






一.引言
在许多数模比赛中,预测类问题(如趋势预测、能耗预测、成绩分析等)是高频考点。传统回归算法(如线性回归、随机森林)虽易上手,但在处理高维数据、非线性关系时往往精度不足,且调参复杂。而 XGBoost(极端梯度提升树) 作为集成学习领域的 “明星模型”,凭借高效的训练速度、优异的泛化能力和简洁的代码实现,成为解决预测问题的 “利器”。本文聚焦实战应用,无需深入原理,手把手带你用 XGBoost 快速搭建高精度预测模型。接下来我会详细介绍应用过程:
二.快速入门:5分钟上手XGBoost
2.1 环境配置:用pip一键安装
pip install xgboost
2.2 数据集划分
首先加载数据(以糖尿病数据集为例),并划分训练集与测试集:
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
# 加载数据集(换成你自己的数据集)
data = load_diabetes()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target # 目标变量:糖尿病病情进展
# 划分特征与标签
features = df.columns[:-1] # 所有特征列
target = 'target' # 目标变量列名
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target],
test_size=0.2,
random_state=42
)
2.3 模型训练与预测
使用 XGBoost 的 sklearn 接口,无需复杂配置即可快速建模:
from xgboost import XGBRegressor as XGBR
# 初始化模型(使用默认参数快速验证效果)
reg = XGBR(n_estimators=100, random_state=42) # n_estimators:树的数量
# 训练模型
reg.fit(X_train, y_train)
# 预测测试集
y_pred = reg.predict(X_test)
2.4 模型评估:量化预测效果
常用的回归评估指标:
R²(决定系数):越接近 1,模型拟合越好
均方误差(MSE):值越小,预测误差越小
from sklearn.metrics import r2_score, mean_squared_error
# R²评分(1为完美预测)
r2 = r2_score(y_test, y_pred)
print(f"R² Score: {r2:.4f}")
# 均方误差(MSE,值越小越好)
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.4f}")
三.进阶技巧:提升模型性能的实战经验
3.1 交叉验证:避免过拟合
使用 K 折交叉验证 评估模型稳定性,替代单次划分数据的随机性:
from sklearn.model_selection import cross_val_score
# 5折交叉验证,计算平均R²
cv_scores = cross_val_score(reg, X_train, y_train, cv=5, scoring='r2')
print(f"Cross-validated R²: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
K折交叉验证将数据集均分为K个子集,每次用K-1个子集训练模型、1个子集验证,重复K次后取性能指标的平均值。这种方法通过多角度验证减少随机划分的偏差,提升数据利用率,能更稳定地评估模型泛化能力,尤其适合小数据集场景。
3.2 学习曲线调优
XGBoost 提供丰富参数调整模型复杂度,推荐优先调整以下核心参数:
n_estimators:树的数量(默认 100,过大易过拟合,需配合learning_rate)
learning_rate:学习率(默认 0.3,越小越稳定,通常设为 0.01-0.3)
max_depth:树的最大深度(默认 6,控制模型复杂度,避免过拟合)
subsample:样本子采样率(默认 1,设为 0.5-1 降低方差)
下面我们以参数learning_rate为例通过学习曲线调优:
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
from xgboost import XGBRegressor as XGBR
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
# 加载糖尿病数据集
data = load_diabetes()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target # 目标变量:糖尿病病情进展
# 划分特征与标签
features = df.columns[:-1] # 所有特征列
target = 'target' # 目标变量列名
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target],
test_size=0.2,
