







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
一、前期工作
1.设置GPU
代码知识点
tf.config.experimental.set_memory_growth(gpu0,True)将第一个GPU设备(gpu0)设置为内存增长模式。在这种模式下,TensorFlow会根据需要动态地分配和释放GPU内存,而不是一开始就占用所有可用的GPU内存。
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0,True)
tf.config.set_visible_devices([gpu0],"GPU")
2.导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
3.归一化
代码知识点
对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。灰度图片是一种数字图像,每个像素只有一个采样颜色,通常显示为从最暗黑色到最亮的白色的灰度。灰度图片中的灰度级别是指黑色到白色之间的等级数,一般为256级。
train_images, test_images = train_images / 225.0 , test_images / 225.0
train_images.shape, test_images.shape, train_labels.shape, test_labels.shape
输出
((50000, 32, 32, 3), (10000, 32, 32, 3), (50000, 1), (10000, 1))
4.可视化
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(20,10))
for i in range(20):
plt.subplot(5, 10, i+1)# subplot(子图行数,子图列数,子图索引(从1开始))
# 不显示轴刻度
plt.xticks([])
plt.yticks([])
# 不显示子图网格线
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
输出

二、构建CNN网络
关于卷积输出的计算方法(来自教案“知识储备部分”)
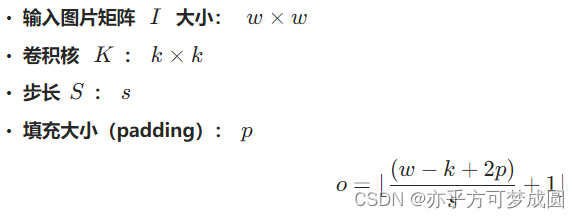
当我们将设置Padding=“same”时,会动态调整填充大小,使得输入输出的大小相等。
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPool2D(2, 2),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPool2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
model.summary()
输出

