










目录
1. 图像基础
1.1 图像如何存储在计算机中
-
灰度图:矩阵
0:白色
1:黑色
0-255:灰色

-
彩色图:三个矩阵的叠加
彩色图 = 三个图层/三个通道 (每个图层由 0-255 的数字组成,用来表示红/绿/蓝 颜色的深浅)
比如,用0来表示最不红,255表示最红。
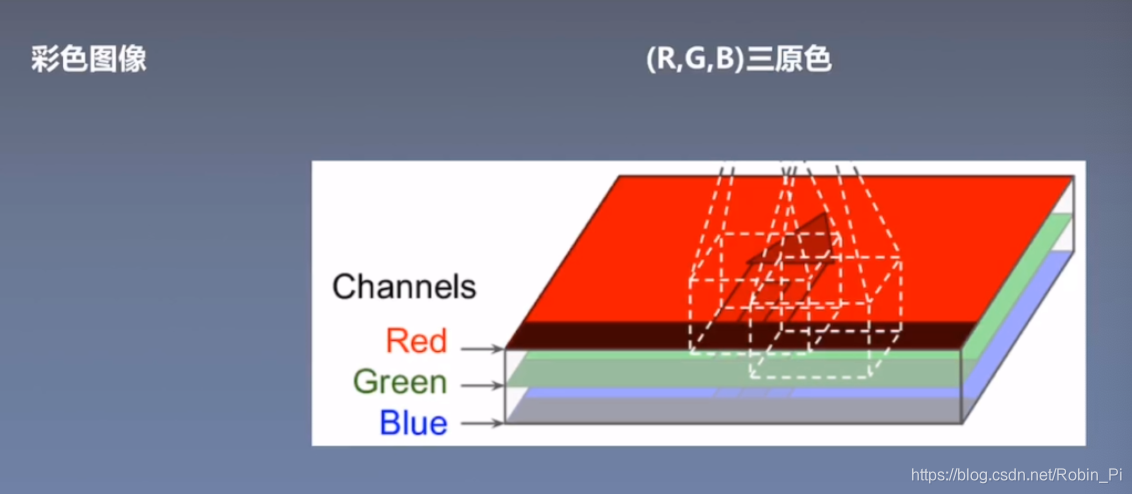
重要概念:width、height、channel
1.2 传统的图像处理
- 人工算子(矩阵形式):参数
- 卷积:运算

可以使用使用卷积神经网络,来自动学习参数。
2. 卷积的基本构件
2.1 卷积层
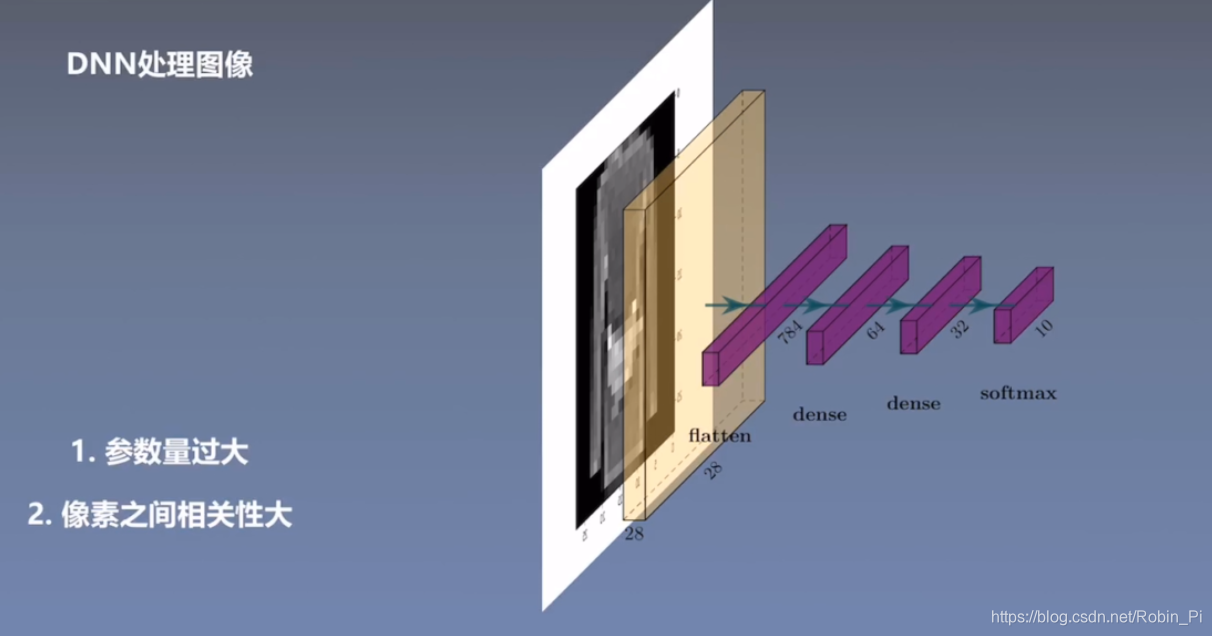
2.1.1 全连接神经网络 处理图像的问题
-
全连接神经网络(DNN):上下层每一个神经元全部连接
-
思路
一张灰度图像(28x28)的全部像素 flatten 成一个n 维(28x28=784)向量,然后接上不同维度(64和32)的全连接层,最后接上 softmax ,输出相应维度(10)的向量,进行最后分类。 -
采用全连接网络的问题:
- 参数太多
- 像素之间相关性太大
2.1.2 卷积层的特性/作用
- 共享参数:大大降低了网络参数——保证了网络的稀疏性,防止过拟合(之所以可以“参数共享”,是因为样本存在局部相关的特性。)
- 局部感受野:解决相关性太大的问题
2.1.3 卷积层的几个重要概念
-
channel
