







一、CNN中的感受野的定义和性质:
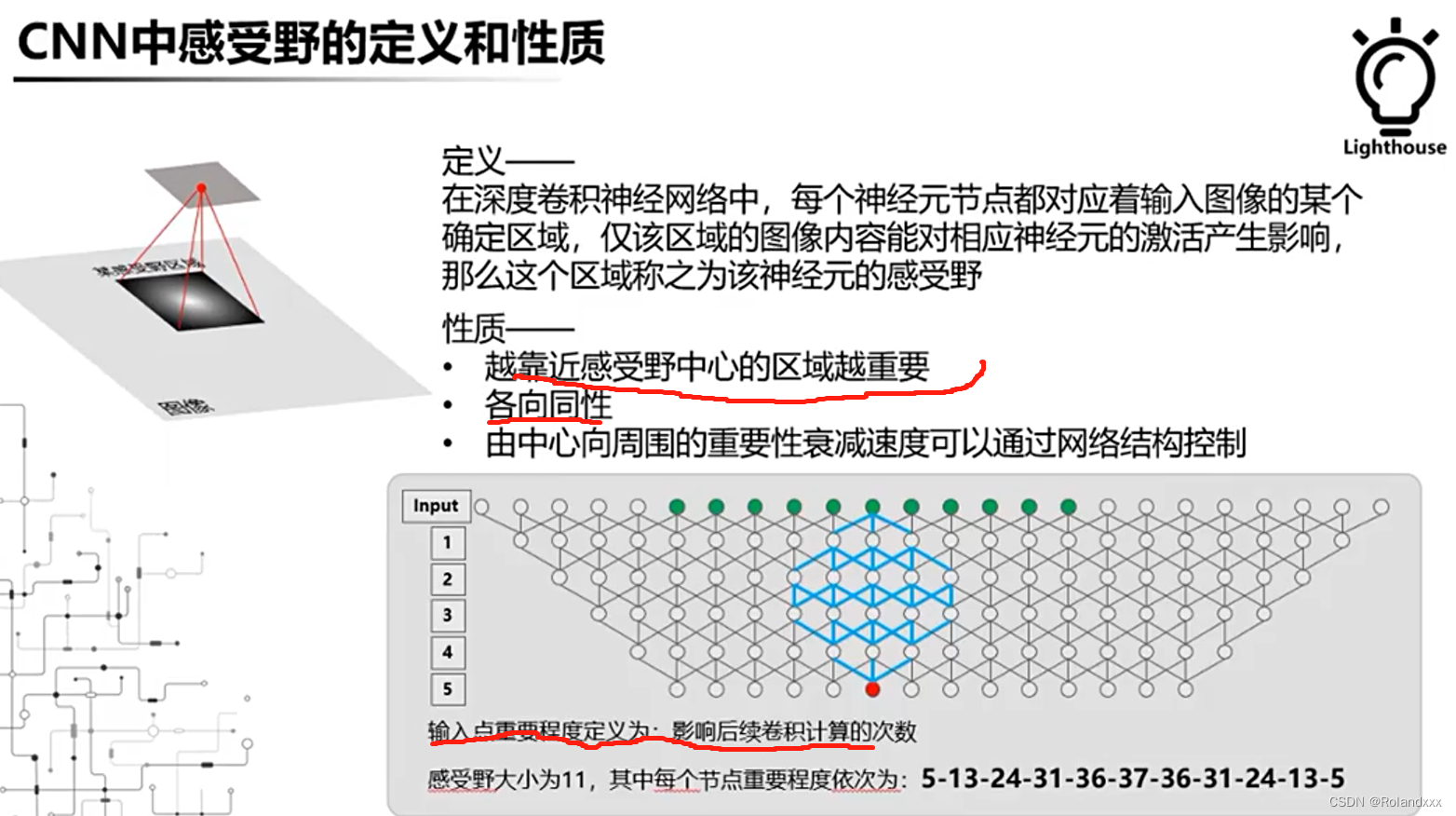
感受野是理解深度卷积神经网络的大杀器,上图中的各向同性是指距离感受野中心相等的位置重要程度是一致的。从上图中可以发现激活值(上图的红色节点)的感受野中心的节点(上图绿色的节点的中间位置的节点)是对激活值起到最关键的影响(因为参与到激活值计算的次数最多,有37次)。
二、哪些操作能够改变感受野大小?

