






目录
一、背景及内容概括
目前的多保真数据融合方法与期望的方法之间仍然存在差距,因为基于插值的模型通常是在对多保真数据进行特定假设的情况下建立的。另一方面,基于学习的模型的训练通常需要相当数量的HF样本才能达到期望的建模精度。尤其是在高维场景中,由于需要确定的权重更多,对HF样本量的要求更高。
本文提出了一个生成对抗网络的多保真数据融合问题(GAN-MDF),其中它的生成器产生的高保真数据的近似;它的鉴别器将识别生成器输出是否为真实的高保真数据。
另外,本文引入监督损失技巧,通过在每次迭代中改进生成器的权值来提高GAN-MDF训练的稳定性。与现有的方法相比,本文提出的GAN-MDF具有以下优点:
(a)、低保真和高保真响应之间的相关性没有特别的要求。
(b)、即使在高保真训练样本很少的情况下,它也具有较高的鲁棒性。
二、方法
2.1、问题及符号设置
低保真度数据: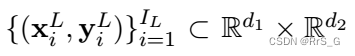
高保真度数据: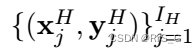
其中。
问题:使用两种数据集学习一个f,使得对于任意x,函数值f(x)可以准确地近似在x点的高保真响应。
2.2、生成器和鉴别器
如下图2所示,GAN-MDF的生成器由两个模块组成:低保真(LF)块和高保真(HF)块。其中:
(a)、LF模块提取输入信号的低保真特征,其权重仅通过LF样本进行训练,然后在后续训练过程中进行固定;
(b)、在对抗性训练过程中训练高保真模块的权值,将提取的低频特征与原始输入融合在一起,生成输入高保真响应的近似。