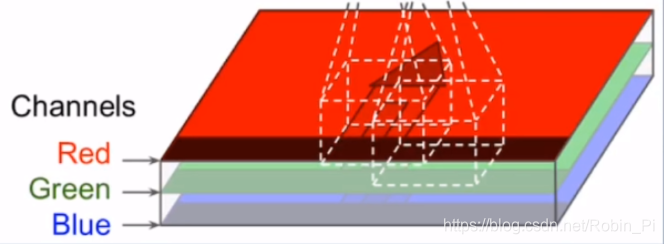
可以理解为矩阵的叠加个数,如:
彩色图的输入channel:3
灰度图的输入channel:1 -
padding
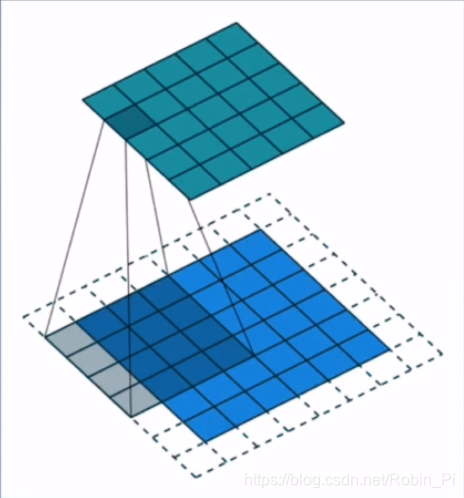
填充(padding)的目的,比如0填充,是为了使得下一层的神经元的个数或者说 feature map 满足一定的条件(比如变大)。 -
strides
增大步长(strides)可以增加感受野外。 -
kernel size
卷积核的大小(kernel size)一般都选择的是奇数大小——因为奇数是对称的,它都有一个中心。 -
filters
有几个不同的卷积核就有几个不同的 filter。 -
feature map
一个卷积核“扫过“一次可以生成一个 feature map;
有几个 feature map 堆叠在一起就有几个channel。 -
感受野
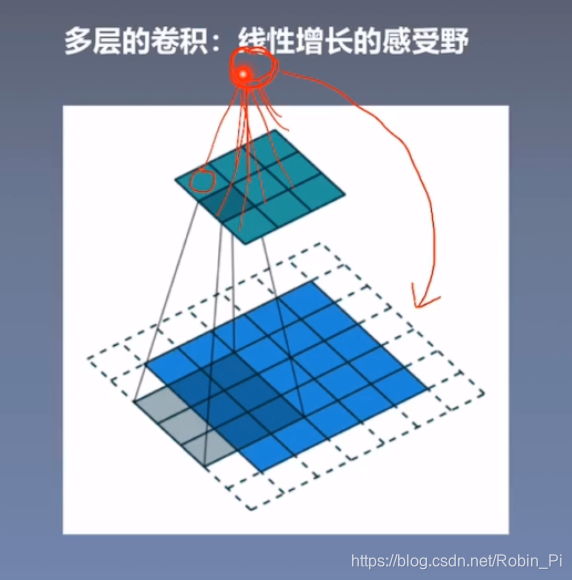
感受野是非常重要的概念,对我们后期的建模有一定的指导意义(选择宏观信息还是局部信息?)比如顶层神经元的感受野是”全局感受野“,意味着顶层神经元蕴含着底层所有像素的信息。
注:关于(对底层 feature map) padding 的两个参数
-
SAME 参数:做padding 且自动计算(有公式)
-
VALID 参数:不做 padding
-
特殊卷积:1x1 卷积
