






在台湾举办的台北国际电脑展上,Stability AI CTO 兼联合 CEO Christian Laforte 与 AMD CEO 苏姿丰一起宣布文本到图像生成模型 Stable Diffusion 3 将于 6 月 12 日开源。
一、扩散模型的正向和反向过程
假设我们有一幅完整的图像,我们可以将它比作一幅清晰的风景画。在扩散模型的正向过程(添加噪声)中,我们逐渐向这幅画上增加噪点,就像在画布上喷洒墨水。每次喷洒的墨水量都很少,但经过多次喷洒后,整幅画逐渐被墨水覆盖,变得模糊不清,最终看起来只是一片混沌的墨水斑点。
接下来是反向过程(移除噪声),这就像是我们有一个能逆转喷洒墨水过程的魔法工具。通过这个工具,我们可以一步一步地移除画布上的墨水,逐渐恢复出之前的风景画。模型的训练过程实际上就是教模型如何使用这个工具,从一片混沌的墨水中逐渐找回原来的画作。
通过这个过程,模型学会了如何从随机噪声中一步步恢复出清晰的图像。这样,在生成新图像时,我们可以给模型一片完全随机的噪声斑点,它就可以根据所学到的内容逐渐将这些噪声“修复”成一幅完整的图像。
二、.Stable Diffusion 和 DiT
Stable Diffusion 2(SD2)是基于潜在扩散模型(Latent Diffusion Model, LDM)的。LDM 是一种特定类型的扩散模型,它在潜在空间中进行扩散过程。SD2 使用 U-Net 架构作为编码器和解码器,将图像压缩到潜在空间,并在潜在空间中应用扩散过程。
U-Net 是一种用于图像分割的卷积神经网络架构,由 Olaf Ronneberger 等人在 2015 年提出。它最初是为生物医学图像分割设计的,但后来在许多计算机视觉任务中得到了广泛应用。
U-Net 的名称来自于它的架构外观,类似字母 “U” 。其主要由两部分组成:
-
编码器(下采样路径):这个部分逐渐降低输入图像的空间分辨率,并提取特征。它通常由多个卷积层和池化层组成,以逐步减少特征图的大小并增加特征的数量。
-
解码器(上采样路径):这个部分逐渐恢复图像的空间分辨率。它通常使用反卷积(上采样)层逐渐增加特征图的大小,并结合编码器路径中的特征,以提高生成的图像质量。
U-Net 的一个关键特点是它在编码器和解码器之间存在跳跃连接,这样在解码过程中可以更好地保留编码器中的空间特征信息,从而提升生成结果的精度和质量。U-Net 架构在扩散模型中也得到了应用,特别是用于生成高质量的图像。
Stable Diffusion 3的架构基于Diffusion Transformer (DiT),而不是U-Net。这是一种新的AI创建图像的方式,它用一个处理图片小部分的系统替换了通常的图像构建块。此外,Stable Diffusion 3还结合了流匹配。 DIT 则是结合了扩散模型和 Transformer 架构的模型。
Stability AI最新发布了一个性能增强的文本到图像模型——Stable Diffusion 3,它在多主题提示处理、图像质量以及拼写能力方面展现出了卓越表现。目前该模型尚处于早期预览阶段,对于有意参与并提供改进建议的用户,现已开放等待名单,以便在全面推出之前进行进一步完善。
三、Stable Diffusion 3的亮点
Stable Diffusion 3将Diffusion Transformer结构与Flow Matching相结合,来看看这意味着什么。
-
性能与质量提升
