







一、Spark环境变量
1、Spark环境配置(通过spark-env.sh设置)
①与集群管理器无关的变量
| 环境变量 | 说明 |
|---|---|
| SPARK_HOME | Spark安装路径的根目录 |
| JAVA_HOME | Java安装的位置 |
| PYSPARK_PYTHON | 供PySpark的驱动器和工作节点上的执行器使用的Python二进制可执行文件。 |
| PYSPARK_DRIVER_PYTHON | 供PySpark的驱动器使用的Python二进制可执行文件。 |
| SPARKR_DRIVER_R | 供SparkR shell使用的R的二进制可执行文件。 |
②与Hadoop相关的环境变量
| 环境变量 | 说明 |
|---|---|
| HADOOP_CONF_DIR或YARN_CONF_DIR | Hadoop配置文件的位置。Spark使用这个路径寻找默认的文件系统和YARN资源管理器的地址。 |
| HADOOP_HOME | Hadoop安装路径。Spark使用这个环境变量寻找Hadoop配置文件。 |
| HIVE_CONF_DIR | Hive配置文件的位置。 |
③YARN专用的环境变量
| 环境变量 | 说明 |
|---|---|
| SPARK_EXECUTOR_INSTANCES | 要在YARN集群上启动的Spark执行器的数量。默认为2。 |
| SPARK_EXECUTOR_CORES | 为每个执行器分配的CPU核心数。默认为1。 |
| SPARK_EXECUTOR_MEMORY | 为每个执行器分配的内存。默认为1GB。 |
| SPARK_DRIVER_MEMORY | 在以集群部署模式运行时,分配给驱动器进程的内存。默认为1GB。 |
| SPARK_YARN_APP_NAME | 应用的名字。用于在YARN资源管理器用户界面中展示。 |
| SPARK_YARN_QUEUE | 默认把应用提交到YARN队列的位置。默认为default。 |
④以集群模式部署应用时相关的环境变量
| 环境变量 | 说明 |
|---|---|
| SPARK_LOCAL_IP | 用于在机器上绑定Spark进程的本地IP地址。 |
| SPARK_PUBLIC_DNS | Spark驱动器用于告知其他主机的主机名。 |
| SPARK_CLASSPATH | Spark默认的类路径。若要引入没有和Spark打包在一起的类,在运行时使用,需设置这个变量。 |
| SPARK_LOCAL_DIRS | 系统中用于RDD存储和混洗数据的路径。 |
⑤用于Spark独立集群守护进程的环境变量
| 环境变量 | 说明 |
|---|---|
| SPARK_MASTER_IP | 运行Spark主进程的主机名或IP地址。Spark集群的所有节点和任意用来提交应用的客户端都需要设置。 |
| SPARK_MASTER_PORT和SPARK_MASTER_WEBUI_PORT | 分别用于IPC通信和主进程网络用户界面的端口号。默认分别为7077和8080。 |
| SPARK_MASTER_OPTS和SPARK_WORKER_OPTS | 托管Spark主进程和工作节点进程的JVM使用的额外的Java选项。 |
| SPARK_DAEMON_MEMORY | 给主进程、工作节点进程,以及历史服务器进程分配的内存量。默认为1GB。 |
| SPARK_WORKER_INSTANCES | 每个从节点上启动的工作节点守护进程数。默认为1。 |
| SPARK_WORKER_CORES | Spark工作节点进程用来分配给执行器的CPU总核心数。 |
| SPARK_WORKER_MEMORY | 工作节点用来分配给执行器的内存总量。 |
| SPARK_WORKER_PORT和SPARK_WORKER_WEBUI_PORT | 分别用于IPC通信和工作节点网络用户界面的端口号。用户界面默认使用8081端口,而工作节点通信会使用随机端口。 |
