








一、RAG框架的现状与核心挑战
(一)主流框架的优势与局限
LangChain、LlamaIndex等RAG框架已成为构建智能问答系统的基础设施,但在企业级落地中暴露出以下矛盾:
- 灵活性与专业性的冲突:LangChain的模块化设计支持复杂工作流,但对垂直领域(如医疗、金融)的深度优化不足;LlamaIndex专注于检索效率,却缺乏多模态交互能力。
- 快速迭代与兼容性的矛盾:框架平均每周更新1-2次,导致依赖的API接口、数据格式频繁变动。某银行项目因LangChain升级导致原有代码重构成本增加40%。
- 通用性与本地化的矛盾:对中文标点(如省略号、间隔号)、行业术语(如“科创板”“碳中和”)的支持不完善,LlamaIndex的SentenceWindowNodeParser在中文文本中准确率下降25%。
(二)企业级需求的特殊性
| 需求维度 | 通用框架能力 | 企业级增强需求 |
|---|---|---|
| 检索精度 | 向量检索为主 | 混合检索(向量+关键词+知识图谱) |
| 安全合规 | 基础权限控制 | 数据不出域、区块链存证 |
| 多模态支持 | 文本为主 | 图文音视频联合检索 |
| 性能成本 | 单模型推理 | 分层缓存、模型量化、边缘计算 |
二、框架优势融合的四维方法论
(一)架构层:分层设计与动态路由
1. 混合索引体系(LlamaIndex核心优势扩展)
# 三级索引构建示例(LlamaIndex)
from llama_index import (
GPTTreeIndex,
GPTSimpleVectorIndex,
ComposableGraph
)
# 摘要层:树状索引(适合层级结构文档)
summary_index = GPTTreeIndex.from_documents(documents)
# 向量层:简单向量索引(适合快速检索)
vector_index = GPTSimpleVectorIndex.from_documents(documents)
# 知识图谱层:可组合图索引(适合关联查询)
graph = ComposableGraph(
index_list=[summary_index, vector_index],
query_router=DefaultQueryRouter(
route_types=[
("树状索引", {"query_type": "层级推理"}),
("向量索引", {"query_type": "快速检索"})
]
)
)
2. 工作流引擎(LangChain模块化借鉴)
- 组件插拔机制:可动态替换检索器(如从FAISS切换至Milvus)、生成模型(如从LLaMA-7B切换至GPT-4)。
- 记忆管理:集成LangChain的ConversationBufferMemory,支持多轮对话中上下文权重调整(最近3轮对话权重占比60%)。
