一时刻隐层的输出与"fluent"甚至"speak"两词相关,但与"France"基本无关,显然这并不符合我们的预期。
另一方面,如下图网络结构,t+1时刻的隐含层与
t
0
,
t
1
t_0, t_1
t0,t1的状态基本没有关联了,因此RNN对于序列数据而言,损失了序列间距较长的相互信息,这也是RNN的致命缺点

一句话总结
RNN: 一种能够应对序列特性变化的神经网络结构,隐含神经元的输入既来自本时刻的输入,也包括上一时刻隐含层的输出。
缺点:序列数据中间距较长的信息会造成损失,即网络只保存了短期记忆,遗失了长期关联记忆
二、LSTM-长短记忆网络
为了解决RNN本身解决不了的“长期关联信息”,1997年德国科学家推出了LSTM网络,它是一种特殊的RNN网络,用于处理“长期关联信息”,
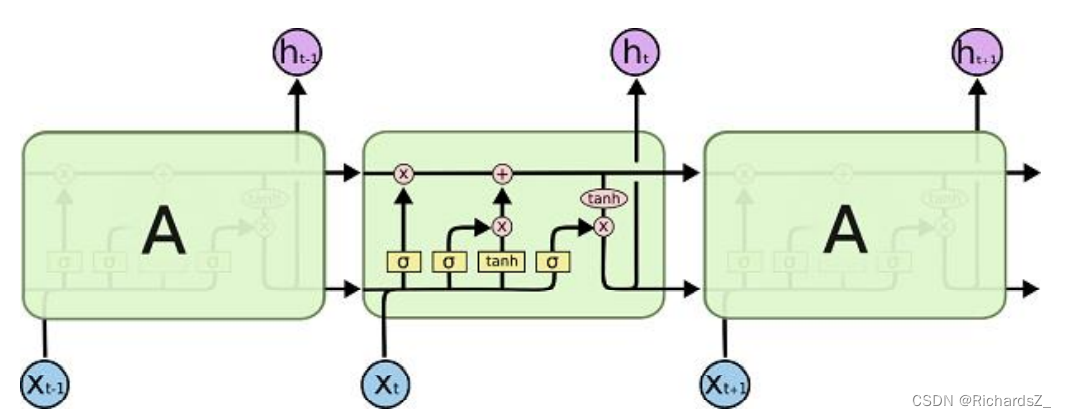
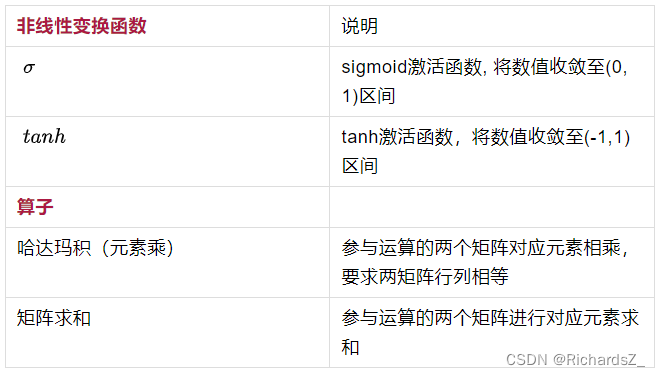
其中,每一节点主要涉及以下两种非线性变换与两种矩阵运算:
将上述两种非线性变换函数与上一阶段和本阶段信息进行不同功能性的组合,构成了LSTM核心的门控结构。
核心思想:门
遗忘门(选择遗忘阶段)
作用:对上一阶段神经元输出层的信息,通过sigmoid函数,进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
遗忘门输出(0,1)区间的数字,1代表完全保留,0代表完全遗忘。

输入门(选择记忆阶段)
作用:对当前阶段输入的信息,进行有选择性记忆。其中sigmoid层用于确定当前输入信息的记忆占比,tanh层则代表基础RNN的输出,两者结合,代表输入数据 在流向下一时刻时,有多少信息被保留。真正被控制的就是几个参数,在原有训练,通过数据来调整W和b使结果满足训练数据里的最大似然值。

更新门(更新阶段)
作用: 整合当前阶段的输入中,来自遗忘门的遗忘信息占比与来自输入门的保留信息占比。

因此LSTM核心就是通过控制权重W和偏置b,来控制遗忘门,更新门的状态,决定本时刻信息中“遗忘信息占比”和“新输入信息占比”,当序列数据中存在长期关联关系时,可能中间时刻的cells中
i
t
i_t
it占比较小,
f
t
f_t
ft占比较大,已实现长期关联关系
(工程简化)GRU-LSTM优化
为了减小计算时的系数,直接将更新门的系数改为
1
−
f
t
1-f_t
1−ft,与遗忘门互斥,网络结构更加简洁。同时GRU的简化也允许了LSTM的网络深度进一步加大。

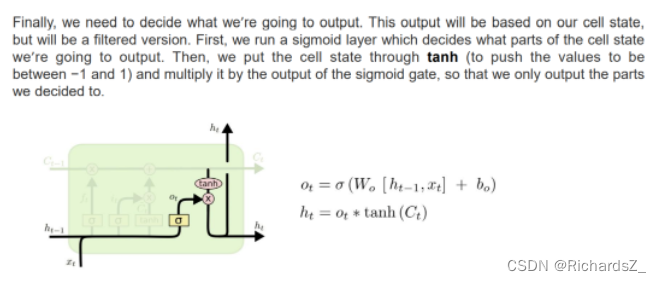
输出门(输出阶段)
作用:对当前阶段的信息输出进行过滤,决定有多少信息作为下一节点的输入
小结
RNN,一种能够应对序列特性变化的神经网络结构,隐含神经元的输入既来自本时刻的输入,也包括上一时刻隐含层的输出。
序列数据中间距较长的信息会造成损失,即网络只保存了短期记忆,遗失了长期关联记忆
LSTM,特殊的RNN,通过门控状态来控制信息的传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但LSTM也因为多个门控引入了更多的参数,也使得训练难度加大了很多。因此很多时候,工程上会使用效果和LSTM相当但参数更少的GRU来简化训练过程。
















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