| SPARK_WORKER_DIR | 设置工作节点进程的工作路径。 |
二、Spark配置属性
1、常见的Spark配置属性
| 属性 | 说明 |
|---|---|
| spark.master | Spark主进程的地址(独立集群为spark://hostname:7077;若为yarn,则读取Hadoop配置文件来定位YARN的ResourceManager) |
| spark.driver.memory | 分配给驱动器进程的内存量。默认为1G。 |
| spark.executor.memory | 每个执行器进程使用的内存量。默认为1G。 |
| spark.executor.cores | 每个执行器使用的核心数。在独立模式下默认使用工作节点上所有可用的CPU核心。在YARN模式下默认使用1个核心。 |
| spark.driver.extraJavaOptions和spark.executor.extraJavaOptions | 托管Spark驱动器和执行器进程的JVM使用的额外的Java选项。 |
| spark.driver.extraClassPath和spark.executor.extraClassPath | 如果要使用或引入没有打包的其他类,需要设置该驱动器和执行器所需的额外的类路径入口。 |
| spark.dynamicAllocation.enabled和spark.shuffle.service.enabled | 共同使用这两个属性可以改变Spark的默认调度行为。 |
2、设置Spark配置属性
①通过/spark/conf/spark-defaults.conf文件进行配置
spark.master yarn
spark.eventLog.enabled true(是否记录spark事件)
spark.eventLog.dir #记录spark事件的目录
spark.history.fs.logDirectory #用于为历史记录程序提供文件系统
spark.executor.memory 2048M
spark.executor.cores 4
②通过在驱动器程序代码中使用SparkConf对象设置
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
conf = SparkConf()
conf.set(“spark.executor.memory”,”3g”)
sc = SparkContext(conf=conf)
③通过spark-shell、pyspark和spark-submit的命令参数设置
| 参数 | 配置属性 | 属性环境变量 |
|---|---|---|
| –master | spark.master | SPARK_MASTER_IP或SPARK_MASTER_PORT |
| –name | spark.app.name | SPARK_YARN_APP_NAME |
| –queue | spark.yarn.queue | SPARK_YARN_QUEUE |
| –executor-memory | spark.executor.memory | SPARK_EXECUTOR_MEMORY |
| –executor-cores | spark.executor.cores | SPARK_EXECUTOR_CORES |
3、Spark配置的优先级
(通过在驱动器程序代码中使用SparkConf对象设置) > (通过spark-shell、pyspark和spark-submit的命令参数设置) > (通过/spark/conf/spark-defaults.conf文件进行配置)
4、通常情况下,不同主机应该使用一致的配置设置。
三、Spark优化
1、早过滤、勤过滤
在应用中今早过滤不需要的记录或字段可能带来显著的性能提升。在有操作(如:reduceByKey、groupByKey)引起数据混洗之前执行过滤操作,join()操作的前后都要过滤。
2、优化满足结合律的操作
