



Transformer自2017年提出后,已经成为大语言模型(LLM)的基石。如今GPT、LLaMA、Qwen等主流模型,都在这一架构上不断演化。
和鲸社区复现的斯坦福CS336课程作业一中的第三部分就要求从零实现Transformer语言模型,相比直接调用高层API,从零实现能够让学习者真正理解:
-
token如何被嵌入为向量;
-
自注意力如何捕捉上下文依赖;
-
为什么需要位置编码、归一化和残差连接;
-
现代LLM在Transformer基础上做了哪些优化。
CS336的作业价值在于它几乎完整覆盖了一个小型GPT的架构核心,是作业中最能“落地见效”的部分。本文将以高层结构为主线,带你系统梳理Transformer的实现逻辑,并结合作业中的设计细节,总结学习亮点与工程技巧。如果你想进一步深入,欢迎到和鲸社区查看完整的开源项目。
项目指路:https://www.heywhale.com/u/10f21e
📚作业开源项目见“和鲸社区”网站
🎬视频讲解:b站“天海一直在AI”
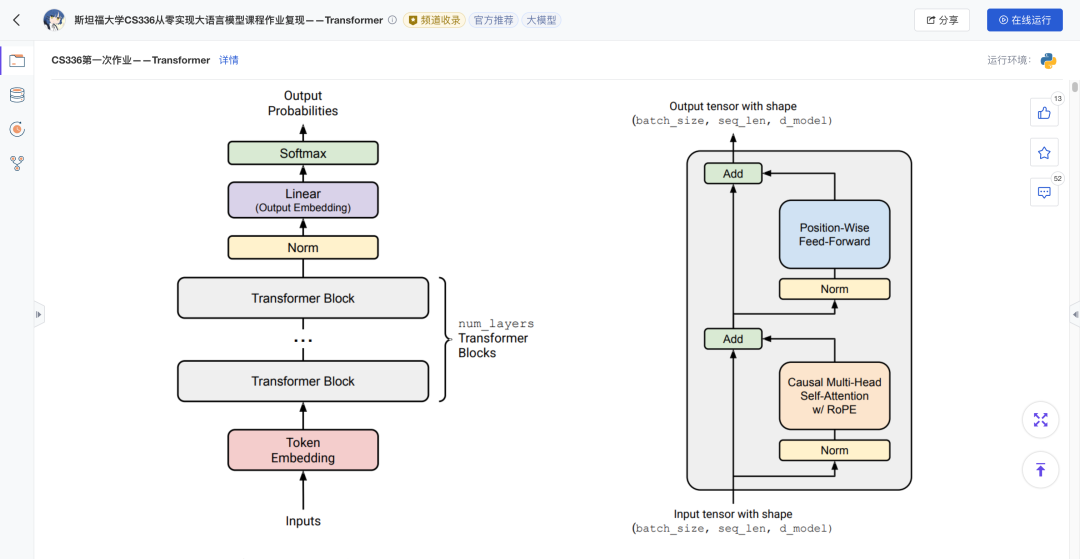
模型的高层结构与作业实现
一个Transformer语言模型大体可以分为四个环节:
1、输入嵌入(Embedding)