残差连接改变感受野的原因是通过跨层连接将特征图进行element-wise的加和,很显然这样将两种特征图进行耦合的操作会改变感受野的大小。这时我们通常将较大的感受野作为最终的感受野大小。
三、感受野大小计算公式(感受野大小的计算公式是和padding是无关的,当前层的步长并不影响当前层的感受野,感受野的增速是直接和卷积步长累乘相关的,但不包含当前层的步长,想要网络更快速得达到某个感受野的尺度,可以让步长大于1的卷积核更靠前):
下图的例子中的卷积操作是由上至下,迭代计算公式,既然是迭代那么一定就要找到初始值,初始值:r0=1,s0=1,可以理解成在输入图像上的每个像素的感受野就是它自己,然后像素之间的步长都是1。 需要注意的是:感受野之所以能大于原图的尺寸是因为中间有padding操作,对特征图进行padding后,padding的部分也默认拥有当前特征层对应的感受野大小。注意:我所说的第l层的感受野是指经过第l层卷积后生成的特征图对应的感受野!

四、感受野中心位置的计算公式(感受野中心位置是感受野像素覆盖面的中心的那个像素点!)
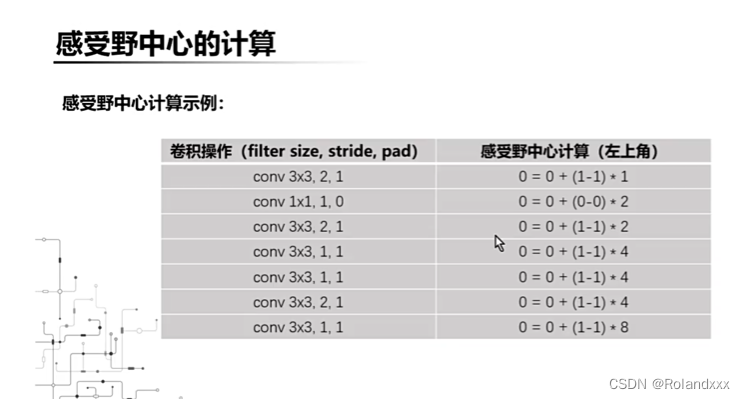
这里有两个公式如下图红框所示,
第一个公式是计算的是当前层左上角处感受野中心的位置即像素坐标(0,0)位置的感受野中心位置,且假设卷积核的长宽均相等,感受野中心位置和pad有关。
当我们获得左上角中心位置以后,当前层其他位置的感受野中心就可以由第二个公式得到,n和m表示对特征图x和y方向的索引,中心位置的偏移均为固定的步长,但这里的计算要注意,对于卷积核步长的累乘是要包括当前层步长的。由这个公式我们也可以得出一个结论,越浅层的特征图,它的步长累乘越小,它在原图上的感受野中心的密度越大。相反越深层的特征图,它在原图上的感受野中心的密度越小,如下面第二张图所示。感受野中心的密度是非常关键的,因为它密度大就说明感受野中心就有很大的概率可能命中目标,就能有效学习。

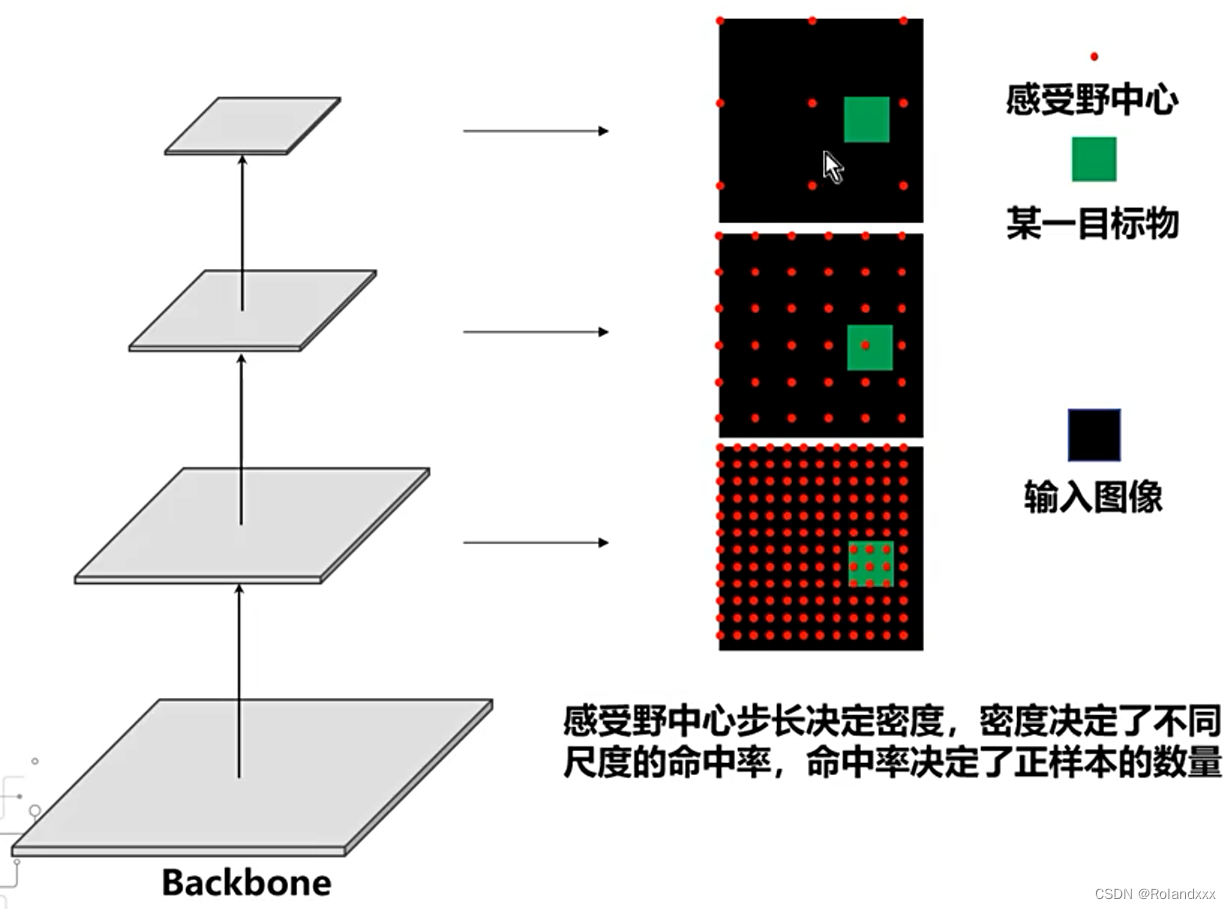
下图为感受野中心计算的例子,这里仅仅计算左上角处的感受野:
