







欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
AIGC时代的 《三年面试五年模拟》AI算法工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写10万字Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章: 深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识

码字不易,希望大家能多多点赞!
Rocky持续在撰写Stable Diffusion 1.x、2.x以及XL的深入浅出全方位解析文章,希望大家能多多点赞,让Rocky有更多坚持的动力:
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
深入浅出完整解析Stable Diffusion(SD)核心基础知识
为了方便大家更好的阅读与理解,本文在整体脉络上将从Stable Diffusion 3 -> FLUX.1系列模型的顺序进行展开, 力求对Stable Diffusion 3和FLUX.1系列模型进行最详细的剖析与解读!
Rocky对Stable Diffusion 3(SD 3)的本质总结: 虽然Stable Diffusion 3只开源了medium版本,最大的8B参数版本并没有开源,但是SD 3所展现的很多改进思想和优化方法会像AI视频领域的Sora一样,给整个AI绘画领域带来强劲的更新迭代推动力,让AI绘画大模型的发展过程有丰富养分可以吸收。
Rocky对FLUX.1系列模型的本质总结: Rocky认为FLUX.1完全可以作为Stable Diffusion 3的正统续作来看待,说是“Stable Diffusion 4”也不为过,毫无疑问是AI绘画领域的“YOLOv5”!
同时,我们能够很欣慰的看到,SD系列模型就像传统深度学习时代的YOLO系列那样,在曲折中持续前进。YOLO原作者在2018年发布YOLOv3后便宣布不再继续更新。在大家都以为YOLO系列要成为绝唱时,终于在2020年有继承者发布全新的YOLOv4进行接棒。Rocky认为Stable Diffusion 3和FLUX.1毫无疑问也成为了AIGC时代的”传承佳话“,持续推动AIGC时代的火焰越来越旺盛!
2024.11.30最新消息:本文已经撰写Stable Diffusion 3和FLUX.1系列和对应LoRA的训练全流程与详细解读内容,同时发布对应的保姆级训练资源,大家可以愉快地训练属于自己的SD 3、FLUX.1和LoRA模型了!
2024.10.22最新消息:StabilityAI最新发布Stable Diffusion 3.5!
2024.10.3最新消息:最强文生图大模型FLUX 1.1版本发布!
2024.8.17最新消息:由于FLUX.1系列模型的网络结构比较复杂,不好可视化,导致大家看的云里雾里。因此本文中已经发布FLUX.1系列中VAE,MM-Single-DiT和Text Encoder(CLIP、T5-XXL )三大模型的可视化网络结构图,大家可以用于学习!
2024.8.12最新消息:本文已经开始持续撰写Flux.1系列模型核心基础知识!希望大家能多多点赞!
2024.08.10最新消息:由于Stable Diffusion 3模型的网络结构比较复杂,不好可视化,导致大家看的云里雾里。因此本文中已经发布Stable Diffusion 3中VAE,MM-DiT和Text Encoder(CLIP、T5-XXL )三大模型的可视化网络结构图,大家可以用于学习!
2024.7.6最新消息:Stable Diffusion 3开始允许商业化! 允许免费非商业用途、免费研究使用,以及任何收入低于100万美元(大约726万元人民币)的个人或组织免费商业使用。
2024.6.12最新消息:Stable Diffusion 3 medium版本正式开源!
大家好,我是Rocky。
2024年2月22号,Stability AI第一次发布了Stable Diffusion 3的相关消息,并于2024年3月5号开源Stable Diffusion 3的论文。但是等到2024年6月12号,Stable Diffusion 3的2B参数量的开源模型才姗姗来迟。

如此曲折的发布过程,其中就受到了包括了Stability AI盈利困难、Stable Diffusion系列模型的核心研究团队集体离职等因素的影响,一时间AIGC领域为之震动。
更戏剧性的是,在2024年8月1号,由Stable Diffusion模型核心团队重新组建的Black Forest Labs(黑森林实验室)带着迄今为止最强的开源文生图大模型FLUX.1王者归来,给AI绘画领域注入强大的新活力!

2024年无疑是AI视频领域的爆发之年,但对于AI绘画领域来说同样也是关键的变革之年。Stable Diffusion 3为AI绘画领域打开了Transformer时代的大门,紧接而来的FLUX.1则宣告AI绘画领域全面迈进Transformer时代。
这也让Rocky想起传统深度学习时代的YOLO系列模型,在2020年同时发布的YOLOv4和YOLOv5,同样深刻改变了目标检测领域的发展进程。“历史不会重复,但是会押韵”,AI绘画领域也像传统深度学习时代的目标检测领域一样,站在了历史的关键道路上。
如果说Stable Diffusion 1.x系列模型是“YOLO”,Stable Diffusion 2.x系列模型是“YOLOv2”,Stable Diffusion XL系列模型是“YOLOv3”,那么Stable Diffusion 3模型就是当之无愧的“YOLOv4”,而FLUX.1系列模型则是毋庸置疑的“YOLOv5”。
同时,Stable Diffusion 3和FLUX.1系列模型的连续发布,让Rocky想起了传统深度学习时代对于AI领域创新的判断总结,Rocky认为放在AIGC时代也非常合适:
- 让人耳目一新的创新:比如说Stable Diffusion、Sora、GPT-4、YOLO、Transformer、U-Net、ResNet、GAN等AI特定领域的“开山鼻祖”模型的提出。
- 守正出奇的创新:比如说从自注意力机制到交叉注意力机制的改进、从Batch Normalization到Ada Layer Normalization的改进等。
- 集成改进的创新:比如说将不同AI细分领域的有效Tricks迁移到特定AI领域再次形成SOTA性能。
从整体上看,Rocky认为Stable Diffusion 3和FLUX.1系列模型的发布,都是属于第一层到第二层之间的创新迭代。
在本文的后续内容中,Rocky将对Stable Diffusion 3和FLUX.1系列模型的全维度各个细节做一个深入浅出的分析与总结(SD 3和FLUX.1系列模型结构解析、SD 3和FLUX.1系列模型原理讲解、SD 3 和FLUX.1系列模型经典应用场景介绍、SD 3和FLUX.1系列模型性能优化、DiT核心基础知识讲解、SD 3和FLUX.1系列模型从0到1保姆级训练教程,SD 3和FLUX.1系列模型在不同AI绘画框架中从0到1推理运行保姆级教程、最新SD 3和FLUX.1系列模型资源汇总分享、AI绘画模型的主流性能测评指标讲解、SD 3和FLUX.1系列模型相关配套工具使用等),和大家一起交流学习,让我们能快速地入门学习Stable Diffusion 3、FLUX.1及其背后的AIGC领域,更好的迎接AI绘画领域的关键革新与发展。
1. Stable Diffusion 3和FLUX.1资源
- 官方博客:Stable Diffusion 3
- Stable Diffusion 3论文地址:Stable Diffusion 3
- Diffusion Transformer论文地址:Scalable Diffusion Models with Transformers
- Diffusion Transformer官方项目地址:https://github.com/facebookresearch/DiT
- Flow Matching论文地址:Flow Matching for Generative Modeling
- SD 3模型权重百度云网盘: 关注Rocky的公众号WeThinkIn,后台回复:SD 3模型,即可获得资源链接,包含Stable Diffusion 3模型权重、Stable Diffusion 3.5 Large/Medium/Turbo模型权重、Hyper Stable Diffusion 3模型权重。不同格式的模型权重比如safetensors格式、diffusers格式、FP16精度格式等均已包含。
- SD 3性能优化报告:pipelines/stable_diffusion_3
- FLUX.1官方项目地址:black-forest-labs/flux
- FLUX.1系列模型权重百度云网盘: 关注Rocky的公众号WeThinkIn,后台回复:FLUX模型,即可获得资源链接,包含FLUX.1-dev模型权重、FLUX.1-schnell模型权重、fLUX.1-lite-8B-alpha模型权重、FLUX.1 LoRA模型权重、FLUX.1 ControlNet模型权重、Hyper FLUX.1模型权重、FLUX.1 IP-Adapter模型权重。不同格式的模型权重比如safetensors格式、diffusers格式、FP16精度、FP8精度格式等均已包含。
- SD 3和FLUX.1保姆级训练资源百度云网盘: 关注Rocky的公众号WeThinkIn,后台回复:SD3-FLUX-Train,即可获得资源链接,包含数据处理、SD3和FLUX.1模型微调训练以及基于SD 3和FLUX.1的LoRA模型训练代码全套资源,帮助大家从0到1快速上手训练属于自己的SD 3和FLUX.1 AI绘画模型。更多SD 3和FLUX.1训练资源使用教程,请看本文第七章内容。
- Stable Diffusion 3和FLUX.1中VAE、Transformer和Text Encoder三大模型的可视化网络结构图下载: 关注Rocky的公众号WeThinkIn,后台回复:SD3网络结构/FLUX网络结构,即可获得网络结构图资源链接。
- Stable Diffusion 3.5官方项目地址:Stability-AI/sd3.5
- Stable Diffusion 3.5官方微调训练教程:Stable-Diffusion-3-5-Large-Fine-tuning-Tutorial
Rocky会持续把更多Stable Diffusion 3和FLUX.1系列模型的干货资源发布到本节中,让大家更加方便的查找SD 3和FLXU.1系列模型的最新资讯。
2. 深入浅出完整解析DiT(Diffusion Transformer)核心基础知识
在Rocky详细讲解Stable Diffusion 3和FLUX.1系列模型之前,我们首先前置学习DiT(Diffusion Transformer,Scalable Diffusion Models with Transformers)这个关键基础模型,SD 3和FLUX.1系列模型的核心架构基于它设计改进,它是AI绘画领域全面迈入Transformer时代的“关键地基”。
同时,AI视频领域的Sora模型也是基于DiT进行设计Baseline架构的,可见DiT模型在AIGC时代的重要性。可以说DiT对与AI绘画领域的重要意义,不亚于ResNet对于图像分类领域、U-Net对于图像分割领域、YOLO对于目标检测领域。

下面大家就跟随Rocky的脚步,让我们一起来挖掘DiT的核心价值与它的“前世今生”吧。
注意:如果有读者对DiT的核心基础知识已经比较熟悉,也可以跳过本章节,直接阅读学习后续章节中的Stable Diffusion 3和FLUX.1系列模型的干货内容。
2.1 通俗易懂全面理解DiT模型架构
DiT(Diffusion Transformer)模型由Meta在2022年首次提出,其主要是在ViT(Vision Transformer)架构基础上进行优化设计得到的。DiT是基于Transformer架构的扩散模型,将扩散模型中经典的U-Net架构完全替换成了Transformer架构。同时DiT是一个可扩展的架构,DiT不仅证明了Transformer思想与扩散模型结合的有效性,并且还验证了Transformer架构在扩散模型上具备较强的Scaling能力(Scalability),在稳步增大DiT模型参数量和增强训练数据质量时,DiT的生成性能稳步提升。其中最大的DiT-XL/2模型在ImageNet 256x256的类别条件生成任务上达到了2022年的SOTA(FID为2.27)性能。
DiT的整体框架并没有采用常规的Pixel Diffusion(像素扩散)架构,而是使用和Stable Diffusion相同的Latent Diffusion(潜空间扩散)架构。
为了获取图像的Latent特征,DiT使用了和SD系列一样的VAE(基于KL-f8)模型。当我们输入512x512x3的图像时,通过VAE能够编码出64x64x4大小的Latent特征,这极大地降低了扩散模型的计算复杂度(减少Transformer的tokens数量)。
DiT的nosie scheduler采用简单的Linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02),这与SD模型是不同的。在SD模型中,所采用的noise scheduler是Scaled Linear scheduler。DiT还沿用了OpenAI的Improved DDPM扩散思想,与原始DDPM相比不再采用固定的方差,而是采用网络来预测方差。
2.2 输入图像的Patch化(Patchify)
DiT和ViT一样,首先采用Patch Embedding策略将输入图像Patch化,主要作用是将VAE编码后的二维特征转化为一维序列,从而得到一系列的图像tokens,具体如下图所示:

同时,DiT在这个图像Patch化的过程中,设计了patch size这个超参数,它直接决定了图像tokens的大小和数量,从而影响DiT模型的整体计算量。DiT论文中共设置了三种patch size,分别是
p
=
2
,
4
,
6
p= 2,4,6
p=2,4,6。同时和其他Transformer模型一样,在得到图像tokens后,还要加上Positional Embeddings进行位置编码,DiT中采用经典的非学习sin&cosine位置编码技术。具体流程如下图所示:

输入图像在经过VAE编码器处理后,生成一个Latent特征,我们假设其尺寸为
I
×
I
×
C
(
64
×
64
×
4
)
I \times I \times C(64 \times 64 \times 4)
I×I×C(64×64×4),其中
I
I
I代表Latent特征的宽度和高度,
C
C
C是Latent特征的通道数。
接下来,用我们设定的patch size来将Latent特征进行Patch化,假设我们设定 p = 16 p=16 p=16,那么这时每个patch的尺寸为 16 × 16 16\times16 16×16。因此在宽度和高度方向可以分别划分出 64 16 = 4 \frac{64}{16} = 4 1664=4个patch。因此,整个Latent特征可以被分成16个patches。
最后我们将每个尺寸为 p = 16 p=16 p=16的patch展平(flatten)成一个向量,其尺寸为 [ 1 , 16 × 16 × 4 ] [1,16\times 16\times 4] [1,16×16×4],这个向量就构成了DiT模型的输入tokens,总的来说,生成的token数量 T T T为:
T = ( I p ) 2 T = \left(\frac{I}{p}\right)^2 T=(pI)2
同时每个token的维度为 d d d,这是DiT输入的Latent特征维度。
如果我们设置的 p p p较小,那么生成的tokens数量就会较多,这时DiT的输入序列长度会变长,从而增加整体的计算复杂度。
2.3 通俗易懂深入理解DiT Block模块
DiT在完成输入图像的预处理后,就要将Latent特征输入到Backbone网络中进行特征的提取了,DiT设计了和ViT模型类似的Backbone主干网络,全部由Transformer Blocks构成。但与ViT不同的是,DiT作为扩散模型还需要在Backbone主干网络中嵌入额外的条件信息(不同模态的条件信息等),这里的条件信息就包括了Timesteps以及类别标签等。
总的来说,DiT中的Backbone网络主要进行了两个工作,一个是常规的图像特征提取,另外一个是对图像特征和额外的多模态条件特征进行融合处理。
一般来说,无论是Timesteps还是类别标签,这些额外信息都可以采用一个Embedding来进行编码,从而注入DiT中。DiT论文中为了增强特征融合的能力,一共设计了四种方案来实现两个额外Embeddings的嵌入,具体如下图所示:

具体包括In-Context Conditioning(上下文条件)、Cross-Attention Block、Adaptive Layer Normalization (AdaLN) Block以及AdaLN-Zero block四种方案,下面Rocky对这四个方案进行详细的讲解。
【In-Context Conditioning(上下文条件)】
如上图中所示,将两个Embeddings看成两个tokens通过Concat的方式合并到Input tokens中,这种处理方式有点类似ViT中的cls token,实现简单同时也不引入额外的计算量。
【Cross-Attention Block】
如上图所示,在Transformer Block中插入一个Cross-Attention机制,将条件Embeddings作为Cross-Attention机制的key和value。这种方式是Stable Diffusion系列模型中常用的特征注入方式,它需要额外引入15%的Gflops。
【Adaptive Layer Normalization (AdaLN) Block】
我们首先了解一下Adaptive Layer Normalization(AdaLN)的基础概念和核心原理。
Adaptive Layer Normalization(AdaLN)是在Layer Normalization(LN)的基础上进行了优化,用来增强AI模型在处理不同输入条件时的适应能力。下面Rocky再通俗易懂地讲解AdaLN的核心原理:
首先在理解AdaLN之前,我们先简单回顾一下Layer Normalization,LN的处理步骤主要分成三步:
-
计算输入权重的均值和标准差:计算模型每一层输入权重的均值和标准差。
-
对输入权重进行标准化:使用计算得到的均值和标准差将输入权重标准化,使其均值为0,标准差为1。
-
对输入权重进行仿射变换:使用可学习的缩放参数和偏移参数,对标准化后的输入权重进行线性变换,使模型能够拟合任意的分布。
完整的LN公式如下所示:
LayerNorm ( x ) = γ ⋅ x − μ σ + ϵ + β \text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sigma + \epsilon} + \beta LayerNorm(x)=γ⋅σ+ϵx−μ+β
其中:
- x x x代表输入权重。
- μ \mu μ和 σ \sigma σ分别是输入权重的均值和标准差。
- γ \gamma γ和 β \beta β是可学习的参数,用于输入权重的缩放和偏移。
- ϵ \epsilon ϵ 是一个小常数,防止除零造成的NAN问题。
讲到这里,我们就了解LN的核心原理了,接下来我们再看看AdaLN是如何在此基础上进行优化的。
AdaLN的核心思想是根据输入的不同条件信息,自适应地调整LN的 γ \gamma γ 缩放参数和 β \beta β偏移参数。AdaLN的核心步骤包括:
- 提取条件信息:从输入的条件(如Text Embeddings、类别标签等)中提取信息,一般来说会专门使用一个神经网络模块(比如全连接层等)来处理输入条件,并生成与输入数据相对应的缩放和偏移参数。
在DiT的官方实现中,使用了一个全连接层+SiLU激活函数来实现这样一个输入条件的特征提取网络:
#输入条件的特征提取网络
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
#c代表输入的条件信息
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
同时,DiT在每个残差模块之后还使用了一个回归缩放参数 α \alpha α来对权重进行缩放调整,这个 α \alpha α参数也是由上述条件特征提取网络提取的。
上面的代码中我们可以看到,adaLN计算了6个变量shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp,这6个变量分别对应了多头自注意力机制的归一化参数与缩放参数(下图中的
β
1
,
γ
1
,
α
1
,
β
2
,
γ
2
,
α
2
\beta_1,\gamma_1,\alpha_1,\beta_2,\gamma_2,\alpha_2
β1,γ1,α1,β2,γ2,α2):

-
生成自适应的缩放和偏移参数:利用提取的条件信息,生成自适应的缩放和偏移参数。假设输入条件为 c c c,经过一个神经网络模块(比如全连接层等)生成缩放参数和偏移参数如下:
γ a d a = f γ ( c ) β a d a = f β ( c ) \gamma_{ada} = f_\gamma(c) \\ \beta_{ada} = f_\beta(c) γada=fγ(c)βada=fβ(c) -
应用自适应参数:使用这些自适应参数对输入权重进行LN处理:
AdaLN ( x , c ) = γ a d a ⋅ x − μ σ + ϵ + β a d a \text{AdaLN}(x, c) = \gamma_{ada} \cdot \frac{x - \mu}{\sigma + \epsilon} + \beta_{ada} AdaLN(x,c)=γada⋅σ+ϵx−μ+βada
为了帮助大家理解,下面是Rocky撰写的AdaLN处理流程图:

当在DiT中采用AdaLN Block模块时,其核心思想是通过DiT模型在训练中自适应学习 γ \gamma γ和 β \beta β两个参数。将Time Embedding和Class Embedding两个额外条件信息相加,并作为AdaLN Block模块的输入,进而来拟合 γ \gamma γ 和 β \beta β这两个参数,这种方式也不增加计算量。
【AdaLN-Zero block】
在传统深度学习时代中,有研究表明在ResNet模型和Batch Normalization(BN)层中使用0初始化其中的部分结构参数可以达到加速模型训练的效果。
ResNet作为在传统深度学习时代和AIGC时代都持续繁荣的跨周期模型,其核心思想是设计了残差模块(ResNet Block)。残差模块可以让网络直接学习输入和输出之间的残差,而不是完全从零开始学习输入到输出的映射。残差模块的经典形式如下:
y = F ( x , W ) + x y = F(x, W) + x y=F(x,W)+x
其中 F ( x , W ) F(x, W) F(x,W)是网络的非线性变换,包含模型参数 W W W和输入权重 x x x; y y y是输出权重。
在训练过程中,为了让网络在训练初期更稳定,将残差模块中的 F ( x , W ) F(x, W) F(x,W)的权重初始化为 0。这意味着在训练开始时,残差模块的输出就是:
y = x + 0 = x y = x + 0 = x y=x+0=x
可以看到,初始的残差模块只会将输入直接传到下一层网络中,而不会做任何的参数修改。这种初始化策略使得模型在开始时相当于一个**“简化的网络”,输入权重能够直接传递给后续的网络层。这种透传特性有助于训练初期的稳定性,使模型可以逐渐从简单到复杂,逐步学习整个数据集的分布。同时,因为网络在初期不需要学习复杂的特征,因此可以更快地进入到高效的训练状态,从而达到加速训练**的效果。
除此之外,BN层作为一种加速神经网络训练的技术,也跨越周期来到了AIGC时代。它通过归一化每个Batch的输入数据,使其成为具有均值为0和方差为1的分布,从而稳定训练过程。其中BN最核心的参数就是缩放因子(scale parameter,记为 γ \gamma γ),它用于调整归一化后的输出。 并且 γ \gamma γ参数的初始化值也会对模型训练的速度有一定的影响。
通过将BN层中的缩放因子 γ \gamma γ初始化为0,可以让初始的BN层输出的值保持不变(即归一化后的输出为 0),从而允许模型直接传递输入特征。当 γ = 0 \gamma = 0 γ=0时,BN层的输出就相当于一个恒定值,这样可以减少训练初期的梯度不稳定性,让模型从更简单的状态开始训练。在训练开始时,模型的学习过程会更接近于线性变换,因此能更快地收敛到有效的解,随着训练的深入进行,模型能够更平滑地进入非线性学习阶段,从而有条不紊充分学习到非线性的复杂数据特征。
到这里我们就学习了ResNet模型和BN层中使用0初始化的价值,其本质是通过减小模型初期的复杂性,让网络逐步学到更深层次的特征,使得模型能更快、更稳定地进行训练和优化。在DiT模型的DiT Block模块中也包含了大量的残差结构与LayerNorm结构。就这样,0初始化作为传统深度学习时代的跨周期经验在DiT中重新繁荣了!
DiT中具体的初始化设置如下所示:
- 对DiT Block中的AdaLN和Linear层均采用参数0初始化。
- 对于其它网络层参数,使用正态分布初始化和xavier初始化。
到此为止,Rocky已经详细介绍了DiT论文中的四种额外特征注入方案。DiT论文中对四种方案也进行了对比试验,主要使用了FID(Fréchet inception distance)指标进行效果评估。最终发现采用AdaLN-Zero效果是最好的,所以DiT默认都采用这种方式来嵌入条件Embeddings。与此同时,AdaLN-Zero也成为了基于DiT架构的AI绘画大模型的必备策略。