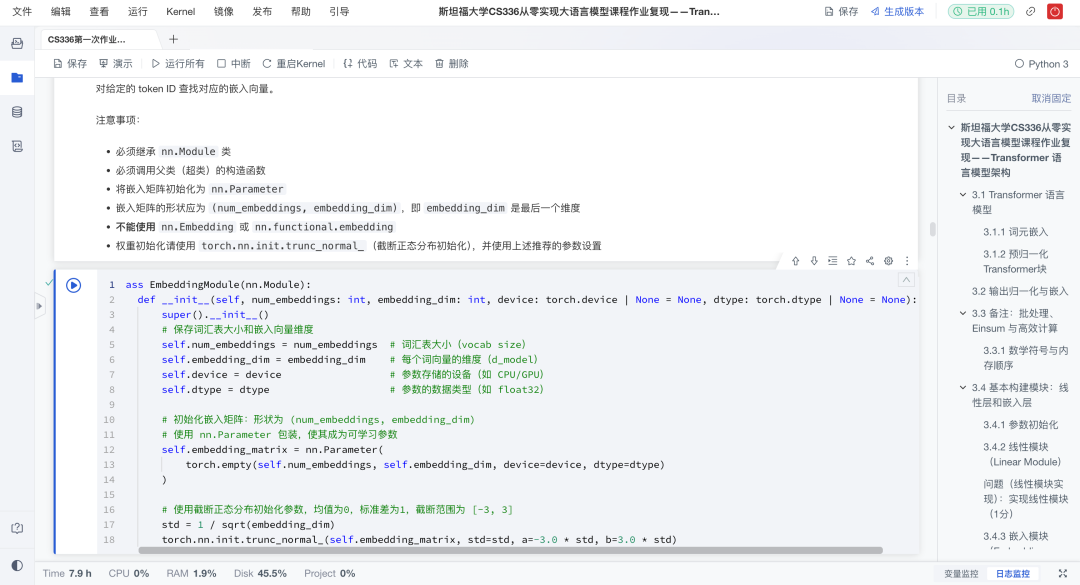
输入的token ID会先通过Embedding层转换为稠密向量表示。这一步是语言模型的入口,赋予离散符号语义信息。作业要求手动实现嵌入矩阵,而不是直接调用PyTorch的nn.Embedding,从底层理解“参数矩阵就是词表”。同时,权重初始化采用截断正态分布,以保证数值稳定。
🔧难点与作业实现:
-
维度对齐:必须保持输出
(batch, seq_len, d_model),才能正确进入注意力模块。作业通过严格控制参数矩阵(vocab_size, d_model)并在forward中索引来解决。 -
初始化稳定性:采用截断正态分布,保证初始embedding不会数值过大。
2、多层Transformer Block(Pre-Norm结构)
核心的计算单元是Transformer Block,每一层都包含归一化、自注意力、前馈网络和残差连接,层层加深模型的理解能力。
作业采用预归一化(Pre-Norm)结构,即在进入每个子层前先进行归一化,再通过残差连接将输出加回原始输入。这种结构已被LLaMA、GPT-NeoX等现代大模型广泛采用,能显著提升深层网络的训练稳定性。计算流程如下:
x = x + MHA( RMSNorm(x) )
x = x + FFN( RMSNorm(x) )
下面我们拆解组件:
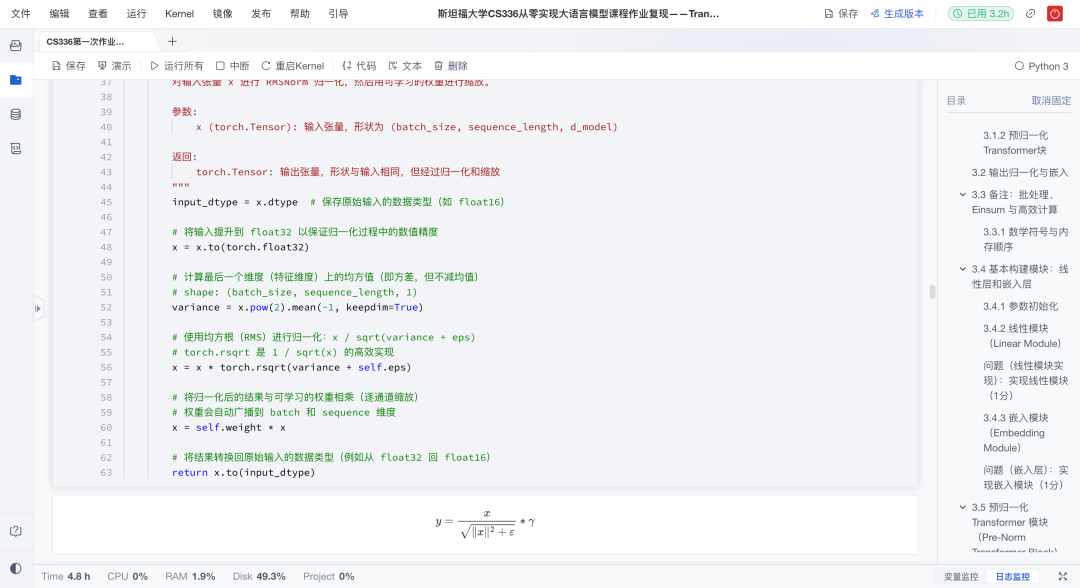
1)归一化(RMSNorm)
采用更轻量的RMSNorm,而不是LayerNorm,符合LLaMA等现代模型的设计。实现时必须先将输入提升到float32,再执行平方和均方根运算,最后转回原始dtype。
🔧难点与作业实现:
-
精度问题:半精度下容易溢出,作业通过float32中间计算保证稳定性;
-
类型还原:归一化完成后,再转回原始数据类型(如float16),节省显存。
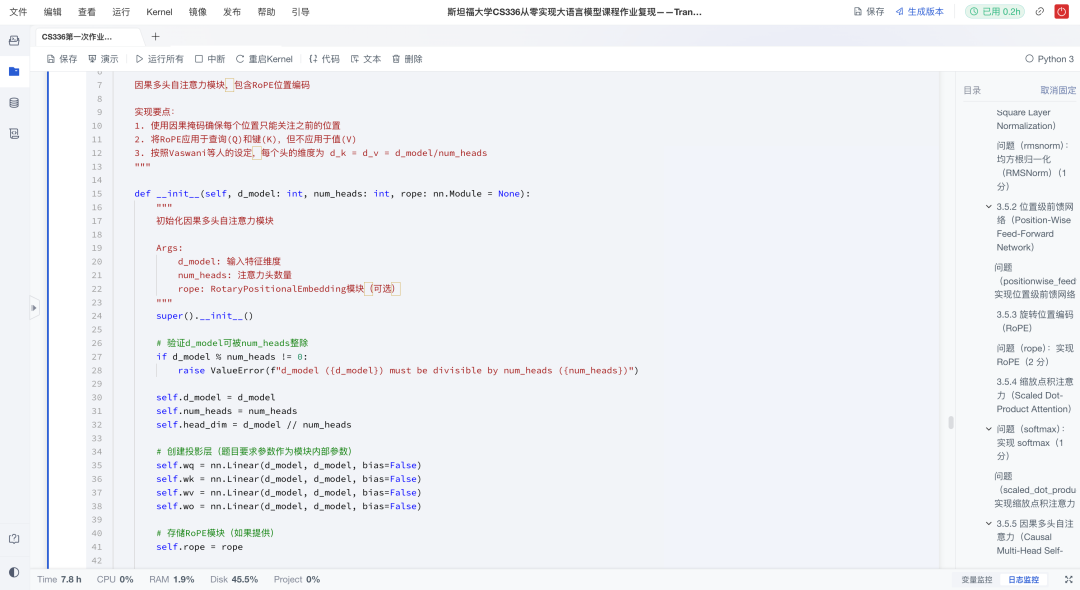
2)自注意力:因果多头注意力(Causal Multi-Head Attention)
这是Transformer的核心,负责捕捉序列内部的长距离依赖关系。作业实现了完整的因果多头注意力:
-
Q、K、V 投影:通过三次独立的线性投影(矩阵乘法)分别生成查询(Q)、键(K)和值(V);
-
因果掩码:利用
torch.triu构造上三角mask,保证模型不能“偷看”未来token; -