Stable Diffusion 3的模型范围涵盖从8亿参数到80亿参数,这种多样化的规模和质量选择能够迎合不同的创意需求。该模型采用Diffusion Transformer架构并结合了Flow Matching技术,使其能够根据文本提示生成高质量的图像。Flow Matching(FM)是一种用来训练生成模型的新方法。生成模型的目标是学习数据的分布,然后生成与真实数据相似的新的数据。FM的独特之处在于它设计了一种训练方法,可以更快更高效地生成高质量的数据。 -
注重安全与责任
开发团队在培训、评估与部署各环节均引入了多项安全措施,防范潜在的滥用风险,强调安全、负责任的AI应用。研究员、专家以及社区正在持续进行符合道德规范的创新合作,将安全性和道德性放在重要位置。新版本Stable Diffusion中最激动人心的特性之一是其8亿参数的版本。这将极大地提升图像合成AI的易用性,与谷歌的Gemma 2b和微软的Phi-2语言模型的方向一致。
四、Diffusion Transformer结构技术概览
DiT结构结合了diffusion模型的强大能力和基于Transformer的可扩展性与灵活性。Diffusion模型通过迭代去除样本噪声的原则,在生成建模任务中获得了显著成功。著名的Transformer,擅长捕捉数据中的长距离相关性,在自然语言处理和计算机视觉领域取得了优异成绩。结合diffusion模型和Transformer的优点,能够生成更强大、更高效的模型,捕捉复杂的数据分布情况。
DiT的架构基础由一系列Transformer层构成,与标准Transformer模型(例如Vision Transformer或在自然语言处理中使用的Transformer架构)中的层类似。DiT在每一层中都融合了diffusion过程。这包括将diffusion机制集成到Transformer的自注意力机制当中。通常,DiT还包含了一个条件机制,用于类别条件图像生成。这个条件机制可以通过多种方式实现,如在输入序列中加入类别标记,或者让注意力机制依赖类别信息。
DiT在处理图像时也采取了分块方法,类似于视觉Transformer架构。图像的每个分块被展平成序列,再由Transformer层进行处理。DiT常使用自适应层归一化(adaLN)来增强训练稳定性和模型的表现。adaLN根据输入数据调整归一化参数,使模型能适应不同的输入分布特点。
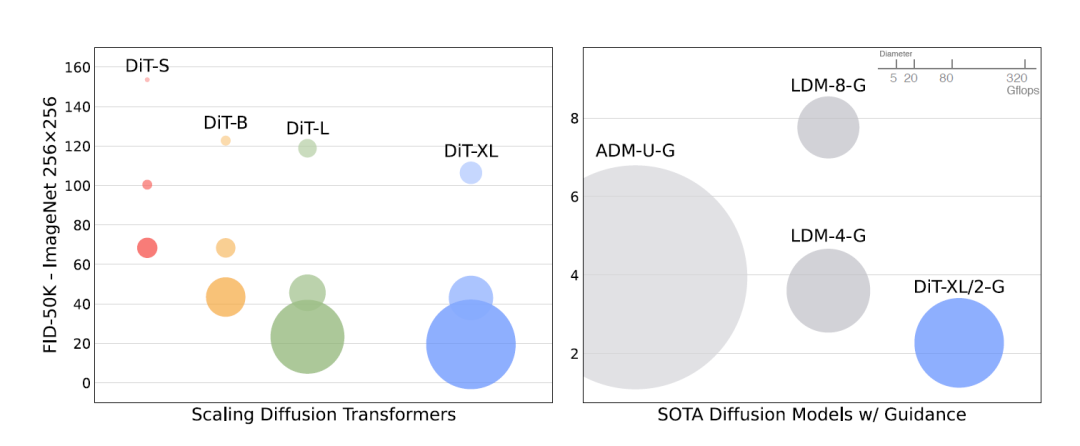
DiT-XL/2-G模型在FID-50K指标上表现优异,并且在计算量方面相对较低,这意味着它在生成高质量图像的同时保持了较高的计算效率。
训练过程
DiTs通常采用标准的生成模型训练技术进行训练,例如最大似然估计或变分推断。训练数据被输入模型,模型参数通过迭代更新以最小化合适的损失函数,如训练数据的负对数似然。在训练过程中,模型可能还会采用额外技术,比如模型权重的指数移动平均(EMA)、数据增强和正则化,以提高性能和稳定性。
DiTs的一个关键优势是其可伸缩性。借助变压器架构的可伸缩性,DiTs可以有效处理大规模的生成模型任务,包括高分辨率图像生成。DiTs在基准数据集上展现出了令人印象深刻的性能,并在诸如Frechet Inception距离(FID)、Inception得分(IS)和精确度/召回率这样的图像质量指标上经常取得先进的结果。
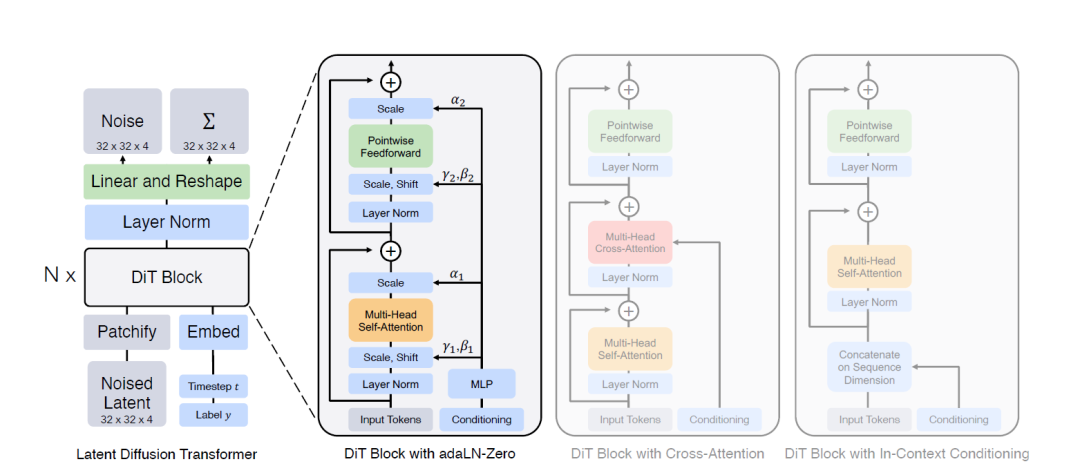
