






 本文提出了一种使用卷积神经网络(MDA-CNN)的多保真数据聚合方法,旨在学习高保真度数据与所有可用的低保真度数据之间的关系。通过模拟卷积操作的滑动窗口,MDA-CNN能更有效地利用大量低保真数据。实验表明,卷积层的使用显著提高了模型的性能,并且高保真模型不仅依赖于低保真模型本身,还依赖其一阶导数信息。
本文提出了一种使用卷积神经网络(MDA-CNN)的多保真数据聚合方法,旨在学习高保真度数据与所有可用的低保真度数据之间的关系。通过模拟卷积操作的滑动窗口,MDA-CNN能更有效地利用大量低保真数据。实验表明,卷积层的使用显著提高了模型的性能,并且高保真模型不仅依赖于低保真模型本身,还依赖其一阶导数信息。
目录
一、方法
让和
分别表示低保真度和高保真度生成模型。考虑两个模型之间的一般关系如下:
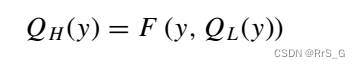
(1)
其中是一个未知函数,它捕捉了低保真量和高保真量之间的关系,它可以是线性的,也可以是非线性的。
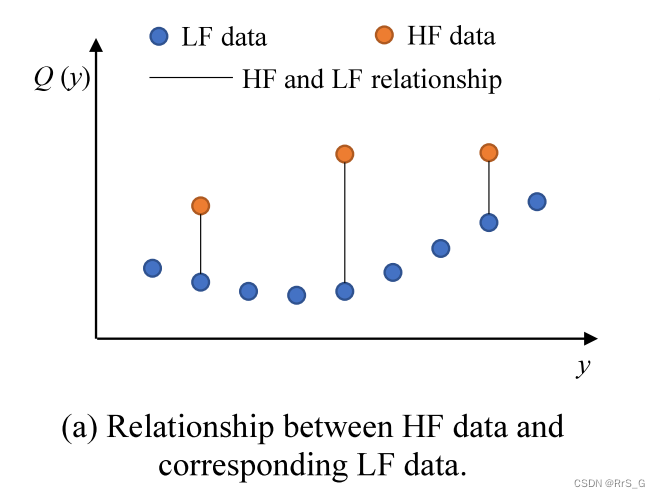
当y为一维时,Eq.(1)中的关系如图1(a)所示。
为了学习F(•),建立了神经网络代理模型。神经网络模型的结构如下图2所示:
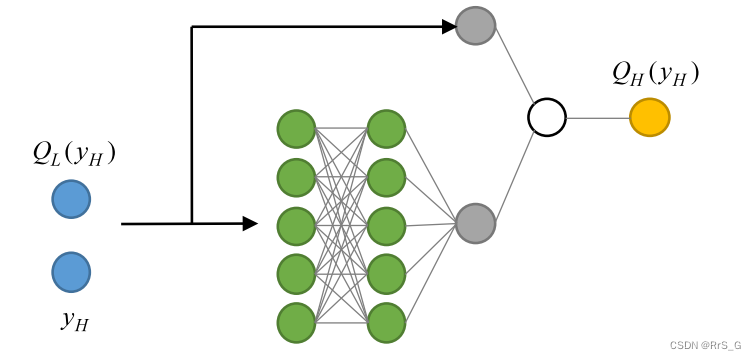
该结构输入层和输出层非常明显,隐藏层包括两部分:线性映射和非线性映射。线性映射和非线性映射分别通过跳跃连接层(上箭头)和完全连接层(下箭头)学习,这两个层分别使用线性和非线性激活函数。
但是如果按照图1(a)点对点的采样数据,有大量的低保真数据没有用到,鉴于此,作者想到一个办法如下图:
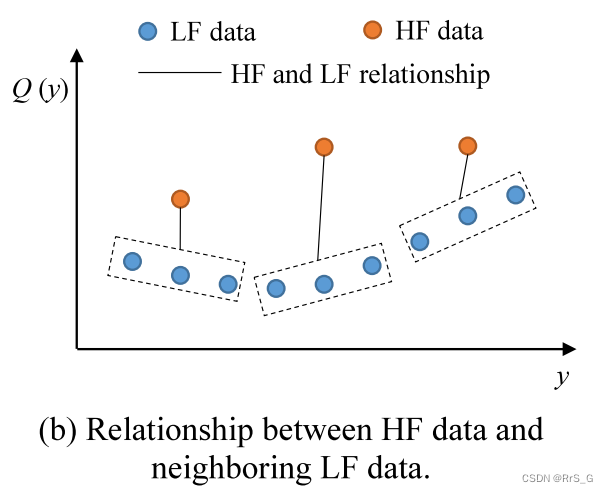
该思想是学习邻域内高保真数据和低保真数据之间的关系(如图1(b)中的矩形框所示)。通过这种方式,多保真模型可以学习点到域的关系。
更一般地,作者扩展上述思想,学习高保真数据与所有可用的低保真数据之间的关系,如图1(c)所示:
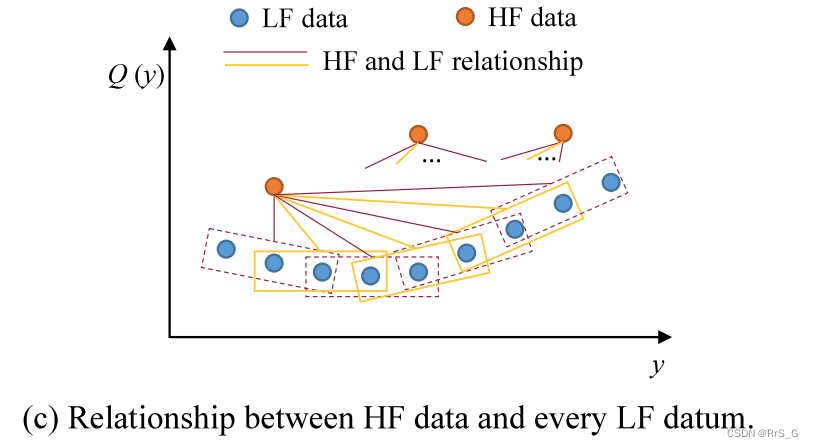
这是通过在低保真数据空间中依次移动本域(图1(c)中的矩形框)来实现的。这个滑动窗口操作捕获每个高保真数据和每个低保真数据的局部域之间的关系。作者发现,这种“滑动窗口”操作类似于卷积操作。这也是作者使用CNN进行多保真数据分析的原因。
下面将描述通过一个神经网络实现图1(c)中的思想:使用卷积神经网络的多保真数据聚合(MDA-CNN)。