1x1 卷积 虽然不能改变 feature map 的长和宽,但是可以在channel 维度做一些文章,比如压缩通道和扩展通道。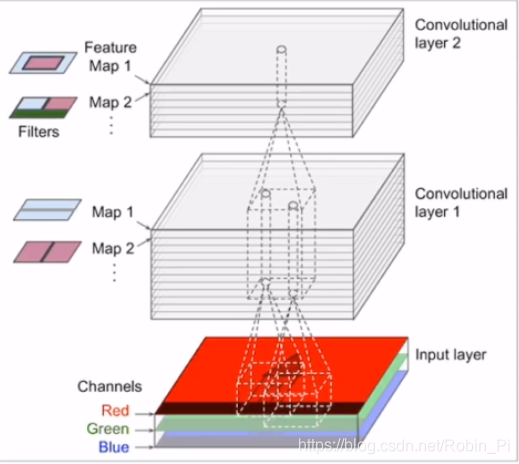
2.2 池化层
化层层没有需要学习的参数。
- 平均池化
- 最大池化
注: 特殊池化,比如 global 池化(全局效果的池化)
2.3 CNN架构设计原则
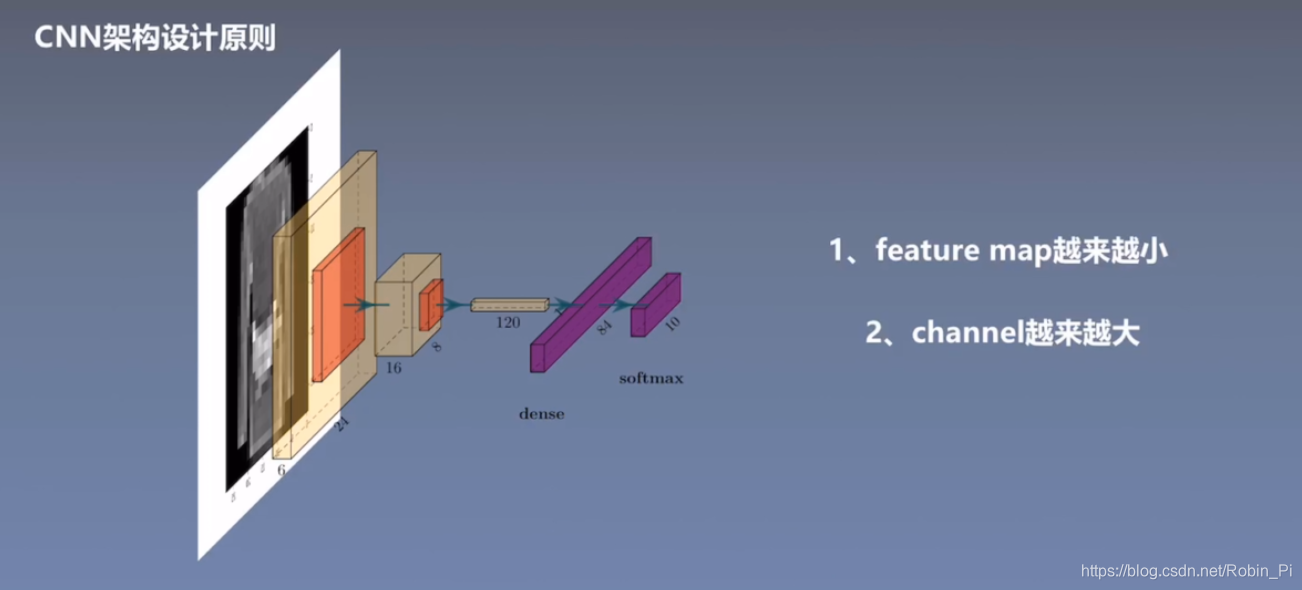
- feature map 会越来越小
- channel 会越来越大
3. 卷积的经典结构
3.1 Lenet 结构
Lenet (GoogleNet)是 CNN 运用到真实场景的一个开端。

3.2 Alexnet 结构
Alexnet 是第一次运用在非常大的数据集( ImageNet )
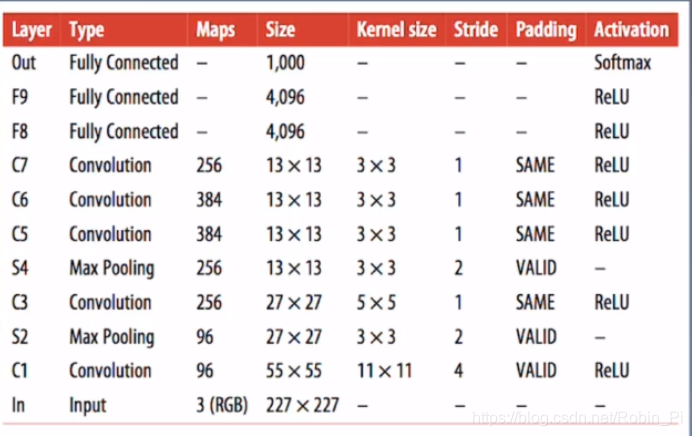
重要的创新/技巧:
- Dropout
在倒数2-3层的全连接层上加入了Dropout 机制,随机屏蔽一些神经元(后期还需要对参数进行还原)
该技巧提升了模型的泛化能力。
- Data augment
数据增强可以大大提升可以训练的数据量。
3.3 Inception 结构
(Google)
使用不同处理手段,最后按照 channel 维度拼接(需满足长和宽的维度大小——需要做padding),作为下一层的输入。
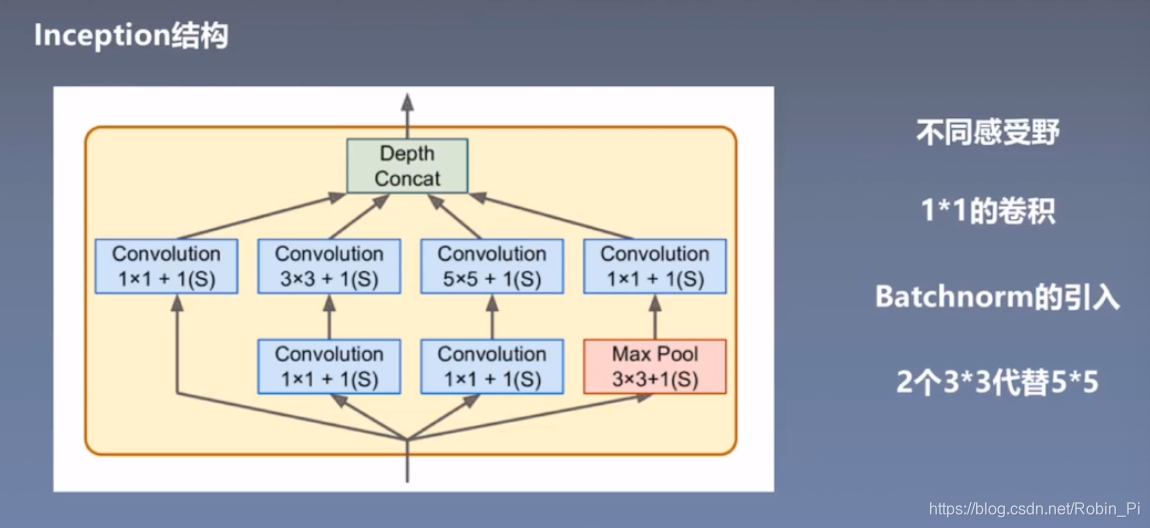
- 不同感受野
引入了 block,相当于引入了不同的感受野(集合到了一块)——相当于拥有了看”宏观信息“和”微观信息“的能力。 - 引入 1x1 的卷积
