






一.引言
本文聚焦模型实战应用,简要阐述模型原理并提供一套完整的支持向量回归(SVR)建模解决方案,包含数据预处理、模型调参、可视化分析全流程代码。支持向量机回归(SVR)凭借其在小样本、高维度数据中的优异表现,成为参赛者的重要工具。本文以洪水概率预测为例,手把手教你搭建完整的 SVR 建模流程,并附可复现代码,助力竞赛实战!
二、SVR 核心原理
2.1 什么是支持向量机?
核心思想:通过核函数将低维非线性数据映射到高维空间,寻找最优超平面使样本点到平面的误差最小化
独特优势:
适合小样本场景(竞赛数据常受限于标注成本)
天然支持高维特征(无需复杂特征筛选)
内置正则化(通过参数 C 控制过拟合)
2.2 什么是支持向量机回归?
支持向量机回归(Support Vector Regression, SVR)是支持向量机(SVM)在回归问题中的扩展,其核心原理是通过引入 “ε- 不敏感损失函数” 和结构风险最小化原则,在允许一定误差的范围内寻找最优回归超平面,从而平衡模型拟合能力与泛化能力。SVR(支持向量机回归)核心原理可简化为三点:
1.ε- 不敏感带
在回归超平面两侧创建宽度为 2ε 的 “容错区”,带内样本不产生损失,仅关注带外样本(支持向量)。
2.核技巧
通过核函数隐式映射数据到高维空间,使模型能处理非线性关系,避免显式计算高维特征。
3.结构风险最小化
通过参数 C 平衡模型复杂度(超平面平坦度)与误差容忍度,防止过拟合。
本质:用支持向量定义最优超平面,仅少数样本决定模型,兼具泛化能力与非线性处理能力。
三.完整建模流程
本案例数据采用2024年第十四届 APMCM 亚太地区大学生数学建模竞赛B 题,超一百万条的洪水数据。从自然因素,人为因素,管理与基础设施因素及其他因素这四个方面出发,共研究季风强度等20个变量对发生洪水概率的影响。
3.1 环境配置:
首先,如果你还没有安装scikit-learn库的话使用pip一键安装:
pip install scikit-learn
如果安装过程速度较慢可以添加清华源加快安装速度:
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
3.2 数据预处理模块(关键步骤解析)
在数据分析流程中,数据预处理扮演着至关重要的角色。本次针对具有特定特性的洪水数据集,采用了一系列关键的预处理步骤,包括特征工程、中位数填充、数据降维以及标准化处理。鉴于该数据集规模庞大,特别引入了随机抽样方法来降低数据维度,这一举措旨在快速验证代码的可行性(待验证完成后可将其注释掉)。后续运用 train_test_split() 函数对数据集进行划分,形成训练集与测试集。最终采用 StandardScaler 进行标准化处理,其核心目标在于通过缩放特征,使不同特征的分布具有相同的量纲,即有效消除量纲差异所带来的影响,进而显著提升模型的训练效果以及收敛速度。
def preprocess_data(df):
# 1. 基础清洗:移除ID列(非特征变量)
df = df.drop(columns=['id'], errors='ignore')
# 2. 特征工程:明确业务相关特征
features = [
'淤积', '人口得分', '湿地损失', '河流管理', '大坝质量', '流域',
'农业实践', '无效防灾', '森林砍伐', '滑坡', '基础设施恶化',
'季风强度', '地形排水', '气候变化', '政策因素', '城市化', '规划不足', '排水系统', '侵蚀', '海岸脆弱性'
]
target = '洪水概率' # 明确预测目标
# 3. 缺失值处理:中位数填充(稳健性优于均值)
df[features] = df[features].fillna(df[features].median())
# 4. 数据降维:竞赛中常用的样本控制策略
n = 20 # 控制样本量在合理范围
df = df.sample(n=n, random_state=42) if len(df)>n else df
# 5. 标准化:SVM对特征尺度敏感(必做步骤)
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target], test_size=0.1, random_state=42
)
scaler = StandardScaler().fit(X_train)
return scaler.transform(X_train), scaler.transform(X_test), y_train, y_test, features
3.2 模型构建与参数调优
推荐初始化核心参数如下:
1. C=0.1(正则化参数)
控制模型对训练误差的容忍度,平衡模型拟合能力与复杂度。 该参数值越小:允许更多训练误差,模型更简单(防止过拟合)。 值越大:强制模型严格拟合训练数据,可能导致过拟合(对异常值更敏感)。 数据存在噪声或希望模型泛化性强时,可适当减小 C(如当前设为 0.1)。
2. kernel=‘rbf’(核函数类型)
将低维非线性数据映射到高维空间,使其线性可分(处理非线性问题)。
常见类型:
- ‘linear’:线性核(适用于线性关系数据)。
- ‘rbf’(径向基函数):默认核,适合非线性、数据分布复杂的场景(代码中使用)。
- ‘poly’:多项式核(用于拟合多项式关系)。
- ‘sigmoid’:适用于类似神经网络的非线性映射。
3. gamma=‘scale’(核函数系数)
控制核函数的“作用范围”,仅在 kernel=‘rbf’/‘poly’/‘sigmoid’时有效。 当前设置’scale’` 自动适配特征尺度,避免手动调参。