MDA-CNN的架构如下图3所示:
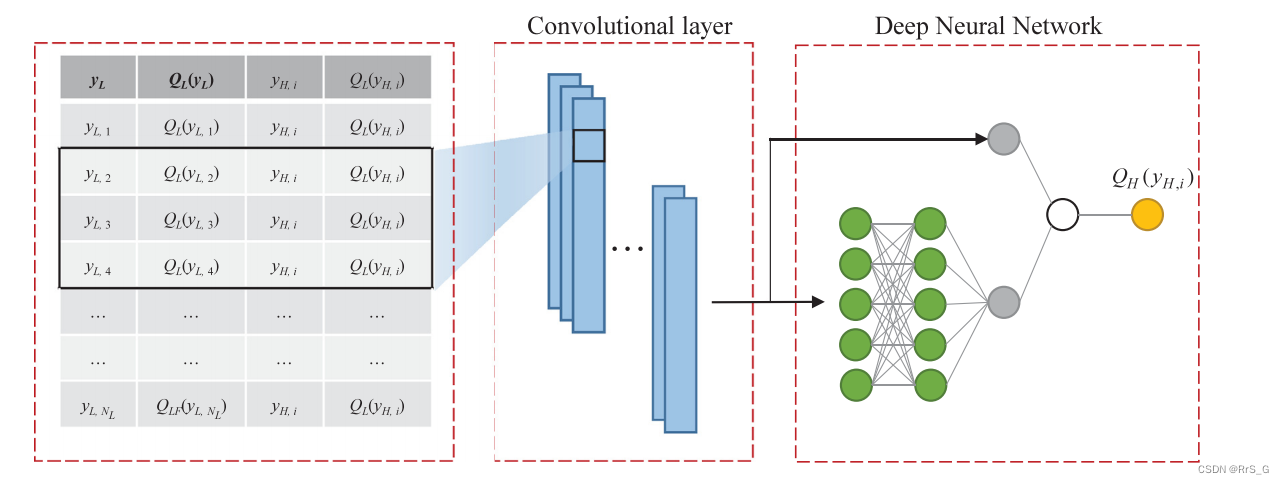
它包括三部分:多保真数据编译,卷积层,深度神经网络。
相比图2中的结构,这个结构的输出仍然不变,为,而输入不只是
和
,还有所有的低保真度数据
和
。
具体来说,输入数据以表的形式编译,如图3中第一个虚线框所示,一共有个这样的表,对应高保真数据的数量,每个表有
行,对应低保真数据的数量。按照这种方式编译后,将所有可用的低保真数据用于NN模型,学习低保真数据与高保真数据之间的关系。
图3中的MDA-CNN是针对一维y的双保真问题。而本文提出的框架并不局限于两个保真级别,可以扩展到处理多个保真级别的数据集,也可以处理任意维度的y。对于这些情况,需要调整图3中第一个虚线框中的多保真数据编译,同时保持MDA-CNN框架的其余部分不变。