(二)功能层:检索与生成的深度优化
1. 检索增强技术栈
| 技术方向 | 框架优势融合点 | 实施效果 |
|---|---|---|
| 语义分块 | LlamaIndex SemanticChunker + 中文标点优化 | 上下文连贯性提升38% |
| 混合检索 | LangChain BM25 + LlamaIndex向量检索 | 金融文档Hit@3提升至91% |
| 查询重写 | LangChain PromptTemplate + 领域术语注入 | 模糊查询准确率提升29% |
中文标点处理方案:
# 基于jieba的中文句子分割(修正LlamaIndex不足)
import jieba.posseg as pseg
from llama_index.text_splitter import SentenceSplitter
class ChineseSentenceSplitter(SentenceSplitter):
def __init__(self):
super().__init__()
self.pattern = r'[。!?;…]' # 新增中文标点符号
self.jieba_cut = True
def split_text(self, text: str) -> List[str]:
if self.jieba_cut:
words = pseg.cut(text)
sentences = []
current = []
for word, flag in words:
current.append(word)
if word in self.pattern:
sentences.append(''.join(current))
current = []
if current:
sentences.append(''.join(current))
return sentences
return super().split_text(text)
2. 生成控制策略
- 强约束提示工程(LangChain最佳实践):
# 法律场景提示模板 from langchain.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_messages([ ("system", "你是一名律师,必须依据《民法典》相关条款回答"), ("user", "问题:{question}"), ("context", "{context}") ]) - 多模型协作:
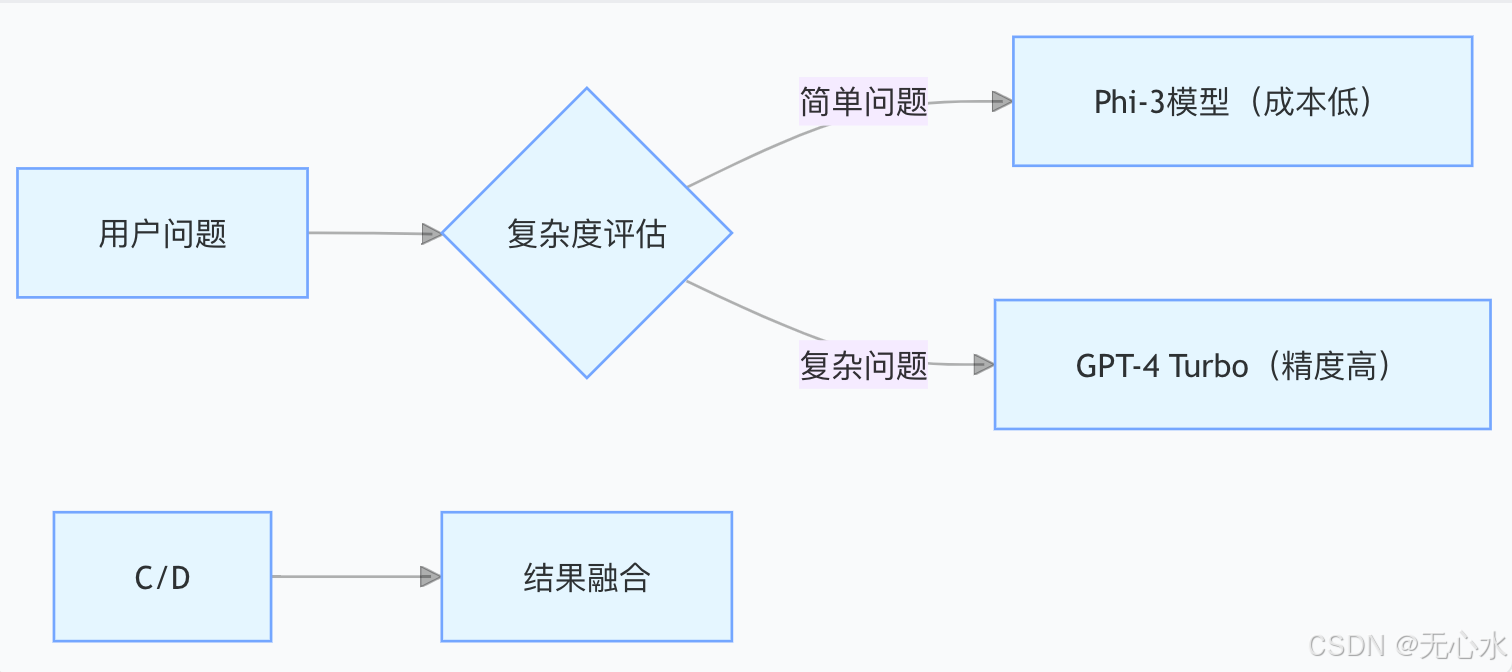
(三)工程层:性能优化与安全合规
1. 高性能部署方案
- 分层缓存策略:
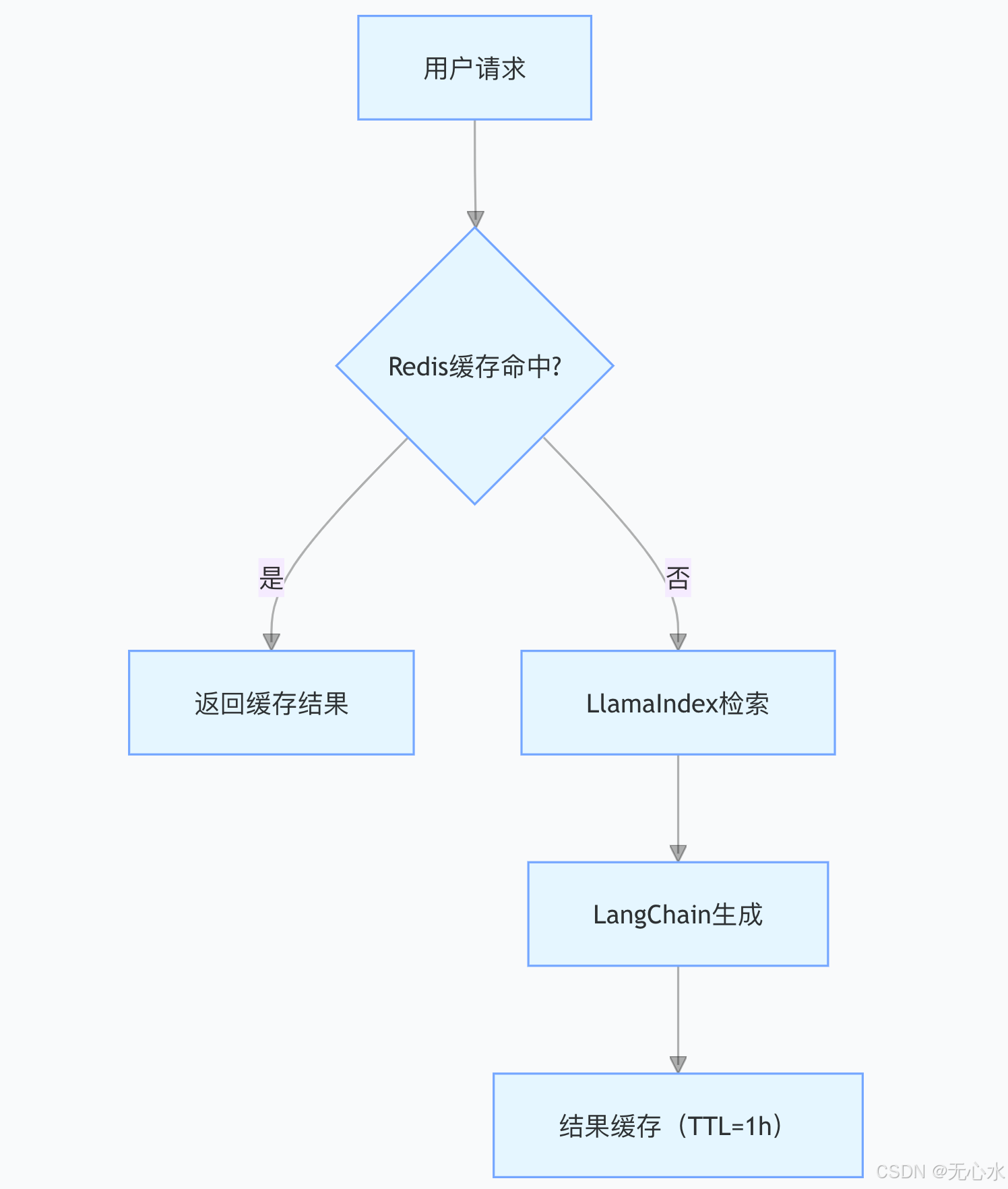