基于adaLN-Zero的DiT Block模块的实现代码如下所示,大家能直观的理解DiT架构的魅力:
def modulate(x, shift, scale):
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x
由于对输入图像进行了token化,所以DiT在最后采用一个Decoder(简单的linear层)来恢复输入的原始维度,将每个token映射为
p
×
p
×
2
C
p\times p\times2C
p×p×2C的Latent特征,然后再通过reshape操作来得到和原始输入空间维度一样的输出特征,但是特征通道数是原来的2倍,分别用来预测噪声和方差。
DiT和ViT类似,也设计了4种不同规模的模型,分别是DiT-S、DiT-B、DiT-L和DiT-XL,其中最大的模型DiT-XL参数量为675M,计算量Gflops为29.1(在256x256图像上设置patch size=4时)。DiT发布之初,只在ImageNet上做了生成实验,并没有扩展到大规模的文生图大模型上。但是DiT犹如沙滩上的蝴蝶扇动了一次不常规的翅膀,在两年后的AI绘画海洋中,掀起了猛烈的创新浪潮!
到这里,Rocky已经完整讲解DiT的核心基础知识。在下面的章节中,Rocky将带着大家进入AIGC时代,进入AI绘画领域,深入浅出讲解Stable Diffusion 3和FLUX.1系列模型的全维度核心知识。
码字实在不易,希望大家能多多点赞!!!
3. Stable Diffusion 3核心基础内容
Stable Diffusion 3是由Stability AI发布的最强文生图大模型,比起Stable Diffusion之前的系列,Stable Diffusion 3在多主题提示词的控制编辑一致性能力(multi-subject prompts)、文字渲染控制能力(spelling abilities)以及图像生成的整体质量(image quality)三个维度都有大幅的提升。
3.1 Stable Diffusion 3整体架构初识
Stable Diffusion 3依旧是一个End-to-End模型,最大的亮点是扩散模型部分使用了全新的MM-DiT(Multimodal Diffusion Transformer)架构,这与OpenAI发布的文生视频大模型Sora一致(Transformer is all you need!)。
同时采用优化改进的Flow Matching(FM)技术训练SD 3模型,Flow Matching技术由Meta于2022年提出,可以让扩散模型的训练过程更高效稳定,而且还可以支持更快的采样生成,同时生成质量进一步提高。
为了让用户能够在不同应用场景和硬件环境使用SD 3模型,SD 3一共发布了参数从8亿到80亿(800M-8B,扩散模型部分)的多个版本,也再次证明了Transformer架构的强大scaling能力。
目前官方开源了2B参数量的Stable Diffusion 3 medium版本,在FP16精度下Stable Diffusion 3 medium模型大小为15.8G(FP32:33.6G,FP8:10.9G),其中MM-DiT大小为4.17G(参数量约2B),VAE模型大小为168M(参数量约80M),CLIP ViT-L大小为246M(参数量约124M),OpenCLIP ViT-bigG大小为1.39G(参数量约695M),T5-XXL Encoder在FP16精度下大小为9.79G(参数量约4.7B,FP8精度下大小为4.89G)
Rocky认为SD 3模型可以作为未来AIGC时代AI多模态产品中的核心基础模型,以SD 3为基底模型进行图像、视频、3D、文本等生成内容的创作。

Stable Diffusion 3的整体网络结构图如下所示:

3.2 VAE模型(包含详细图解)
VAE(变分自编码器,Variational Auto-Encoder)模型在Stable Diffusion 3(SD 3)中依旧是不可或缺的组成部分,Rocky相信不仅在SD 3模型中,在AIGC时代的未来发展中VAE模型也会持续发挥价值。
到目前为止,在AI绘画领域中关于VAE模型我们可以明确的得出以下经验:
- VAE作为Stable Diffusion 3的组成部分在AI绘画领域持续繁荣,是VAE模型在AIGC时代中最合适的位置。
- VAE在AI绘画领域的主要作用,不再是生成能力,而是辅助SD 3等AI绘画大模型的压缩和重建能力。
- VAE的编码和解码功能,在以SD 3为核心的AI绘画工作流中有很强的兼容性、灵活性与扩展性,也为Stable Diffusion系列模型增添了几分优雅。
和之前的系列一样,在SD 3中,VAE模型依旧是将像素级图像编码成Latent特征,不过由于SD 3的扩散模型部分全部由Transformer架构组成,所以还需要将Latent特征转换成Patches特征,再送入扩散模型部分进行处理。
之前SD系列中使用的VAE模型是将一个 H × W × 3 H\times W\times 3 H×W×3的图像编码为 H 8 × W 8 × d \frac{H}{8}\times \frac{W}{8} \times d 8H×8W×d的Latent特征,在8倍下采样的同时设置 d = 4 d=4 d=4(通道数),这种情况存在一定的压缩损失,产生的直接影响是对Latent特征重建时容易产生小物体畸变(比如人眼崩溃、文字畸变等)。
所以SD 3模型通过提升
d
d
d来增强VAE的重建能力,提高重建后的图像质量。下图是SD 3技术报告中对不同
d
d
d的对比实验:

我们可以看到,当设置 d = 16 d=16 d=16时,VAE模型的整体性能(FID指标降低、Perceptual Similarity指标降低、SSIM指标提升、PSNR指标提升)比 d = 4 d=4 d=4时有较大的提升,所以SD 3确定使用了 d = 16 d=16 d=16(16通道)的VAE模型。
与此同时,随着VAE的通道数增加到16,扩散模型部分(U-Net或者DiT)的通道数也需要跟着修改(修改扩散模型与VAE Encoder衔接的第一层和与VAE Decoder衔接的最后一层的通道数),虽然不会对整体参数量带来大的影响,但是会增加任务整体的训练难度。因为当通道数从4增加到16,SD 3要学习拟合的内容也增加了4倍,我们需要增加整体参数量级来提升模型容量(model capacity)。下图是SD 3论文中模型通道数与模型容量的对比实验结果:

当模型参数量小时,16通道VAE的重建效果并没有比4通道VAE的要更好,当模型参数量逐步增加后,16通道VAE的重建性能优势开始展现出来,当模型的深度(depth)增加到22时,16通道的VAE的性能明显优于4通道的VAE。
不过上图中展示了8通道VAE在FID指标上和16通道VAE也有差不多的效果,Rocky认为在生成领域,只使用一个指标来评价模型整体效果是不够全面的,并且FID只是图像质量的一个间接评价指标,并不能反映图像细节的差异。从重建效果上看,16通道VAE应该有更强的重建性能,而且当模型参数量级增大后,SD 3模型的整体性能上限也大幅提升了,带来了更多潜在的优化空间。
下面是Rocky梳理的Stable Diffusion 3 VAE完整结构图,大家可以感受一下其魅力。希望能让大家对这个在Stable DIffusion系列中持续繁荣的模型有一个更直观的认识,在学习时也更加的得心应手:

可以看到,SD 3 VAE模型中有三个基础组件:
- GSC组件:GroupNorm+SiLU+Conv
- Downsample组件:Padding+Conv
- Upsample组件:Interpolate+Conv
同时SD 3 VAE模型还有两个核心组件:ResNetBlock模块和SelfAttention模块,两个模块的结构都已在上图中展示。
SD 3 VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
而VAE Decoder部分正好相反,其输入Latent特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
下面是Rocky对1024x1024分辨率和2048x2048分辨率图像经过VAE压缩和重建的效果对比(从左到右分别是原图、SDXL、SD 3的重建图):

可以看到,在2048x2048高分辨率上,SDXL VAE出现了较明显的内容和文字的信息损失。与此同时,SD 3 VAE能够较好的对高分辨率图像进行压缩与重建。
关于FLUX.1系列模型中VAE部分讲解,大家可以阅读本文的5.2章节,Rocky已经在该章节深入浅出的讲解。大家进行对比研读,能更好的理解两者的异同,从而收获更多的思考与感悟。
3.3 MM-DiT模型(Multimodal Diffusion Backbone,包含详细图解)
Rocky认为Stable Diffusion 3在架构上最重要的改进就是设计了以多模态DiT(MM-DiT)作为核心的扩散模型,这标志着AI绘画领域全面进入了Transformer时代。
SD 3中MM-DiT架构的一个核心关键是对图像的Latent Tokens和文本的Tokens设置了两套独立的权重参数,并在Attention机制前拼接在一起,再送入Attention机制进行注意力的计算。MM-DiT架构图如下所示:

在Stable Diffusion之前的系列中,对于文本的Text Embeddings的统一处理方式是在U-Net中使用Cross-Attention机制来与图像信息结合,其中Text Embeddings作为Attention中的keys和values。SD 3一改之前的范式,直接将Text Embeddings和图像的patch Embeddings拼接(Concat)在一起进行处理,将文本特征的重要性和图像特征对齐,这样就不需要再引入Cross-Attention机制。
由于图像和文本属于两个不同的模态,所以SD 3中采用两套独立的权重参数来处理学习这两个不同模态的特征,两种模态特征在所有Transformer层的权重参数并不是共享的,只通过Self-Attention机制来实现特征的交互融合。这相当于使用了两个独立的Transformer模型来处理文本和图像信息,这也是SD 3技术报告中称这个结构为MM-DiT的本质原因,这是一个多模态扩散模型。
下图是Rocky梳理的Stable Diffusion 3 MM-DiT的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion 3 MM-DiT部分,相信大家脑海中的思路也会更加清晰:

从上图可以看到,SD 3 MM-DiT中主要包含了以下的核心模块:
- MM-DiT Block:一共有24个MM-DiT Blocks构成了MM-DiT架构的主体。每个MM-DiT Block中包含了两个AdaLayerNormZero层+MM-DiT Attention层+两个LayerNorm层+两个FeedForward层。
- MM-DiT Attention Structure:MM-DiT Block中的核心组件,用于将图像特征和文本特征进行同等级别的Attention机制。
- FeedForward:由GELU+Dropout+Linear组成。
MM-DiT和原生DiT模型一样在Latent空间中将图像的Latent特征转成patches特征,这里的patch size=2x2,和原生DiT的默认配置一致。接着和ViT一样,将得到的Patch Embedding与Positional Embedding相加(add)一起输入到Transformer的主架构中。
有读者可能会问,什么是Positional Embedding呢?
在 Vision Transformer (ViT) 中,Positional Embedding(位置嵌入) 是为了解决 Transformer 对输入顺序不敏感的问题而设计的。由于 Transformer 不像卷积神经网络那样能够直接感知空间信息,因此需要显式地将位置编码添加到 patch embeddings 中,让模型了解输入数据的空间布局。在SD 3中也是用了这一经典的位置编码技术,设置固定Positional Embedding(Sine-Cosine Encoding),本质上通过正弦和余弦函数根据patch的二维位置(行和列)生成固定的位置编码,获得类似于下面的特征矩阵:
E p o s = [ 0.0 1.0 0.0 0.5 … 0.1 0.2 0.9 0.3 0.6 … 0.4 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ 0.5 0.8 0.6 0.7 … 0.3 ] \mathbf{E}_{pos} = \begin{bmatrix} 0.0 & 1.0 & 0.0 & 0.5 & \dots & 0.1 \\ 0.2 & 0.9 & 0.3 & 0.6 & \dots & 0.4 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0.5 & 0.8 & 0.6 & 0.7 & \dots & 0.3 \end{bmatrix} Epos= 0.00.2⋮0.51.00.9⋮0.80.00.3⋮0.60.50.6⋮0.7……⋱…0.10.4⋮0.3
与此同时,MM-DiT中将文本特征CLIP pooled embedding(全局语义信息)直接和Timestep Embedding加(add)在一起,并通过我们在之前DiT章节中提到的adaLN-Zero层将融合特征作为额外条件注入到Transformer Block中。下面Rocky通过图文和代码两个维度直观为大家讲解CLIP pooled embedding和Timestep Embedding的特征融合过程:
class CombinedTimestepTextProjEmbeddings(nn.Module):
def __init__(self, embedding_dim, pooled_projection_dim):
super().__init__()
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
def forward(self, timestep, pooled_projection):
timesteps_proj = self.time_proj(timestep)
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
pooled_projections = self.text_embedder(pooled_projection)
conditioning = timesteps_emb + pooled_projections
return conditioning
从上面的代码中可以看到,完成CLIP pooled embedding和Timestep Embedding特征提取后,再通过add操作将两个特征进行融合相加,就获得了要注入每一个Transformer Block的adaLN-Zero层的Conditioning特征。下图是详细清楚的图示,让大家能够直观的了解感受:

关于adaLN-Zero层应用的具体细节各位读者可以回看本文的第二章节内容。
同时为了验证MM-DiT架构的有效性,SD 3论文中还将3套不同参数的MM-DiT(CLIP text tokens、T5-XXL text tokens和Patches分别各一套参数)与CrossDiT(引入Cross-Attention机制的DiT架构)、UViT(U-Net和Transformer混合架构)基于CC12M数据集训练后进行性能对比,不同架构的模型具体表现如下图所示:

可以看到MM-DiT在性能上是明显优于其它架构的, MM-DiT的模型参数规模主要是模型的深度 d d d,即Transformer Block的数量决定的,论文中设置的SD 3 MM-DiT模型中间特征的维度大小是 64 ⋅ d 64\cdot d 64⋅d。当论文中设置深度为24时,MM-DiT参数量为2B;当深度设为最大的38时,MM-DiT参数量为8B。所以目前SD 3系列最大的版本参数量有 8 B 8B 8B左右。这意味着当SD 3模型的深度 d d d增大为 r ⋅ d r\cdot d r⋅d,模型的参数量会同比增大 r 3 r^3 r3,即 2 B ∗ ( 38 / 24 ) 3 ≈ 8 B 2B*(38/24)^3\approx 8B 2B∗(38/24)3≈8B。
到这里,Rocky就将SD 3 MM-DiT架构讲解好了。码字不易,希望大家能多多点赞!!!
3.4 Text Encoder模型(包含详细图解)
Stable Diffusion 3的文字渲染能力很强,同时遵循文本Prompts的图像生成一致性也非常好,这些能力主要得益于SD 3采用了三个Text Encoder模型,它们分别是:
- CLIP ViT-L(参数量约124M)
- OpenCLIP ViT-bigG(参数量约695M)
- T5-XXL Encoder(参数量约4.76B)
在SD系列模型的版本迭代中,Text Encoder部分一直在优化增强。一开始SD 1.x系列的Text Encoder部分使用了CLIP ViT-L,在SD 2.x系列中换成了OpenCLIP ViT-H,到了SDXL则使用CLIP ViT-L + OpenCLIP ViT-bigG的组合作为Text Encoder。有了之前的优化经验,SD 3更进一步增加Text Encoder的数量,加入了一个参数量更大的T5-XXL Encoder模型。
与SD模型的结合其实不是T5-XXL与AI绘画领域第一次结缘,早在2022年谷歌发布Imagen时,就使用了T5-XXL Encoder作为Imagen模型的Text Encoder,并证明了预训练好的纯文本大模型能够给AI绘画大模型提供更优良的文本特征。接着OpenAI发布的DALL-E 3也采用了T5-XXL Encoder来提取文本(Prompts)的特征信息,足以说明T5-XXL Encoder模型在AI绘画领域已经久经考验。
这次SD 3加入T5-XXL Encoder也是其在文本理解能力和文字渲染能力大幅提升的关键一招。Rocky认为在AIGC时代,随着各细分领域大模型技术的持续繁荣,很多灵感创新都可以在AI绘画领域中迁移借鉴与应用,从而推动AI绘画大模型的持续发展与升级!
下图是Rocky梳理的Stable Diffusion 3 CLIP ViT-L Text Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习SD 3 ViT-L CLIP Text Encoder部分,相信大家脑海中的思路也会更加清晰:

可以看到SD 3 ViT-L CLIP Text Encoder是只包含Transformer结构的模型,一共由12个CLIPEncoderLayer模块组成。同时每个CLIPEncoderLayer模块包含一个Self-Attention层和MLP层。
下图是Rocky梳理的Stable Diffusion 3 OpenCLIP ViT-bigG Text Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习SD 3 OpenCLIP ViT-bigG Text Encoder部分,相信大家脑海中的思路也会更加清晰:

可以看到SD 3 ViT-bigG CLIP Text Encoder同样只包含Transformer结构的模型,一共由32个CLIPEncoderLayer模块组成。同时每个CLIPEncoderLayer模块同样包含一个Self-Attention层和MLP层。
下图是Rocky梳理的Stable Diffusion 3 T5-XXL Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习SD 3 T5-XXL Text Encoder部分,相信大家脑海中的思路也会更加清晰:

SD 3 T5-XXL Text Encoder也是只包含Transformer结构的模型,但与CLIP系列模型相比,整体网络架构上有较大的不同。T5-XXL Text Encoder一共由24个T5-XXL Block模块组成。同时每个T5-XXL Block模块包含一个T5LayerFF层和T5Self-Attention层。
接下来,让我们一起来学习SD 3中三个Text Encoder模型的具体作用。总的来说,SD 3一共需要提取输入文本的全局语义和文本细粒度两个层面的信息特征。
首先需要提取CLIP ViT-L和OpenCLIP ViT-bigG的Pooled Text Embeddings,它们代表了输入文本的全局语义特征,维度大小分别是768和1280,两个embeddings拼接(concat操作)得到2048的embeddings,然后经过一个MLP网络并和Timestep Embeddings相加(add操作)。
接着我们需要提取输入文本的细粒度特征。这里首先分别提取CLIP ViT-L和OpenCLIP ViT-bigG的倒数第二层的特征,拼接在一起得到77x2048维度的CLIP Text Embeddings;再从T5-XXL Encoder中提取最后一层的T5 Text Embeddings特征,维度大小是77x4096(这里也限制token长度为77)。紧接着对CLIP Text Embeddings使用zero-padding得到和T5 Text Embeddings相同维度的编码特征。最后,将padding后的CLIP Text Embeddings和T5 Text Embeddings在token维度上拼接在一起,得到154x4096维度的混合Text Embeddings。这个混合Text Embeddings将通过一个linear层映射到与图像Latent的Patch Embeddings特征相同的维度大小,最终和Patch Embeddings拼接在一起送入MM-DiT中。具体流程如下图所示:

虽然SD 3采用CLIP ViT-L + OpenCLIP ViT-bigG + T5-XXL Encoder的组合带来了文字渲染和文本一致性等方面的效果增益,但是也限制了T5-XXL Encoder的能力。因为CLIP ViT-L和OpenCLIP ViT-bigG都只能默认编码77 tokens长度的文本,这让原本能够编码512 tokens的T5-XXL Encoder在SD 3中也只能处理77 tokens长度的文本。而SD系列的“友商”模型DALL-E 3由于只使用了T5-XXL Encoder一个语言模型作为Text Encoder模块,所以可以输入512 tokens的文本,从而发挥T5-XXL Encoder的全部能力。
由于三个Text Encoder都是已经预训练好的语言模型,因此在SD 3的训练过程中它们的参数被冻结。 同时三个Text Encoder的特征单独以46.4%的概率进行drop,然后送入MM-DiT中辅助SD 3的训练。按照这样的思路,其实在SD 3推理时也是可以任意组合这三个Text Encoder的。
由于T5 XXL的参数量是最大的,所以一些读者如果想在2080Ti等GPU上轻量化的部署推理SD 3模型,可以只使用CLIP ViT-L + OpenCLIP ViT-bigG的特征,此时需要将T5-XXL的特征设置为zero(不加载)。如下图所示,SD 3论文中对SD 3 的8B模型进行了实验,发现去掉T5-XXL后,图像生成的整体质量不会下降(有50%的胜率),但是文字渲染能力大幅下滑(仅有38%的胜率),同时文本理解能力有一定的下滑(只有46%的胜率)。

整体上看,T5-XXL Encoder对于SD 3还是非常关键的,因为就算是最大的8B模型,缺少了T5-XXL Encoder后,SD 3引以为傲的文字渲染与文字理解能力都大打折扣。而目前开源的仅是2B参数的SD 3 medium,如果要降低显存占用而不使用T5-XXL Encoder,那么SD 3模型在开源社区是否能与SDXL甚至SD 1.x系列同台竞技都需要打上问号。