五、有效感受野的概念:
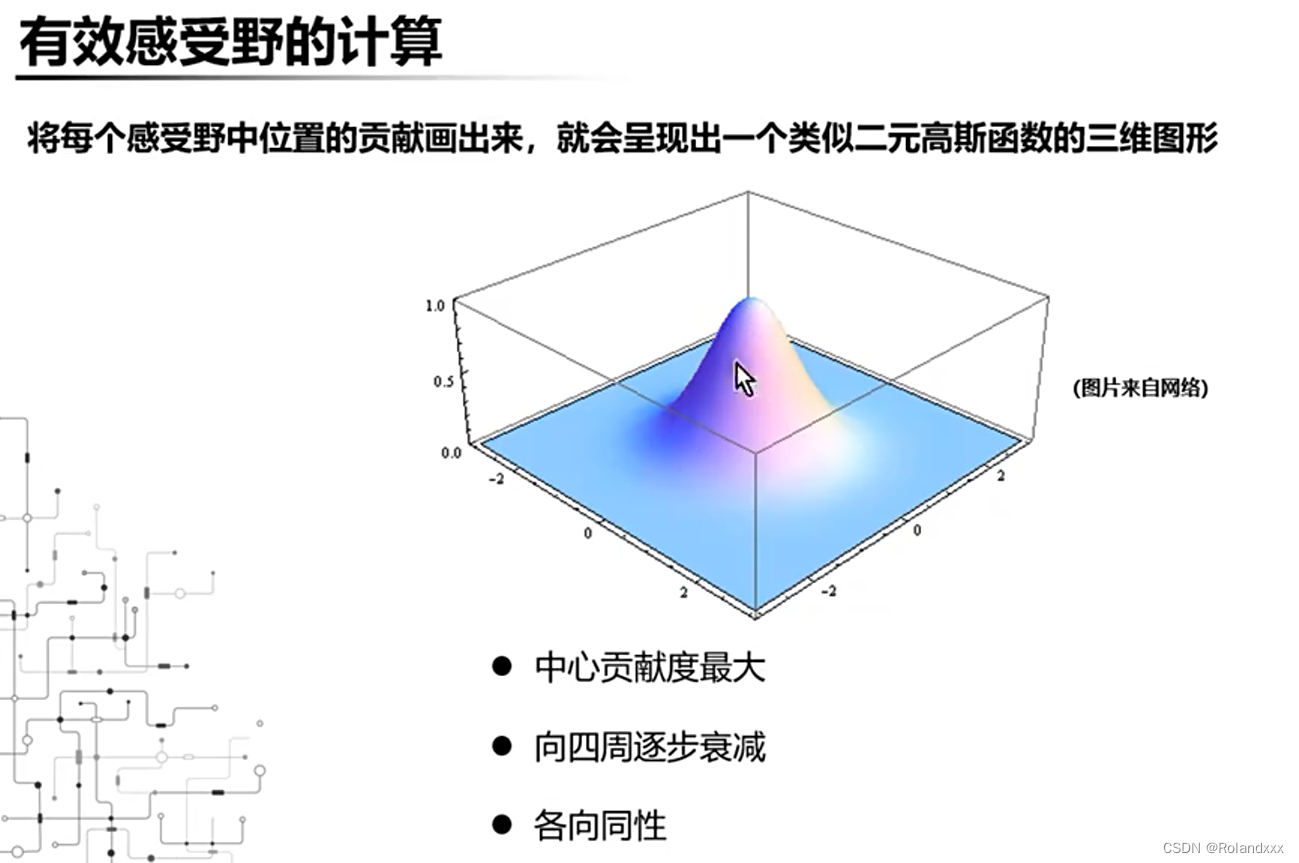
下图两个方形表示理论感受野的大小,他们是一样的,颜色越白的区域表示越重要,可以看到理论感受野虽然相同,但是有效感受野的分布是不一样的。为什么有效感受野这么重要呢?因为通过有效感受野,我们可以知道神经网络到底在关注哪里,有多关注!还可以指导分类、检测、分割网络的设计(多深),还是一个进一步探索网络可解释性的有效手段。

六、如何计算有效感受野?(有效感受野就可以理解为第一节图中所说的“输入节点影响后续计算的次数被作为它的重要程度”,那么重要程度大于某个阈值的我们都可以认为是属于有效感受野)
我们可以把CNN的整个计算过程看成是一个三维的有向图,边的指向是由底层节点指向高层节点(高层指越往后的特征图),有了这个假设然后就可以参考下图红圈中的计算方式了。还可以从梯度反传的角度来看,每条边代表的梯度是同等重要的,所以用边的总数来刻画这个贡献度是十分合理的!

七、感受野如何影响分类网络(深度于网络的意义):