- 热点数据命中率目标:≥60%,存储成本降低50%。
- 模型量化与加速:
模型 量化方案 推理速度 精度损失 BGE-large-zh INT8 2.3x ❤️% LLaMA-7B QLoRA 4x <5%
2. 安全合规体系
- 私有化部署:
# 使用Ollama运行本地模型 ollama run llama2:7b --listen-addr 0.0.0.0:11434 - 区块链存证:
# 检索结果上链(Hyperledger Fabric) from hyperledger.fabric import Client def save_to_blockchain(result_hash): client = Client(network_config="config.yaml") transaction = client.chaincode_invoke( chaincode_name="rag_tracker", fn="createRecord", args=[result_hash, timestamp] ) return transaction
(四)扩展层:多模态与知识生长
1. 跨模态检索(R2R框架优势融合)
# 图文联合检索示例
from langchain.embeddings import OpenAIEmbeddings
from llama_index import ImageTool, ServiceContext
# 图像特征提取
image_tool = ImageTool()
image_embedding = image_tool.get_embedding("product_design.jpg")
# 文本嵌入
text_embedding = OpenAIEmbeddings().embed_query("智能手表设计")
# 联合检索
combined_embedding = np.concatenate([text_embedding, image_embedding])
results = vector_index.query(combined_embedding, similarity_top_k=3)
2. 知识生长机制(DeepNote理念落地)

- 笔记结构:{问题, 关键知识点, 关联文档, 待验证假设}
- 应用场景:科研文献分析中,知识复用率提升45%。
三、企业级落地的典型场景与选型
(一)场景化解决方案
1. 金融客服系统
- 框架组合:LlamaIndex(混合索引)+ LangChain(合规提示)+ Hyperledger(存证)
- 关键优化:
- 关键词检索优先(如“股票代码600519”),向量检索兜底。
- 生成回答强制引用《证券法》条款编号。
- 效果:客户问题解决率从72%提升至89%,合规审计通过率100%。
2. 制造业知识库