T5-XXL对于SD 3的意义非常重大,我们还可以通过使用FP8精度的T5-XXL来替代FP16精度,大约可以节省6G左右的显存,同时只损失了少许生成精度。就算这样,生成效果也远远好于只使用两个CLIP模型,因此不失为一种高性价比的轻量化方案。
码字不易,希望大家能给Rocky的劳动多多点赞!!!
3.5 使用优化的RF(Rectified Flow)采样方法(无公式通俗易懂讲解)
SD 3不再使用DDPM作为扩散模型,而是改用优化的RF(Rectified Flow)做为扩散模型。
图像生成任务本质上是让模型学习一个图像数据集所表达的数据分布,之后再从这个数据分布中进行随机采样。比如我们想让模型生成二次元图像,就是要让模型学习一个二次元数据集的数据分布。
一般来说,我们很难表达出一个适合采样的复杂分布。因此,我们会把学习一个数据分布的问题转换成学习一个简单好采样的数据分布到复杂数据分布的映射关系,一般这个简单分布我们会选择标准正态分布。但是学习这种映射关系依然是很困难的。
基于DDPM的扩散模型用一种巧法来学习这种映射:从纯噪声(标准正态分布里的数据)到真实数据的映射很难表达,但从真实数据到纯噪声的逆映射就比较容易表达。所以,我们可以先人工定义从图像数据集到噪声的变换路线,然后再让模型学习对应的逆路线。这样让噪声数据沿着逆路线走,就实现了从噪声到图像的生成过程。
在知道了人工定义的数据到噪声的变换路线后,也就知道了数据在路线上每一位置的对应速度。这时我们就可以以每一位置的反向速度为基准,学习到噪声到真实数据的速度场,这样的学习过程就被称为流匹配 (Flow Matching)。
SD 3中使用的Rectified Flow技术的核心思想就是通过引入流匹配方法,对于不同的扩散模型及流匹配模型,其本质区别在于图像到噪声的路线的定义方式。在扩散模型中,图像到噪声的路线通常是由一个复杂的公式表示的。而使用Rectified Flow技术后,扩散模型的训练过程被定义为一个Rectified Flow,以一条直线连接数据分布和噪声分布,简化模型的训练和推理过程,提升图像生成效率,具有较好的简洁性。Rectified Flow中的前向过程:
z t = ( 1 − t ) x 0 + t ϵ z_t=(1-t)x_0+t\epsilon zt=(1−t)x0+tϵ
RF的前向过程一个特点是 z t z_t zt由数据 x 0 x_0 x0和噪声 ϵ \epsilon ϵ线性插值得到,表示我们人工定义的概率路径是一条直线。直线的一个好处是采样时我们可以步子迈大一点,这就相当于我们可以减少采样的总步数。
虽然SD 3没有提出新的流匹配方法,但论文中的实验结果表明流匹配模型更适合文生图任务。
在使用Rectified Flow技术后,SD 3还使用了非均匀噪声采样来优化Rectified Flow。对于Rectified Flow,其默认使用均匀分布 t ∼ U ( 0 , 1 ) t\sim\mathcal{U}(0, 1) t∼U(0,1)进行采样,这也就是说各个时间步 t t t是被等价对待的。但是SD 3论文中发现不同时间步的任务难度是不一样的:刚开始和快到终点的路线很好学,而路线的中间处比较难学。所以,SD 3中设计了非均匀噪声采样方法来提高中间时间步的权重。
如下图所示,SD 3主要考虑了两种方法:Mode Sampling with Heavy Tails(左边)和Logit-Normal Sampling(右边)。两种方法的共同点是中间部分进行采样加权,两边加权较少较多。同时Logit-Normal分布的一个问题是两边
t
=
0
t=0
t=0和
t
=
1
t=1
t=1附近基本采样不到,可能会对性能有一定的影响。
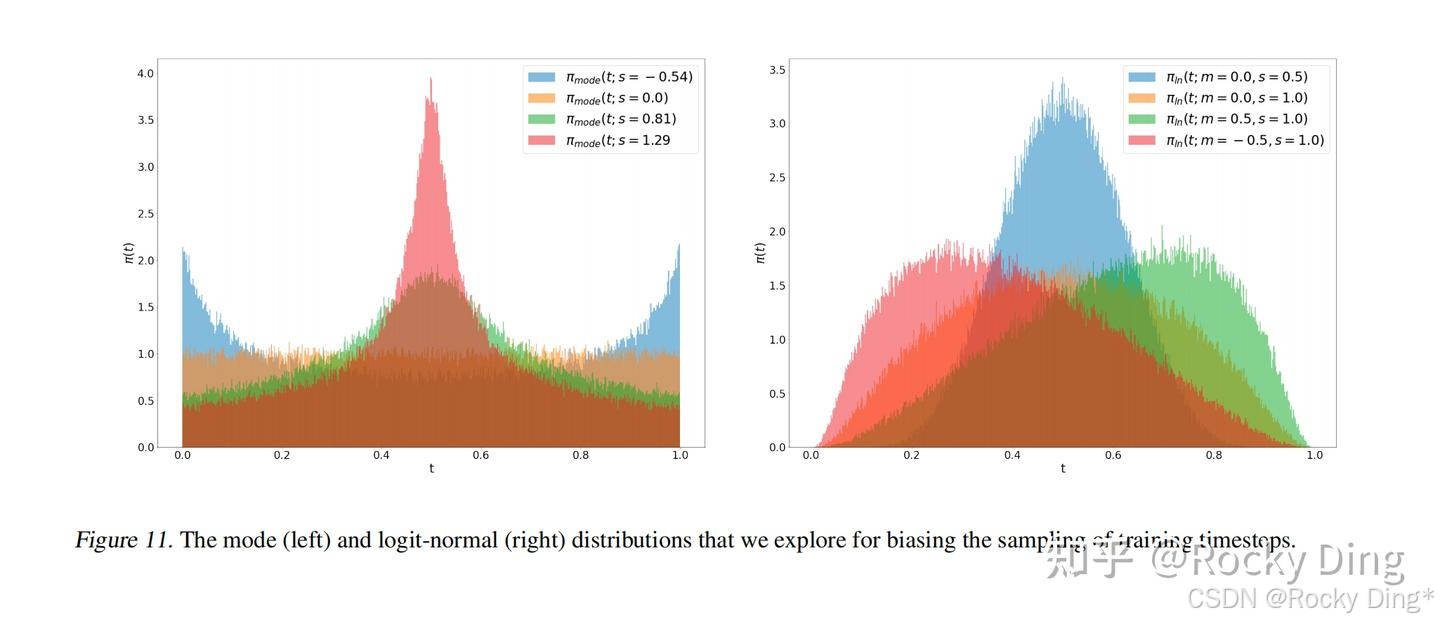
码字不易,希望大家能多多点赞!!!
4. Stable Diffusion 3官方训练技巧&细节解析
4.1 训练数据预处理
在SD 3的技术报告中并没有公布预训练数据集的来源分布,不过技术报告中的很多数据预处理技术依旧值得我们借鉴研究:
- NSFW风险内容过滤:使用NSFW检测模型来过滤这些风险数据。
- 筛除美学分数较低的数据:使用美学评分系统预测图像的美学分数,并筛除分数较低的数据。
- 数据去重:使用基于聚类的去重方法来筛除数据集中重复的图像,防止模型对于某些重复图像中的特征过拟合。
SD 3中构建了非常专业的数据去重策略,使用SSCD算法作为backbone生成数据集的高质量Embedding特征,并结合autoFAISS(Facebook AI Similarity Search)的大规模聚类功能,进而高效移除数据集中的重复样本。这种去重方法降低了模型的过拟合风险,同时保留了训练数据的多样性。具体的流程如下所示:

为了更生动地讲解上述的聚类过程,下面Rocky给大家举一个具体例子。
假设我们有一个簇,里面包含 5 张图像的嵌入向量,每个向量是 3 维的;每张图像有一个对应的 ID。我们希望找到这些图像中相似的图像,我们设置阈值是0.5,用于衡量两张图像是否相似。
其中向量列表(vecs):
vecs = [
[0.1, 0.2, 0.3], # 图像1
[0.1, 0.2, 0.4], # 图像2
[0.9, 0.8, 0.7], # 图像3
[0.9, 0.8, 0.8], # 图像4
[0.0, 0.1, 0.2] # 图像5 ]
图像 ID 列表(items):
items = [101, 102, 103, 104, 105]
遍历每个向量 vecs[i],依次执行以下步骤5次。
第一个循环(图像1)
当前向量 qs = [0.1, 0.2, 0.3],当前 ID = 101。
在 FAISS 索引中查找与 qs 距离小于 0.5 的所有向量,最终输出输出 {102, 104} 表示图像 2 和图像 4 是重复项。
同时,SD 3还对基于SSCD的去重方法的效果进行了评估,比较去重前后AI绘画大模型的过拟合情况。具体策略如下所示:

总的来说,使用SSCD方法去除重复样本能够有效减少模型的过拟合现象。去重后训练的模型显著减少了潜在的记忆化样本,为扩散模型的安全性和数据隐私提供了重要保障。
在上述的数据预处理完成后,官方筛选出了1B+的数据供SD 3训练优化。SD 3首先在1B数据上进行了预训练,然后再用30M专注于特定视觉内容和风格的高质量美学数据进行微调,最后使用3M偏好数据进行精细化训练。
4.2 图像数据集的Caption标签精细化
SD 3借鉴了DALL-E 3的数据标注方法,使用多模态大模型CogVLM对训练数据集中进行标注,生成高质量的精细化Caption标签。
目前来说,DALL-E 3的数据标注方法已经成为AI绘画领域的主流标注方法,很多SOTA性能的AI绘画大模型都使用了这套标签精细化的方法。
有读者可能会问,DALL-E 3的数据标注方法具体是什么样的呢?
Don‘t Worry,Rocky下面就详细讲解一下DALL-E 3的数据标注工作流程,让大家有更深刻的理解。
DALL-E 3开源的技术报告题目直接就是 《Improving Image Generation with Better Captions》,可见OpenAI对数据质量与标注质量非常重视。
目前AI绘画大模型存在一个很大的问题是模型的文本理解能力(Prompt Following)不强,主要是指AI绘画大模型生成的图像和输入文本Prompt的一致性不高。举个例子,如果说输入的文本Prompt非常精细复杂,那么生成的图像内容可能会缺失这些精细的信息,导致图像与文本的内容不一致。
产生这个问题归根结底还是由训练数据集本身所造成的,更本质说就是图像的Caption标注太过粗糙。
这里总共有两个方面的原因。第一个原因就是图像数据集自带的常规文本Caption标签一般很简单(比如COCO数据集),它们大部分只描述图像中的主体内容而缺失了背景、主体位置、主体数量、图像中的文字等很多重要信息。第二个原因就是当前训练AI绘画大模型的主流图像文本对数据集(LAION数据集等)都是从网页上直接爬取的,其中文本Caption标签其实就是简单的Alt Text信息,并且会包含很多不太相关的文本信息,导致引入了太多的无关噪声。这两个原因导致了AI绘画大模型的训练数据集中的Caption标签粗糙且不准确,而数据是决定AIGC模型性能上限的关键,自然也导致训练的模型无法充分学习到文本和图像的对应关系,就产生了我们刚才说的Prompt Following能力不足的问题。
所以我们需要优化训练数据集的Caption标签,来提升的AI绘画大模型的Prompt Following能力,让生成的图像和输入文本Prompt更加一致。
DALL-E 3是通过训练一个基于CoCa架构的Image Captioner模型来完善图像的Caption标签。CoCa模型相比CLIP模型额外增加了一个Multimodal Text Encoder结构来生成Caption,它训练的损失同时包含CLIP的对比损失和Captioning的交叉熵损失。因此CoCa也可以用于Caption标签的生成,CoCa模型的架构和训练过程如下图所示:

预训练好Image Captioner模型后,为了获得更加精细的Caption标签,DALL-E 3中对Image Captioner进行了进一步的微调训练,包括两个不同的数据集构建方案,具体如下所示:
- 第一个方案的微调数据集中只有描述图像主体的短Caption标签。
- 第二个方案的微调数据集中有详细描述图像内容的长Caption标签。
通过这两种方案,我们获得了两个不同的微调模型,分别具备生成短Caption(Short Synthetic Captions,SSC)标签和长Caption(Descriptive Synthetic Captions,DSC)标签的能力。下图中分别展示了三个图像的原始Alt Text标签、生成的短Caption标签和生成的长Caption标签。我们可以看到原始Alt Text标质量很差,而生成的短Caption标签能够简洁地描述图像的主体内容,同时生成的长Caption标签则能详细的描述图像的主体内容与细节内容。

接下来DALL-E 3技术报告中主要实验了合成Caption标签(只用原始Caption,5%的原始Caption+95%的合成短Caption,5%的原始Caption+95%的合成长Caption)对AI绘画大模型性能的影响,以及训练过程中合成Caption标签和原始Caption标签的最佳混合比例。之所以要混合合成Caption和原始Caption,主要是为了防止AI绘画大模型过拟合到合成Caption的某些特定范式上,比如最常见的例子是合成的Caption往往以"a"和"an"开头。在训练过程中,在合成Caption中混入一些原始的Caption,相当于一种模型正则化操作。
完成上述的两个实验后,DALL-E 3技术报告中得出两个结论:
- 采用合成的长Caption对AI绘画大模型的Prompt Following能力是有比较大提升的。
- 采用95%的合成长Caption+5%的原始Caption作为最终的Caption标签,在此基础上训练得到的AI绘画大模型的图像生成效果是最好的。
上面的内容就是DALL-E 3的完整标签制作流程与训练策略,这也是其图像生成性能大幅提升的关键。
虽然采用95%的合成长Caption进行训练会大大提升AI绘画大模型的生成效果,但是也存在AI绘画大模型过拟合到长Caption上的问题,当我们输入常规的短Caption时,生成图像的效果可能会变差的情况。为了解决这个问题,OpenAI是用了GPT-4对用户输入的Caption进行“upsampling”操作,对输入的文本进行优化扩写。下图展示了用GPT-4对输入Prompt进行优化扩写的过程,这样不论用户输入什么样的Prompt,DALL-E 3都能生成质量较高的图像:

所以,DALL-E 3与GPT-4结合不仅仅是AIGC产品层面的创新,也是为了保证DALL-E 3的输入Prompt不偏离训练时的分布。
现在我们说回到SD 3,SD 3沿用了DALL-E 3的数据标注技术,只是将Image Captioner模型从CoCa替换成了CogVLM。同时在SD 3的训练过程中,是使用50%的原始Caption和50%的合成长Caption,就能够较好的提升SD 3模型的整体性能,具体结果如下表中所示:

4.3 图像特征和文本特征在训练前缓存
SD 3与之前的版本相比,整体的参数量级大幅增加,这无疑也增加了训练成本,所以官方的技术报告中也对SD 3训练时冻结(frozen)部分进行了分析,主要评估了VAE、CLIP-L、CLIP-G以及T5-XXL的显存占用(Mem)、推理耗时(FP)、存储成本(Storage)、训练成本(Delta),如下图所示,T5-XXL的整体成本是最大的:

为了减少训练过程中SD 3所需显存和特征处理耗时,SD 3设计了图像特征和文本特征的预计算策略:由于VAE、CLIP-L、CLIP-G、T5-XXL都是预训练好且在SD 3微调过程中权重被冻结的结构,所以在训练前可以将整个数据集预计算一次图像的Latent特征和文本的Text Embeddings,并将这些特征缓存下来,这样在整个SD 3的训练过程中就无需再次计算。同时上述冻结的模型参数也无需加载到显卡中,可以节省约20GB的显存占用。
但是根据机器学习领域经典的“没有免费的午餐”定理,预计算策略虽然为我们大幅减少了SD 3的训练成本,但是也存在其他方面的代价。第一点是训练数据不能在训练过程中做数据增强了,所有的数据增强操作都要在训练前预处理好。第二点是预处理好的图像特征和文本特征需要一定的存储空间。第三点是训练时加载这些预处理好的特征需要一定的时间。
整体上看,其实SD 3的预计算策略是一个空间换时间的技术。
4.4 使用Classifier-Free Guidance技术
Classifier-Free Guidance技术可以说是AI绘画领域必不可少的一环了,从AIGC元年开始的Stable Diffusion 1.x系列,到现在的Stable Diffusion 3和FLUX.1系列模型,都用到了Classifier-Free Guidance技术对扩散模型进行训练优化。
我们想要了解Classifier-Free Guidance,那首先要从Classifier Guidance讲起。
Classifier Guidance技术是由OpenAI在2021年首次提出,其思想是让扩散模型可以按照指定的类别生成图像。我们可以使用贝叶斯定理对条件生成概率进行分解,从下式中可以看出Classifier Guidance的条件生成只需要添加一个额外的Classifier梯度即可:
∇ x t log p ( x t ∣ y ) = ∇ x t log ( p ( x t ) p ( y ∣ x t ) p ( y ) ) = ∇ x t log p ( x t ) + ∇ x t log p ( y ∣ x t ) − ∇ x t log p ( y ) = ∇ x t log p ( x t ) ⏟ unconditional score + ∇ x t log p ( y ∣ x t ) ⏟ classifier gradient (1) \begin{aligned} \nabla_{x_t} \log p\left(\boldsymbol{x}_t \mid y\right) & =\nabla_{x_t} \log \left(\frac{p\left(\boldsymbol{x}_t\right) p\left(y \mid \boldsymbol{x}_t\right)}{p(y)}\right) \\ & =\nabla_{x_t} \log p\left(\boldsymbol{x}_t\right)+\nabla_{x_t} \log p\left(y \mid \boldsymbol{x}_t\right)-\nabla_{x_t} \log p(y) \\ & =\underbrace{\nabla_{x_t} \log p\left(\boldsymbol{x}_t\right)}_{\text {unconditional score }}+\underbrace{\nabla_{x_t} \log p\left(y \mid \boldsymbol{x}_t\right)}_{\text {classifier gradient }} \end{aligned} \tag1 ∇xtlogp(xt∣y)=∇xtlog(p(y)p(xt)p(y∣xt))=∇xtlogp(xt)+∇xtlogp(y∣xt)−∇xtlogp(y)=unconditional score ∇xtlogp(xt)+classifier gradient ∇xtlogp(y∣xt)(1)
接着我们可以添加一个权重项 λ \lambda λ来灵活的控制unconditional score和classifier gradient两者的权重:
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + λ ∇ x t log p ( y ∣ x t ) (2) \nabla_{x_t} \log p\left(\boldsymbol{x}_t \mid y\right) = \nabla_{x_t} \log p\left(\boldsymbol{x}_t\right) \tag2 + \lambda\nabla_{x_t} \log p\left(y \mid \boldsymbol{x}_t\right) ∇xtlogp(xt∣y)=∇xtlogp(xt)+λ∇xtlogp(y∣xt)(2)
我们已经知道使用Classifer Guidance技术需要训练Classifier梯度项,这相当于要额外训练一个根据噪声得到类别标签的分类器,同时这个分类器的梯度反馈到了整体的生成梯度上,无疑会对模型的生成效果产生一定程度的干扰影响。
为了解决这个问题,Google提出了Classifier-Free Guidance技术。Classifier-Free guidance的核心思想是通过一个隐式分类器来代替显式分类器,使得生成过程不再依赖这个显式的分类器,从而解决了Classifier Guidance中出现的梯度干扰问题。具体来讲,我们对式(1)进行移项,可得:
∇ x t log p ( y ∣ x t ) = ∇ x t log p ( x t ∣ y ) − ∇ x t log p ( x t ) (3) \nabla_{x_t} \log p\left(y \mid \boldsymbol{x}_t\right) = \nabla_{x_t} \log p\left(\boldsymbol{x}_t \mid y\right) - \nabla_{x_t} \log p\left(\boldsymbol{x}_t\right) \tag3 ∇xtlogp(y∣xt)=∇xtlogp(xt∣y)−∇xtlogp(xt)(3)
接着将式(3)代入到式(2)中,我们有
∇ x t log p ( x t ∣ y ) = ∇ x t log p ( x t ) + λ ( ∇ x t log p ( x t ∣ y ) − ∇ x t log p ( x t ) ) = ∇ x t log p ( x t ) + λ ∇ x t log p ( x t ∣ y ) − λ ∇ x t log p ( x t ) = λ ∇ x t log p ( x t ∣ y ) ⏟ conditional score + ( 1 − λ ) ∇ x t log p ( x t ) ⏟ unconditional score (4) \begin{aligned} \nabla_{x_t} \log p\left(x_t \mid y\right) & =\nabla_{x_t} \log p\left(x_t\right)+\lambda\left(\nabla_{x_t} \log p\left(x_t \mid y\right)-\nabla_{x_t} \log p\left(x_t\right)\right) \\ & =\nabla_{x_t} \log p\left(x_t\right)+\lambda \nabla_{x_t} \log p\left(x_t \mid y\right)-\lambda \nabla_{x_t} \log p\left(x_t\right) \\ & =\underbrace{\lambda \nabla_{x_t} \log p\left(x_t \mid y\right)}_{\text {conditional score }}+\underbrace{(1-\lambda) \nabla_{x_t} \log p\left(x_t\right)}_{\text {unconditional score }} \end{aligned} \tag4 ∇xtlogp(xt∣y)=∇xtlogp(xt)+λ(∇xtlogp(xt∣y)−∇xtlogp(xt))=∇xtlogp(xt)+λ∇xtlogp(xt∣y)−λ∇xtlogp(xt)=conditional score λ∇xtlogp(xt∣y)+unconditional score (1−λ)∇xtlogp(xt)(4)
根据式(4),我们可以得到分类器由conditional score和unconditional score两部分组成。在训练时,我们就可以通过对标签进行Dropout来将标签以一定概率置空,从而巧妙实现了条件和无条件两种情况在同一个模型中的训练。
同样的,SD 3在训练过程中通过对输入文本进行一定程度的dropout来实现Classifier-Free Guidance,SD 3的三个Text Encoder各以46.4%的比例单独dropout,这意味着输入文本完全dropout的比例为 ( 46.4 % ) 3 ≈ 10 % (46.4\%)^3\approx10\% (46.4%)3≈10%。
三个Text Encoder独立进行dropout可以增加模型的泛化性能,这样当我们使用SD 3进行推理时就可以灵活的使用三个Text Encoder。比如说,当我们的计算资源有限时,我们可以不加载最大的T5-XXL模型,从而只保留两个CLIP Text Encoder模型。官方论文中也进行了实验,发现并不会影响在文本提示词高度详细的场景中的视觉美感(没有T5-XXL的胜率为50%),不过会导致文本一致性的略微下降(胜率为46%)。不过如果想要进行高质量的文字渲染,还是需要加上T5-XXL模型的,因为在不加载T5-XXL时的胜率只有38%。
4.5 使用DPO(Direct Preference Optimization)技术
DPO(Direct Preference Optimization)技术最初应用在NLP领域,主要是使用偏好数据对大语言模型(LLMs)进行微调来获得更好的性能。现在在AI绘画领域,DPO技术也可以用来对AI绘画模型进行偏好的微调训练了。
与SDXL使用的RLHF技术(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)相比,DPO技术的优势是无需单独训练一个Reward模型,而是直接基于成对的比较数据进行微调训练。具体来说,我们首先收集人类偏好数据(固定提示词生成的图片中选出人类最喜欢的那个);然后设计一个损失函数,使模型倾向于生成更符合人类偏好的输出。通过最小化这个损失函数,直接微调模型参数。DPO避免了强化学习中的试错过程,训练更稳定,效率更高,适用于AI绘画等有大量人类偏好数据的场景。与其说DPO是一种技术,倒不如说是一种训练思想。
官方报告中验证了DPO技术能够有效地根据人类偏好对SD 3模型进行进一步调优,SD 3并没有直接微调整个网络参数,而是引入了Rank=128的LoRA权重在20亿和80亿参数的SD 3模型上进行了4000次和2000次迭代的微调。
经过DPO技术的微调后,SD 3的图像生成质量有一定的提升,特别是文字渲染方面的能力更强了。具体效果对比如下所示:

4.6 使用QK-Normalization
随着SD 3模型的参数量持续增大,官方发现在进行高分辨率图像训练时,Attention层的attention-logit(Q和K的矩阵乘)会变得不稳定,导致训练会跑飞,梯度出现NaN的情况。为了提升SD 3在混合精度训练时的稳定性,在MM-DiT的Self-Attention层使用RMSNorm对Q-Embeddings和K-Embeddings进行归一化,也就是论文里说的QK-Normalization。

接下来Rocky为大家详细介绍一下RMSNorm(Root Mean Square Layer Normalization)。RMSNorm是一种在传统深度学习时代常用的归一化方法,对AI模型的参数激活值进行归一化,以提高训练的稳定性和收敛速度。
RMSNorm主要是基于Layer Normalization的一种改进方法,它通过计算参数激活值的均方根(RMS)进行归一化,而不是像Layer Normalization那样计算均值和方差。
假设输入向量为 x x x,其维度为 d d d。RMSNorm 的计算步骤如下:
- 计算均方根值(RMS):
RMS ( x ) = 1 d ∑ i = 1 d x i 2 \text{RMS}(x) = \sqrt{\frac{1}{d} \sum_{i=1}^{d} x_i^2} RMS(x)=d1i=1∑dxi2
- 对参数进行归一化:
x ^ = x RMS ( x ) \hat{x} = \frac{x}{\text{RMS}(x)} x^=RMS(x)x
- 缩放和平移:
y = γ x ^ + β y = \gamma \hat{x} + \beta y=γx^+β
其中, γ \gamma γ和 β \beta β\分别是缩放和平移参数,与Batch Normalization和Layer Normalization类似,这两个参数是可学习的,在SD 3的训练过程中逐步优化更新。
总体来说,使用RMSNorm作为正则化项有如下优势:
-
计算效率高:RMSNorm 仅需计算均方根值,而不需要计算均值和方差,计算量相对较小。
-
适用于小批量或单样本:与Batch Normalization不同,RMSNorm不依赖于批量大小,因此在小批量或单样本情况下表现良好。
-
稳定性:通过均方根值进行归一化,可以在一定程度上避免梯度爆炸和梯度消失问题,提高训练稳定性。
下面是RMSNorm在PyTorch中的简单实现示例:
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-8):
super(RMSNorm, self).__init__()
self.normalized_shape = normalized_shape
self.eps = eps
self.scale = nn.Parameter(torch.ones(normalized_shape))
self.shift = nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x):
rms = torch.sqrt(torch.mean(x ** 2, dim=-1, keepdim=True) + self.eps)
x_norm = x / rms
return self.scale * x_norm + self.shift
# 示例用法
input_tensor = torch.randn(3, 5) # 假设输入维度为 (batch_size, feature_dim)
rms_norm = RMSNorm(normalized_shape=input_tensor.size(-1))
output_tensor = rms_norm(input_tensor)
print(output_tensor)
4.7 设计多尺度位置编码
SD 3先在256x256分辨率的数据上进行预训练,接着在1024x1024分辨率的数据上进行多尺寸的微调,所以需要MM-DiT架构对应的位置编码也设计成多尺寸的。否则在256x256分辨率上确定的位置编码在其他分辨率上就不能适用,并会造成编码混乱。
为了能够适应多尺寸的位置编码,SD 3的MM-DiT借鉴了ViT(vision transformer)的2D Frequency Embeddings(两个1D Frequency Embeddings进行concat操作),并在此基础上进行了插值+扩展的策略。
假设目标分辨率的像素量为 S 2 S^2 S2,SD 3中也使用了数据分桶(bucketed sampling)训练的策略,数据集中各个尺寸的图像满足 H × W ≈ S 2 H\times W\approx S^2 H×W≈S2(比如2048x2048、1024x4096、4096x1024等),同时设定图像的宽和高最大分别为 H max H_{\text {max}} Hmax和 W max W_{\text {max}} Wmax。因为SD 3 的VAE会进行8倍的下采样,同时设置Patch Size为2会带来2倍的下采样,所以输入到SD 3的MM-DiT架构中的patches尺寸进行了16倍下采样,最大值有 h max = H max / 16 , w max = W max / 16 , s = S / 16 h_{\text{max}}=H_{\text{max}}/16,w_{\text{max}}=W_{\text{max}}/16, s=S/16 hmax=Hmax/16,wmax=Wmax/16,s=S/16。
SD 3的预训练阶段是在256x256分辨率下进行位置编码的,我们可以先通过插值的方式将位置编码应用到 S × S S\times S S×S尺度上,此时相当于位置 p p p处的网格值为 p ⋅ 256 S p\cdot\frac{256}{S} p⋅S256。进一步地,我们可以将其扩展支持最大的宽和高,以高为例子,这里有 ( p − h max − s 2 ) ⋅ 256 S (p-\frac{h_{\text{max}}-s}{2})\cdot\frac{256}{S} (p−2hmax−s)⋅S256。对于不同的尺寸,我们只需要CenterCrop出对应的2D网格进行Embedding得到位置编码。
4.8 TimeStep Schedule中shift参数作用
在AI绘画大模型的训练过程中,如果对高分辨率的图像采用和低分辨率图像一样的noise schedule,会出现对图像的加噪破坏不充分的情况,如下图所示:

DDPM架构的扩撒模型采用对noise schedule进行偏移的方法来进行解决,对于SD 3这个基于RF的扩散模型来说,则是设计了TimeStep Schedule的shift策略。
假设我们当前的图像分辨率为 n = H × W n = H \times W n=H×W,同时是一个“常量图像”,即每个像素的值都相等,记为 c c c。根据SD 3的RF采样过程,我们可以得到噪声的加入方式如下:
$$z_t = (1 - t) c \mathbf{1} + t \epsilon \$$
这里 1 ∈ R n \mathbf{1} \in \mathbb{R}^n 1∈Rn是一个所有分量都为1的向量, ϵ ∈ R n \epsilon \in \mathbb{R}^n ϵ∈Rn是噪声向量,它的每个分量都是服从标准正态分布的独立随机变量。
在此基础上,产生 n n n个观察变量:
Y = ( 1 − t ) c + t η Y = (1 - t) c + t \eta Y=(1−t)c+tη
其中 η \eta η是标准正态分布的随机变量,即均值为 0,方差为 1。
根据上述公式,我们还可以计算得到随机变量 Y Y Y的均值:
E ( Y ) = ( 1 − t ) c \mathbb{E}(Y) = (1 - t) c E(Y)=(1−t)c
和标准差:
σ ( Y ) = t \sigma(Y) = t σ(Y)=t
根据观测值 z t z_t zt我们能够估计原始的图像常量 c c c。我们可以用以下公式来估计 c c c:
c ^ = 1 1 − t E ( Y ) = 1 1 − t 1 n ∑ i = 1 n z t , i \hat{c}= \frac{1}{1 - t} \mathbb{E}(Y)=\frac{1}{1-t}\frac{1}{n}\sum_{i=1}^{n}z_{t,i} c^=1−t1E(Y)=1−t1n1i=1∑nzt,i
而标准差(偏差)则为:
σ ( t , n ) = t 1 − t 1 n \sigma(t, n) = \frac{t}{1 - t} \sqrt{\frac{1}{n}} σ(t,n)=1−ttn1
这里的标准差可以看成噪声对 c c c的破坏程度,上述公式意味着随着像素数量 n n n增加,噪声的影响会减少,特别是当图像的宽度和高度同时增加时,破坏程度会持降低。
为了保证不同分辨率下的噪声破坏效果一致,我们引入了一个新的时间步
t
m
t_m
tm,用于分辨率为
m
m
m的图像。我们想要让分辨率
n
n
n下的
σ
(
t
n
,
n
)
\sigma(t_n,n)
σ(tn,n)和分辨率
m
m
m下的
σ
(
t
m
,
m
)
\sigma(t_m,m)
σ(tm,m)
相同,我们可以得到以下关系式:
σ ( t n , n ) = σ ( t m , m ) → t m = m n t n 1 + ( m n − 1 ) t n \sigma(t_n, n) = \sigma(t_m, m) \rightarrow t_m = \frac{\sqrt{\frac{m}{n}} t_n}{1 + \left( \sqrt{\frac{m}{n}} - 1 \right) t_n} σ(tn,n)=σ(tm,m)→tm=1+(nm−1)tnnmtn
这个公式意味着,当图像分辨率变化时,时间步 t m t_m tm需要根据分辨率的比率$ \sqrt{\frac{m}{n}}$来进行缩放。
接下来,我们可以进一步计算出信噪比(SNR):
λ m = 2 log ( 1 − t m t m ) = λ n − log m n \lambda_m = 2 \log \left( \frac{1 - t_m}{t_m} \right) = \lambda_n - \log \frac{m}{n} λm=2log(tm1−tm)=λn−lognm
这意味着随着图像分辨率从
n
n
n变化到
m
m
m,信噪比要偏移一个
log
m
n
\log\frac{m}{n}
lognm。

在AI绘画大模型的实际训练中,当图像分辨率变化时,选择一个常数比例值 α = m n \alpha = \sqrt{\frac{m}{n}} α=nm可以得到良好的噪声调度。SD 3论文中的实验结果表明,当分辨率调整为 1024 × 1024 1024 \times 1024 1024×1024时,最优值为 3.0。
4.9 基于DiT架构AI绘画大模型的Scaling能力
基于Transformer架构与基于U-Net(CNN)架构相比,一个较大的优势是具备很强的Scaling能力,通过增加模型参数量、训练数据量以及计算资源可以稳定的提升AI绘画大模型的生成能力和泛化性能。SD 3论文中也选择了不同参数规模(设置网络深度为15、18、21、30、38,当网络深度为38时,也就是SD 3的8B参数量模型)的MM-DiT架构进行实验。
经过实验后,整体上的结论是MM-DiT架构表现出了比较好的Scaling能力,当模型参数量持续增加时,模型性能稳步提升,具体实验结果如下图所示:

同时在实验中也发现,如果使用网络深度为38的MM-DiT架构,在模型训练到 3 × 1 0 5 3 × 10^5 3×105 步时必须调整学习率以防止训练的发散。这表明,随着模型规模的扩大,超参数(如学习率)的选择变得更加关键,需要更加细致地调整以确保稳定的训练。
当模型参数量持续增加时,验证损失(Validation Loss)呈现出平滑下降的趋势。验证损失的降低表明模型在验证集上的表现越来越好,这通常意味着模型在未见过的数据上具有更好的泛化能力。
验证损失(Validation Loss)与T2I-CompBench、GenEval、人类视觉偏好等评价指标都有很强的相关性,也可以很好地衡量模型的整体性能。
同时从实验结果也可以看到,以目前的参数量级来说,还没有出现模型性能饱和的情况,说明如果继续增大模型参数量,模型性能可能继续提升,而这个结论也在后续发布的FLUX.1模型中得到了印证。
下图展示了三个不同大小的SD 3模型生成图像的差异,可以看到提升参数量确实能够提升图像生成质量。

同时参数量更大的模型不仅性能更好,而且在生成时可以用较少的采样步数获得相同的性能:

总的来说,SD 3论文中的整个实验过程也完全证明了Scaling Law在AI绘画领域依旧成立,特别是在基于DiT架构的AI绘画大模型上。Rocky判断未来在工业界、学术界、应用界以及竞赛界,AI绘画领域的Scaling Law的价值会持续凸显与放大。
5. 深入浅出完整解析FLUX.1系列模型核心基础知识
就在2024年2月份Stability AI发布Stable Diffusion 3后不久,就曝出Stable Diffusion系列模型的核心研究团队集体离职的消息,一时间AIGC领域为之震动。
在2024年8月1号,由Stable Diffusion系列模型核心团队重新组建的Black Forest Labs(黑森林实验室)带着迄今为止最大的开源文生图大模型FLUX.1王者归来。FLUX.1一共有12B(120亿)的参数量,具备强劲的图像生成能力。FLUX.1一开源就获得了AI绘画开源社区的广泛好评,围绕着FLUX.1系列模型的开源生态迅速构建,强力助推AIGC时代的AI绘画领域持续繁荣!
FLUX.1系列模型基于Stable Diffusion 3架构上进行了优化升级,可以说是“Stable Diffusion 4”也不为过,也标志着AI绘画领域全面进入了Transformer时代。
目前FLUX.1的技术报告暂时还没有发布,Rocky也会持续关注,持续更新解读FLUX.1的技术细节。

5.1 FLUX.1系列模型初识(包含详细图解)
当前FLUX.1系列一共包含了三个变体模型:
- FLUX.1-pro:FLUX.1系列的最强模型,只能通过API和官方平台在线使用。
- FLUX.1-dev:在FLUX.1-pro基础上进行指引蒸馏(guidance-distilled) 后的模型,图像生成的质量与文本一致性与FLUX.1 -pro非常接近,同时推理效率比FLUX.1 -pro更高。
- FLUX.1-schnell:为个人开发者和应用者发布的本系列推理速度最快的模型。FLUX.1-schnell是基于指引蒸馏(guidance-distilled)和时间步蒸馏(TimeStep-distilled) 双重蒸馏后的模型,仅需1-4步就可以能完成图像的生成过程,代价是无法设置图像生成过程的Classifier-Free Guidance强度。

指引蒸馏(guidance-distilled)的目标是让AI绘画模型直接学习 Classifier-Free Guidance (CFG) 的生成结果,使得AI绘画模型一次输出之前要运行两次才能得到的指引生成结果,从而能够节约近一半的推理耗时。时间步蒸馏(TimeStep-distilled)通过加速蒸馏手段,在FLUX-pro基础上蒸馏得到的模型,从而能在极少的采样步数(1-4步)里完成图像的生成过程。
FLUX.1系列模型的三个版本对比如下所示:

从上图可以看到,FLUX.1-pro版本是生成能力最强的一个版本,同时所需的成本(包括计算资源、运行时间等)也最高。
FLUX.1系列的扩散模型部分是基于Stable Diffusion 3的MM-DiT架构和自主设计的Single-DiT架构进行组合,参数量直接scale up至120亿,可以说在模型工程上进行了大大阔斧的改进。同时FLUX.1和Stable Diffusion 3一样,也是根据Rectified Flow采样进行推导的扩散模型。
目前官方开源的FLUX.1-dev/Schnell两个版本,在FP16精度下模型大小为34G,其中FP16精度下扩散模型大小为23.8G(参数量约12B,FP8:16.8G),VAE模型大小为168M(参数量约80M),CLIP ViT-L大小为246M(参数量约124M),T5-XXL Encoder在FP16精度下大小为9.79G(参数量约4.7B,FP8精度下大小为4.89G)
除此之外,FLUX.1系列模型还引入了NLP领域经典的旋转式位置编码 (RoPE) 技术和并行注意力机制等技术,来提升图像生成的整体性能与效率。
下面是FLUX.1系列模型的完整网络架构示意图:

接下来,Rocky将带着大家详细解析FLUX.1在Stable Diffusion 3的基础上做了哪些优化,看看FLUX.1有哪些独有的设计理念与深邃的技术思考。
5.2 FLUX.1系列模型的VAE结构(包含详细图解)
在3.2章节中,Rocky已经为大家详细讲解了Stable Diffusion 3 VAE的核心知识,SD 3模型通过提升VAE架构的通道数(16)来增强VAE的重建能力,进而提高重建后的图像整体质量。
FLUX.1系列中,FLUX.1 VAE架构依然继承了SD 3 VAE的8倍下采样和输入通道数(16)。在FLUX.1 VAE输出Latent特征,并在Latent特征输入扩散模型前,还进行了Pack_Latents操作,一下子将Latent特征通道数提高到64(16 -> 64),换句话说,FLUX.1系列的扩散模型部分输入通道数为64,是SD 3的四倍。这也代表FLUX.1要学习拟合的内容比起SD 3也增加了4倍,所以官方大幅增加FLUX.1模型的参数量级来提升模型容量(model capacity)。下面是Pack_Latents操作的详细代码,让大家能够更好的了解其中的含义:
@staticmethod
def _pack_latents(latents, batch_size, num_channels_latents, height, width):
latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2)
latents = latents.permute(0, 2, 4, 1, 3, 5)
latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4)
return latents
可以看到FLUX.1模型的Latent特征Patch化方法是将 2 × 2 2\times 2 2×2像素块直接在通道维度上堆叠。这种做法保留了每个像素块的原始分辨率,只是将它们从空间维度移动到了通道维度。与之相对应的,SD 3使用下采样卷积来实现Latent特征Patch化,但这种方式会通过卷积减少空间分辨率从而损失一定的特征信息。
Rocky再举一个形象的例子来解释SD 3和FLUX.1的Patch化方法的不同:
-
SD 3(下采样卷积):想象我们有一个大蛋糕,SD 3的方法就像用一个方形模具,从蛋糕上切出一个
的小方块。在这个过程中,我们提取了蛋糕的部分信息,但是由于进行了压缩,Patch块的大小变小了,信息会有所丢失。 -
FLUX.1(通道堆叠):FLUX.1 的方法更像是直接把蛋糕的
块堆叠起来,不进行任何压缩或者切割。我们仍然保留了蛋糕的所有部分,但是它们不再分布在平面上,而是被一层层堆叠起来,像是三明治的层次。这样一来,蛋糕块的大小没有改变,只是它们的空间位置被重新组织了。
总的来说,相比SD 3,FLUX.1将 2 × 2 2\times 2 2×2特征Patch化操作应用于扩散模型之前。这也表明FLUX.1系列模型认可了SD 3做出的贡献,并进行了继承与优化。
目前发布的FLUX.1-dev和FLUX.1-schnell两个版本的VAE结构是完全一致的。同时与SD 3相比,FLUX.1 VAE并不是直接沿用SD 3的VAE,而是基于相同结构进行了重新训练,两者的参数权重是不一样的。并且SD 3和FLUX.1的VAE会对编码后的Latent特征做平移和缩放,而之前的SD系列中VAE仅做缩放:
def encode(self, x: Tensor) -> Tensor:
z = self.reg(self.encoder(x))
z = self.scale_factor * (z - self.shift_factor)
return z
平移和缩放操作能将Latent特征分布的均值和方差归一化到0和1,和扩散过程加的高斯噪声在同一范围内,更加严谨和合理。
下面是Rocky梳理的FLUX.1-dev/schnell系列模型的VAE完整结构图,希望能让大家对这个从SD系列到FLUX.1系列都持续繁荣的模型有一个更直观的认识,在学习时也更加的得心应手:

FLUX.1 VAE架构和SD 3 VAE架构一致,关于VAE模型架构的细节拆解与分析,大家可以回看本文3.2章节中的内容。
接下来,我们分别使用SDXL、SD 3、FLUX.1系列模型进行1024x1024分辨率和2048x2048分辨率图像的压缩和重建,重建效果如下所示:

我们可以看到SDXL VAE在压缩和重建过程中出现图像内容和文本的畸变,而SD 3 VAE和FLUX.1 VAE基本看不到明显的重建畸变。
Rocky认为Stable Diffusion系列和FLUX.1系列中VAE模型的改进历程,为工业界、学术界、竞赛界以及应用界都带来了很多灵感,有很好的借鉴价值。Rocky也相信AI绘画中针对VAE的优化是学术界一个非常重要的论文录用点!
5.3 FLUX.1系列模型的MM-Single-DiT结构(包含详细图解)
FLUX.1的Transformer模型部分在SD 3的基础上进一步优化,除了和SD 3一样有MM-DiT模块(双流DiT)外,同时还设计了Single-DiT模块(单流DiT)。在单流DiT Block模块中,文本信息和图像信息拼接融合在一起,再送入Attention机制中处理(经典DiT Block架构)。同时在额外条件部分会输入完整的Text Embeddings和池化过的Pooled Text Embeddings。
直观的理解,先使用MM-DiT block实现两个模态信息融合,然后再接Single-DiT Block加深模型深度,增强模型的整体学习能力的同时,还可以节省一些参数。可以说Black Forest Labs在模型架构工程上下了不少功夫。
下图是Rocky梳理的FLUX.1-dev/schnell系列模型MM-Single-DiT的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习FLUX.1-dev/schnell系列模型MM-Single-DiT部分,相信大家脑海中的思路也会更加清晰:

可以看到,FLUX.1系列中MM-Single-DiT架构包含了19层MM-DiT Block结构和38层Single-DiT Block结构。除此之外,Rocky再对MM-Single-DiT架构的核心组建进行介绍:
- MM-DiT Block:由两个AdaLayerNormZero层+一个MM-DiT Attention Structure模块+两个LayerNorm层+两个FeedForward层组成。
- Single-DiT Block:由一个AdaLayerNormZero层+一个Single-DiT Attention Structure(DiT Attention)模块+两个Linear层+一个GELU激活函数组成。
- MM-DiT Attention Structure:FLUX.1的MM-DiT Block中的核心组件,和SD 3一样,将文本信息和图像信息以同等重要的级别进行Attention机制。
- Single-DiT Attention Structure:FLUX.1的Single-DiT Block中的核心组件,将文本信息和图像信息的特征融合后,进行经典的DiT-Attention机制。
- FeedForward:由GELU激活函数+Dropout层+Linear层组成。
和SD 3一样, FLUX.1系列模型将得到的Patch Embedding与Positional Embedding相加(add)一起输入到Transformer的主架构中。 同时通过adaLN-Zero层将文本特征CLIP pooled embedding(全局语义信息)和Timestep Embedding加(add)在一起的融合特征作为额外条件注入到Transformer Block中。
除此之外,FLUX.1的Transformer架构中还引入了并行注意力机制(parallel Attention-MLP Blocks),主要是在Single-DiT(单流DiT)部分使用,进一步优化模型整体的性能。具体的优化方式如下所示:

可以看到,并行注意力机制把注意力和线性层之间的串联结构转变成并联结构。常规注意力机制需要在计算注意力的前后各经过一次线性层的特征提取,在转换成并联结构后,注意力在计算完成后与MLP进行了add操作,将特征融合。这样一来,整体的计算并行度更高,AI绘画模型的运行效率也随之提升了。
除了整体模型结构与SD 3相比有优化外,在位置编码上FLUX.1也有自己的改进。SD 3中采用的是2d frequency embeddings,这是经典的绝对位置编码方式。FLUX.1这次采用了大模型领域中常用的旋转式位置编码rotary positional embedding(RoPE),RoPE是直接作用在Attention机制上的相对位置编码方式。
我们知道Transformer架构中只包含注意力和全连接两种经典计算方式,这两种计算都是和位置信息无关的。为了让Transformer知道图像像素间的空间对应关系,我们就需要给Transformer中的token注入额外的位置信息。
经典的正弦编码方式虽然能表示一定的相对位置信息,但是经过了注意力机制后,其中的相对位置信息几乎就丢失了。而旋转位置编码使用二维向量来表示每个token的二维位置编码,在经过注意力机制的计算后,结果里恰好会出现相对位置关系。从而让注意力机制的计算过程也能知道token间的相对位置关系。
总的来说,RoPE使用旋转变换,使得每个位置的Token保留了相邻位置的相对关系。相比传统的绝对位置编码,RoPE更注重局部关系的建模。这种增强的局部敏感性有助于AI绘画大模型捕获图像局部区域之间的细节关联,从而提升模型的生成质量和泛化性能。
在FLUX.1中,具体的操作是将文本的位置编号设为(0, 0, 0),图像的位置编号设为(0, i, j),之后用标准的旋转式位置编码对三个维度的编号编码,再把三组编码拼接。具体例子如下:
假设位于(i, j)的图像像素的位置编号是(0, i, j),经过特征编码,位置编号会转换成[16, 56, 56]维度的矩阵,表示第一个维度用长度 16 的位置编码,后两维用长度 56 的位置编码。再经RoPE函数计算得到旋转式位置编码后,会拼接到一起,最后形成 128维的位置编码。编码前16个通道是第一维位置编号的位置编码,后面两组56个通道分别是第二维、第三位位置编号的位置编码。这也表示在进行注意力运算时,特征的前16个通道不知道位置信息,中间56个通道知道垂直的位置信息,最后56个通道知道水平的位置信息。
Rocky认为第一个是纬度是为视频生成的time维度预留,也就是说后续Black Forest Labs很有可能发布AI视频大模型。
Rocky认为AI绘画大模型的持续发展开始带动AI视频大模型的更新迭代了,未来相信AI绘画和AI视频两个产业将会形成“你中有我,我中有你”的全新局面,为AIGC时代带来更大的价值。
5.4 FLUX.1系列模型的Text Encoder结构(包含详细图解)
在之前的章节中,Rocky已经详细讲解了Stable Diffusion 3的Text Encoder部分,一共使用了CLIP ViT-L、OpenCLIP ViT-bigG、T5-XXL Encoder三个Text Encoder模型。其中两个CLIP Encoder提取的Pooling Text Embeddings特征拼接在一起后与Time Embedding相加。同时再将两个CLIP Encoder的Text Embedding特征进行拼接,再在Token维度与T5-XXL的Text Embedding拼接后送入MM-DiT架构中。
FLUX.1在SD 3的基础上对Text Encoder部分进行了精简优化,只使用了CLIP ViT-L和T5-XXL Encoder两个Text Encoder模型,并没有使用OpenCLIP ViT-bigG模型。FLUX.1中将CLIP ViT-L的Pooling Text Embeddings特征与Time Embedding相加,同时T5-XXL提取的Text Embedding特征直接送入MM-DiT架构中。
总的来说,FLUX.1比起SD 3更依赖T5-XXL提取的文本特征信息,SD 3中CLIP Encoder的特征还有较大的作用,比如SD 3可以去掉T5-XXL只用CLIP Encoder提取文本特征信息来生成图像。
Rocky通过FLUX.1-dev和FLUX.1-schnell两个版本模型的对比,可以发现两者的Text Encoder部分结构是完全一致的。
下图是Rocky梳理的FLUX.1-dev/schnell系列模型 CLIP ViT-L Text Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习FLUX.1-dev/schnell系列模型的ViT-L CLIP Text Encoder部分,相信大家脑海中的思路也会更加清晰:

下图是Rocky梳理的FLUX.1-dev/schnell系列模型 T5-XXL Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习FLUX.1-dev/schnell系列模型的T5-XXL Text Encoder部分,相信大家脑海中的思路也会更加清晰:

码字确实不易,希望大家能多多点赞!!!
5.5 FLUX.1系列模型的官方训练技巧&细节解析
【1】使用time_shift值来平移Timestep
我们已经知道FLUX.1系列模型和SD 3模型一样使用了基于RF(Rectified Flow)采样方法来生成图像,FLUX.1也设置了一个time_shift值来平移Timestep。
在RF(Rectified Flow)采样方法中,图像沿着某条高维路线从纯高斯噪声运动到训练集分布中,同时标准差用于控制不同时刻图像的不确定性。
时刻为0时,图像为纯噪声,此时标准差为1; 等到了时刻为1时,图像趋近训练集中的图像分布,此时标准差要尽可能趋于0。原本对于中间时刻,标准差默认按照时刻线性变化。而FLUX.1中设置了time_shift是一个 0.5 ~ 1.16 之间的数,控制的是中间时刻的噪声均值。
如下图所示,当time_shift值越大时,运动线路逐渐上凸:

当输入的图像分辨率越大,对应的tokens越多时,time_shift越大,这时要加的噪声就越大。这也与SD 3中的shift策略一致,对于分辨率越高的图像,需要加更多噪声来摧毁原图像的分布特征。
【2】FLUX.1系列模型的多分辨率图像生成能力
FLUX.1系列模型能够对多种图像分辨率和图像长宽比进行灵活生成,能够适应0.1-2.0MP(Megapixels,百万像素)的图像生成任务。总的来说,图像像素数量越多,图像的分辨率越高,细节表现越丰富。
FLUX.1系列模型进行多分辨率与多长宽比图像生成的示例如下所示:

可以看到,FLUX.1确实能够很好的适配各种分辨率的图像生成,这主要得益于FLUX.1采用了多尺度训练+RoPE位置编码+动态time shift的组合策略。
【3】FLUX.1系列模型与其他主流AI绘画大模型的性能对比
官方使用ELO Score指标将FLUX.1系列模型与其他主流的AI绘画大模型进行了性能对比,毫无疑问FLUX-pro和FLUX-dev占据了前两名的位置。同时FLUX-schnell排在了第五位,前面两位分别是当前火爆的SD 3和Ideogram。

同时,官方还从多个评估维度上对包含FLUX.1系列模型在内的主流AI绘画大模型(SD 3、Ideogram、Midjourney V6、DALL-E 3、Auraflow V2等)的性能进行了全面的评估:

上图中左侧和右侧的雷达图分别展示了不同AI绘画大模型在五个关键评估维度上的表现,图中使用了不同的颜色和线条来代表不同的模型。其中五个关键评估维度分别是:
- Visual Quality(视觉质量):衡量AI绘画模型生成图像的整体视觉效果,包括细节、颜色、对比度和清晰度。
- Prompt Following(提示遵循度):评估AI绘画模型生成的图像内容与输入提示词一致性程度的能力。
- Size/Aspect Variability(尺寸/长宽比的多样性):衡量AI绘画模型生成不同尺寸和长宽比图像的能力和灵活性。
- Typography(排版):评估AI绘画模型在生成图像中正确渲染文本(如字体和排版)的能力。
- Output Diversity(输出多样性):衡量AI绘画模型生成的图像在风格和内容上的多样性。
从上图中可以看出,FLUX-pro和FLUX-dev模型在大部分评估维度上表现出色,远超其他AI绘画模型。尤其在视觉质量、提示遵循度和输出多样性方面。
FLUX-schnell模型是目前最先进的快速生成模型,不仅超越了同级别的AI绘画蒸馏模型,还优于一些非蒸馏模型,比如Midjourney v6.0 和 DALL·E 3。
同时Ideogram在排版这个评估维度上是目前最好的。
6. 从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画(全网最详细讲解)
6.1 Stable Diffusion 3模型权重不同版本介绍
目前StabilityAI官方已经开源的Stable Diffusion 3模型,整个开源目录结构如下所示:
├── comfy_example_workflows/
│ ├── sd3_medium_example_workflow_basic.json
│ ├── sd3_medium_example_workflow_multi_prompt.json
│ └── sd3_medium_example_workflow_upscaling.json
│
├── text_encoders/
│ ├── README.md
│ ├── clip_g.safetensors
│ ├── clip_l.safetensors
│ ├── t5xxl_fp16.safetensors
│ └── t5xxl_fp8_e4m3fn.safetensors
│
├── LICENSE
├── sd3_medium.safetensors
├── sd3_medium_incl_clips.safetensors
├── sd3_medium_incl_clips_t5xxlfp8.safetensors
└── sd3_medium_incl_clips_t5xxlfp16.safetensors
我们可以看到,完整的SD 3 medium一共有四个版本:
- sd3_medium.safetensors:只包括MM-DiT和VAE的权重,不包括任何文本编码器。
- sd3_medium_incl_clips.safetensors:包含除了T5-XXL之外的所有SD 3模型结构的权重。
- sd3_medium_incl_clips_t5xxlfp8.safetensors:包含SD 3 medium的所有结构,同时T5-XXL部分是fp8版本。
- sd3_medium_incl_clips_t5xxlfp16.safetensors:包含SD 3 medium的所有结构,同时T5-XXL部分是fp16版本。
同时我们可以看到Text Encoder部分有一个单独的文件夹,独立列出了SD 3所需的3个Text Encoder模型:
- clip_g.safetensors:代表OpenCLIP ViT-bigG模型的权重。
- clip_l.safetensors:代表CLIP ViT-L模型的权重。
- t5xxl_fp16.safetensors:代表T5-XXL模型fp16精度的权重。
- t5xxl_fp8_e4m3fn.safetensors:代表T5-XXL模型fp8精度的权重。
最后在comfy_example_workflows文件夹中包含了SD 3模型的三个ComfyUI工作流,方便我们直接在ComfyUI上搭建运行SD 3 medium模型:
- sd3_medium_example_workflow_basic.json
- sd3_medium_example_workflow_multi_prompt.json
- sd3_medium_example_workflow_upscaling.json

6.2 零基础使用diffusers搭建Stable Diffusion 3推理流程
每次SD系列技术在更新迭代时,diffusers库一般都是最先原生支持其功能的,这次也不例外。所以在diffusers中能够非常高效的构建Stable Diffusion 3的推理流程。但是由于diffusers目前没有现成的可视化界面,Rocky将在Jupyter Notebook中搭建完整的Stable Diffusion 3推理工作流,让大家能够快速的学习掌握。
Stable Diffusion 3官方的推理参数建议如下:
- 采样器:dpmpp 2m (不建议使用karras)
- Steps: 32
- CFG:设置4-6即可
目前Stable Diffusion 3模型已经可以在diffusers上搭建使用,其中文本生成图像的具体代码如下所示:
# 在diffusers中使用 SD3前先确保安装的diffusers是最新版本
pip install --upgrade diffusers
pip install transformers -U
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("/本地路径/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says WeThinkIn",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
image

除了文生图之外,我们还可以在diffusers中使用SD 3进行图像生图像任务,具体代码如下所示:
import torch
from diffusers import StableDiffusion3Img2ImgPipeline
from diffusers.utils import load_image
pipe = StableDiffusion3Img2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png")
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipe(prompt, image=init_image).images[0]
image

所以我们可以在ComfyUI上测试两个模型。去掉T5 XXL,模型推理(单张1024x1024图像)只需要7.5GB的显存,而加上T5 XXL后显存需要约17GB,这对GPU要求就高了不少。
6.3 零基础使用diffusers搭建FLUX.1推理流程

FLUX.1作为SD 3的正统续作,Diffusers也第一时间支持了其推理的Pipeline流程,不过FLUX.1的推理代码还在 Diffusers的在线主分支中持续完善,目前暂时未集成进pip版的Diffusers里。所以如果我们想要在Diffusers中使用FLUX.1,就需要从源码端安装最新Diffusers库,只需要在命令行输入以下命令即可:
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
pip install transformers[sentencepiece] datasets accelerate torch==2.0.1 torchvision==0.15.2 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
完成上面的依赖安装后,我们就可以使用Diffusers库搭建FLUX.1的推理流程了。
我们首先使用FLUX.1-dev版本进行推理流程:
import torch
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("/本地路径/FLUX.1-dev", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU power
prompt = "A cat holding a sign that says WeThinkIn"
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=3.5,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save("flux-dev-test.png")

从上图可以看到,FLUX.1-dev的图像生成效果非常不错,文字渲染的非常精美。
接下来,我们再使用FLUX.1-schnell版本进行推理流程:
import torch
from diffusers import FluxPipeline
pipe = FluxPipeline.from_pretrained("/本地路径/FLUX.1-schnell", torch_dtype=torch.bfloat16)
pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU power
prompt = "A cat holding a sign that says hello world"
image = pipe(
prompt,
guidance_scale=0.0,
num_inference_steps=4,
max_sequence_length=256,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save("flux-schnell-test.png")

从Rocky对两个版本的使用感受来看,FLUX.1-dev版本的效果稳定性与图形整体质量要高于FLUX.1-schnell。而FLUX.1-schnell则更加快速,适合对出图耗时要求较高的场景。
6.4 零基础使用ComfyUI搭建Stable Diffusion 3推理流程
6.5 零基础使用ComfyUI搭建FLUX.1推理流程
ComfyUI是一个基于节点式的Stable Diffusion AI绘画工具。和Stable Diffusion WebUI相比,ComfyUI通过将Stable Diffusion模型生成推理的pipeline拆分成独立的节点,实现了更加精准的工作流定制和清晰的可复现性。
目前ComfyUI能够非常成熟的使用Stable Diffusion 3和FLUX.1系列模型,下面是Rocky使用ComfyUI来加载Stable Diffusion 3和FLUX.1系列模型并生成图片的完整Pipeline:

话说回来,下面Rocky将带着大家一步一步使用ComfyUI搭建FLUX.1系列模型的推理流程,从而实现上图所示的生成过程。
首先,我们需要安装ComfyUI框架,这一步非常简单,在命令行输入如下代码即可:
git clone https://github.com/comfyanonymous/ComfyUI.git
安装好后,我们可以看到本地的ComfyUI文件夹。
ComfyUI框架安装到本地后,我们需要安装其依赖库,我们只需以下操作:
cd ComfyUI #进入下载好的ComfyUI文件夹中
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
完成这些配置工作后,我们就可以配置模型了,首先我们将FLUX.1系列的flux1-dev.safetensors和flux1-schnell.safetensors这两个版本的模型放到ComfyUI/models/unet/路径下。这样以来,等我们开启可视化界面后,就可以选择FLUX.1系列模型进行AI绘画了。
然后我们再把clip_l.safetensors、t5xxl_fp16.safetensors以及t5xxl_fp8_e4m3fn.safetensors三个Text Encode模型放到ComfyUI/models/clip/路径下,这样以来,我们就可以在使用FLUX.1系列模型时灵活的选用不同的Text Encode模型。
最后我们再把FLUX.1-dev和FLUX.1-schnell两个版本各自的ae.safetensors模型放到ComfyUI/models/vae/路径下,这样我们也能对VAE模型进行灵活的选型与使用。
接下来,我们就可以启动ComfyUI了!我们到ComfyUI/路径下,运行main.py即可:
python main.py --listen --port 8888
运行完成后,可以看到命令行中出现的log:
To see the GUI go to: http://0.0.0.0:8888
我们将http://0.0.0.0:8888输入到我们本地的网页中,即可打开如上图所示的ComfyUI可视化界面,愉快的使用FLUX.1系列模型生成我们想要的图片了。
接下来就是ComfyUI的节点式模块讲解了。
后续持续更新,大家敬请期待!
7. 从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型(全网最详细讲解)
我们能够看到目前AI绘画领域在Stable Diffusion 3(SD 3)和FLUX.1系列模型连续发布后迎来了全新的繁荣,图像生成性能的大幅提升让开源社区快速跟进,基于SD 3和FLUX.1的微调模型源源不断的发布。同时对应的SD 3 LoRA、FLUX.1 LoRA模型、SD 3 ControlNet以及FLUX.1 ControlNet模型也持续的发布更新,整个AI绘画领域的产业生态达到了新高峰。有了这些模型,我们就有更多的AI绘画工具去尝试实现我们的奇思妙想,这也是AI绘画领域能够跨周期繁荣的关键所在。
那么我们如何快速训练SD 3、FLUX.1、SD 3 LoRA和FLUX.1 LoRA模型呢?Don’t worry,Rocky详细梳理总结了从0到1的保姆级训练教程,方便大家快速上手入门与深入进阶。
7.1 Stable Diffusion 3和FLUX.1系列模型训练初识
Stable Diffusion 3(SD 3)和FLUX.1系列模型的训练流程主要分成以下步骤:
- 训练数据预处理: 数据采集、数据质量评估、行业标签梳理、数据清洗、数据标注、标签清洗、数据增强等。
- 训练资源配置: 底模型选择、算力资源配置、训练环境搭建、训练参数设置等。
- 模型微调训练: 运行SD 3模型、FLUX.1模型、SD 3 LoRA模型、FLUX.1 LoRA模型训练脚本,使用TensorBoard等技术监控模型训练过程,阶段性验证模型的训练效果。
- 模型测试与优化: 将训练好的SD 3模型、FLUX.1模型、SD 3 LoRA模型、FLUX.1 LoRA模型用于效果评估与消融实验,根据bad case和实际需求进行迭代优化。
讲完SD 3和FLUX.1系列模型训练的方法论,Rocky再向大家推荐一些SD 3和FLUX.1系列模型的训练资源:
- https://github.com/kohya-ss/sd-scripts/tree/sd3 (sd-scripts训练框架,包含SD 3、FLUX.1、FLUX.1 LoRA的训练脚本)
- diffusers/examples/dreambooth(huggingface开源的diffusers训练框架,包含SD 3、FLUX.1、SD 3 LoRA、FLUX.1 LoRA的训练脚本)
- https://github.com/bghira/SimpleTuner/tree/main (包含SD 3、FLUX.1、SD 3 LoRA、FLUX.1 LoRA的训练脚本)
- https://github.com/ostris/ai-toolkit (包含FLUX.1 LoRA的训练脚本)
同时Rocky也在持续整理优化SD 3和FLUX.1系列模型的完整训练资源SD3-FLUX-Train项目,大家只用在SD3-FLUX-Train中就可以完成SD 3和FLUX.1系列模型的训练工作,方便大家上手实操。大家可以关注Rocky的公众号WeThinkIn,后台回复:SD3-FLUX-Train,即可获得资源链接,包含数据处理、SD3和FLUX.1模型微调训练以及基于SD 3和FLUX.1的LoRA模型训练代码全套资源。
目前为止,我们对SD 3和FLUX.1系列模型的训练流程与所需资源已经有了初步的了解。接下来,就让我们跟随着Rocky的脚步,从0到1基于SD 3和FLUX.1系列模型,并结合训练资源一起训练自己的SD 3和FLUX.1绘画模型和对应的LoRA绘画模型吧!
7.2 Stable Diffusion 3和FLUX.1系列模型训练环境与训练文件配置
(1)基于原生sd-scripts训练项目
首先,我们需要下载训练资源,只需在命令行输入下面的代码即可:
git clone https://github.com/kohya-ss/sd-scripts.git
sd-scripts项目包含了Stable Diffusion 3和FLUX.1系列模型的核心训练脚本,同时包含了SD 3 LoRA和FLUX.1 LoRA的微调训练脚本。
但是sd-scripts项目中内容较为复杂,整个流程比较繁锁,对新手非常不友好,并且想要完成一整套训练流程,我们需要进行较多的配置与工程,非常不方便。所以在此基础上,Rocky这边帮大家对sd-scripts项目进行了整合归纳,总结了简单易上手的SD 3和FLUX.1模型以及相应LoRA模型的训练流程,制作成完整训练资源SD3-FLUX-Train项目,方便大家上手实操。
(2)一键上手的Stable Diffusion 3和FLUX.1系列模型训练环境配置
我们下载了SD3-FLUX-Train项目后,首先进入SD3-FLUX-Train项目中,安装SD 3和FLUX.1训练所需的依赖库,我们只需在命令行输入以下命令即可:
cd SD3-FLUX-Train
pip install torch==2.4.0 torchvision==0.19.0 xformers==0.0.27.post2 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
在完成上述的依赖库安装后,我们需要确认一下目前的Python、PyTroch、CUDA以及cuDNN的版本是否兼容,我们只需要在命令行输入以下命令即可:
# Python版本推荐3.10
>>> python
Python 3.10.14
# 加载PyTroch
>>> import torch
# 查看PyTorch版本
>>> print(torch.__version__)
2.4.0+cu121
# 查看CUDA版本
>>> print(torch.version.cuda)
12.1
# 查看cuDNN版本
>>> print(torch.backends.cudnn.version())
90100
# 查看PyTroch、CUDA以及cuDNN的版本是否兼容,True代表兼容
>>> print(torch.cuda.is_available())
True
如果大家在本地验证的时候和Rocky上述的版本一致,说明SD 3和FLUX.1模型的训练环境已经全部兼容!
安装和验证好所有SD 3和FLUX.1模型训练所需的依赖库后,我们还需要设置一下SD 3和FLUX.1模型的训练环境参数,我们主要是用accelerate库的能力,accelerate库能让PyTorch的训练和推理变得更加高效简洁。我们只需在命令行输入以下命令,并对每个设置逐一进行填写即可完成优化配置,Rocky下面主要介绍单机单卡训练和单机多卡训练的环境配置流程。
首先我们进行单机单卡训练的配置:
# 在命令行输入以下命令,开始对每个设置进行填写
accelerate config
# 开始进行训练环境参数的配置
In which compute environment are you running? # 选择This machine,即本机
Please select a choice using the arrow or number keys, and selecting with enter
➔ This machine
AWS (Amazon SageMaker)
# 单机单卡训练,选择No distributed training
Which type of machine are you using?
Please select a choice using the arrow or number keys, and selecting with enter
➔ No distributed training
multi-CPU
multi-XPU
multi-GPU
multi-NPU
multi-MLU
multi-MUSA
TPU
# 设置在GPU上训练,则输入NO;设置在CPU上训练,则输入yes
Do you want to run your training on CPU only (even if a GPU / Apple Silicon / Ascend NPU device is available)? [yes/NO]:NO
# torch dynamo,DeepSpeed等环境参数,不需要配置,直接回车跳过即可
Do you wish to optimize your script with torch dynamo?[yes/NO]: # 输入回车即可
Do you want to use DeepSpeed? [yes/NO]: # 输入回车即可
# 选择哪个卡进行训练,如果我们只有一张卡,那直接输入all即可;如果我们有多张卡,比如说8张卡,我们可以输入0-7中的一个数,表示使用特定的卡进行训练
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
# NVIDIA hardware环境参数,不需要配置
Would you like to enable numa efficiency? (Currently only supported on NVIDIA hardware). [yes/NO]: # 输入回车即可
# 训练精度,可以选择fp16、bf16、fp8。
Do you wish to use FP16 or BF16 (mixed precision)?
Please select a choice using the arrow or number keys, and selecting with enter
no
➔ fp16
bf16
fp8
# 完成配置后,配置文件default_config.yaml会保存在/root/.cache/huggingface/accelerate下
accelerate configuration saved at /root/.cache/huggingface/accelerate/default_config.yaml
到这里我们就完成了SD 3和FLUX.1系列模型的单机单卡训练的环境配置了。后续我们进行SD 3、FLUX.1、SD 3 LoRA和FLUX.1 LoRA模型训练的时候,只需要加载对应的default_config.yaml配置文件即可使用配置好的训练环境,具体的调用方法,后续的章节中Rocky会详细讲解。
我们下面再来看看如何进行单机多卡训练的配置:
# 在命令行输入以下命令,开始对每个设置进行填写
accelerate config
# 开始进行训练环境参数的配置
In which compute environment are you running? # 选择This machine,即本机
Please select a choice using the arrow or number keys, and selecting with enter
➔ This machine
AWS (Amazon SageMaker)
# 单机多卡训练,选择multi-GPU
Which type of machine are you using?
Please select a choice using the arrow or number keys, and selecting with enter
No distributed training
multi-CPU
multi-XPU
➔ multi-GPU
multi-NPU
multi-MLU
multi-MUSA
TPU
# 几台机器用于训练,一般选择1台。注意这里是指几台机器,不是几张GPU卡
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1
# torch dynamo,DeepSpeed,FullyShardedDataParallel,Megatron-LM等环境参数,不需要配置,直接回车跳过即可
Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: # 输入回车即可
Do you wish to optimize your script with torch dynamo?[yes/NO]: # 输入回车即可
Do you want to use DeepSpeed? [yes/NO]: # 输入回车即可
Do you want to use FullyShardedDataParallel? [yes/NO]: # 输入回车即可
Do you want to use Megatron-LM ? [yes/NO]: # 输入回车即可
# 选择多少张卡投入训练,假设我们有8张卡,则可以输入1-8之间的数字
How many GPU(s) should be used for distributed training? [1]:8
# 设置投入训练的GPU卡id,如果是全部的GPU都投入训练,则输入all即可。
# 如果是部分的GPU投入训练,那么需要输入特定的GPU卡id,比如我们有8张卡,投入2张卡进行训练,则可以输入0,1或者3,7等
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
# NVIDIA hardware环境参数,不需要配置
Would you like to enable numa efficiency? (Currently only supported on NVIDIA hardware). [yes/NO]: # 输入回车即可
# 训练精度,可以选择fp16、bf16、fp8。
Do you wish to use FP16 or BF16 (mixed precision)?
Please select a choice using the arrow or number keys, and selecting with enter
no
➔ fp16
bf16
fp8
# 完成配置后,配置文件default_config.yaml会保存在/root/.cache/huggingface/accelerate下
accelerate configuration saved at /root/.cache/huggingface/accelerate/default_config.yaml
到这里我们就完成了SD 3和FLUX.1系列模型的单机多卡训练的环境配置了。后续我们进行SD 3、FLUX.1、SD 3 LoRA和FLUX.1 LoRA模型训练的时候,同样只需要加载对应的default_config.yaml配置文件即可使用配置好的训练环境,具体的调用方法,后续的章节中Rocky也会详细讲解。
(3)依赖文件与依赖模型配置
另外需要注意的是,我们进行SD 3和FLUX.1模型的训练时,SD 3的Text Encoder模型会调用clip-vit-large-patch14、CLIP-ViT-bigG-14-laion2B-39B-b160k、t5-v1_1-xxl这三个配置文件。与此同时,FLUX.1的Text Encoder模型会调用clip-vit-large-patch14、t5-v1_1-xxl这两个配置文件。
一般情况下SD 3和FLUX.1模型会从huggingface上将配置文件下载到~/.cache/huggingface/目录中,但是由于网络原因很可能会下载失败,从而导致训练的失败。
所以为了让大家能更方便的训练SD 3和FLUX.1系列模型,Rocky已经将clip-vit-large-patch14、CLIP-ViT-bigG-14-laion2B-39B-b160k、t5-v1_1-xxl这三个配置文件放入SD3-FLUX-Train项目的utils_json文件夹中,并且已经为大家配置好依赖路径,大家只要使用SD3-FLUX-Train项目便无需做任何修改。如果大家想要修改clip-vit-large-patch14、CLIP-ViT-bigG-14-laion2B-39B-b160k和t5-v1_1-xxl依赖文件夹的调用路径,大家可以找到library/strategy_sd3.py脚本和library/strategy_flux.py脚本中的对应部分修改成自己的本地自定义路径比如“/本地路径/utils_json/clip-vit-large-patch14”即可,具体如下所示:
# strategy_sd3.py脚本的第20-22行
CLIP_L_TOKENIZER_ID = "./utils_json/clip-vit-large-patch14"
CLIP_G_TOKENIZER_ID = "./utils_json/CLIP-ViT-bigG-14-laion2B-39B-b160k"
T5_XXL_TOKENIZER_ID = "./utils_json/t5-v1_1-xxl"
# strategy_flux.py脚本的第20-21行
CLIP_L_TOKENIZER_ID = "./utils_json/clip-vit-large-patch14"
T5_XXL_TOKENIZER_ID = "./utils_json/t5-v1_1-xxl"
完成上述的流程后,接下来我们就可以进行SD 3和FLUX.1系列模型训练数据的制作和训练脚本的配置流程了!
7.3 Stable Diffusion 3和FLUX.1模型训练数据集制作
在本章节中,Rocky将带着大家完整讲解如何对Stable Diffusion 3和FLUX.1模型的训练数据集进行预处理与标签制作。
首先,我们需要对数据集进行清洗,和传统深度学习时代一样,数据清洗工作依然占据了AIGC时代模型训练70%-80%左右的时间。
并且这个过程必不可少,因为数据质量决定了机器学习的性能上限,而算法和模型只是在不断逼近这个上限而已。
我们需要筛除分辨率较低、质量较差(比如说1024*1024分辨率的图片< 500kb)、存在破损以及和任务目标无关的数据,接着再去除数据里面可能包含的水印、干扰文字等,接着我们就可以开始进行数据标注了。
数据标注可以分为自动标注和手动标注。自动标注主要依赖像BLIP和WaifuDiffusion Tagger这样的模型,手动标注则依赖标注人员。
从标注内容来看,AI绘画领域的标注内容主要可以分成Img2Caption和Img2Tag两个任务,下面我们一起深入浅出的学习理解这两个标注过程。
(1)使用BLIP自动生成数据的caption标签(自然语言标签)
我们先用BLIP对数据集进行自动标注,BLIP输出的是自然语言标签,我们进入到SD3-FLUX-Train/finetune/路径下,运行以下代码即可获得自然语言标签(caption标签):
cd SD3-FLUX-Train/finetune/
python make_captions.py "/替换成数据集路径" --caption_weights "../BLIP/model_large_caption.pth" --batch_size=1 --beam_search --min_length=5 --max_length=100 --debug --caption_extension=".caption" --max_data_loader_n_workers=2 --recursive
根据上面的代码Rocky向大家介绍一下每个参数的意义:
我们第一个传入的参数是训练集的路径,这也是必传的参数。
–caption_weights:输入本地BLIP模型路径,表示加载本地模型。如果不传入本地模型路径,则默认从云端下载BLIP模型。
–batch_size:表示每次传入BLIP模型进行前向推理的数据数量。较大的batch_size可以加快BLIP的推理速度,但是会增加显存占用。
–beam_search:设置为波束搜索,默认Nucleus采样。Beam Search是一种搜索策略,用于生成更精准的Caption标签。
–min_length:设置caption标签可以生成的最短长度。
–max_length:设置caption标签可以生成的最长长度。
–debug:如果设置,将会在BLIP前向推理过程中,打印所有的图片路径与caption标签内容,以供我们实时检查。
–caption_extension:设置caption标签文件的扩展名格式,一般为".caption"。
–max_data_loader_n_workers:指定PyTorch中DataLoader库读取图片的线程数量。设置更多的线程可以加快数据加载速度,特别是在数据量级比较大时有明显的加速效果。
–recursive:设置recursive参数后,会对所有子文件夹中的数据进行标注。
讲完了上述的运行代码以及相关和关键参数,下面Rocky再举一个美女图片标注的例子, 让大家能够更加直观的感受到BLIP处理数据生成caption标签的过程:

上图是单张图像的标注过程,整个数据集的标注流程也是同理的。等整个数据集的标注完成后,Stable Diffusion 3和FLUX.1系列模型训练所需的caption标注就准备好了。
当然的,除了使用BLIP模型进行自然语言的标注外,我们还可以使用git-large-textcaps系列、moondream系列、MiniCPM系列、CogVLM系列、MiniGPT-4系列等不同的模型生产不同细粒度和不同长度的标签,让我们的数据标注与处理过程更加灵活:

(2)使用WaifuDiffusion Tagger模型自动生成数据的tag标签(单词的排列组合)
接下来我们可以使用WaifuDiffusion Tagger模型对训练数据进行自动标注,WaifuDiffusion Tagger模型输出的是tag关键词标签,其由一个个关键词短语组成:

这里需要注意的是,我们调用WaifuDiffusion Tagger模型需要安装特定版本(2.10.0)的Tensorflow库,不然运行时会报“DNN library is not found“错误。我们只需要在命令行输入以下命令即可完成Tensorflow库的版本检查与安装适配:
# 检查Tenosrflow库的版本
pip show tensorflow
# 如果出现下面的log信息,说明Tenosrflow库的版本已经做好了适配
Name: tensorflow
Version: 2.10.0
Summary: TensorFlow is an open source machine learning framework for everyone.
# 如果显示Tenosrflow库并未安装或者版本不对,可以输入下面的命令进行重新安装
pip install tensorflow==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
完成上述的环境配置后,我们依然进入到SD3-FLUX-Train/finetune/路径下,运行下面的代码即可获得tag标签:
cd SD3-FLUX-Train/finetune/
python tag_images_by_wd14_tagger.py "/数据路径" --batch_size=8 --model_dir "../tag_models" --repo_id "wd-v1-4-moat-tagger-v2" --remove_underscore --general_threshold=0.35 --character_threshold=0.35 --caption_extension=".txt" --max_data_loader_n_workers=2 --debug --undesired_tags=""
Rocky根据上面的代码向大家介绍一下每个参数的意义:
我们第一个传入的参数是训练集的路径,这也是必传的参数。
–batch_size:表示每次传入WaifuDiffusion Tagger模型进行处理的数据数量。数值越大,处理速度越快,但会占用更多显存。
–model_dir:表示加载的本地WaifuDiffusion Tagger模型路径。
–repo_id:表示加载的本地WaifuDiffusion Tagger模型版本。
–remove_underscore:如果开启,会将输出tag关键词中的下划线替换为空格(long_hair -> long hair)。
–general_threshold:设置常规tag关键词的筛选置信度,比如1girl、solo、long_hair、1boy、smile、looking at viewer、blue eyes、hat、full body、dress等约7000个基础概念标签。
–character_threshold:设置特定人物特征tag关键词的筛选置信度,比如初音未来(hatsune miku)、羽衣啦啦(agoromo lala)、博麗靈夢(hakurei reimu)等约2100个特定人物特征标签。
–caption_extension:设置tag关键词标签的扩展名,一般为".txt"即可。
-max_data_loader_n_workers:指定PyTorch中DataLoader库读取图片的线程数量。设置更多的线程可以加快数据加载速度,特别是在数据量级比较大时有明显的加速效果。
–debug:如果设置,将会在WaifuDiffusion Tagger模型处理过程中,打印所有的图片路径与tag关键词标签内容,供我们检查。
–undesired_tags:设置不需要保存的tag关键词。
下面Rocky依然用之前的美女图片作为例子, 让大家能够更加直观的感受到WaifuDiffusion Tagger模型处理数据生成tag关键词标签的过程:

上图是单个图像的标注示例,整个数据集的标注流程也是同理的。等整个数据集都完成标注后,Stable Diffusion 3和FLUX.1系列模型训练所需的tag关键词标签就准备好了。
上面Rocky是使用了WaifuDiffusion Tagger模型系列模型中的wd-v1-4-moat-tagger-v2模型,目前WaifuDiffusion Tagger模型系列模型一共有5个版本,除了刚才介绍到的wd-v1-4-moat-tagger-v2模型,还包括wd-swinv2-tagger-v3模型、wd-convnext-tagger-v3模型、wd-v1-4-convnextv2-tagger-v2模型以及wd-vit-tagger-v3模型。
Rocky也分别对他们的自动标注效果进行了对比,在这里Rocky将上面的“美女”图片,分别输入到这五个自动标注模型中,一起来看看不同版本的WaifuDiffusion Tagger模型的效果:

从上图可以看到,在将general_threshold和character_threshold同时设置为0.5时,不同模型能够生成不同细粒度的标签,大家可以根据实际情况选择合适的模型。在这里,Rocky也推荐大家默认使用wd-v1-4-moat-tagger-v2模型。
(3)补充自定义的特殊标签
在完成了caption和tag的自动标注之后,如果我们需要训练一些自定义的特殊标注的话,还可以对数据进行补充标注。
SD3-FLUX-Train项目中也提供了对数据进行补充标注的代码,Rocky在这里将其进行提炼总结,方便大家直接使用。
大家可以直接打开SD3-FLUX-Train/custom tag.ipynb文件,并按照Rocky在代码中提供的注释进行参数修改,然后运行代码即可对数据集进行补充标注。如果大家觉得代码太复杂,don‘t worry,大家只需要将train_data_dir ="/本地数据集路径"和custom_tag ="WeThinkIn"设置成自己数据集的本地路径和想要添加的特殊标签,然后运行代码即可,非常简单实用。
还是以之前的美女图片为例子,当运行完补充标注的代码后,可以看到txt文件中,最开头的tag为“WeThinkIn”:

大家注意,一般我们会将手动补充的特殊标签放在第一位,因为一句话中最开始的tag权重最大,越靠后的tag权重越小。
到这里,Rocky已经详细讲解了在Stable Diffusion3和FLUX.1系列模型训练前,如何生成数据集的Caption标注、Tags标注以及补充自定义特殊标签的完整步骤与流程,在数据标注完成后,接下来我们就要进入训练数据预处理的阶段了。
(4)训练数据预处理
我们主要有两种方式对制作好的训练数据进行预处理:
- 制作训练数据的meta_data.json:对刚才生成的后缀为.caption和.txt的标注文件进行整合,存储成一个json格式的文件,方便后续SD 3和FLUX.1模型训练时根据json中的信息调取训练数据与标注。
- 制作训练数据的data_config.toml:在data_config.toml文件中配置相应的训练数据信息与数据参数,方便后续SD 3和FLUX.1模型训练时根据不同训练数据文件夹灵活配置参数。
下面Rocky将带着大家详细讲解上述的两种训练数据预处理形式,让大家能够更好的熟悉SD 3和FLUX.1模型训练前的数据预处理过程。
我们首先来讲解一下如何制作训练数据的meta_data.json文件。
我们需要进入SD3-FLUX-Train项目的finetune文件夹中,运行merge_all_to_metadata.py脚本即可:
cd SD3-FLUX-Train
python ./finetune/merge_all_to_metadata.py "/本地数据路径" "/本地数据路径/meta_data.json"
运行结果如下图所示,我们依旧使用之前的美图女片作为例子,我们在数据集路径中得到一个meta_data.json文件,打开可以看到图片名称、对应的tag和caption标注都封装在了json文件中,让人一目了然,非常清晰。

Rocky接下来讲解一下如何制作训练数据的data_config.toml文件。
我们只需要创建一个data_config.toml文件,并在其中填入相应的数据信息与参数并保存即可:
[general]
# general部分定义训练数据的常规参数
flip_aug = false
color_aug = false
shuffle_caption = false
caption_tag_dropout_rate = 0
keep_tokens_separator= "|||"
caption_extension = ".txt"
[[datasets]]
# 定义第一个训练数据文件夹的特定参数
batch_size = 2
enable_bucket = true
resolution = [2048, 2048]
max_bucket_reso = 2048
min_bucket_reso = 512
[[datasets.subsets]]
image_dir = "/本地路径/训练数据路径1"
num_repeats = 5
[[datasets]]
# 定义第二个训练数据文件夹的特定参数
batch_size = 6
enable_bucket = true
resolution = [1024, 1024]
min_bucket_reso = 512
[[datasets.subsets]]
image_dir = "/本地路径/训练数据路径2"
num_repeats = 5
[[datasets]]
# 定义第三个训练数据文件夹的特定参数
batch_size = 8
enable_bucket = true
resolution = [768, 768]
min_bucket_reso = 512
[[datasets.subsets]]
image_dir = "/本地路径/训练数据路径3"
num_repeats = 10
我们可以看到,在data_config.toml文件包含了“[general]”和“[[datasets]]”两个部分,其中“[general]”的参数会影响所有训练数据,而“[[datasets]]”部分的参数只会影响特定的训练数据文件夹。并且上述的数据参数配置形式,能够让我们方便的进行多分辨率训练(2048、1024、768等),下面Rocky再为大家讲解一下其中的重要参数的含义:
flip_aug和color_aug: 这两个数据增强参数在AI绘画领域中不建议开启,其与caching latents不兼容,若启用会导致训练时间大大增加(由于每次训练迭代时输入数据都会改变,无法提前获取 latents)。
shuffle_caption: 设置为true时,训练时对数据标签进行打乱,能一定程度提高模型的泛化性。
caption_tag_dropout_rate: 设置一个数据丢弃部分标签的概率,默认为0,取值范围[0-1]。(类似于传统深度学习的Dropout逻辑在数据标签上的扩展应用)
keep_tokens_separator: 如果有启动keep_tokens_separator、caption_tag_dropout_rate等参数,keep_tokens_separator设置的标签分隔符来表示哪些数据标签不受影响,下面我们举一个具体例子:
设置keep_tokens_separator= "|||"
# 假设数据标签如下
cat, dog, bird ||| WeThinkIn, park
# 这时标签 cat, dog, bird 可以被打乱或移除。
# 但 WeThinkIn, park 部分由于位于 ||| 之后,会保持原样,不参与任何随机操作。
caption_extension: 设置要读取的数据标签扩展名,一般为".caption"或者“.txt”。
enable_bucket、resolution、max_bucket_reso、min_bucket_reso: 这四个参数是一套组合参数,当我们设置enable_bucket = true,代表我们对训练数据进行分桶处理(resolution buckets);这时我们需要设置分桶的最大分辨率,由resolution分别设定图像的width和height;同时我们还要设置分桶的数据分辨率范围,最长边由max_bucket_reso设定,最短边由min_bucket_reso设定。
num_repeats: 特定数据集重复训练的次数,也可以理解为每个epoch中,训练集数据迭代的次数。(经验分享:如果数据量级小于一千,可以设置为10;如果数据量级大于一千,可以设置为5)
在完成上述的两种数据预处理过程后,我们就可以进入SD 3和FLUX.1模型训练的阶段了,我们可以对SD 3和FLUX.1模型进行微调(finetune)训练,也可以基于SD 3和FLUX.1训练对应的LoRA模型。
7.4 Stable Diffusion 3微调(finetune)训练(包含在12GB显存内训练)
在AI绘画领域,微调(finetune)训练仍然是让Stable Diffusion 3和FLUX.1系列模型优化训练的主流方法,理想的状态是让SD 3和FLUX.1模型在原有生成能力的基础上,再学习一个或几个细分领域的全新数据特征与分布,从而能在工业界、学术界、竞赛界以及应用界满足不同的AI绘画应用需求。
Rocky为大家举一个形象的例子,让大家能够能好理解SD 3和FLUX.1模型微调训练的意义。比如我们要训练一个二次元的SD 3和FLUX.1模型,应用于二次元领域。那么我们首先需要收集二次元优质数据作为训练集,由于官方发布的SD 3和FLUX.1模型能力已经足够强大,我们可以直接将其作为训练底模型。有了底模型和训练数据,再加上Rocky为大家撰写的SD 3和FLUX.1模型微调训练全流程攻略,我们就能训练获得一个能生成二次元风格的SD 3和FLUX.1行业模型,并作为二次元AIGC产品的核心大模型。
那么话不多说,下面Rocky将带着大家从0到1使用SD 3和FLUX.1模型进行微调训练的全流程攻略,让我们一起来训练属于自己的SD 3和FLUX.1模型吧!
(1)SD 3微调(finetune)数据集制作
在SD 3微调中,SD 3能够学习到大量的主题、人物、画风以及抽象概念等数据特征,所以我们需要对一个细分领域的数据进行广泛的收集,并进行准确的标注。
Rocky这边收集整理了833张宝可梦数据,包含多样的宝可梦种类,组成宝可梦数据集,作为本次SD 3微调训练的训练集。

接下来,我们就可以按照本文7.3章节中SD 3和FLUX.1模型数据集制作章节里的步骤,进行数据的清洗、自动标注以及添加特殊标签。
Rocky认为对SD 3和FLUX.1模型进行微调训练主要有两个目标:
- 增强SD 3和FLUX.1模型的图像生成能力。
- 增加SD 3和FLUX.1模型对新prompt的触发响应能力。
我们应该怎么理解这两个目标呢。我们拿宝可梦数据集为例,我们想要让SD 3和FLUX.1模型学习宝可梦的各种特征,包括脸部特征、形状特征、姿势特征、二次元背景特征以及二次元画风特征等。通过训练不断让SD 3和FLUX.1模型“学习”这些数据的内容,从而增强模型生成新宝可梦图片的能力。与此同时,我们通过自动标注与特殊标签,将图片的特征与标注信息进行对应,让模型在学习图片数据特征的同时,学习到对应的标注信息,能够通过二次元的专属标签生成对应的新宝可梦图像。
理解了上面的内容,咱们的数据处理部分就告一段落了。为了方便大家使用宝可梦数据集进行后续的SD 3和FLUX.1模型微调训练,Rocky这边已经将处理好的宝可梦数据集开源(包含原数据、标注文件、读取数据的json文件等),大家可以关注公众号WeThinkIn,后台回复“宝可梦数据集”获取。
(2)SD 3微调训练参数配置与讲解
本节中,Rocky主要介绍SD 3微调(finetune)训练的参数配置和训练脚本,同时也支持Stable Diffusion 3.5 Large/Medium模型的微调训练。
Rocky已经帮大家整理好了SD 3微调训练的全部参数与训练脚本,大家可以在SD3-FLUX-Train项目的data_config文件夹中找到相应的训练数据参数配置文件(data_config.toml),并且我们可以在SD3-FLUX-Train项目中找到SD3_finetune.sh脚本,里面包含了核心的训练参数。我们可以设置并运行这个脚本进行SD 3的微调训练。
接下来,Rocky将带着大家从头到尾走通SD 3微调训练过程,并讲解训练参数的意义。首先,我们可以修改data_config.toml中关于训练数据的相关参数以符合自己的需求,具体参数含义Rocky已在之前的章节中详细讲述。
接着,大家进入SD3-FLUX-Train项目中,可以打开SD3_finetune.sh脚本,修改其中的训练参数。最后使用sh SD3_finetune.sh命令即可启动SD 3模型的训练流程,训练自己的SD 3模型了:
accelerate launch \
--num_cpu_threads_per_process 8 sd3_train.py \
--pretrained_model_name_or_path "/本地路径/stable-diffusion-3-medium/sd3_medium.safetensors" \
--clip_l "/本地路径/stable-diffusion-3-medium/text_encoders/clip_l.safetensors" \
--clip_g "/本地路径/stable-diffusion-3-medium/text_encoders/clip_g.safetensors" \
--t5xxl "/本地路径/stable-diffusion-3-medium/text_encoders/t5xxl_fp16.safetensors" \
--save_model_as safetensors \
--sdpa \
--persistent_data_loader_workers \
--max_data_loader_n_workers 8 \
--seed 42 \
--mixed_precision bf16 \
--save_precision bf16 \
--dataset_config "/本地路径/data_config.toml" \
--output_dir "/本地路径/模型保存地址" \
--output_name "WeThnkIn_SD3_model" \
--learning_rate 5e-6 \
--max_train_epochs 20 \
--highvram \
--save_every_n_epochs 1 \
--optimizer_type adafactor \
--optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" \
--lr_scheduler constant_with_warmup \
--max_grad_norm 0.0 \
--cache_text_encoder_outputs \
--cache_text_encoder_outputs_to_disk \
--cache_latents \
--cache_latents_to_disk \
--vae_batch_size 6 \
--text_encoder_batch_size 6 \
--num_last_block_to_freeze 120 \
--full_bf16
大家使用上述的SD 3微调训练参数,并且将data_config.toml文件中的分辨率参数设置为1024、batch_size参数设置为1后,就能够在12G显存的机器上训练SD 3模型了!
(3)SD 3训练的关键参数详解
–sdpa:启动Scaled Dot-Product Attention(缩放点积注意力)优化技术,其中包含三种计算核心kernels:sdpa_flash、sdpa_mem_eff、sdpa_math。可以提升约2倍左右的计算性能,同时能够减少显存占用,能够支持Tranformer结构的高效训练和推理。
–num_last_block_to_freeze:在训练中冻结SD 3的部分参数,默认0,可设置 0~240。SD 3的MM-DiT中一共有240个Block结构,在训练中冻结120个Blocks以上的参数,能够获得更好的训练效果。比如设置为120,则代表冻结120个Blcoks的参数。开启这个参数还可以减少SD 3模型训练的显存占用,在10G左右的显存中也能进行SD 3的微调训练!
–highvram:如果我们的显存足够,可以启动这个参数。使得训练过程不清除 CUDA 缓存,充分利用显存,提高训练和推理的速度。
–optimizer_type、–optimizer_args以及–lr_scheduler:其中–optimizer_type代表训练中设置的优化器,它的主要任务是在反向传播过程中,根据损失函数计算的梯度来更新模型的权重,从而逐步最小化(或最大化)损失函数。不同的优化器采用了不同的策略来调整参数,使得模型能够更快、更稳健地收敛。目前主流的优化器有"AdamW"、“AdamW8bit”、“Lion”、“SGDNesterov”、“SGDNesterov8bit”、“DAdaptation”、“AdaFactor”、"PagedAdamW8bit"等。–optimizer_args代表指定优化器选项参数,可以用“key=value”的格式指定多个值。–lr_scheduler代表学习率调度器(Learning Rate Scheduler),主要控制优化器的学习率随着训练过程进行调整。目前主流的学习率调度策略有按比例衰减、指数衰减、余弦函数衰减、Reduce on Plateau、OneCycleLR等。
–max_grad_norm:启动梯度裁剪(Gradient Clipping),限制每次反向传播时梯度的范数(norm),从而避免梯度爆炸现象对模型训练的影响。默认值我们可以设置为1.0,这表示如果梯度的L2范数超过 1.0,会对梯度进行裁剪,使其范数不超过 1.0。如果设置为0,则表示不进行梯度裁剪,不对梯度的大小做任何限制。
–cache_text_encoder_outputs、–cache_text_encoder_outputs_to_disk:两个选项的作用都是缓存文本编码器(Text Encoder)的输出,以减少重新计算文本编码器输出所带来的计算开销,从而降低GPU显存的占用。其中–cache_text_encoder_outputs的作用是缓存文本编码器的输出,将生成的文本表示保存在内存中。–cache_text_encoder_outputs_to_disk的作用是将文本编码器的输出缓存到磁盘,因为内存资源是有限的,将输出保存到磁盘可以更有效地管理资源,尤其是在内存不足时。
–cache_latents、–cache_latents_to_disk:两个选项的作用都是缓存VAE输出的Latent特征,可以显著减少GPU显存的消耗。–cache_latents选项将Latents特征缓存到主内存(即RAM中)而不是GPU显存,能够有效减少显存(VRAM)的使用。–cache_latents_to_disk选项将Latents特征缓存到磁盘(如硬盘或SSD)而不是内存,这样能够进一步减少了显存和内存的使用。
–learning_rate:由于SD 3是基于Transformer架构的,所以建议学习率可以设置的小一点,可以设置5e-6与1e-7之间。
–vae_batch_size和–text_encoder_batch_size:前者用于指定VAE输出Latent特征进行缓存的批处理大小。后者用于指定Text Encoder输出文本编码特征(text encoder outputs)进行缓存的批处理大小。如果显存充足,我们可以增大vae_batch_size和text_encoder_batch_size来加速缓存过程,从而提升训练的整体效率。同时在缓存的过程中设计了多线程机制,能够有5%左右的加速处理。
–skip_cache_check:当启动该参数后,我们在训练时将不再检查图像Latent特征和文本特征的缓存文件(*.npz)内容,但是如果存在缓存文件缺失的情况,将为我们补充生成对应的缓存文件。在百万级以上大规模数据集进行训练时,该参数非常实用,使得我们不用重复生成冗余的缓存文件,加速模型训练。
–text_encoder_lr1、–text_encoder_lr2、–text_encoder_lr3:SD 3系列支持Text Encoder的微调训练,这三个学习率分别代表了CLIP-L、CLIP-G和T5-XXL各自的学习率。
到此为止,Rocky已经将SD 3全参微调训练的全流程都做了详细的拆解,等训练完成后,我们就可以获得属于自己的SD 3模型了!大家如果觉得好,欢迎给Rocky的劳动点个赞,支持一下Rocky,谢谢大家!
(4)加载自训练SD 3模型进行AI绘画
SD 3模型微调训练完成后,会将模型权重保存在我们之前设置的output_dir路径下。接下来,我们使用ComfyUI作为框架,加载SD 3宝可梦模型进行AI绘画。
在本文六章中,Rocky已经详细讲解了如何搭建ComfyUI框架,未使用过的朋友可以按照这个流程快速搭建起ComfyUI。
7.5 FLUX.1模型微调(finetune)训练(包含在24GB显存内训练)
本章节中,Rocky将带着大家从0到1进行FLUX.1模型的微调训练,FLUX.1在微调训练的参数设置和数据设置上与SD 3有很多相似之处。故本章节中Rocky将为大家着重讲解FLUX.1独有的训练参数与训练流程,与SD 3相通的部分大家可以直接看上一章节SD 3微调训练的内容,Rocky在本章节中就不再过多赘述了。
(1)FLUX.1微调(finetune)数据集制作
Rocky这边收集整理了更多的宝可梦数据共1287张,其中包含多样的宝可梦种类,组成FLUX.1-宝可梦数据集,作为本次FLUX.1微调训练的训练集。

