







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、前期准备
1.设置GPU
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu" )
device
输出
device(type=‘cuda’)
2.导入数据
torchvision.datasets是 PyTorch 的一个库,它提供了许多常用的数据集和相应的数据加载器。这些数据集包括用于图像识别、分割、检测等任务的数据集,如 CIFAR、ImageNet、COCO 等。这些数据集通常都有预定义的接口,使得加载数据变得非常简单。
torchvision.datasets通常用于以下两种场景:
- 加载数据集:通过指定数据集的名称和相关的参数,你可以轻松地加载所需的数据集。
- 下载和加载数据集:如果数据集尚未下载,
torchvision.datasets还可以自动下载并加载数据集。 以下是一些常用的torchvision.datasets函数和参数:Dataset:这是所有数据集的基类,它提供了通用的接口和功能。其他数据集都是继承自这个类。ImageFolder:这是一个通用的数据加载器,用于加载以文件夹形式组织的图像数据集。每个文件夹代表一个类别,文件夹内的所有图像都属于该类别。
root:数据集的根目录。transform:对图像进行变换的函数。target_transform:对目标进行变换的函数。CIFAR10:用于加载 CIFAR-10 数据集。
root:数据集的根目录。train:是否加载训练集或测试集。download:如果为 True,则自动下载数据集。transform:对图像进行变换的函数。MNIST:用于加载 MNIST 数据集。
root:数据集的根目录。train:是否加载训练集或测试集。download:如果为 True,则自动下载数据集。transform:对图像进行变换的函数。ImageNet:用于加载 ImageNet 数据集。
root:数据集的根目录。split:指定数据集的分割(‘train’、‘val’、‘test’)。transform:对图像进行变换的函数。target_transform:对目标进行变换的函数。
train_ds = torchvision.datasets.MNIST('data',
train = True,
transform=torchvision.transforms.ToTensor(),
download = True)
test_ds = torchvision.datasets.MNIST('data',
train = False,
transform=torchvision.transforms.ToTensor(),
download = True)
torch.utils.data.DataLoader是 PyTorch 提供的一个数据加载器,它允许我们在训练模型时以批处理的形式加载数据。它通常与torch.utils.data.Dataset结合使用,后者是一个表示数据集的抽象类。DataLoader负责在数据集上提供迭代功能,并支持多线程数据加载、批量处理、采样和混洗等操作。
以下是DataLoader的一些主要参数及其用法:
dataset:这是DataLoader最重要的参数,它指定了要加载的数据集。这个数据集必须是torch.utils.data.Dataset的一个子类实例。batch_size:每个批处理包含的样本数量。默认值为 1。shuffle:如果设置为True,那么在每个 epoch 开始时,DataLoader会打乱数据集的数据。这对于随机梯度下降(SGD)等优化算法是有益的,因为它可以减少模型的过拟合。sampler:定义了从数据集中采样的策略。如果指定了sampler,那么shuffle必须设置为False。batch_sampler:与sampler类似,但是它返回的是一批索引。如果指定了batch_sampler,那么batch_size、shuffle、sampler和drop_last参数都会被忽略。num_workers:指定用于加载数据的工作进程数。默认值为 0,这意味着数据将在主进程中加载。如果设置为大于 0 的值,则使用多进程数据加载,这可以显著提高数据加载速度,尤其是在数据读取和处理较慢时。pin_memory:如果设置为True,那么在数据传输到 GPU 时,数据加载器会使用固定的内存(页锁定内存)。这通常可以提高数据传输到 GPU 的速度。drop_last:如果设置为True,那么当数据集的大小不能被batch_size整除时,最后一个不完整的批处理会被丢弃。默认值为False。timeout:如果为正数,那么在从工作进程中收集批次时,如果超过这个时间(秒),则工作进程会被杀死。默认值为 0,表示无限期等待。worker_init_fn:如果指定,它将在每个工作进程开始时调用,并接收工作进程的 ID 作为参数。这可以用于进行一些工作进程特定的初始化操作。prefetch_factor:每个工作进程在加载下一个批次之前预取的数据批次数量。默认值为 2。persistent_workers:如果设置为True,那么数据加载器会保留工作进程在迭代结束后不被关闭,这可以提高性能,尤其是在多个 epoch 的情况下。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size = batch_size,
shuffle = True)
test_dl = torch.utils.data.DataLoader(test_ds,
shuffle = True)
在 PyTorch 中,
shape函数通常指的是调用张量的.shape属性或