下图4分别给出了二维y、两种低保真模型以及利用低保真模型一阶导数的情况下的输入表设计:
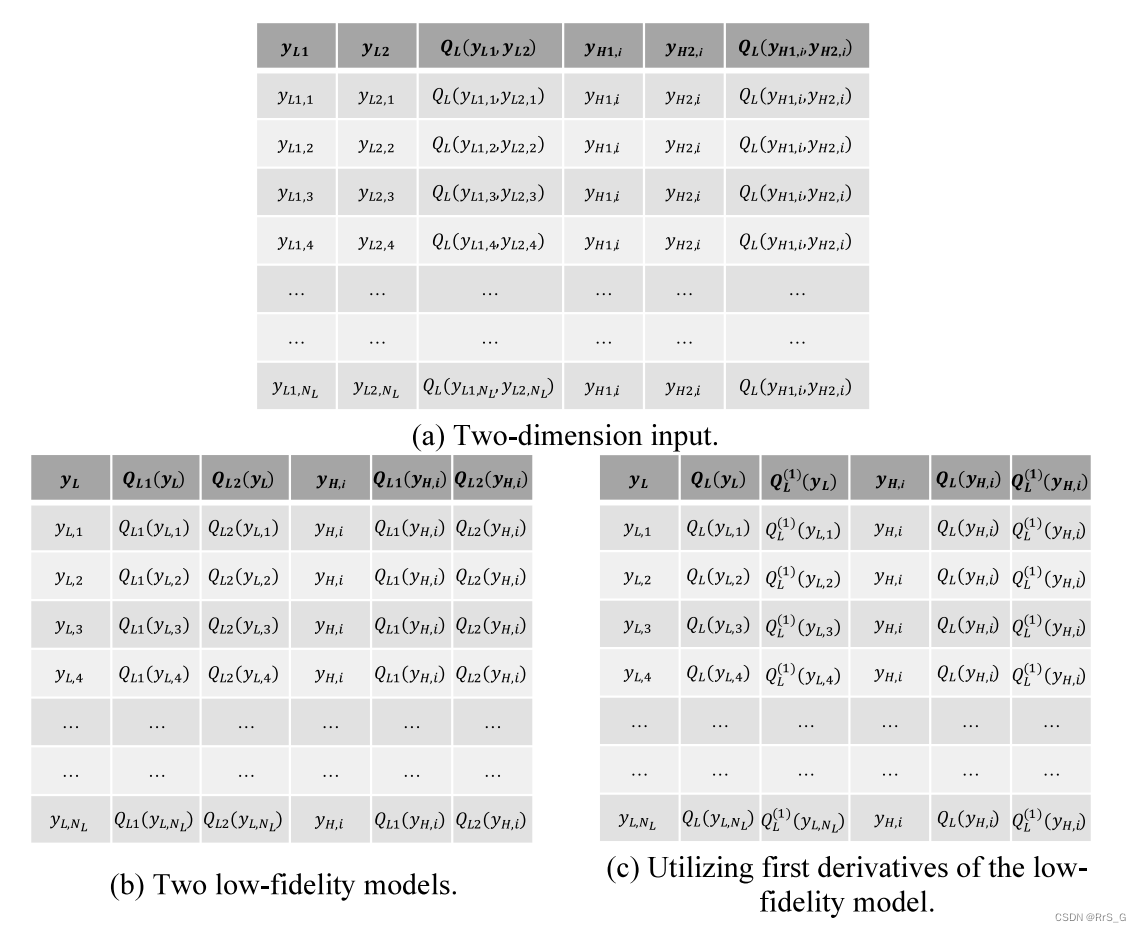
构造输入表的基本思想是,表的左半部分包含所有低保真信息,而右半部分表示与可用的高保真数据对应的低保真数据。
二、实验
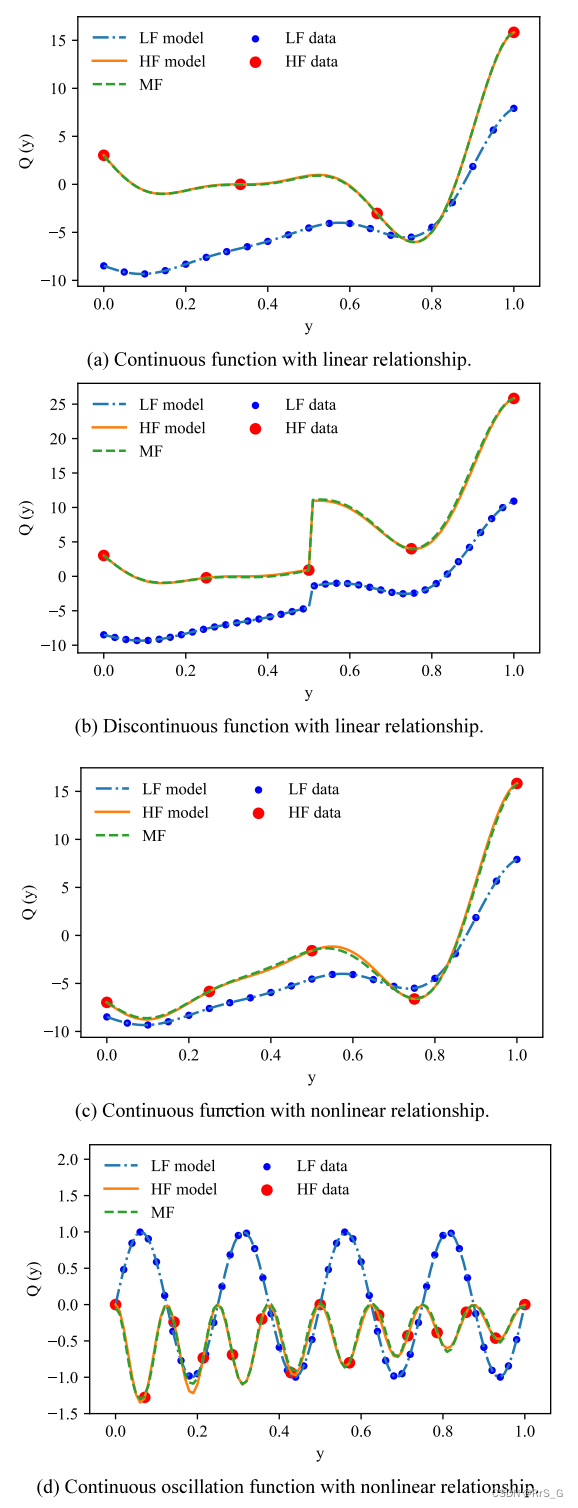
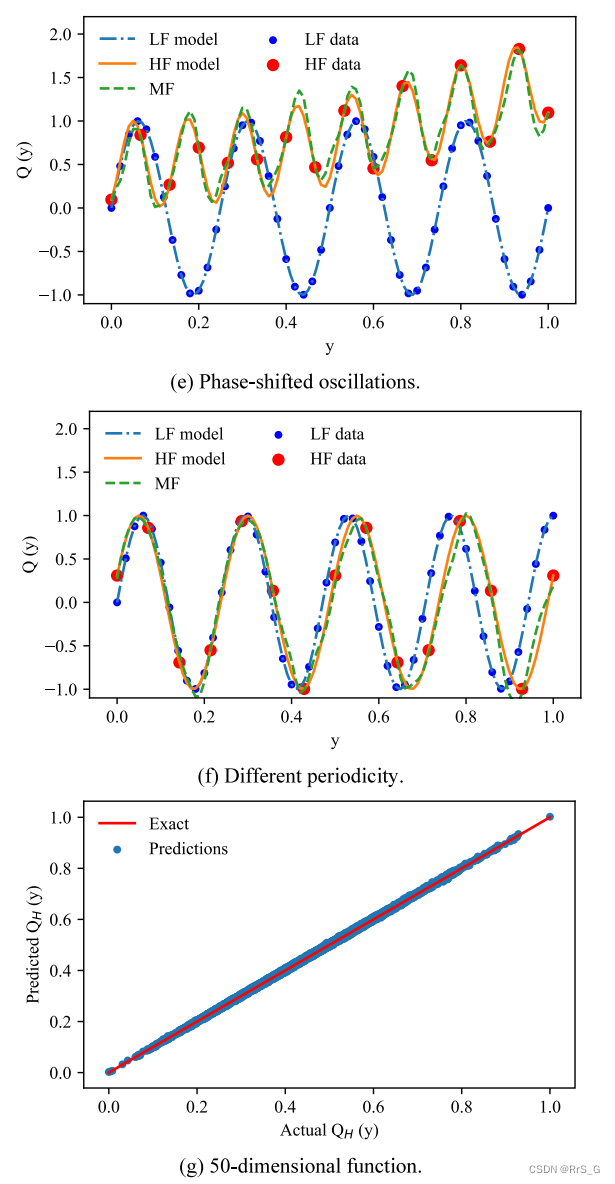
采用7个数值算例对MDA-CNN模型进行了验证,具体如下表1。

结果如下:
三、讨论
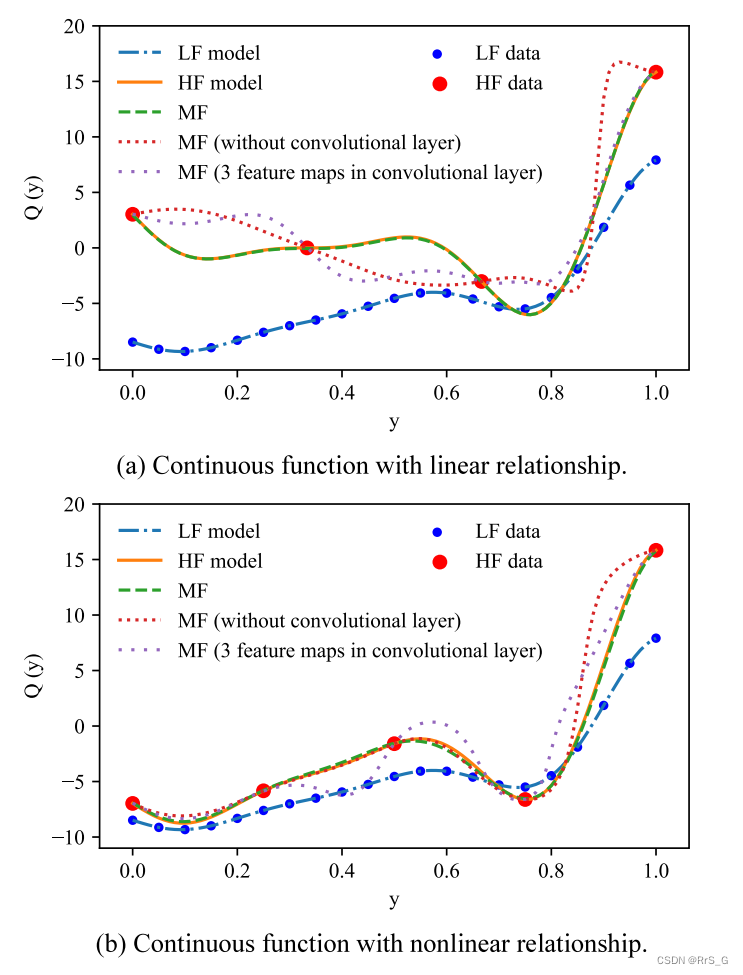
3.1. 卷积层效应