random_state=42
)
# 定义参数搜索范围
learning_rates = [0.001, 0.005, 0.01, 0.02, 0.03]
scores = []
for lr in learning_rates:
reg = XGBR(n_estimators=200, learning_rate=lr, random_state=42)
score = cross_val_score(reg, X_train, y_train, cv=5, scoring='r2').mean()
scores.append(score)
# 可视化参数效果
plt.plot(learning_rates, scores, marker='o')
plt.xlabel("Learning Rate")
plt.ylabel("Cross-validated R²")
plt.title("Learning Rate Tuning")
plt.show()
# 找出最佳学习率
best_lr = learning_rates[scores.index(max(scores))]
print(f"Best learning rate: {best_lr}")
注: 参数learning_rate学习曲线可视化可以清晰直观找出参数最优值或范围
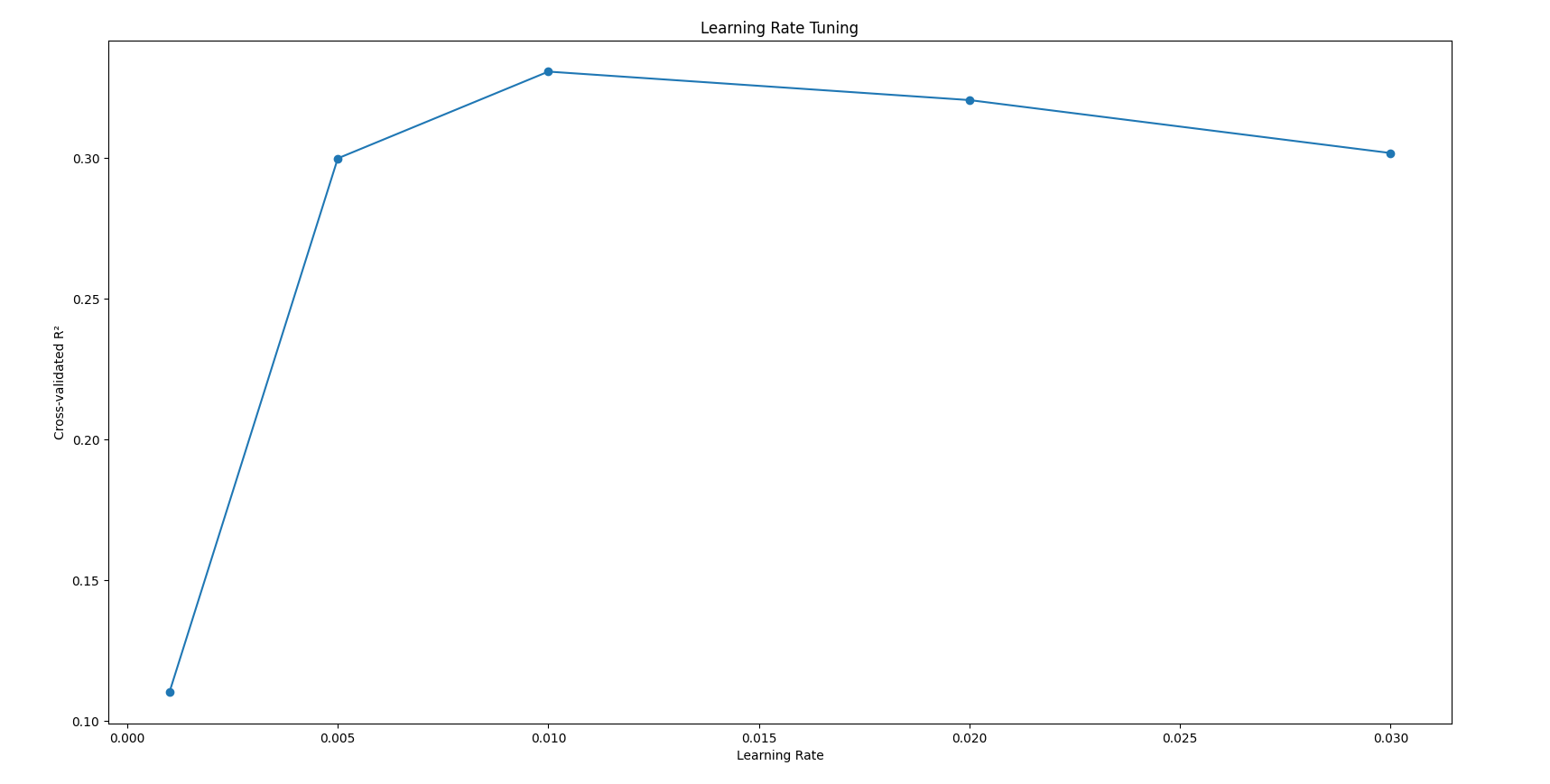
学习曲线调优 通常针对单一参数:固定其他参数,让目标参数在合理区间变化,通过绘制模型性能曲线(如得分、方差)定位最优值,适合单个参数的精细调节,实践中可按“核心参数→正则化参数”顺序依次调优。
多参数调优时,学习曲线法因参数组合爆炸导致效率低下,此时推荐使用贝叶斯优化等自动化方法——其通过智能采样策略,能用更少训练次数搜索到更优参数组合,适合复杂场景。相关高级调优技术后续结合实战详解。
3.3 完整代码
将学习曲线调优后的参数带入模型训练(代码中的参数并不是最优参数):
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
from xgboost import XGBRegressor as XGBR
from sklearn.model_selection import cross_val_score
# 加载糖尿病数据集
data = load_diabetes()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target # 目标变量:糖尿病病情进展
# 划分特征与标签
features = df.columns[:-1] # 所有特征列
target = 'target' # 目标变量列名
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
df[features], df[target],
test_size=0.2,
random_state=42
)
# 使用最优参数
reg = XGBR(n_estimators=100, learning_rate=0.002, random_state=42)
# 5折交叉验证,计算平均R²
cv_scores = cross_val_score(reg, X_train, y_train, cv=5, scoring='r2')
print(f"Cross-validated R²: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
# 训练模型
reg.fit(X_train, y_train)
# 预测测试集
y_pred = reg.predict(X_test)
# R²评分(1为完美预测)
r2 = r2_score(y_test, y_pred)
print(f"R² Score: {r2:.4f}")
# 均方误差(MSE,值越小越好)
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.4f}")
注:在实战中数据预处理步骤非常有必要,可根据数据集情况进行处理。交叉验证的目的是在不使用测试集的情况下,对模型在训练集上的泛化能力进行评估,从而为模型的参数调整和性能评估提供依据。如果在模型训练(fit)之后再进行交叉验证,就失去了其意义,因为此时模型已经在整个训练集上进行了学习,交叉验证就无法真实反映模型在未见过数据上的表现。
四.总结
这是我的第一篇博客,很高兴能和大家分享我的数模参赛经历与实战经验!若有不足,欢迎各位前辈和小伙伴们批评指正~
我将自己在赛场上积累的技巧整理成了系列笔记,后续会持续分享机器学习、深度学习模型在数模比赛中的实用解法。这里不纠结复杂原理,只聚焦实战干货——从数据处理到模型调优,从代码实现到结果分析,每一篇都力求“短平快”,让你直接上手能用的技巧!
无论你是刚开始接触数模的新手,还是想优化现有方案的备赛选手,都能在这里找到可复用的思路。希望这些笔记能为即将踏上赛场的学弟学妹们提供一些启发,咱们一起在实战中少走弯路,快速成长!

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