当前配置适用于 非线性回归问题,通过rbf 核处理非线性关系,C=0.1平衡拟合与泛化gamma=‘scale’` 自动适配特征尺度。
# 初始化模型
best_model = SVR(
C=0.1, # 正则化参数(防止过拟合)
kernel='rbf', # 常用核函数(处理非线性关系)
gamma='scale',# 核函数系数(自动适配特征尺度)
).fit(X_train, y_train)
# 进阶:网格搜索调参(建议竞赛后期使用)
# param_grid = {'C': [0.1, 1, 10], 'gamma': ['scale', 'auto']}
# grid_search = GridSearchCV(SVR(kernel='rbf'), param_grid, cv=5)
# grid_search.fit(X_train, y_train)
# best_model = grid_search.best_estimator_
3.3 模型评估:可视化验证
1.常用的回归评估指标:
R²(决定系数):越接近 1,模型拟合越好
均方误差(MSE):值越小,预测误差越小
2.模型可视化评估:
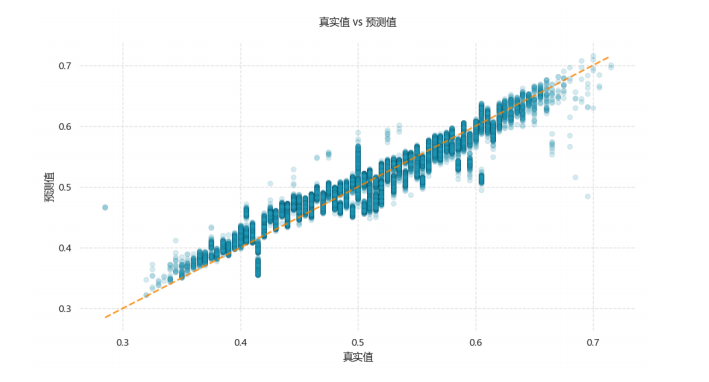
为更直观地展示模型预测效果,绘制了预测值与真实值的对比图。图表标题为 “真实值 vs 预测值”,横轴表示样本的 真实值,纵轴表示模型的 预测值。
橙色对角线: 代表理想状态下 y = x的完美预测线。若预测完全准确,所有样本点应紧密分布在这条线上。
蓝色点: 每个点对应一个样本的真实值与预测值。点越靠近橙色对角线,说明模型对该样本的预测越精准;点越偏离对角线,预测误差越大。
def evaluate_model(model, X_test, y_test, use_hexbin=False):
y_pred = model.predict(X_test)
# 计算指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"测试集均方误差 (MSE): {mse:.4f}")
print(f"决定系数 (R²): {r2:.4f}")
# 可视化预测结果
plt.figure(figsize=(10, 6), dpi=100)
if use_hexbin:
plt.hexbin(y_test, y_pred, gridsize=50, cmap='Blues', mincnt=1)
plt.colorbar(label='密度')
else:
ax = sns.scatterplot(
x=y_test,
y=y_pred,
alpha=0.2, # 降低透明度
color=light_blue_palette[1],
edgecolor=light_blue_palette[2],
linewidth=0.3
)
plt.plot(
[y_test.min(), y_test.max()],
[y_test.min(), y_test.max()],
'--',
color=light_blue_palette[4],
linewidth=2,
alpha=0.8
)
ax.set(xlabel='真实值', ylabel='预测值', title='真实值 vs 预测值')
ax.grid(visible=True, which='major', linestyle='--', alpha=0.6)
sns.despine(left=True, bottom=True)
plt.tight_layout()
plt.show()
return y_pred
3.4完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV, KFold, cross_val_score as CVS
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.svm import SVR
import matplotlib.pyplot as plt
import shap
import seaborn as sns
# 加载数据(替换成你自己的数据集路径)
df = pd.read_excel('./train_data_original.xlsx')
# ======================
# 数据预处理(根据不同任务做出相应的改变)
# ======================
def preprocess_data(df):
# 移除ID列
df = df.drop(columns=['id'], errors='ignore')
# 定义特征和目标变量
features = [
'淤积', '人口得分', '湿地损失', '河流管理', '大坝质量', '流域',
'农业实践', '无效防灾', '森林砍伐', '滑坡', '基础设施恶化',
'季风强度', '地形排水', '气候变化', '政策因素', '城市化', '规划不足', '排水系统', '侵蚀', '海岸脆弱性'
]
target = '洪水概率'
# 处理缺失值(使用中位数填充)
df[features] = df[features].fillna(df[features].median())
# 3. 随机采样(控制数据规模)
# n = 200000
# if len(df) > n:
# df = df.sample(n=n, random_state=42)
# print(f"数据量超过{n},已随机采样{n}行数据")
# else:
# print(f"数据量为{len(df)},未进行采样")
# 划分训练测试集(先于标准化)
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target],