ERF是有效感受野,RF是感受野。随着网络越深,感受野也就越大,但感受野仅仅和原图像一样大就足够了吗,答案是否定的,因为这时有效感受野这时并没有覆盖全图,下图中白色亮的地方就是有效感受野,最外面的那个正方形就是指理论感受野。可以想象就像人的眼睛一样,盯着一个位置看,虽然周围的内容都能映入眼底,可以看得最清楚的还是盯着的那个位置的旁边的那些地方。

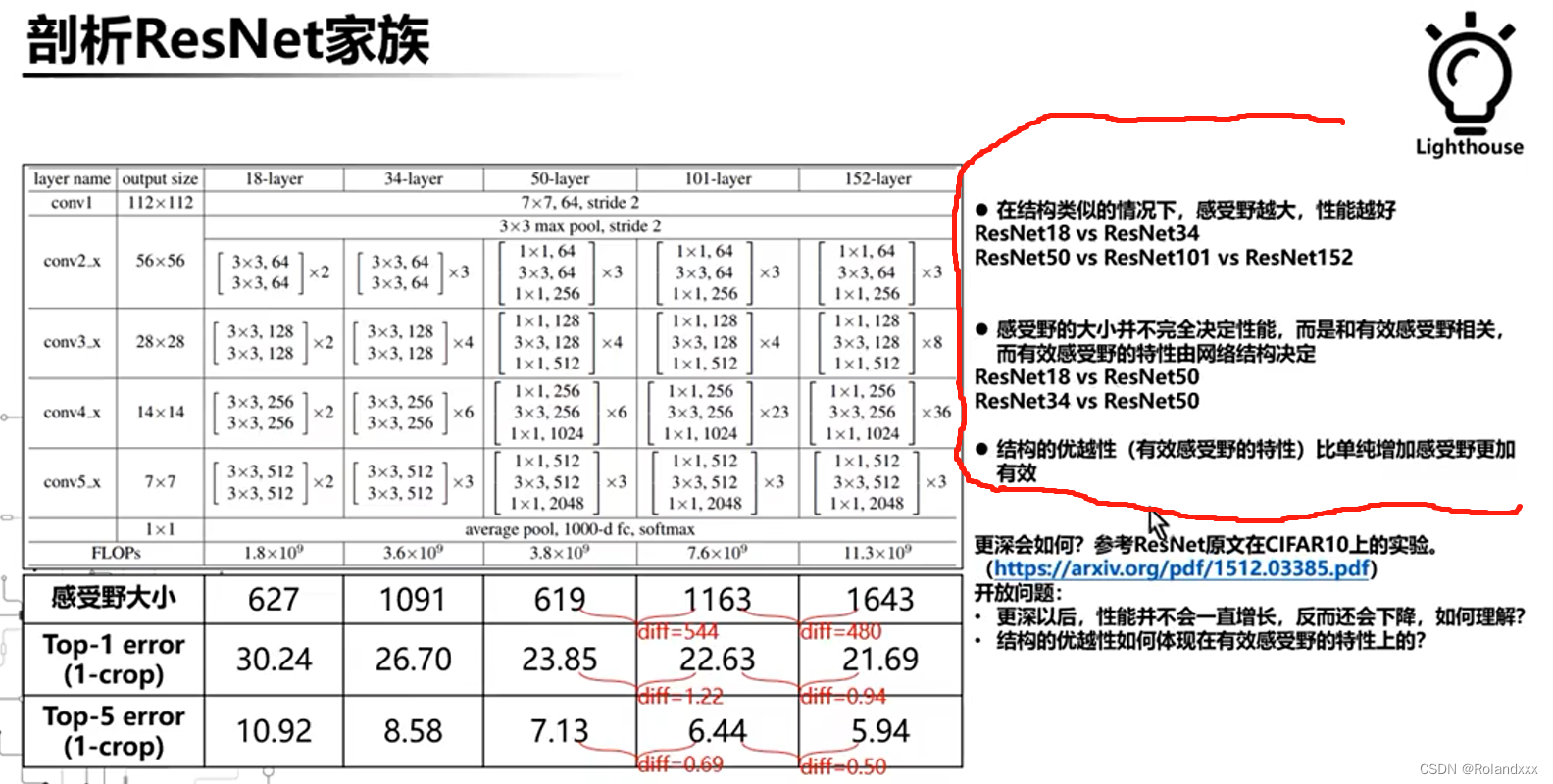
八、感受野如何影响检测网络:
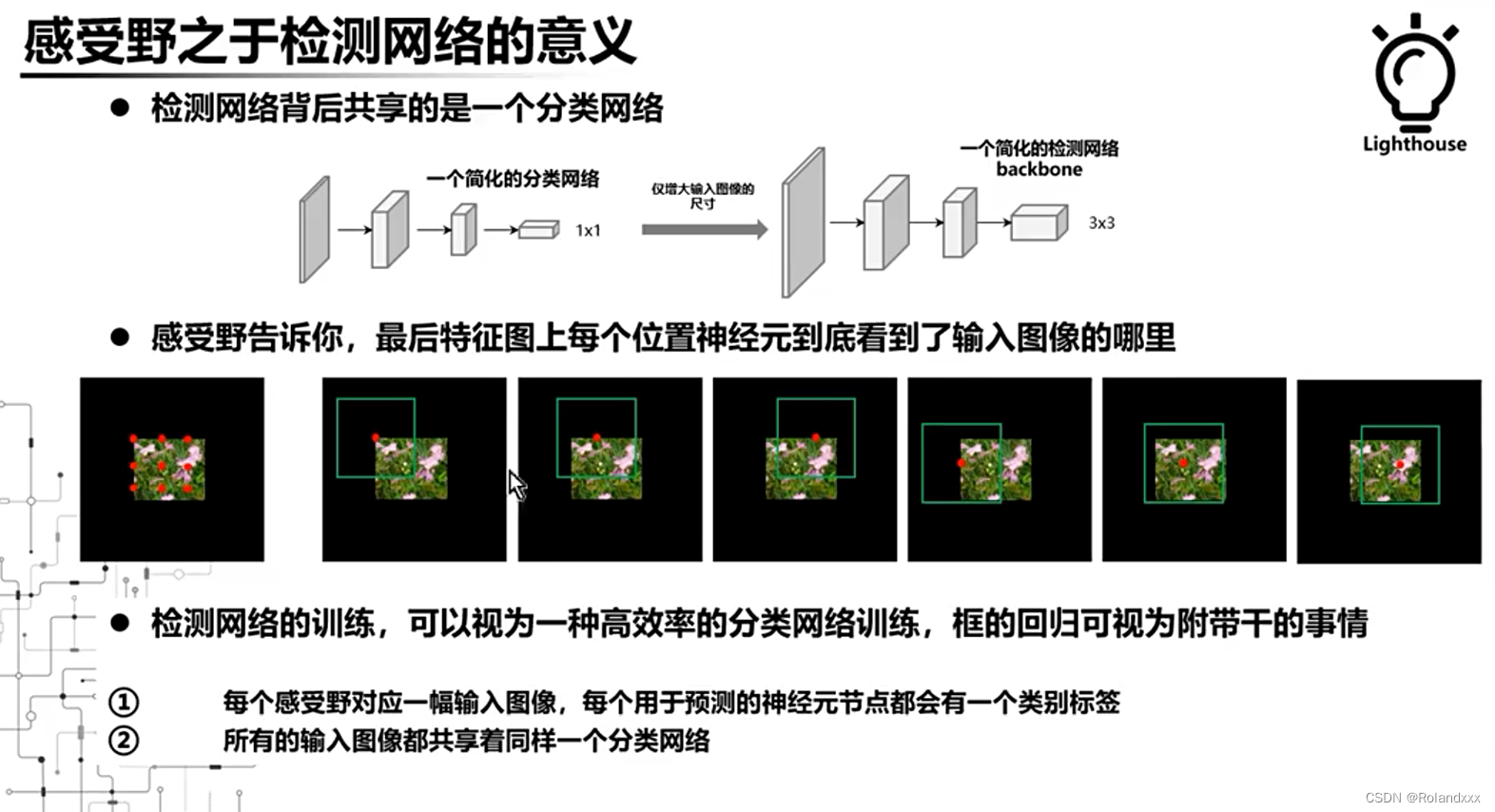
所谓的检测网络背后就是一个分类网络而已,并没有什么神奇的地方,检测任务是一个典型的多任务学习:分类+回归,为什么这么说呢?接下来告诉你答案。如下图是一个全卷积网络,输入图像分辨率的改变会导致输出的分辨率有所改变,比如下图右边的部分最后的特征图出来是3×3的。然后检测网络会在输出层上做预测,这个时候就需要同时给出3×3,也就是9个类别标签,也就是要同时预测9幅图像的标签,那这个9幅图像到底是哪9幅图像呢?