下图(a)和(b)显示了使用卷积层和不使用卷积层的神经网络以及使用不同特征映射的数量得到的结果的比较。这两个图分别对应表1中(a)和(c)中的线性关系的连续函数和非线性关系的连续函数。
3.2. 梯度信息的影响
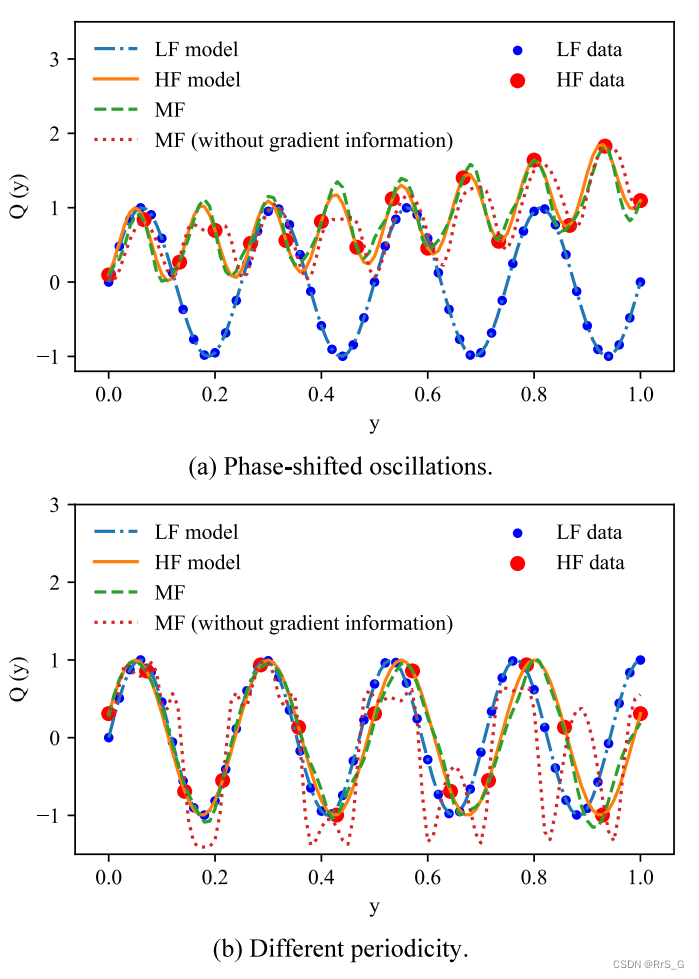
可以看出,没有低保真梯度信息的预测是不准确的。这可以解释如下:表1中式(12)、(14)可以进一步表示为
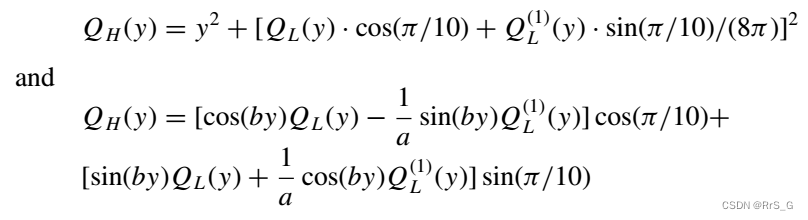
高保真模型不仅是低保真模型本身的函数,而且是低保真模型一阶导数的函数。如果没有提供低保真梯度信息用于多保真建模,现有的数据集不足以让神经网络模型学习正确的关系。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









