







一、什么是高斯过程
高斯过程是一种随机过程,即按时间或者空间索引的随机变量的集合。这个集合中的有限个随机变量构成多维高斯分布。高斯过程就是这个集合中所有随机变量(无限多个)的联合分布。
二、高斯分布
2.1 一元高斯分布
一元高斯分布的概率密度函数为:
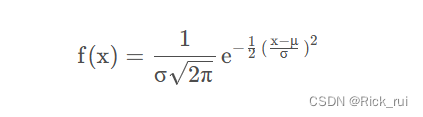
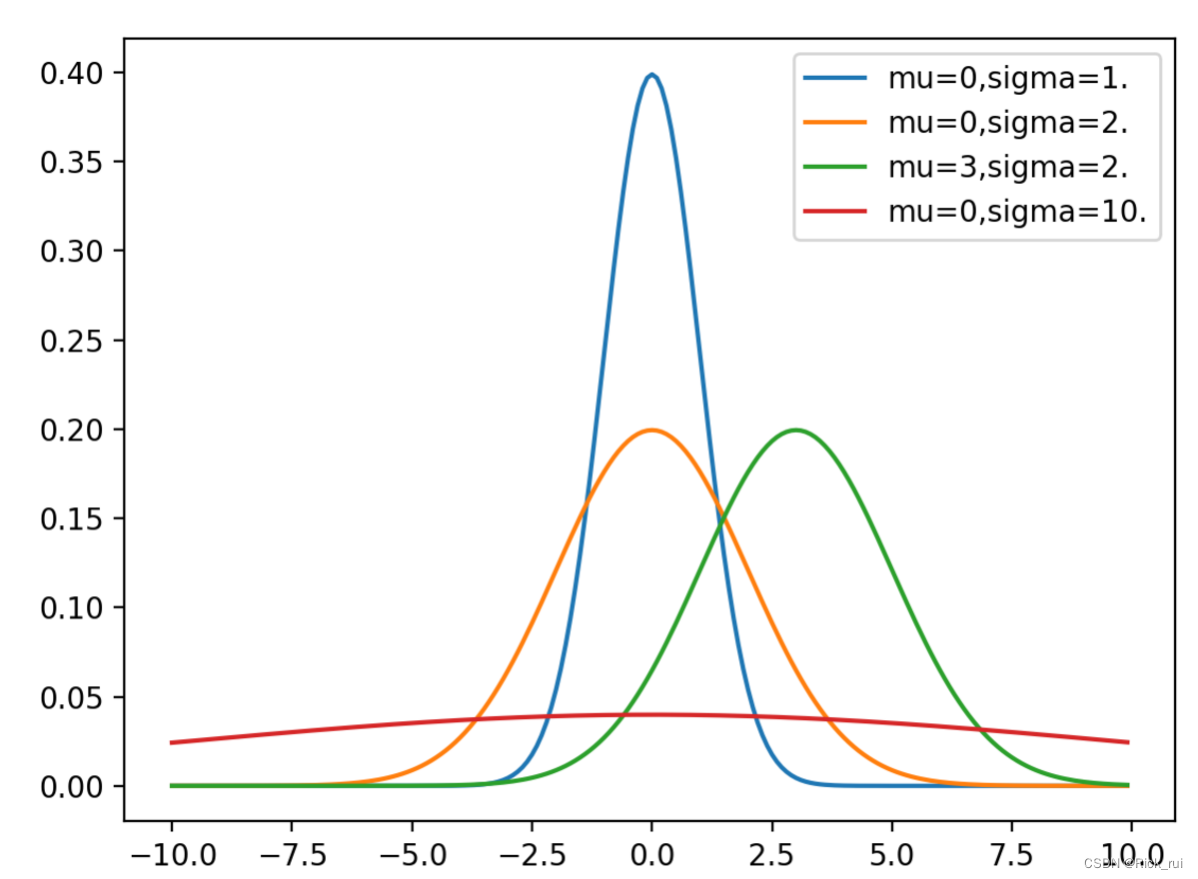
2.2 多元高斯分布
多元高斯分布是单元正态分布向多维的推广。我们以二元为例进行介绍。
假设变量为
[
X
,
Y
]
T
[X,Y]^T
[X,Y]T,其概率密度函数为:
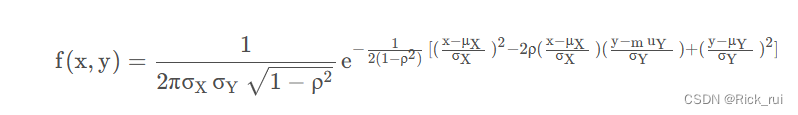 ρ
\rho
ρ是
X
X
X,
Y
Y
Y之间的相关系数,
ρ
\rho
ρ是
X
X
X,
Y
Y
Y之间的相关系数,
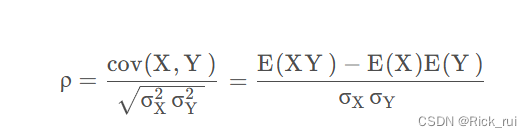

如果
X
X
X,
Y
Y
Y之间相互独立,则
ρ
=
0
\rho = 0
ρ=0

三、从高斯分布到高斯过程
高斯过程是无限个随机变量的联合高斯分布,如下图所示,横轴表示连续的时间域,纵轴表示某时刻内随机变量的取值。其中采样了四个随机变量
(
ζ
1
,
ζ
2
,
ζ
3
,
ζ
4
)
(\zeta_1,\zeta_2,\zeta_3,\zeta_4)
(ζ1,ζ2,ζ3,ζ4)任意一个t tt时刻的随机变量都符合高斯分布(如图中蓝色线)。图中对同一时刻的随机变量分别采样了两次,构成了两次高斯过程的采样(如图中橙线和绿线)。

从图中可以看出高斯过程不像高斯分布那样有一个确定的均值和方差,而是与时间(/空间)相关的函数确定每个时刻的均值和方差。这两个函数分别就是mean function 和 convariance function。mean function 决定了样本出现的整体位置,covariance function也称为kernel function 用于捕捉不同输入点之间的距离关系,我们可以利用点与点之间的关系来对未知点进行预测。
四、FedCor
论文链接:http://arxiv.org/abs/2103.13822
核心思想主要基于以下直觉:
- 客户的贡献并不相等。例如,在一个“好”客户端上使用一个大而平衡的数据集进行训练可以减少大多数客户端的损失,而在一个“坏”客户端上使用一个小而极端偏差的数据集进行训练可能会增加其他客户端的损失。
- 客户端不独立贡献。选择一个客户端的影响取决于其他选择的客户端,因为它们的本地更新将被聚合。
1、客户直接存在损失相关性
2、使用高斯过程(GP)建模客户端之间的损失相关性,从而推导出客户选择策略


















 1868
1868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