为了方便大家使用FLUX.1-宝可梦数据集进行FLUX.1模型微调训练,Rocky这边已经将处理好的宝可梦数据集开源(包含原数据、标注文件、读取数据的json文件等),大家可以关注公众号WeThinkIn,后台回复“FLUX宝可梦数据集”获取。
(2)FLUX.1微调训练参数配置与讲解
本节中,Rocky主要介绍FLUX.1微调(finetune)训练的参数配置和训练脚本,包含了FLUX.1-dev和FLUX.1-schnell两个版本。
Rocky已经帮大家整理好了FLUX.1微调训练的全部参数与训练脚本,大家可以在SD3-FLUX-Train项目的data_config文件夹中找到相应的训练数据参数配置文件(data_config.toml),并且我们可以在SD3-FLUX-Train项目中找到FLUX_finetune.sh脚本,里面包含了核心的训练参数。我们可以设置并运行这个脚本进行FLXU.1的微调训练。
接下来,Rocky将带着大家从头到尾走通FLUX.1微调训练过程,并讲解训练参数的意义。首先,我们可以修改data_config.toml中关于训练数据的相关参数以符合自己的需求,具体参数含义Rocky已在之前的章节中详细讲述。
最后,大家进入SD3-FLUX-Train项目后,可以打开FLUX_finetune.sh脚本,修改其中的训练参数。同时使用sh FLUX_finetune.sh命令启动FLUX.1模型的训练流程,就可以训练自己的FLUX.1模型了:
accelerate launch
--num_cpu_threads_per_process 8 flux_train.py \
--pretrained_model_name_or_path "/本地路径/flux1-dev.safetensors" \
--clip_l "/本地路径/clip_l.safetensors" \
--t5xxl "/本地路径/t5xxl_fp16.safetensors" \
--ae "/本地路径/ae.safetensors" \
--save_model_as safetensors \
--sdpa \
--persistent_data_loader_workers \
--max_data_loader_n_workers 8 \
--seed 1024 \
--gradient_checkpointing \
--mixed_precision bf16 \
--save_precision bf16 \
--dataset_config "/本地路径/data_config.toml" \
--output_dir "/本地路径/模型保存地址" \
--output_name "WeThnkIn_FLUX_model" \
--learning_rate 5e-5 \
--max_train_epochs 10 \
--sdpa \
--highvram \
--cache_text_encoder_outputs_to_disk \
--cache_latents_to_disk \
--save_every_n_epochs 1 \
--optimizer_type adafactor \
--optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" \
--lr_scheduler constant_with_warmup \
--max_grad_norm 0.0 \
--timestep_sampling shift \
--discrete_flow_shift 3.1582 \
--model_prediction_type raw \
--guidance_scale 1.0 \
--loss_type l2 \
--fused_backward_pass \
--blocks_to_swap 35 \
--fp8_base
大家使用上述的FLXU.1微调训练参数,并且将data_config.toml文件中的分辨率参数设置为1024、batch_size参数设置为1后,就能够在24G显存的机器上训练FLUX.1模型了!
(3)FLUX.1训练的关键参数详解
下面Rocky再对FLUX.1微调训练的参数进行详细的讲解,让大家能够更好理解关键参数的意义。
–full_bf16:启用使用bf16格式进行训练,同时应用于权重和梯度。bf16(Brain Floating Point 16)是一种16位浮点数格式,具有较大的动态范围。使用bf16可以减少显存占用,加速计算,同时保持相对较高的数值精度。
–fused_backward_pass:将优化器的更新步骤与每个参数的反向传播过程融合。在常规的模型训练过程中,模型首先进行前向传播,然后反向传播计算梯度,最后由优化器更新参数。融合优化器步骤能够在计算梯度的同时直接更新参数,减少了中间梯度的存储需求,降低显存占用。目前仅支持Adafactor优化器。当同时指定 --fused_backward_pass 和 --full_bf16 时,随机舍入(Stochastic Rounding)被启用。这是一种数值技术,可以提高低精度计算的稳定性。
–blockwise_fused_optimizers:将优化器的更新步骤与每个块(block)的反向传播过程融合。作用类似于 --fused_backward_pass,但作用的粒度不同。以块为单位进行融合,可以更好地平衡内存使用和计算效率。可以与任何优化器兼容,但为了显存效率,建议使用Adafactor优化器。目前–blockwise_fused_optimizers 不能与 --fused_backward_pass 同时使用,同时不支持随机舍入。
–blocks_to_swap:指定要交换(swap)到 CPU 的双流模块和单流模块的数量。在显存不足时,将部分数据从GPU显存转移到CPU内中,当需要计算时再交换回来。这可以降低显存占用,同时会增加数据传输的开销成本,是一个以时间换空间的技术。默认不交换,设置为None。同时必须与–fused_backward_pass 或 --blockwise_fused_optimizers一起使用才能生效。为了在显存使用和训练速度之间取得平衡,建议双流模块最多交换 9 个,单流模块最多交换 18 个。例如我们设置–blocks_to_swap 6时,表示在每次训练迭代过程中交换6个双流模块,剩下的13个双流模块始终在GPU上。整体上的显存节省效果:每交换一个双流模块可节省约640MB的显存。每交换一个单流模块可节省约320MB的显存。在多GPU训练中,–blocks_to_swap参数目前暂不能使用。
–t5xxl_max_token_length:用于指定T5-XXL模型一次可以处理的最大文本tokens长度。在FLUX.1-dev模型中默认值为512;在FLUX.1-schnell模型中默认值为256。
–timestep_sampling:选择采样时间步长(范围 0-1)的方法,主要有以下几种模式:
- sigma:基于sigma的采样方式,与Stable Diffusion 3(SD 3)中的采样方式相同。
- uniform:使用均匀随机采样,每次在0-1范围内均匀地随机选择一个时间步长。
- sigmoid:使用标准正态分布生成的随机数经过sigmoid变换后得到的时间步长。
- shift:基于正态分布生成的随机数经过sigmoid变换后,再对sigmoid结果进一步偏移,以改变采样的分布。
- flux_shift:类似于shift,但偏移量根据图像分辨率动态调整,与FLUX.1-dev模型推理时的采样方式一致。注意,当指定flux_shift时,–discrete_flow_shift参数将失效。
–sigmoid_scale:当–timestep_sampling选择“sigmoid”和“shift”时生效,用于指定sigmoid和shift时间步长采样的缩放因子,默认值为 1.0。如果设置更大的值,将使采样分布更接近均匀分布。
–discrete_flow_shift:是Euler离散调度器(Euler Discrete Scheduler)中的离散流偏移量,默认值为 3.0,与 SD 3中的偏移量一致。在FLUX.1模型的微调训练中,建议设置为3.1582。
下面我们仔细讲解一下不同采样时间步长方法的分布是什么样的。
当我们设置–timestep_sampling shift和–sigmoid_scale 1.0时,–discrete_flow_shift设置0.5、1、3对timesteps分布的影响如下所示:

当我们设置–timestep_sampling sigmoid和–timestep_sampling uniform时,对应的Timesteps分布如下:

当我们设置–timestep_sampling shift时,不同–sigmoid_scale值(0.5、1.2、2.0)对timesteps分布的影响如下所示:

–model_prediction_type:用于指定对模型预测结果的处理方式,有以下几种方式:
- raw:直接使用预测值。
- additive:将预测结果添加到噪声输入中。
- sigma_scaled:应用sigma缩放,增强预测结果与噪声之间的距离,与SD 3中的sigma缩放方式相同。适合对噪声影响较敏感的任务,使模型预测更为稳健。
–loss_type:用于指定FLUX.1训练中使用的损失函数类型,默认使用L2损失函数(MSE loss)。除此之外,我们还可以选择huber代表Huber损失函数,smooth_l1代表smooth L1损失函数。
在开源社区的经验中,设置以下的参数可以获得较好的FLUX.1模型微调训练效果:
--timestep_sampling shift --discrete_flow_shift 3.1582 --model_prediction_type raw --guidance_scale 1.0 --loss_type l2
如果我们想在12G显存内对FLUX.1系列模型进行微调训练,我们可以设置–blocks_to_swap 28来实现,适合算力资源较为稀缺的读者尝试。
(4)加载自训练FLUX.1模型进行AI绘画
FLUX.1模型微调训练完成后,会将模型权重保存在我们之前设置的output_dir路径下。接下来,我们使用ComfyUI作为框架,加载FLUX.1宝可梦模型进行AI绘画。
在本文六章中,Rocky已经详细讲解了如何搭建ComfyUI框架,未使用过的朋友可以按照这个流程快速搭建起ComfyUI。
后续持续更新,码字不易,希望大家能多多点赞!!!
7.6 基于Stable Diffusion 3训练LoRA模型(包含在12GB显存内训练)
在Stable Diffusion 3和FLUX.1系列模型成为AI绘画领域最强的核心大模型后,LoRA模型的价值也再次被放大。因为轻量级的LoRA能够让AI绘画领域所有参与者以成本最低的方式,高效进行SD 3和FLUX.1系列模型的训练和商业应用。
Rocky认为基于Stable Diffusion和FLUX.1的AI绘画开源生态之所以如此繁荣,LoRA模型绝对功不可没。LoRA模型的训练成本是Stable Diffusion和FLUX.1全参微调训练成本1/10左右,各式各样的LoRA模型不断发布发布到开源社区,反哺AI绘画开源生态,让AI绘画领域持续繁荣。
如果大家想要了解LoRA模型的核心基础知识、LoRA的优势特点、热门LoRA模型应用推荐等内容,可以阅读Rocky之前写的文章:
深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
在本节,Rocky将为大家讲解从0到1使用SD 3模型训练对应的LoRA的全流程攻略,让我们一起来训练属于自己的SD 3 LoRA模型吧!
(1)SD 3 LoRA数据集制作
首先,我们需要确定数据集主题,比如说人物、画风或者某个抽象概念等。本次我们选择用Rocky自己搜集的人物主题数据集——纲手数据集来进行SD 3 LoRA模型的训练。

为了方便大家使用纲手数据集进行后续的LoRA训练,Rocky这边已经将处理好的纲手数据集开源(包含原数据和标注文件),大家可以关注公众号WeThinkIn,后台回复“纲手数据集”获取。
(2)SD 3 LoRA训练参数配置
训练Stable Diffusion 3 LoRA的参数配置与Stable Diffusion 3全参微调的训练配置有相同的部分,也有LoRA的特定参数需要配置。在本章节中,Rocky将着重为大家讲解SD 3 LoRA特定参数的相关意义。
大家只需要进入SD3-FLUX-Train项目后,可以打开SD3_LoRA_finetune.sh脚本,修改其中的训练参数。同时使用sh SD3_LoRA_finetune.sh命令启动SD 3 LoRA模型的训练流程,就可以训练自己的SD 3 LoRA模型了:
accelerate launch
--mixed_precision bf16 \
--num_cpu_threads_per_process 8 sd3_train_network.py \
--pretrained_model_name_or_path "/本地路径/stable-diffusion-3-medium/sd3_medium.safetensors" \
--clip_l "/本地路径/stable-diffusion-3-medium/text_encoders/clip_l.safetensors" \
--clip_g "/本地路径/stable-diffusion-3-medium/text_encoders/clip_g.safetensors"
--t5xxl "/本地路径/stable-diffusion-3-medium/text_encoders/t5xxl_fp16.safetensors" \
--save_model_as safetensors \
--sdpa \
--persistent_data_loader_workers \
--max_data_loader_n_workers 8 \
--seed 2048 \
--gradient_checkpointing \
--mixed_precision bf16 \
--save_precision bf16 \
--network_module networks.lora_sd3 \
--network_dim 16 \
--network_alpha=8 \
--network_train_unet_only \
--optimizer_type "PagedAdamW8bit" \
--lr_scheduler constant_with_warmup \
--max_grad_norm 0.0 \
--learning_rate 1e-4 \
--cache_latents_to_disk \
--cache_text_encoder_outputs \
--cache_text_encoder_outputs_to_disk \
--highvram \
--max_train_epochs 10 \
--save_every_n_epochs 1 \
--dataset_config "/本地路径/data_LoRA_config.toml" \
--output_dir "/本地路径/模型保存地址" \
--output_name "WeThnkIn_SD3_LoRA" \
--t5xxl_max_token_length 512 \
--fp8_base
大家使用上述的SD 3 LoRA模型微调训练参数,并且将data_LoRA_config.toml文件中的分辨率参数设置为1024、batch_size参数设置为1后,就能够在12G显存的机器上愉快训练SD 3 LoRA模型了!
(3)SD 3、SD 3.5 Large/Medium LoRA训练的关键参数详解
–blocks_to_swap:和FLUX.1 LoRA训练一样,SD 3、SD 3.5 Large/Medium LoRA训练也可以使用GPU和CPU的模型权重交换保存在缓解显存的占用。其中SD 3.5 Large最多可以设置36,SD 3.5 Medium最多可以设置22。
–pretrained_model_name_or_path:要使用的训练底模型,目前已经支持SD 3、SD 3.5 Large/Medium版本。
–training_shift:用于控制SD 3系列模型在训练过程中对时间步长(timesteps)的采样分布,默认值为 1.0,表示均匀分布(uniform distribution)。当值小于1.0时(较小的时间步长),训练更加偏向于接近图像的一侧,模型更专注于学习从低噪声恢复图像的能力。当值大于1.0时(较大的时间步长),训练更加偏向于接近噪声的一侧,模型更专注于学习从高噪声还原图像的能力。具体图示如下:

train_block_indices:我们可以通过设置该参数,来指定SD 3中要与LoRA权重结合训练的Blocks。比如说下面的设置表示1、2以及6-8层的Blocks进行训练:
--network_args "train_block_indices=1,2,6-8"
(4)加载自训练SD 3 LoRA模型进行AI绘画
SD 3 LoRA模型微调训练完成后,会将模型权重保存在我们之前设置的output_dir路径下。接下来,我们使用ComfyUI作为框架,加载SD 3 LoRA纲手人物模型进行AI绘画。
在本文六章中,Rocky已经详细讲解了如何搭建ComfyUI框架,未使用过的朋友可以按照这个流程快速搭建起ComfyUI。
后续持续更新,码字不易,希望大家能多多点赞!!!
7.7 基于FLUX.1模型训练LoRA模型(包含在12GB显存内训练)
在本章中,Rocky将为大家详细讲解FLUX.1 LoRA模型的微调训练全流程。如果大家想要了解LoRA模型的核心基础知识、LoRA的优势、热门LoRA模型推荐等内容,可以阅读Rocky之前写的文章:
深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
(1)FLUX.1 LoRA数据集制作
本次我们选择用Rocky自己搜集的人物主题数据集——火影忍者数据集来进行FLUX.1 LoRA模型的训练。

为了方便大家使用火影忍者数据集进行后续的FLUX.1 LoRA训练,Rocky这边已经将处理好的火影忍者数据集开源(包含原数据和标注文件),大家可以关注公众号WeThinkIn,后台回复“火影忍者数据集”获取。
(2)FLUX.1 LoRA训练参数配置
大家只需要进入SD3-FLUX-Train项目后,可以打开FLUX_LoRA_finetune.sh脚本,修改其中的训练参数。同时使用sh FLUX_LoRA_finetune.sh命令启动FLUX.1 LoRA模型的训练流程,就可以训练自己的FLUX.1 LoRA模型了:
accelerate launch
--num_cpu_threads_per_process 8 flux_train_network.py \
--pretrained_model_name_or_path "/本地路径/flux1-dev.safetensors" \
--clip_l "/本地路径/clip_l.safetensors" \
--t5xxl "/本地路径/t5xxl_fp8_e4m3fn.safetensors" \
--ae "/本地路径/ae.safetensors" \
--save_model_as safetensors \
--sdpa \
--persistent_data_loader_workers \
--max_data_loader_n_workers 8 \
--seed 2048 \
--gradient_checkpointing \
--mixed_precision bf16 \
--save_precision bf16 \
--network_module networks.lora_flux \
--network_dim 16 \
--network_alpha 8 \
--learning_rate 1e-3 \
--network_train_unet_only \
--cache_latents_to_disk \
--cache_text_encoder_outputs \
--cache_text_encoder_outputs_to_disk \
--highvram \
--max_train_epochs 20 \
--save_every_n_epochs 2 \
--dataset_config "/本地路径/data_LoRA_config.toml" \
--output_dir "/本地路径/模型保存地址" \
--output_name "WeThnkIn_FLUX_LoRA" \
--timestep_sampling shift \
--discrete_flow_shift 3.1582 \
--model_prediction_type raw \
--guidance_scale 1.0 \
--loss_type l2 \
--optimizer_type adafactor \
--optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" \
--lr_scheduler constant_with_warmup \
--max_grad_norm 0.0 \
--t5xxl_max_token_length 512 \
--fp8_base \
--split_mode \
--network_args "train_blocks=single"
其中要注意的是,我们要从“data_LoRA_config.toml”中读取数据的相关路径与参数配置。大家使用上述的FLUX.1 LoRA模型微调训练参数,并且将data_LoRA_config.toml文件中的分辨率参数设置为1024、batch_size参数设置为1后,就能够在12G显存的机器上愉快训练FLUX.1 LoRA模型了!
(3)FLUX.1 LoRA训练的关键参数详解
–fp8_base:设置该参数可以将FLUX.1模型转化为fp8(Float8)格式。比起热门的bf16/fp16精度,fp8占用显存资源更少。目前fp8模型仅支持float8_e4m3fn格式,其中e4m3 表示使用4位表示指数,3位表示尾数。相比其他 fp8 格式(如 e5m2),它在数值精度和范围之间做了一定权衡,适合AI模型中的浮点运算。fn(finite-numbers only) 表示会忽略非数值(NaN)和无穷大(Inf)的情况,进一步提升了计算效率,同时对数值稳定性有一定要求。
–cpu_offload_checkpointing:在训练时可以将部分模型参数转移到CPU上,减少约1GB的显存占用,但训练速度会下降约 15%。如果显存资源非常紧缺,可以启动该参数。
–optimizer_type:关于优化器的选择,除了我们之前提到过的AdamW、Lion、SGDNesterov、DAdaptation、AdaFactor等经典优化器之外,社区中也有使用adamwschedulefree和sgdschedulefree等schedulefree的优化器,在FLUX.1 LoRA的训练上也有较好的效果,具体我们可以进行如下设置:
--optimizer_type= "RAdam"
--optimizer_schedulefree_wrapper
--schedulefree_wrapper_args momentum=0.9, weight_decay_at_y=0.1
当我们使用经典的adafactor优化器,我们可以在16G左右的显卡上训练FLUX.1 LoRA模型:
--optimizer_type adafactor --optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" --lr_scheduler constant_with_warmup --max_grad_norm 0.0
–split_mode、–network_args “train_blocks=single”、–network_args “train_blocks=double”:我们可以使用–split_mode、–network_args "train_blocks=single"或者–split_mode、–network_args “train_blocks=double” 相组合的形式,只对FLUX.1的single-blocks部分和double-blocks部分进行LoRA权重的训练,能够大幅降低对显存的要求,可以在12G的显卡上进行训练。
–text_encoder_lr:如果想要微调FLUX.1中的CLIP ViT-L和T5-XXL Encoder,我们可以设置–text_encoder_lr参数。比如–text_encoder_lr 1e-4 1e-5分别代表CLIP ViT-L和T5-XXL Encoder的学习率;如果设置–text_encoder_lr 1e-4则代表两个Text Encoder模型公用一个学习率。
–network_train_unet_only:代表只对FLUX.1中的Transformer架构结合LoRA权重进行微调。如果想同时微调训练FLUX.1的Text Encoder模型,我们需要去掉–network_train_unet_only参数,同时在–network_args参数中增加train_t5xxl=True字段来让两个Text Encoder同时进行训练。
–fp8_base:启动该参数,我们可以使用经过fp8量化的t5xxl_fp8_e4m3fn.safetensors作为T5-XXL的模型权重,进一步降低FLUX.1 LoRA训练时的显存要求。
和FLUX.1微调训练一样,在开源社区的经验中,设置以下的参数可以获得较好的FLUX.1 LoRA模型微调训练效果:
--timestep_sampling shift --discrete_flow_shift 3.1582 --model_prediction_type raw --guidance_scale 1.0 --loss_type l2
"split_qkv=True"参数:设置–network_args "split_qkv=True"启动该参数后,能够在FLUX.1的注意力机制Q/K/V(Query、Key 和 Value)层引入独立的LoRA权重,能够更加充分训练LoRA权重来增强模型的表达能力。但同时会增加训练时间。
–apply_t5_attn_mask:启动该参数后,将会在训练过程中对注意力层设置注意力掩码(Attention Mask)。在传统深度学习时代,Transformer模型中设置注意力掩码可以控制注意力机制对输入信息的关注程度。掩码可以限制模型对某些特定位置的关注,从而增强模型对上下文的理解,从而增强模型的泛化性能。
train_double_block_indices和train_single_block_indices:通过在–network_args中指定这两个参数,能够在训练中指定FLUX.1系列double blocks和single blocks与LoRA权重结合的个数。因为Double Blocks一共有19个,所以我们可以设置的索引范围为 0-18。与此同时Single Blocks一共有38个,可以设置的索引范围为0-37。下面是一些具体的设置示例:
# 代表训练FLUX.1 double block中的0、1、8-12以及18部分;同时训练single block中的3、10、20-25以及37部分。
--network_args "train_double_block_indices=0,1,8-12,18" "train_single_block_indices=3,10,20-25,37"
#代表只训练FLUX.1 single block中的10-15部分,不训练double block部分
--network_args "train_double_block_indices=none" "train_single_block_indices=10-15"
(4)加载自训练FLUX.1 LoRA模型进行AI绘画
FLUX.1 LoRA模型微调训练完成后,会将模型权重保存在我们之前设置的output_dir路径下。接下来,我们使用ComfyUI作为框架,加载FLUX.1 LoRA火影忍者人物模型进行AI绘画。
在本文六章中,Rocky已经详细讲解了如何搭建ComfyUI框架,未使用过的朋友可以按照这个流程快速搭建起ComfyUI。
后续Rocky将持续更新完善本文,希望大家能多多点赞,支持Rocky的义务劳动!!!
8. Stable Diffusion 3和FLUX.1不同版本模型详解
8 .1 Stable Diffusion 3.5系列
2024年10月22号,StabilityAI最新发布了Stable Diffusion 3的升级版Stable Diffusion 3.5系列,包括Stable Diffusion 3.5 Large、Stable Diffusion 3.5 Large Turbo以及Stable Diffusion 3.5 Medium(将于10月29日开源)三个模型。三个SD 3.5系列模型的特点如下:
- Stable Diffusion 3.5 Large:参数量为8B,具有卓越的图像生成质量和提示词遵循能力,是Stable Diffusion系列中最强大的模型,能够生成一百万像素分辨率的高质量图像。
- Stable Diffusion 3.5 Large Turbo:作为Stable Diffusion 3.5 Large的蒸馏版本,它仅需4步就能生成高质量图像,并且具有出色的提示词遵循能力,速度比Stable Diffusion 3.5 Large快很多。在需要快速生成大量图像的场景中具备很强的价值。
- Stable Diffusion 3.5 Medium:参数量为2.5B,设计了全新的MM-DiT-X架构和训练方法,能够在消费级硬件上“即开即用”,在质量和定制便捷性之间取得了平衡。同时它能够生成分辨率在0.25到2百万像素之间的图像。