GAN-MDF鉴别器的输入要么是真实的HF响应,要么是生成器的输出。
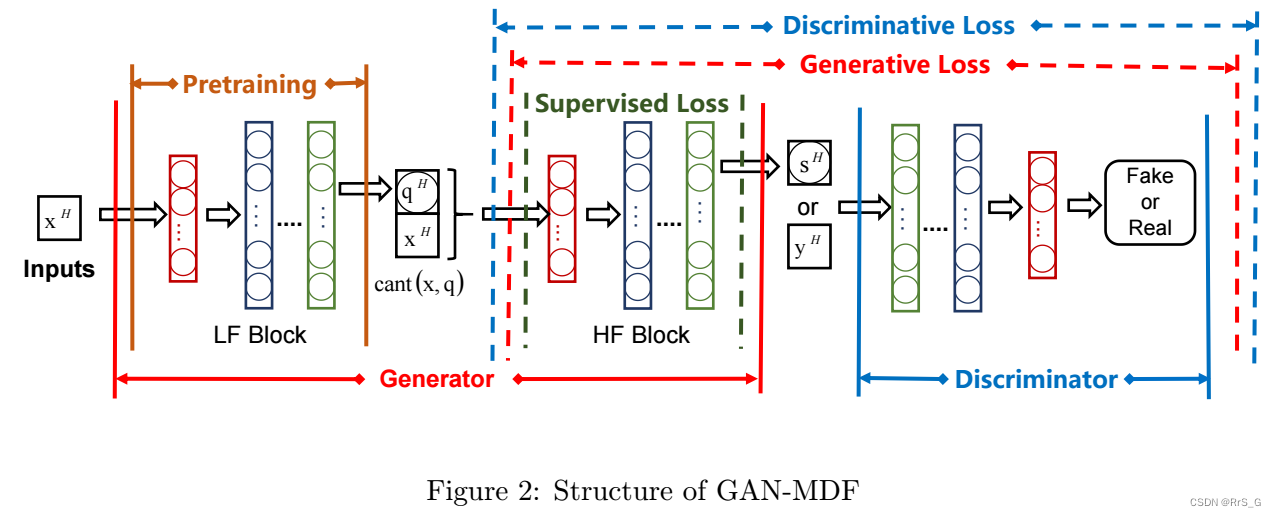
只利用低保真的样本训练LF模块的权重,然后在后续的训练过程中固定权重。
给定一个维输入x,LF模块的输出为
维的q,然后HF模块的输入为
维的cant(x,q),其中
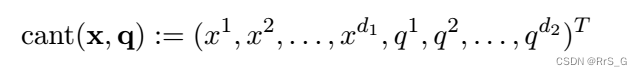
HF模块继承了LF模块的结构特点,其权值在对抗训练中被更新。鉴别器也很常规。
2.3、对抗训练策略
与传统的GAN训练策略不同,本文在每次迭代中引入监督损失策略来平衡生成器和鉴别器的训练,从而稳定GAN-MDF的训练过程。具体地,关于高保真样本的监督损失为
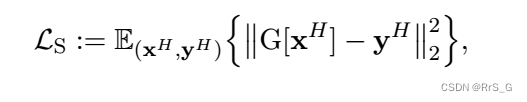