- 使得通道(channel)之间有了一定的沟通
- 压缩了 feature map,使得下一层卷积核的参数大大减少。
-
Batchnorm 的引入
注意:CNN 和 DNN 的使用方法有些不一样(维度不一样) -
2 个3x3 代替 5x5
真正理解”感受野“才行——让最顶层的神经元获取底层的所有信息即可:
5x5 的 feature map 可以用 5x5 的卷积核直接进行卷积,得到 1 个神经元;
5x5 的 feature map 也可以 由 1 个 3x3 的卷积核进行卷积得到 3x3的 feature map,最后再接一个卷积核就可以得到一个 1x1 的 feature map。
即用 2 个 3x3 的卷积核可以达到 1 个 5x5 卷积核达到的感受野。
同时,5x5的参数个数是 5x5=25 个,2 个3x3的只需要 3x3 + 3x3=18 个参数。参数越少越不容易过拟合,而且易于计算。
3.3 VGGNet
(微软)
VGGNet 完全依照 CNN的基本设计原则:
channel 越来越大;
feature map 的size 越来越小
VGGNet完全由卷积层和池化层的得加而来。
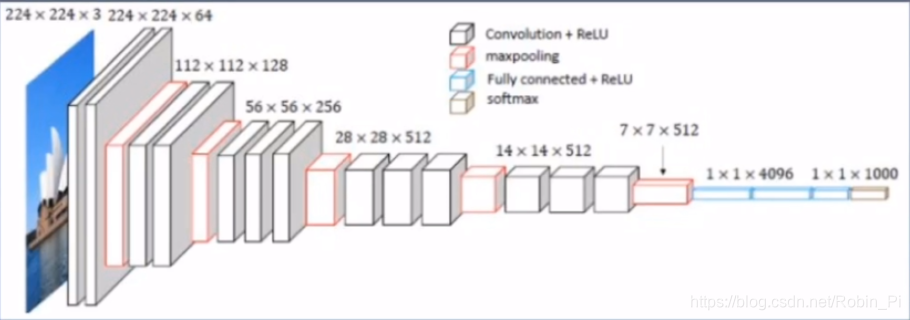
VGGNet完全由卷积层和池化层的得加而来。但是不能做得太深,直到微软又发明出了 Resnet(残差网络)
3.4 Resnet
残差网络在模型深度上有了新的突破,能轻易地训练到100多层!