在分布式分区的数据集上,满足结合律的键值对操作经常会引起数据混洗。在使用groupByKey()和reduceByKey()执行sum()或count()操作时,若在分布式分区的数据集上把数据根据键进行分组仅仅视为了根据键聚合结果,那么使用reduceByKey一般会更好。
reduceByKey()在任何必需的数据混洗之前就直接把值按照对应的键进行组合,因此减少了通过网络传输的数据量,也减少了下一阶段的计算量和内存需求。
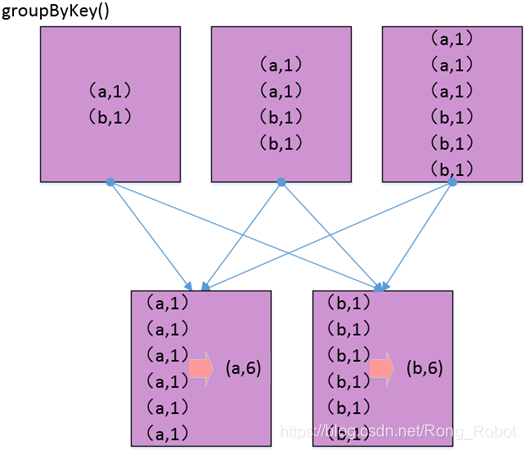
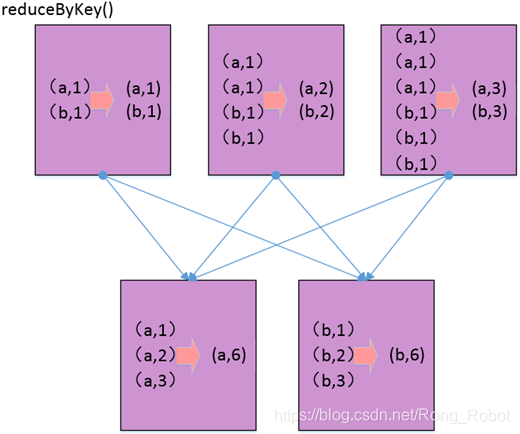
3、理解函数和闭包的影响
函数会被发到Spark集群的执行器里,并且附带所有的绑定变量和自由变量。这个过程提供了高效无共享的分布式处理,但是这也可能同时造成一些影响性能和稳定性的问题。
4、收集数据的注意事项
在执行collect()时,RDD中所有的结果记录都会从执行谱系最后任务的执行器返回到驱动器进程中。对于大规模数据集来说,这会导致不必要的网络传输,而如果驱动器所在主机没有足够的内存来存放收集到的对象,会导致发生异常。
如果只是想查看输出数据,使用take()和takeSample()更好。如果非必要,不要把过多的数据带回驱动器进程。
5、使用配置参数调节和优化应用
①优化并行度
spark.default.parallelism在应用层面或使用spark-default.conf设置的配置参数。该设置指定了reduceByKey()、join()和parallelize()这样的转化操作返回的RDD在没有提供numPartitions参数时使用的默认分区数(建议将该值设置为等于或双倍于工作节点核心数的总数)。
②动态分配
Spark默认运行时的行为是,在应用的整个生命周期中始终占用所申请的执行器。如果一个应用长时间运行,那么这种行为就不是很合适。使用动态分配时,如果执行器空闲达到一定时长,就被被释放回集群的资源池。动态分配作为系统配置实现,利于最大化利用系统资源。
6、避免低效的分区
①小文件导致过多的小分区
小分区,就是所含数据量较小的数据分区,是低效的,因为这会导致很多小任务出现。生成这些任务的开销甚至超过执行这些任务所需要的处理开销。
②避免出现特别大的分区
因为不可切分的压缩文件没有索引且不可切分,整个文件必须在一个执行器中处理。如果解压出的数据大小超出了执行器可用的内存量,该分区就会溢写到硬盘上。
解决:①尽量避免使用不支持切分的压缩;②在本地解压每个文件,然后再把文件加载到RDD中;③在对RDD进行第一个转化操作后马上执行重新分区。
另外,自定义的分区函数进行混洗操作也可能导致大分区出现。
解决:在大规模数据混洗之前先对数据进行重新分区。
③选择合适的分区数量或大小
7、应用性能问题诊断
①使用应用的用户界面诊断性能问题
应用的用户界面在运行着驱动器程序主机的4040端口上提供服务(多个应用,端口号顺延)。在YARN集群中,应用的用户界面可通过YARN的ResourceMananger用户界面上的ApplicationMaster链接进行访问。
②数据混洗与任务执行的性能
应用由一个或者多个作业组成,而作业由一个行动操作产生。作业由一个或多个阶段组成,而阶段由一个或多个任务组成。一个任务操作RDD的一个分区。(http://master:4040)
Stages(阶段汇总信息)>>Completed Stages(已完成阶段)>>Description(说明)
③数据收集的性能
如果程序中有数据收集阶段,那么Spark应用的用户界面上会显示摘要和详细信息的性能信息。
④使用Spark历史界面诊断性能问题
应用的用户界面(位于端口404X)只在应用尚未结束时可以访问,因此用它诊断正在运行的应用的问题较为方便。Spark历史服务器的用户界面,一般在历史服务器进程所在主机的18080端口上提供服务。














 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