上面这张图展示了扩散Transformer(Diffusion Transformer,DiT)模型的架构。图中分为三部分,分别描述了模型的整体架构和两种不同的DiT块的设计:带有自适应层归一化的DiT块和带有交叉注意力的DiT块。
左侧:DiT模型架构
-
输入的潜在变量(latent)被分解成多个patch,然后输入到DiT块中进行处理。
-
该模型可以处理带有噪声的潜在变量,经过线性变换和形状调整后进行层归一化,再进入多个DiT块中。
-
输入中还包括时间步长(timestep t)和标签(label y),用于表示扩散过程中的当前状态和条件信息。
中间:带有自适应层归一化的DiT块
-
该块主要由两个子块组成,每个子块都包括多头自注意力(Multi-Head Self-Attention)、点对点前馈网络(Pointwise Feedforward)和自适应层归一化(Adaptive Layer Norm)。
-
自适应层归一化通过缩放和偏移参数来调整数据分布,参数通过MLP(多层感知机)从条件信息中得出。
-
多头自注意力和点对点前馈网络分别处理输入特征,并经过归一化和缩放调整后结合。
右侧:带有交叉注意力的DiT块
-
该块在自注意力之外还引入了交叉注意力机制(Multi-Head Cross-Attention),用于处理输入数据和条件信息之间的交互。
-
该块首先对输入特征进行多头自注意力处理,然后对条件信息应用交叉注意力。
-
通过在序列维度上连接输入特征和条件信息,使得模型能够更好地利用条件信息进行生成。
DiT模型利用Transformer架构的优势在扩散模型中生成高质量图像。图中展示了两种不同的DiT块设计,分别通过自适应层归一化和交叉注意力来有效利用条件信息。这些设计使得模型能够在扩散过程中更好地生成符合条件的图像。
下面这张图展示了不同Transformer模型规模和patch(图像块)大小对生成图像质量的影响。图中以生成的狗的图像为例,从不同的Transformer规模和patch大小的组合中展示了生成结果。
-
横轴(Increasing transformer size):
-
从左到右,Transformer模型的规模逐渐增大。
-
增大的Transformer规模通常表示模型参数量的增加,从而有更强的模型能力。
-
纵轴(Decreasing patch size):
-
从上到下,patch的大小逐渐减小。
-
较小的patch大小意味着图像被分割成更小的块进行处理,因此模型可以捕捉到更细节的特征。
结论:
-
随着Transformer规模的增大(从左到右),生成的图像通常变得更清晰,细节更丰富。
-
随着patch大小的减小(从上到下),图像的细节也变得更丰富、更清晰。
-
最右下角的图像(最大Transformer规模,最小patch大小)通常显示出最好的生成效果,而最左上角的图像(最小Transformer规模,最大patch大小)生成效果最差。
这说明增大Transformer规模和减小patch大小可以显著提升生成图像的质量

Patch size(图像块大小)是指将输入图像分割成较小的块(称为patches)时,每个块的尺寸。在计算机视觉的Transformer模型中,例如Vision Transformer(ViT)和扩散模型中的DiT,图像通常不会直接作为一个整体被输入模型,而是会被分割成多个较小的块,每个块作为一个独立的输入单元。这些块的大小就是patch size。
-
输入维度的调整: 将图像分割成patches可以将二维图像转换成类似一维序列的形式,从而适应Transformer模型的输入需求。