test_size=0.1,
random_state=42
)
# 标准化特征(仅在训练集上拟合)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
return X_train_scaled, X_test_scaled, y_train, y_test, features
# 执行预处理
X_train, X_test, y_train, y_test, feature_names = preprocess_data(df)
best_model = SVR(C=0.1, kernel='rbf', gamma='scale').fit(X_train, y_train)
# ======================
# 模型评估
# ======================
# 全局样式设置
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 使用微软雅黑
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示
plt.rcParams['axes.labelsize'] = 12 # 轴标签字号
plt.rcParams['axes.titlesize'] = 14 # 标题字号
# 自定义浅蓝色调色板
light_blue_palette = ["#8ECAE6", "#219EBC", "#023047", "#FFB703", "#FB8500"]
sns.set_theme(
style="whitegrid",
palette=sns.color_palette(light_blue_palette),
font="Microsoft YaHei",
rc={'axes.titlepad': 20} # 标题间距
)
def evaluate_model(model, X_test, y_test, use_hexbin=False):
y_pred = model.predict(X_test)
# 计算指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"测试集均方误差 (MSE): {mse:.4f}")
print(f"决定系数 (R²): {r2:.4f}")
# 可视化预测结果
plt.figure(figsize=(10, 6), dpi=100)
if use_hexbin:
plt.hexbin(y_test, y_pred, gridsize=50, cmap='Blues', mincnt=1)
plt.colorbar(label='密度')
else:
ax = sns.scatterplot(
x=y_test,
y=y_pred,
alpha=0.2, # 降低透明度
color=light_blue_palette[1],
edgecolor=light_blue_palette[2],
linewidth=0.3
)
plt.plot(
[y_test.min(), y_test.max()],
[y_test.min(), y_test.max()],
'--',
color=light_blue_palette[4],
linewidth=2,
alpha=0.8
)
ax.set(xlabel='真实值', ylabel='预测值', title='真实值 vs 预测值')
ax.grid(visible=True, which='major', linestyle='--', alpha=0.6)
sns.despine(left=True, bottom=True)
plt.tight_layout()
plt.show()
# 计算预测值的累积分布函数
sorted_preds = np.sort(y_pred)
cdf = np.arange(1, len(sorted_preds) + 1) / len(sorted_preds)
# 绘制预测值的累积分布函数曲线
plt.figure(figsize=(10, 6), dpi=100)
plt.plot(sorted_preds, cdf, color=light_blue_palette[2])
plt.title("预测值的累积分布函数曲线")
plt.xlabel("预测值")
plt.ylabel("累积比例")
plt.tight_layout()
plt.show()
return y_pred
# 执行评估
y_pred = evaluate_model(best_model, X_test, y_test)
注: 在实际的预测任务中,务必将数据路径替换为您自有数据集的具体路径。同时,需严格依据实际数据特征重新定义特征变量与目标变量。
四. 总结
在上一期的分享中,我们深入探讨了 XGBoost 在预测领域的应用,为大家呈现了机器学习模型在相关任务中的应用流程。本期内容将延续这一技术探索思路,转而聚焦支持向量机回归(SVR)在预测任务中的复杂应用实践。
此外,对于 XGBoost 的应用拓展,我们也鼓励感兴趣的朋友大胆尝试——利用 XGBoost 开展洪水发生概率的预测实验,这不仅是对模型泛化能力的检验,更是将技术与实际场景结合的有益探索。 同时若发现一些地方不足,欢迎各位前辈和小伙伴们批评指正。希望这些笔记能为大家提供一些启发,咱们一起在实战中少走弯路,快速成长!


















 2686
2686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