目前最新版的diffusers已经集成了SD 3.5,我们只需使用如下代码即可使用SD 3.5模型:
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("/本地路径/stable-diffusion-3.5-large", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
image = pipe(
"A capybara holding a sign that reads Hello World",
num_inference_steps=28,
guidance_scale=3.5,
).images[0]
image.save("capybara.png")

同时ComfyUI官方也第一时间支持了SD 3.5,提供了SD 3.5 ComfyUI工作流教程:https://blog.comfy.org/sd3-5-comfyui/
Rocky后续也会持续更新SD 3.5的最新干货知识,码字不易,希望大家能多多点赞!
8.2 “蓝莓”模型FLUX1.1-[Pro]
BlackForestLabs最新发布的FLUX1.1-[pro]模型,代号“蓝莓”。FLUX1.1-[pro]的生成速度是FLUX.1-[pro]的六倍,同时还提高了生成图像的整体质量、提示词一致性能力和多样性。
![FLUX1.1-[pro]模型生成图像示例](https://i-blog.csdnimg.cn/direct/304ef1441dc143fbb9f29b87e6458bee.png#pic_center)
目前FLUX1.1-[pro]模型在排行榜上超越了所有其他模型,获得了最高的Elo score分数:
![FLUX1.1-[pro]模型与其他主流模型的Elo score分数对比](https://i-blog.csdnimg.cn/direct/51bc40c357c0492d816f148dfd53b0f4.png#pic_center)
目前FLUX1.1-[pro]暂未开源,只能在在线平台使用,或者通过官方API来访问使用。官方还宣布即将推出快速高分辨率图像生成:后续将可以使用FLUX1.1-[pro]快速生成高达2K分辨率的图像,并且不会牺牲图像生成的提示词一致性。
8.3 FLUX.1 Lite-8B-alpha模型
FLUX.1作为当前性能最强劲的开源AI绘画大模型,其参数量达到了12B,与之对应的是推理成本也大幅增加。
因此Freepik在FLUX.1-dev的基础上开源了一个更小的蒸馏模型:FLUX.1 Lite-8B-alpha,DiT部分的参数量从12B减少到了8B,推理所需的显存减少了7GB左右,同时生成图像的速度提升了23%。

虽然说参数量从12B降低到了8B,但是整体的图像生成质量并未降低,使用同样的提示词,FLUX.1 Lite可以得到和FLUX.1-dev质量一致的生成图像:

那么FLUX.1 Lite是如何进行模型轻量化的呢?
很简单,减少FLUX.1-dev中MM-DiT Blocks的数量。FLUX.1-dev一共包含了19个MM-DiT Blocks,而最新的FLUX.1 Lite中只有8个,去掉了4~15层的一共11个MM-DiT Blocks。这本质上是使用了模型轻量化领域中的经典技术—模型剪枝来实现的,再使用FLUX.1-dev作为教师模型蒸馏训练得到。
那么我们在深挖一层,为什么要去掉4~15层的一共11个MM-DiT Blocks呢?
这也是Freepik通过实验验证的,通过固定提示词,分别分析了不同的MM-DiT Blocks和Single-DiT blocks对于整个生图结果的贡献。通过计算每个block的输入和输出之间的MSE(mean squared error)值,来量化这个block对最终图像质量的贡献。如果得到的MSE值很小,说明Latent特征经过这个block后并没有发生太多变化。Freepik对FLUX.1的MM-DiT Blocks和Single-DiT blocks的分析结果如下所示:

我们可以看到,FLUX.1前面和后面部分的MM-DiT block的输入和输出变化很大,而中间部分的MM-DiT block变化很小。同时后面部分的Single-DiT block的输入和输出变化很大,而前面的大部分Single-DiT block变化很小。这表明我们可以去掉一些中间的block模块,并不会对最后的生图质量带来明显的改变。
最后Freepik团队选择去掉了4~15层的MM-DiT blocks,大概率是因为MM-DiT blocks的参数规模比Single-DiT blocks要大,所以对MM-DiT blocks进行剪枝的收益更高。
目前Diffusers库和ComfyUI已经完美支持FLUX.1 Lite模型的推理,为了获得最佳结果,官方建议guidance_scale设置为3.5,并且采样步数设置在22~30之间。下面是通过直接运行Diffusers库FLUX.1 Lite模型的代码:
import torch
from diffusers import FluxPipeline
base_model_id = "/本地路径/flux.1-lite-8B-alpha"
torch_dtype = torch.bfloat16
device = "cuda"
# Load the pipe
model_id = "/本地路径/flux.1-lite-8B-alpha"
pipe = FluxPipeline.from_pretrained(
model_id, torch_dtype=torch_dtype
).to(device)
# Inference
prompt = "A close-up image of a green alien with fluorescent skin in the middle of a dark purple forest"
guidance_scale = 3.5 # Keep guidance_scale at 3.5
n_steps = 28
seed = 1024
with torch.inference_mode():
image = pipe(
prompt=prompt,
generator=torch.Generator(device="cpu").manual_seed(seed),
num_inference_steps=n_steps,
guidance_scale=guidance_scale,
height=1024,
width=1024,
).images[0]
image.save("output.png")
下面是使用ComfyUI运行FLUX.1 Lite模型的完整工作流:

9. Stable Diffusion 3和FLUX.1系列模型的性能优化
Stable Diffusion 3扩散模型部分的参数量达到了8B,而FLUX.1扩散模型部分的参数量更是直接达到了12B。我们可以从中看出,从2022年AIGC元年至今,AI绘画领域SOTA模型的参数量正向越来越大的趋势发展。
AIGC模型也面临着传统深度学习时代YOLO一样的模型轻量化、端侧部署、实时性能等应用需求,Rocky相信这也是AIGC时代未来10年中工业界、学术界以及竞赛界的一个重要研究方向。未来AI绘画大模型的整体性能优化(显存占用、推理耗时、效果稳定) 会是AIGC算法解决方案中非常重要的一环。
Rocky在本章中也会持续补充Stable Diffusion 3和FLUX.1系列模型的性能优化技术,方便大家持续学习。
9.1 Hyper-SD 3/Hyper-FLUX.1加速SD 3和FLUX.1推理
Hyper-SD 3 LoRA模型(0.125的权重)可以与SD 3结合,能够对SD 3模型的采样过程进行蒸馏,从而降低SD 3的采样步数,同时保持生成效果的一致性。
使用Hyper-SD3-4steps-CFG-lora模型时,可以设置CFG为3.0,采样步数为4;使用Hyper-SD3-8steps-CFG-lora模型时,可以设置CFG为5.0,采样步数为8(或者更小的步数6);使用Hyper-SD3-16steps-CFG-lora模型时,可以设置CFZG为7.0,采样步数为16(或者更小的步数12)。下面是SD 3挂载Hyper-SD 3 LoRA模型加速推理的具体代码:
import torch
from diffusers import StableDiffusion3Pipeline
base_model_id = "/本地路径/stable-diffusion-3-medium-diffusers"
# Take 8-steps lora as an example
ckpt_name = "/本地路径/Hyper-SD3-8steps-CFG-lora.safetensors"
# Load model, please fill in your access tokens since SD3 repo is a gated model.
pipe = StableDiffusion3Pipeline.from_pretrained(base_model_id, token="xxx")
pipe.load_lora_weights(ckpt_name)
pipe.fuse_lora(lora_scale=0.125)
pipe.to("cuda", dtype=torch.float16)
image=pipe(prompt="a photo of a cat holding a sign that says WeThinkIn", num_inference_steps=8, guidance_scale=5.0).images[0]
image.save("WeThinkIn.png")
Hyper-FLUX.1 LoRA模型(0.125的权重)可以与FLUX.1模型结合,同样能够对FLUX.1模型的采样过程进行蒸馏,从而达到降低FLUX.1采样步数从而加速推理。
使用Hyper-FLUX.1-dev-8steps-lora模型时,可以设置CFG为3.5,采样步数为8;当使用Hyper-FLUX.1-dev-16steps-lora模型时,可以设置CFG为3.5,采样步数为16。下面是FLUX.1模型挂载Hyper-FLUX.1 LoRA模型加速的具体代码:
import torch
from diffusers import FluxPipeline
base_model_id = "/本地路径/FLUX.1-dev"
# Take 8-steps lora as an example
ckpt_name = "/本地路径/Hyper-FLUX.1-dev-8steps-lora.safetensors"
# Load model, please fill in your access tokens since FLUX.1-dev repo is a gated model.
pipe = FluxPipeline.from_pretrained(base_model_id, token="xxx")
pipe.load_lora_weights(ckpt_name)
pipe.fuse_lora(lora_scale=0.125)
pipe.to("cuda", dtype=torch.float16)
image=pipe(prompt="a photo of a cat holding a sign that says WeThinkIn", num_inference_steps=8, guidance_scale=3.5).images[0]
image.save("WeThinkIn.png")
9.2 Model Offloading策略减少SD 3和FLUX.1的显存占用
在diffusers架构中运行SD 3和FLUX.1系列模型时,我们可以使用Model Offloading策略将模型的部分组件缓存到CPU中以节省GPU资源,不过这会让推理时间略有增加。这个策略的本质逻辑是SD 3和FLUX.1系列模型在推理时将用到的权重加载到GPU上,同时将剩余暂时不使用的权重保留在CPU上。
具体代码如下所示:
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("/本地路径/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
# Model Offloading策略核心代码
pipe.enable_model_cpu_offload()
image = pipe(
prompt="a photo of a cat holding a sign that says WeThinkIn",
negative_prompt="",
num_inference_steps=28,
height=1024,
width=1024,
guidance_scale=7.0,
).images[0]
image.save("sd3_WeThinkIn.png")
9.3 Dropping T5-XXL Encoder策略减少SD 3和FLUX.1的显存占用
如果在推理的过程中不加载T5-XXL Encoder这个4.7B参数量的文本编码器模型,SD 3和FLUX.1系列模型都可以显著降低对GPU显存的需求,同时图像生成的整体性能只会略有下降。
具体代码如下所示:
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained(
"/本地路径/stable-diffusion-3-medium-diffusers",
text_encoder_3=None,
tokenizer_3=None,
torch_dtype=torch.float16
)
pipe.to("cuda")
image = pipe(
prompt="a photo of a cat holding a sign that says WeThinkIn",
negative_prompt="",
num_inference_steps=28,
height=1024,
width=1024,
guidance_scale=7.0,
).images[0]
image.save("sd3_WeThinkIn-no-T5.png")
9.4 Quantized Version of the T5-XXL Encoder策略减少SD 3和FLUX.1的显存占用
我们除了不加载T5-XXL Encoder之外,还可以使用T5-XXL的8-bit量化精度版本,这样,我们可以继续使用所有的三个文本编码器,同时仅对性能产生轻微影响。
具体代码如下所示:
import torch
from diffusers import StableDiffusion3Pipeline
from transformers import T5EncoderModel, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model_id = "/本地路径/stable-diffusion-3-medium-diffusers"
text_encoder = T5EncoderModel.from_pretrained(
model_id,
subfolder="text_encoder_3",
quantization_config=quantization_config,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
model_id,
text_encoder_3=text_encoder,
device_map="balanced",
torch_dtype=torch.float16
)
image = pipe(
prompt="a photo of a cat holding a sign that says WeThinkIn",
negative_prompt="",
num_inference_steps=28,
height=1024,
width=1024,
guidance_scale=7.0,
).images[0]
image.save("sd3_WeThinkIn-8bit-T5.png")
9.5 使用Torch Compile加速SD 3和FLUX.1推理
使用Torch Compile编译后的SD 3和FLUX.1系列模型可以提升4倍左右的推理速度。
下面的代码具体展示了编译SD 3中MM-DiT和VAE模块进行加速推理的流程:
import torch
from diffusers import StableDiffusion3Pipeline
torch.set_float32_matmul_precision("high")
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = StableDiffusion3Pipeline.from_pretrained(
"/本地路径/stable-diffusion-3-medium-diffusers",
torch_dtype=torch.float16
).to("cuda")
pipe.set_progress_bar_config(disable=True)
pipe.transformer.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.transformer = torch.compile(pipe.transformer, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
# Warm Up
prompt = "a photo of a cat holding a sign that says WeThinkIn"
for _ in range(3):
_ = pipe(prompt=prompt, generator=torch.manual_seed(1))
# Run Inference
image = pipe(prompt=prompt, generator=torch.manual_seed(1)).images[0]
image.save("sd3_WeThinbkIn.png")
9.6 NF4、FP8以及SVDQuant等量化技术加速SD 3和FLUX.1推理
我们可以在Stable Diffusion-WebUI-Forge上运行SD 3和FLUX.1模型,同时可以设置NF4(Normalized Float 4-bit)和FP8两种精度进行推理。
与FP8精度相比,NF4精度在速度上更具优势,快了3.86 倍;同时NF4的显存占用更少,只有FP8的一半左右;不过FP8提供了更高的精度,这意味着FP8精度下会有更好的细节内容的生成与保留。
同时MIT提出了一种扩散模型后训练量化方法SVDQuant,可以将FLUX.1的权重和激活值量化到4 bits,在16GB的4090 GPU上实现3.5倍的显存优化和8.7倍的延迟减少。

SVDQuant方法是通用的,不仅支持DiT架构的SD 3和FLUX.1系列模型,还支持U-Net架构的SDXL、SD 1.x等模型。
Rocky将持续补充Stable Diffusion 3和FLUX.1系列模型的性能优化干货内容,大家敬请期待!!!
10. AI绘画大模型的效果评价指标
总的来说,到目前为止效果评估仍然是生成式AI模型的一个重要但未解决的问题,随着AIGC技术的持续发展, 更加完善的效果评价指标体系也在不断构建中。
Stable Diffusion 3在效果测评时使用了GenEval和人类视觉系统(HVS)评估作为文生图大模型的评价指标,其中人类视觉系统依旧是占据主导地位。
10.1 GenEval
基于GenEval评价指标,SD 3和其它模型的性能对比如下所示,可以看到在结合DPO技术后,SD 3的整体性能有一定的提升:

10.2 人类视觉系统(HVS)
SD 3在人类视觉系统(HVS)中进行了三个方面的评估:
- 生成图像的内容与提示词的一致性(Prompt following):让人工判断哪张图像与Prompt描述内容的匹配度更高。
- 视觉美感(Visual aesthetics):让人工关注图像的整体视觉质量和美感。在给定提示词的前提下,要求评估者选出质量最高和美感上最具吸引力的图像。
- 文字排版(Typography):让人工关注图像中生成的文字内容,去评估哪个图像更准确地生成了Prompt描述中指定的文字,包括字体、排版以及拼写的正确性。
上面这三项标准帮助评估者从不同的角度来评估SD 3与其他主流AI绘画大模型在生成图像时的表现。
论文中与SD 3模型进行对比的有Ideogram-V1.0、MJ-V6、DALL-E 3、Playgorund V2.5等AI绘画SOTA模型,在提示词一致性和文字排版方面,SD 3基本超过了目前所有的SOTA模型,在视觉美感方面也超过了大部分SOTA模型(和Ideogram-V1.0差不多)。具体对比结果如下图所示:

10.3 主流AI绘画领域的评价指标汇总
在这个章节中,Rocky将为大家持续汇总当前主流的AI绘画领域评价指标,让大家在工业界、学术界、竞赛界和应用界都能进行AI绘画大模型的效果测评闭环。
- FID、aesthetic:用于Playground系列模型的测评。
- MPS (Multi-dimensional Human Preference Score):用于Kolors模型的测评。
- DALL-E 3 eval:用于DALL-E 3模型的测评。
- MS-COCO FID-30k:用于PixArt-alpha模型的测评。
- Prompt–Image Alignment、VQAScore:用于Imagen3模型的测评。
后续持续更新,大家敬请期待!!!
11. 推荐阅读
Rocky会持续分享AIGC的干货文章、实用教程、商业应用/变现案例以及对AIGC行业的深度思考与分析,欢迎大家多多点赞、喜欢、收藏和转发,给Rocky的义务劳动多一些动力吧,谢谢各位!
11.1 深入浅出完整解析Stable Diffusion XL核心基础知识
在此之前,Rocky也对Stable Diffusion XL的核心基础知识作了比较系统的梳理与总结:
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
11.2 深入浅出完整解析Stable Diffusion核心基础知识
在此之前,Rocky也对Stable Diffusion的核心基础知识作了比较系统的梳理与总结:
深入浅出完整解析Stable Diffusion(SD)核心基础知识
11.3 深入浅出完整解析Stable Diffusion中U-Net核心基础知识
同时对Stable Diffusion中最为关键的U-Net结构进行了深入浅出的分析,包括其在传统深度学习中的形态和AIGC中的形态:
深入浅出完整解析Stable Diffusion中U-Net的前世今生与核心知识
11.4 深入浅出完整解析LoRA核心基础知识
对于AIGC时代中的“ResNet”——LoRA,Rocky也进行了讲解,大家可以按照Rocky的步骤方便的进行LoRA模型的训练,繁荣整个AIGC生态:
深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
11.5 深入浅出完整解析ControlNet核心基础知识
AI绘画作为AIGC时代的一个核心方向,开源社区已经形成以Stable Difffusion为核心,ConrtolNet和LoRA作为首要AI绘画辅助工具的变化万千的AI绘画工作流。
ControlNet正是让AI绘画社区无比繁荣的关键一环,它让AI绘画生成过程更加的可控,更有助于广泛地将AI绘画应用到各行各业中:
11.6 深入浅出完整解析Sora等AI视频大模型核心基础知识
AI绘画和AI视频是两个互相促进、相互交融的领域,2024年无疑是AI视频领域的爆发之年,Rocky也对AI视频领域核心的Sora等大模型进行了全面系统的梳理与解析:
11.7 深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统“AI江湖”之势。 Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
深入浅出完整解析AIGC时代Transformer核心基础知识
11.8 深入浅出完整解析主流AI绘画框架核心基础知识
AI绘画框架正是AI绘画“工作流”的运行载体,目前主流的AI绘画框架有Stable Diffusion WebUI、ComfyUI以及Fooocus等。在传统深度学习时代,PyTorch、TensorFlow以及Caffe是传统深度学习模型的基础运行框架,到了AIGC时代,Rocky相信Stable Diffusion WebUI就是AI绘画领域的“PyTorch”、ComfyUI就是AI绘画领域的“TensorFlow”、Fooocus就是AI绘画领域的“Caffe”:
深入浅出完整解析主流AI绘画框架(Stable Diffusion WebUI、ComfyUI、Fooocus)核心基础知识
11.9 手把手教你如何成为AIGC算法工程师,斩获AIGC算法offer!
在AIGC时代中,如何快速转身,入局AIGC产业?成为AIGC算法工程师?如何在学校中学习AIGC系统性知识,斩获心仪的AIGC算法offer?
Don‘t worry,Rocky为大家总结整理了全维度的AIGC算法工程师成长秘籍,为大家答疑解惑,希望能给大家带来帮助:
手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2025年版)
11.10 AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解:
深入浅出全面解析AIGC时代核心价值与发展趋势(2025年版)
11.11 算法工程师的独孤九剑秘籍
为了便于大家实习,校招以及社招的面试准备与技术基本面的扩展提升,Rocky将符合大厂和潜力独角兽价值的算法高频面试知识点撰写总结成 《三年面试五年模拟之独孤九剑秘籍》 ,并制作成pdf版本,大家可在公众号WeThinkIn后台【精华干货】菜单或者回复关键词“三年面试五年模拟”进行取用。
【三年面试五年模拟】AIGC时代的算法工程师的求职面试秘籍(持续更新中)
11.12 深入浅出完整解析AIGC时代中GAN系列模型的前世今生与核心知识
GAN网络作为传统深度学习时代的最热门生成式Al模型,在AIGC时代继续繁荣,作为Stable Diffusion系列模型的“得力助手”,广泛活跃于Al绘画的产品与工作流中:
深入浅出完整解析AIGC时代中GAN系列模型的前世今生与核心知识
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于AI行业话题的讨论与研究,包括但不限于算法、开发、竞赛、科研以及工作求职等。群里有很多AI行业的大牛,欢迎大家入群一起交流探讨~(请备注来意,添加小助手微信Jarvis8866,邀请大家进群~)


















 2740
2740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