-
细节和特征表示: 更小的patch size可以捕捉到图像中更细微的特征和细节。相反,较大的patch size会导致图像细节的丢失,但模型需要处理的输入块数量更少。
-
计算效率和性能: 较小的patch size可以使模型捕捉到更多的细节信息,但同时也会增加计算负担。需要在计算复杂度和模型性能之间取得平衡。
在图像生成任务中,选择适当的patch size可以帮助模型更好地捕捉图像中的特征,从而提高生成效果。
五、Flow Matching
Flow Matching(FM)是一种用于训练连续归一化流(CNF)模型的新颖框架,旨在克服与传统训练方法相关的一些局限。它引入了一种无需模拟的方法论,利用条件结构高效地扩展到高维数据集,同时提供改进的采样和生成能力。
传统训练CNF模型的方法通常涉及计算成本高昂的模拟,特别是处理高维数据时。这些模拟可能会阻碍可伸缩性和效率。Flow Matching的目标是通过提供一个无需模拟的替代方案来解决这些挑战,此方案简化了训练过程,同时保持了高质量的采样和生成性能。
-
条件结构:FM依赖于条件概率路径和向量场来建模数据通过潜在空间的流动。通过基于相关变量的条件操作,FM能更有效地捕捉复杂的数据分布。
-
概率路径:FM不依赖于扩散过程或随机模拟,而是直接指定通过潜在空间的概率路径。这允许对数据生成过程进行更精确的控制。
-
向量场:FM利用向量场定义流动的动力学,指导数据从输入空间向潜在空间的转换。这些向量场可以优化,以匹配期望的概率路径。
FM训练方法论
-
无需模拟的方法:FM通过直接规定概率路径并相应地优化向量场,消除了对成本高昂模拟的需求。这使训练过程更快速和高效。
-
基于梯度的优化:FM采用基于梯度的优化技术迭代更新CNF模型参数,确保向期望的概率分布收敛。
-
条件流匹配目标:FM定义了一个新颖的目标函数——条件流匹配(CFM)目标,它允许无偏梯度估计和高效训练。FM已在不同分辨率的各种图像数据集中,包括CIFAR-10和ImageNet,展现出有效性。它在负对数似然(NLL)、样本质量(通过Frechet Inception距离,FID测量)和训练效率(通过功能评估次数,NFE测量)方面都达到了最先进的结果。与现有方法的比较实验凸显了FM的优越性能,特别是在收敛速度更快和采样效率提高方面。
我会进一步详细解释每个部分:
-
背景:生成模型是一类让电脑学习如何生成新数据的技术。比如,给它看大量真实的图片,然后让它生成一张从未见过的新图片。过去几年出现了很多新模型,比如扩散模型,通过逐渐添加噪声再逆向去噪来生成新图片。然而,这种方法通常需要很长的训练时间和大量的计算资源,生成图片的过程也比较慢。
-
CNF是什么:CNF(连续正则流)是一种生成模型的技术,它通过学习一个时间相关的向量场来将一种概率分布转换为另一种。简单来说,它是一组可以将随机数据(比如一堆噪点)变成复杂数据(比如一幅高清图像)的数学操作。在这个过程中,CNF可以调整自己以适应不同的目标任务。
-
什么是流匹配:流匹配是一种新的方法,用来训练CNF模型。它让模型学习一种特殊的“流”(数学公式),该流可以将随机噪点变成高质量的图片。研究人员通过提供目标和优化损失(即让模型生成的图片尽可能接近目标)来帮助模型学会这个流的公式。与之前的方法相比,流匹配不需要复杂的数值模拟,简化了训练过程。
-
条件流匹配:直接找到那个复杂的向量场很困难,研究人员提出了一种简化方法,叫条件流匹配。它通过引入条件概率路径和条件向量场,将复杂的问题分解成更简单的小问题。每次模型只需要学习其中一个小问题,逐渐把各个小问题的答案组合在一起,从而达到目标。