旋转位置编码(RoPE):只作用在Q和K上,通过预计算正余弦表,在前向传播时按位置切片使用。
难点与解决:
-
维度匹配:作业要求用
einsum显式表示张量流动,避免因复杂的transpose和reshape操作而出错; -
数值稳定性:softmax前减去最大值,mask时加上大负数而非
-inf,避免NaN。
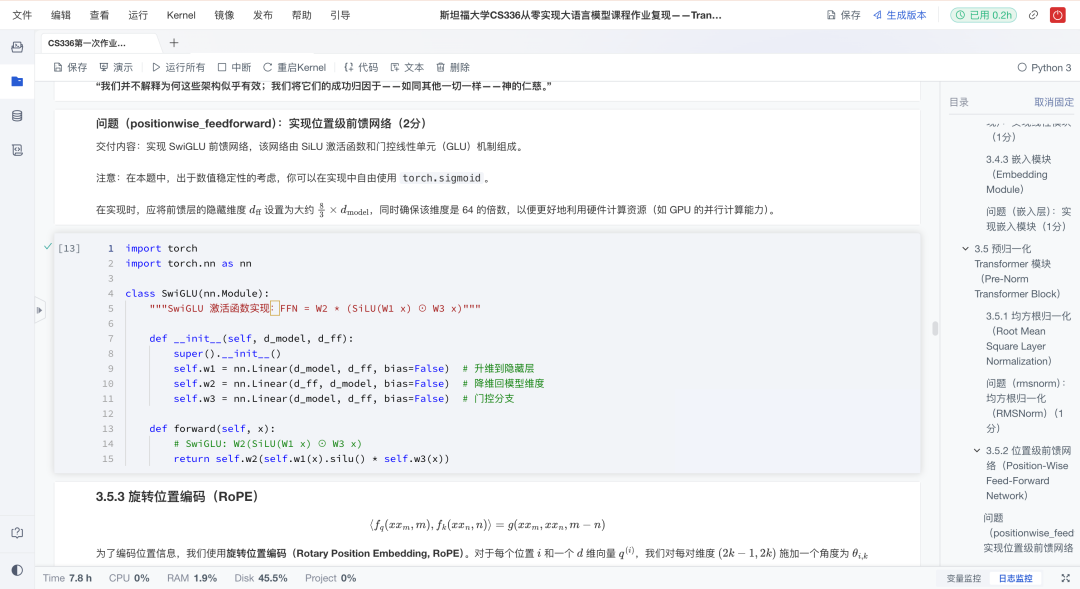
3)前馈网络(SwiGLU):
作业采用SwiGLU替代ReLU前馈层,这也是LLaMA、Qwen等现代模型采用的设计。实现时要求中间维度大约是d_model的4倍,并保证能被64整除以提升GPU并行效率。
🔧难点与解决:
-
激活函数实现:通过
SiLU(W1x)⊙W3x与W2x相乘组合,既保留梯度通路,又增强非线性表达; -
维度设置:通过自动检查d_ff是否满足倍数要求,保证计算性能。
4)残差连接(Residual Connection):
在每个子层(注意力和前馈网络)外加入残差连接,使输入能够绕过子层直接传递。这一设计允许梯度直接流过深层网络,有效缓解梯度消失问题,是训练深层模型的关键。
由于作业采用Pre-Norm结构,归一化操作发生在子层内部,而残差连接始终连接的是原始输入。