注意: 图中的加号➕指的是维度上相加,所以 feature map 的长、宽以及 channel 必须统一。
(注:长跟宽-可以通过 padding 来完成统一;channel-可以通过 1x1的卷积来完成扩展或压缩)
- Skip connection 跳层连接
假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的 卷积层)f(x, θ)去逼近一个目标函数为h(x)。
有论文指出,残差函数—— h(x) - x 相比原始函数h(x) 更容易学习。
因此, 原来的优化问题可以转换为:让非线性单元 f (x, θ) 去近似残差函数 h(x) − x,并 用f(x,θ)+x 去逼近h(x)。
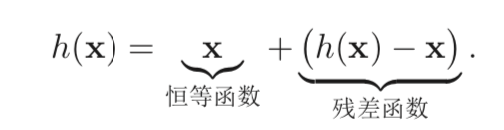
- Resnet 为什么效果很好,简单分析:
- 纯数学上,可以解决梯度消失的问题(BP角度)
- 集成模型(high way 角度)
- 是 ODE 方程的一个数学近似
3.4 Xception
深度可分离卷积
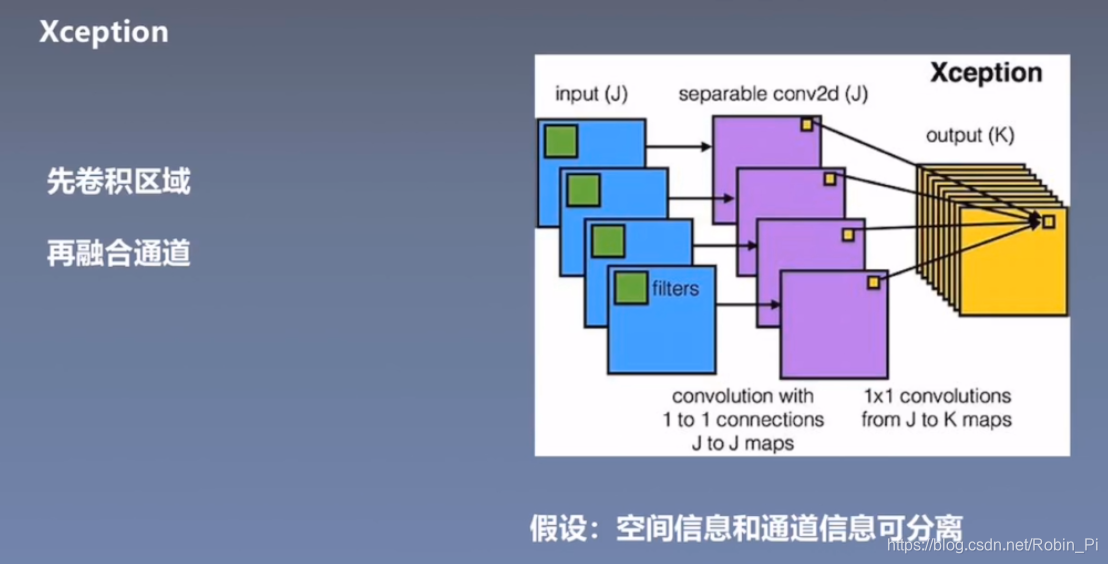
思想:先卷积区域,再融合通道
参数量会少很多;
将空间信息和通道信息分离;(假设)
比如,人脸 RGB 三种颜色、三层信息应该都能单独识别出人脸信息,而不应该非要融合在一起才能起作用。
可以继续参考:
4. 卷积神经网络中十大拍案叫绝的操作














 8628
8628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