结合之前的感受野的介绍和计算,来看下图中间的图示,最左边表示的是3×3的特征图上每个位置在原图的感受野中心,这里由红点表示。右边六幅图就分别对应了这3×3位置前两行的感受野信息,这里由绿色的框表示,所以这9幅图像也就是这个九个感受野区域!其实对于检测网络网络的训练可以视为一种高效的分类网络训练,因为一个检测的样本一次可以产生非常多分类的样本,每个分类样本就是感受野对应的图像区域,框的回归其实被当做一件附带的事情给干了,因为无论是one-stage还是two-stage的方法,框的预测都是和类别无关的!也就是大多数只会使用4个feature map,并没有类别信息。
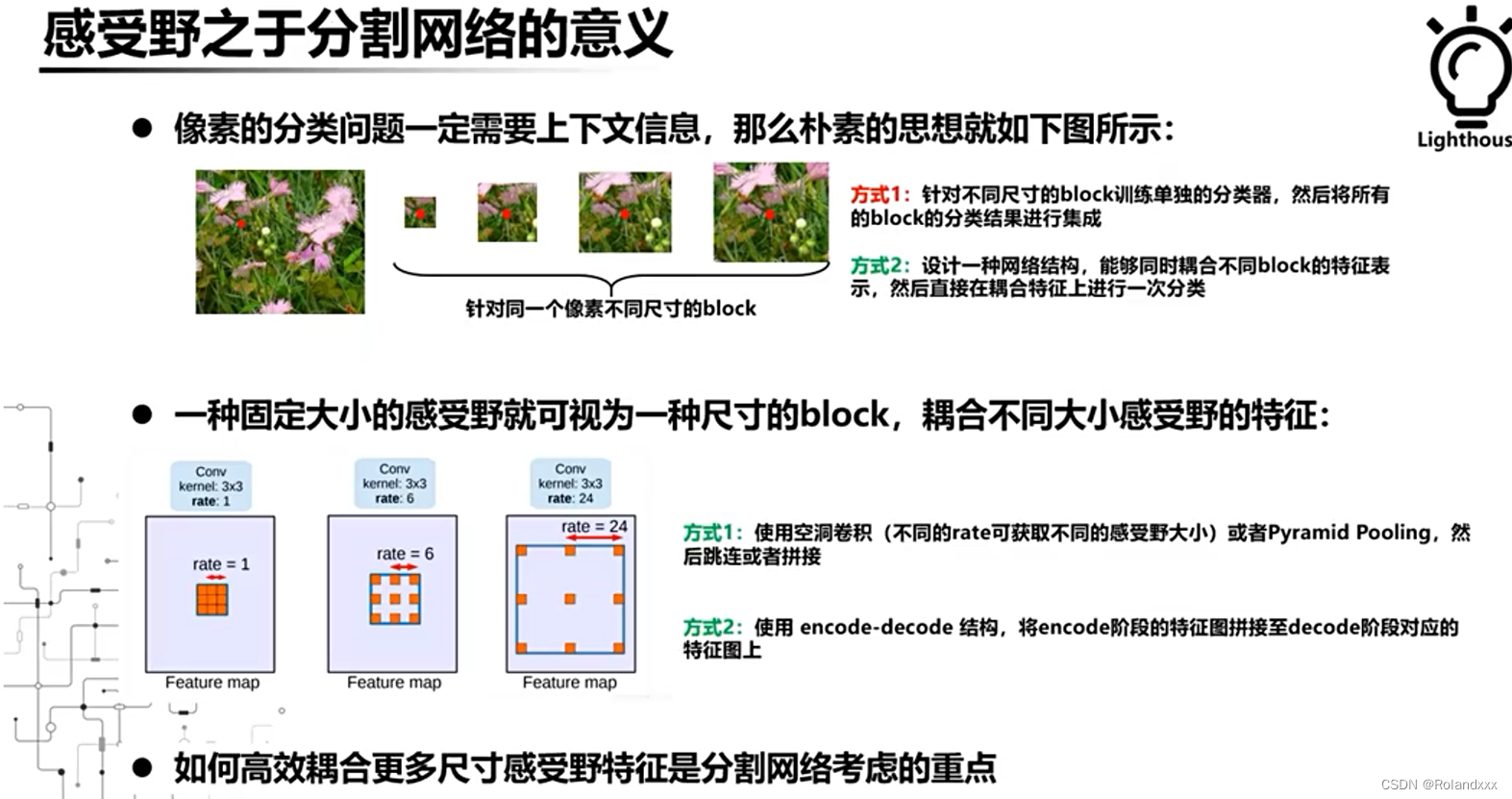
九、感受野如何影响分割网络:
假设不了解任何语义分割的前提下,如果让我们自己设计去做语义分割,我们会怎么做呢?因为语义分割就是像素级的分类任务,一个非常直观的想法就是如下图的上部分图示,以某个待分类的像素为中心,裁切若干尺寸不同的block,然后把每种尺寸的block进行分类,最后将分类结果进行集成得到这个像素的类别,但这种方法推理时十分耗时。那么有没有一种方法能够同时耦合多种block的特征,然后只进行一次分类呢?这样一来效率就会高非常多。不难想到,所谓的block其实就是感受野呀!那么其实就变成了如何去耦合不同大小感受野的特征(耦合就是指让这些感受野不同的特征图结合到一起,那么通过add或者concat其实都行)。所以得出了一个结论就是如何高效耦合更多尺寸感受野特征是分割网络考虑的重点
总结
数据集里不同类别对感受野要求不一致,感受野不是越大越好,也不是越小越好,比如感受野增大会提升大目标的性能,但过大反而会拉低大目标性能提升小目标性能,所以要实际考虑到物体的size。所以CV领域,笔者认为调参是门学问,是经验的累积,它需要依靠理论的支撑,而不是纯靠运气炼丹。拿检测任务举例,调参的目的是用来权衡所有类别的最好值。


















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