-
特例:论文中提出了两种特例:
-
扩散路径:这是一种从噪声生成清晰图片的路径,常用于扩散模型。它通过逐步减少噪声,在每一步都得到更清晰的图片。
-
最优传输路径:通过最优传输理论,可以设计一种直接从一种概率分布到另一种概率分布的路径,不需要中间的许多步骤。这种方法通过线性插值直接平滑地将两种概率分布连接起来。
- 实验结果:
-
样本质量:在质量测量上,流匹配产生的图片质量优于目前流行的扩散模型,在Frechet Inception Distance(FID)和Negative Log-Likelihood(NLL)两个指标上表现更好。
-
训练效率:流匹配在训练过程中,比扩散模型更快。在ImageNet数据集的不同分辨率上进行了测试,结果表明流匹配耗时更短。
-
生成效率:在生成图片时,流匹配比扩散模型快。相同的迭代次数下,流匹配能更快地产生高质量的图片。
- 结论:这项研究为生成模型提供了一种新的训练方式,可以让电脑通过更直接、更快的方法学会生成图片。通过这项技术,我们不仅可以提高图片的生成速度,还可以产生更高质量的图片。未来还可以探索如何将这项技术应用于更多种类的生成任务,比如文本和音频生成。
六、DiT和FM融合
Diffusion Transformer架构与Flow Matching的结合代表了文本到图像生成AI领域中一个有趣的路径。一
Diffusion Transformer架构将Transformer模型强大的序列建模能力与diffusion模型生成高质量图像的能力结合在一起。这种结合使模型能够有效捕捉文本提示与相应图像之间的复杂关系,从而产生更连贯、更符合上下文的输出。语言与图像之间的关系至关重要,因为最终模型理解人类语言及其含义并将其融入生成过程中时,我们将向更可控的图像生成系统迈进。
Flow Matching技术使得模型能学习图像数据的底层分布,并生成与这个分布紧密匹配的样本。通过将生成的图像与目标分布对齐,Flow Matching确保了输出在视觉上吸引人且呈现现实特征。根据Stability的研究人员表示,Diffusion Transformer架构与Flow Matching的整合显著提高了图像质量。模型能够生成具有更精细的细节、更锐利的纹理以及对输入文本提示更准确的表现的图片。这种对图像保真度的提升增强了整体用户体验,并拓宽了潜在应用领域的范围,如数字艺术、设计和娱乐等。
文本到图像生成的另一个挑战是处理含有多个主题的提示。因此,我们通常所见的大多数AI生成的图像,通常只会呈现单个人物。Diffusion Transformer架构与Flow Matching相结合,使得模型能够更准确、更连贯地处理复杂的多主题提示。这一能力允许用户基于细致的文本描述生成多样化和复杂的图像,这为创造性表达和故事讲述开辟了新的可能性。
Diffusion Transformer架构和Flow Matching的结合代表了文本到图像生成方法学的一大进步。通过利用两种方法的优势,这一创新框架提供了改进的建模能力、增强的图像质量以及在优先考虑安全和伦理的同时,有效处理多主题提示。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

















 5886
5886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