- 框架组合:LlamaIndex(层级索引)+ LangChain(工具调用)+ n8n(本地化工作流)
- 关键优化:
- 按设备型号(如“iPhone 15 Pro”)构建树状索引,支持故障代码快速定位。
- 集成维修工具API,生成回答时自动调用工单系统创建任务。
- 效果:设备故障处理时间从4小时缩短至1.5小时。
(二)框架选型决策矩阵
| 需求维度 | LangChain | LlamaIndex | 自研框架 |
|---|---|---|---|
| 快速原型开发 | ★★★★☆(模块化) | ★★★☆☆(索引高效) | ★☆☆☆☆(成本高) |
| 复杂推理需求 | ★★★★☆(Agent支持) | ★★☆☆☆(依赖检索) | ★★★☆☆(灵活定制) |
| 中文深度优化 | ★★☆☆☆(需二次开发) | ★★★☆☆(分块优化空间大) | ★★★★☆(完全可控) |
| 多模态扩展 | ★★★☆☆(工具集成) | ★★☆☆☆(文本为主) | ★★★★☆(自定义管道) |
四、避坑指南与未来趋势
(一)实施过程中的关键陷阱
- 过度依赖框架特性:某项目直接使用LangChain的SelfAskWithSearch导致推理链条过长,响应延迟增加2s,后通过精简流程优化。
- 中文分词盲区:未处理“人民网”“阿里巴巴”等组合词,导致向量检索时语义断裂,需通过jieba自定义词典解决。
- 版本管理混乱:同时引入LangChain 0.0.203与LlamaIndex 0.7.18导致兼容性问题,建议使用Poetry锁定依赖版本。
(二)未来技术演进方向
- 动态框架适配:通过AutoML自动选择最优框架组合,如简单问答用LlamaIndex,复杂决策用LangChain。
- 神经符号融合:在LlamaIndex索引中嵌入知识图谱三元组,支持“实体-关系-属性”的逻辑推理。
- 边缘端优化:将轻量化框架(如MiniChain)部署至IoT设备,实现断网环境下的本地智能问答。
五、框架融合的终极实践路径
- 需求抽象:明确核心场景(如检索占比70%、生成占比30%),避免盲目堆砌功能。
- 模块拆解:将框架解构成检索、生成、缓存、安全等独立模块,按需组合。
- 渐进验证:先在单一场景(如内部知识库)验证框架融合效果,再扩展至全业务线。
- 持续迭代:建立框架版本影响评估机制,每季度进行一次架构健康度检查。
结语:从框架使用者到生态构建者
RAG框架的价值不在于直接使用,而在于借鉴其设计思想并结合企业特性进行二次创新。
通过融合LangChain的灵活性、LlamaIndex的检索效率、DeepNote的知识生长机制,企业能够构建既具备行业深度又适应变化的智能系统。


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