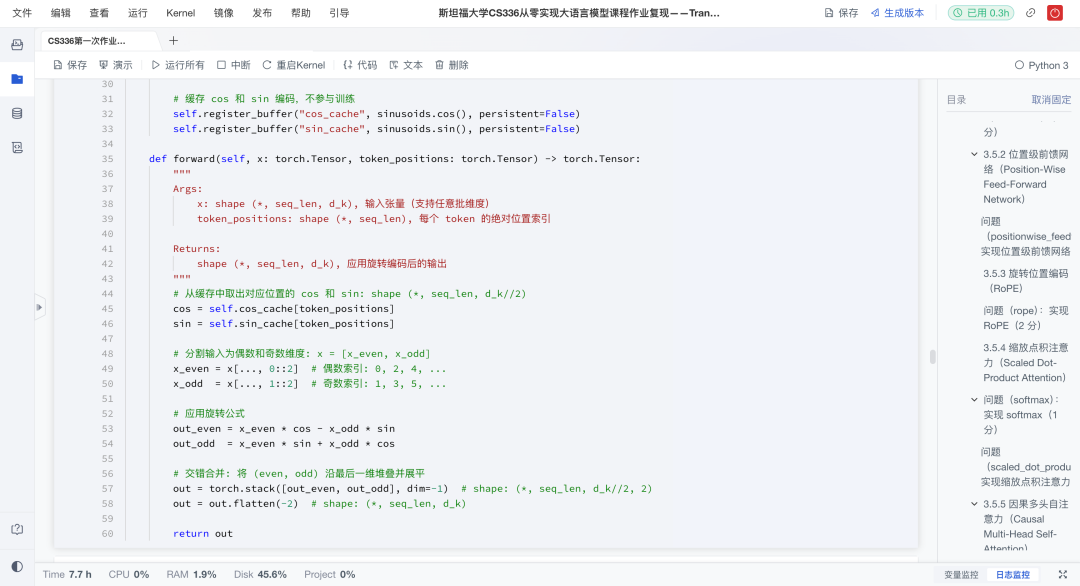
3、位置编码:旋转位置编码(RoPE)
Transformer本身不具备顺序信息,需要额外注入。作业采用旋转位置编码(RoPE),通过正余弦函数在Q、K中引入位置信息。这种方式已经成为GPT-NeoX、LLaMA等模型的标准配置。
🔧难点与作业实现:
-
缓存机制:作业实现了预先生成大规模正余弦表,运行时按需切片,提高效率;
-
奇偶维度旋转:通过张量拼接操作,把偶数维和奇数维交替旋转,确保位置信息正确注入。
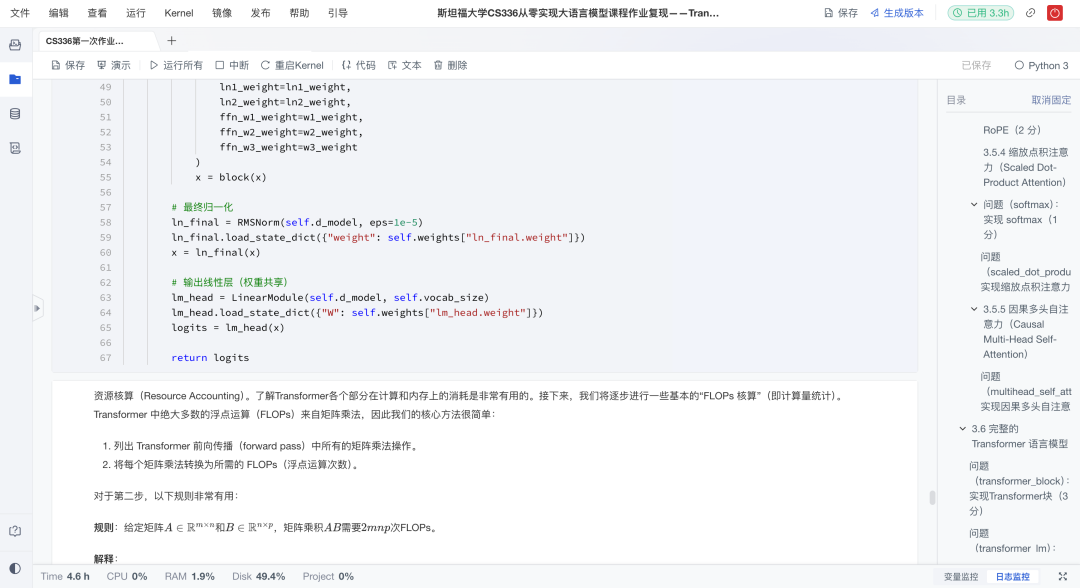
4、输出投影(LM Head)
经过多层Block后,最终表示会通过线性层映射到词表维度,并通过softmax得到下一个token的概率分布,这就是语言模型的核心预测能力。
🔧难点与解决:
-
对齐问题:输出层的权重矩阵维度必须是
(d_model, vocab_size),以确保输出的logits维度与词汇表大小一致,从而能正确计算概率和损失; -
初始化:同样使用截断正态分布初始化,避免训练不稳定。


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