三、编译
代码知识点
model.compile是Keras中用于配置模型的训练选项的方法。它通常在模型定义完成后,训练数据准备就绪之前调用。SparseCategoricalCrossentropy()是Keras中用于计算稀疏类别交叉熵损失函数的方法。from_logits=True:这是一个参数,表示输入到损失函数的预测值是否已经是概率分布(即logits)。如果输入已经是概率分布,那么将from_logits设置为True;如果输入是原始的预测值,那么将from_logits设置为False。metrics:评估指标,用于衡量模型的性能。常用的评估指标有准确率(accuracy)、精确率(precision)、召回率(recall)等。可以传入一个列表,包含多个评估指标。
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
四、训练模型
history = model.fit(train_images, train_labels, epochs=10,
validation_data = (test_images, test_labels))
输出
Epoch 1/10
1563/1563 [ ] - 17s 10ms/step - loss: 1.5035 - accuracy: 0.4491 - val_loss: 1.2236 - val_accuracy: 0.5606
Epoch 2/10
1563/1563 [ ] - 17s 11ms/step - loss: 1.1326 - accuracy: 0.5983 - val_loss: 1.0417 - val_accuracy: 0.6288
Epoch 3/10
1563/1563 [ ] - 15s 10ms/step - loss: 0.9645 - accuracy: 0.6608 - val_loss: 0.9656 - val_accuracy: 0.6654
Epoch 4/10
1563/1563 [ ] - 15s 10ms/step - loss: 0.8638 - accuracy: 0.6983 - val_loss: 0.9057 - val_accuracy: 0.6866
Epoch 5/10
1563/1563 [ ] - 16s 10ms/step - loss: 0.7846 - accuracy: 0.7249 - val_loss: 0.9041 - val_accuracy: 0.6895
Epoch 6/10
1563/1563 [ ] - 14s 9ms/step - loss: 0.7296 - accuracy: 0.7451 - val_loss: 0.8858 - val_accuracy: 0.6974
Epoch 7/10
1563/1563 [ ] - 17s 11ms/step - loss: 0.6773 - accuracy: 0.7625 - val_loss: 0.8517 - val_accuracy: 0.7153
Epoch 8/10
1563/1563 [ ] - 15s 10ms/step - loss: 0.6364 - accuracy: 0.7783 - val_loss: 0.8526 - val_accuracy: 0.7172
Epoch 9/10
1563/1563 [ ] - 16s 11ms/step - loss: 0.5950 - accuracy: 0.7929 - val_loss: 0.8586 - val_accuracy: 0.7174
Epoch 10/10
1563/1563 [ ] - 18s 11ms/step - loss: 0.5567 - accuracy: 0.8061 - val_loss: 0.8664 - val_accuracy: 0.7190
五、预测
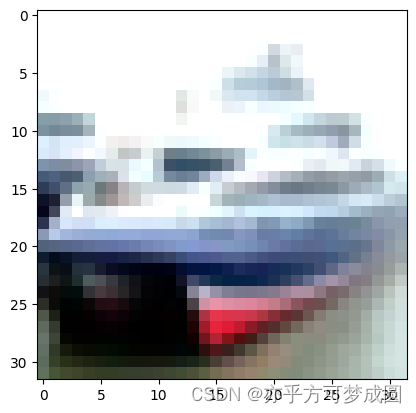
plt.imshow(test_images[1])
代码知识点
np.argmax是numpy库中的一个函数,它的主要功能是返回输入数组中最大值的索引。如果输入数组中出现多个最大值,np.argmax将返回第一个最大值的索引。这个函数有两个参数,第一个参数是需要找到最大值索引的数组,第二个参数是指定的轴,即沿着哪个轴寻找最大值。例如,当axis=1时,函数会按行比较并找出每行的最大值索引。值得注意的是,如果不指定轴,则函数会将整个数组平铺开来,找出其中最大的那个值的索引。此外,np.argmax函数还支持out参数,用于指定一个数组用于存储结果。
import numpy as np
pre = model.predict(test_images)
print(class_names[np.argmax(pre[1])])
输出
313/313 [==============================] - 1s 2ms/step
ship
六、模型评估
代码知识点
plt.plot()是一个绘图函数,它接受两个参数:x轴的数据和y轴的数据。
history.history['accuracy']是从训练过程中保存的历史记录中获取准确率数据。历史记录通常在模型训练时使用model.fit()函数进行训练,并返回一个包含训练过程中各种指标的对象。
label='accuracy'是一个可选参数,用于设置图例标签。
plt.ylim([0.5, 1])用于调节y轴的范围
plt.legend(loc='lower right')将图例的位置设置在了
verbose=2表示在评估过程中输出详细信息,包括每个批次的损失值和准确率。下角
import matplotlib.pyplot as plt
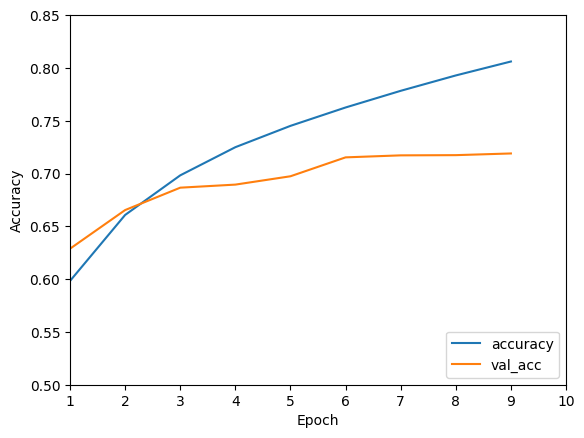
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.xlim([1, 10])
plt.ylim([0.5, 0.85])
plt.legend(loc='lower right')
plt.show()
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
输出
313/313 - 1s - loss: 0.8664 - accuracy: 0.7190 - 943ms/epoch - 3ms/step
print(test_acc)
0.718999981880188
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