具体算法如下:

三、数值实验
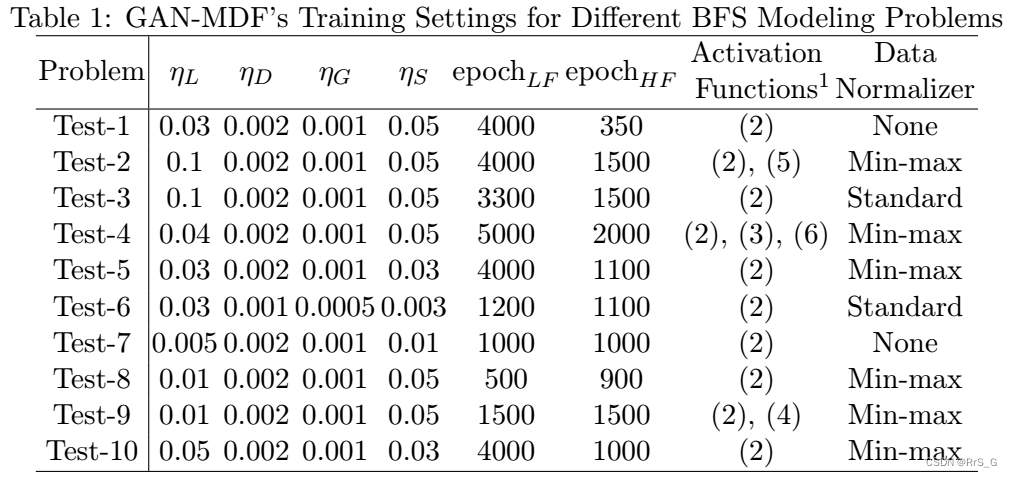
实验设置如下:
测试指标:
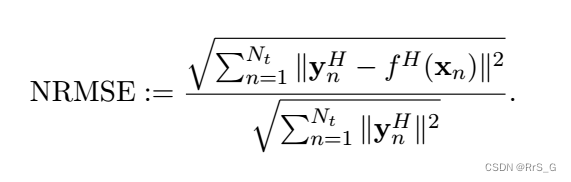
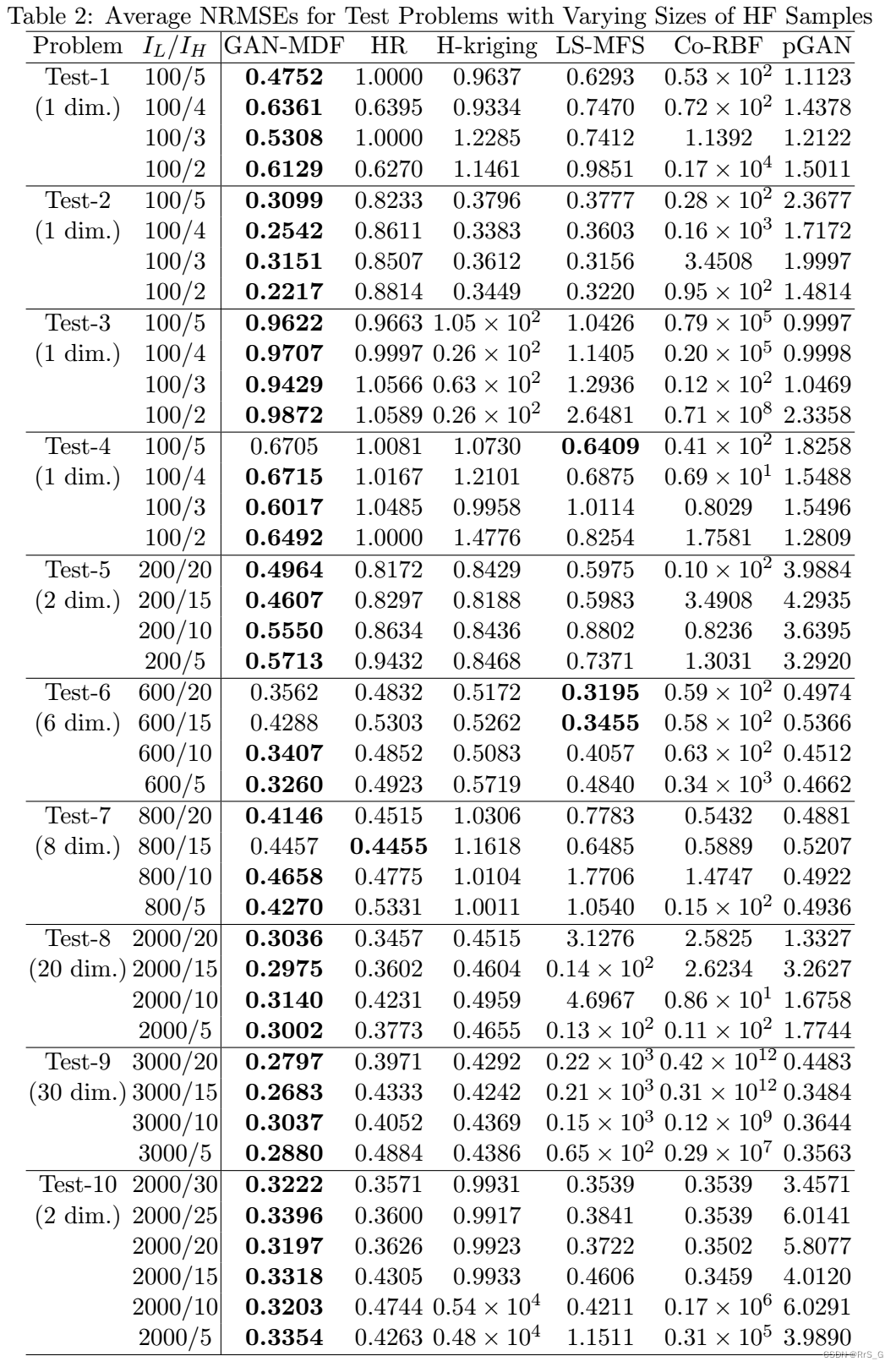
3.1、不同高保真点尺寸的实验
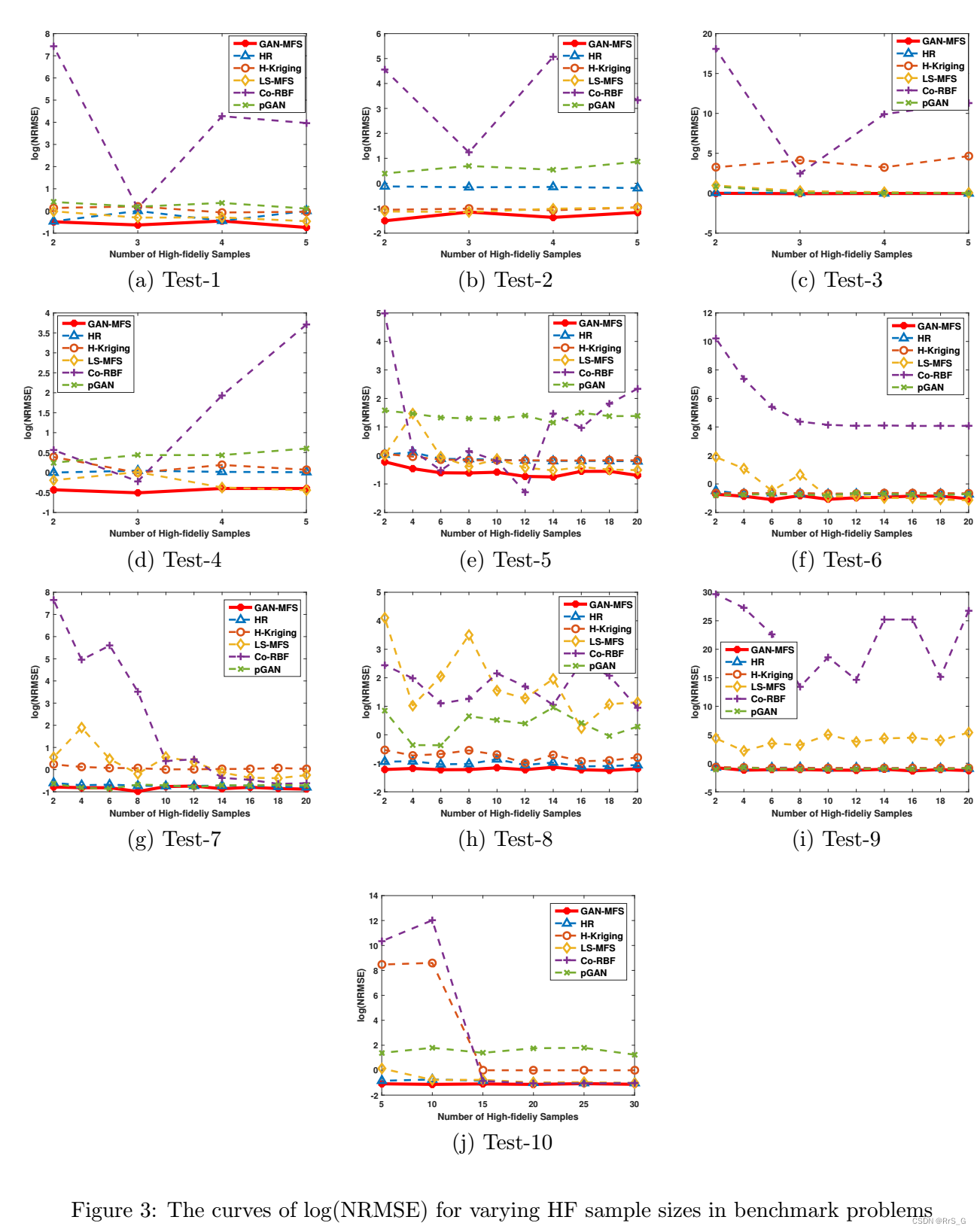
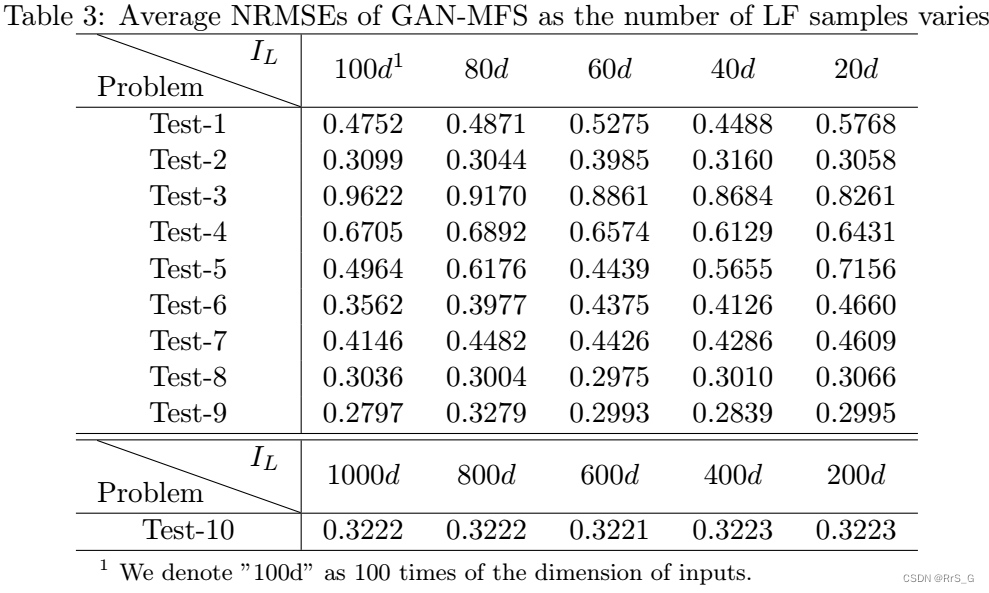
3.2、不同低保真点尺寸的实验



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