torch.Tensor.shape,它返回一个元组(tuple),表示张量(tensor)的尺寸。这个元组中的每个元素代表张量在不同维度上的大小。例如,一个图像张量可能有三个维度,分别代表颜色通道、高度和宽度。
假设我们有一个图像张量,其形状为(3, 256, 256),这四个数(在这个例子中是三个数)的含义如下:
- 第一个数字(3):这通常代表颜色通道的数量。在 RGB 图像中,这个数字是 3,分别代表红色、绿色和蓝色通道。
- 第二个数字(256):这代表图像的高度,以像素为单位。
- 第三个数字(256):这代表图像的宽度,以像素为单位。
对于具有四个维度的张量,例如在批量处理图像时,其形状可能类似于
(batch_size, channels, height, width),其中:
- 第一个数字(
batch_size):这代表批量中的样本数量。- 第二个数字(
channels):这代表颜色通道的数量,例如 RGB 图像的 3。- 第三个数字(
height):这代表图像的高度,以像素为单位。- 第四个数字(
width):这代表图像的宽度,以像素为单位。对于其他类型的张量,维度的含义可能会有所不同,取决于数据的上下文和应用场景。例如,一个包含单词嵌入的批量可能具有形状
(batch_size, sequence_length, embedding_size),其中:
batch_size:批量中样本的数量。sequence_length:每个样本中的序列长度(例如,句子中的单词数)。embedding_size:每个单词的嵌入维度大小。
imgs,labels = next(iter(train_dl))
imgs.shape
torch.Size([32, 1, 28, 28])
这里的四个数分别是batch_size,channel,height,width
3.数据可视化
在 PyTorch 中,
enumerate函数通常用于在遍历数据集的批次时同时获取批次索引和数据。enumerate是 Python 的内置函数,它允许我们遍历一个序列(如列表、元组或字符串)并返回每个元素的索引和值。
在 PyTorch 的上下文中,当我们使用DataLoader迭代数据集时,enumerate函数通常与 for 循环一起使用,以便在训练循环中跟踪 epoch 的编号,enumerate(data_loader)会返回每个批次的索引i和数据对(inputs, targets)。这样,我们可以在训练循环中使用i来跟踪当前是第几个批次,这对于打印训练进度、记录日志或在特定批次时执行某些操作(如调整学习率)非常有用。enumerate函数还可以接受一个start参数来指定索引的起始值,例如enumerate(data_loader,start=1),这将使得批次的索引从 1 开始,而不是默认的 0。
np.squeeze()是 NumPy 库中的一个函数,它的作用是从数组的形状中移除单维的条目,即维度大小为 1 的轴。这个函数的目的是为了减少数组的维度,使得数组的形状更加紧凑,便于进行某些操作或计算。
为什么要使用np.squeeze():
- 数据形状适配:在处理图像数据时,我们通常希望图像的形状是
(height, width, channels)或(batch_size, height, width, channels)。但是,有时候由于数据的来源或处理方式,图像数据的形状可能会包含不必要的单维轴,例如(1, height, width, 1)。在这种情况下,使用np.squeeze()可以将数据形状变为(height, width)或
(height, width, channels),这样就可以直接用于图像显示或其他图像处理函数。- 简化计算:在机器学习模型中,某些操作(如卷积、池化等)要求输入数据的维度是固定的。如果一个数组有多余的单维轴,那么在进行这些操作之前,可能需要使用
np.squeeze()来简化数组的形状。- 避免广播错误:在 NumPy 中,当进行数组运算时,如果数组的形状不匹配,NumPy 会尝试通过广播机制来扩展数组。如果一个数组有不必要的单维轴,可能会导致意外的广播行为。使用
np.squeeze()可以避免这种错误。- 提高代码可读性:移除不必要的单维轴可以使数组的形状更加清晰,提高代码的可读性和可维护性。
import numpy as np
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]): # 提取前20个元素
npimg = np.squeeze(imgs.numpy())
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')
输出
二、构建简单的CNN网络
解释一下模型传递过程中的参数变化
这段代码定义了一个简单的卷积神经网络模型,用于图像分类。
self.conv1 = nn.Conv2d(1, 32, kernel_size=3):
- 这一层定义了一个二维卷积层,它接受一个通道(例如灰度图)的输入,并输出 32 个特征图。卷积核的大小是 3x3。每个卷积核的权重是 3x3 = 9个参数,加上一个偏置项,共 10个参数。因此,总共是 32x10 = 320个参数。
self.pool1 = nn.MaxPool2d(2):
- 这一层定义了一个最大池化层,池化窗口大小为 2x2。池化层不引入任何参数,它只是对输入的特征图进行下采样。
self.conv2 = nn.Conv2d(32, 64, kernel_size=3):
- 这一层定义了第二个二维卷积层,它接受 32 个通道的输入,并输出 64 个特征图。卷积核的大小是 3x3。每个卷积核的权重是 32x3x3 = 288个参数,加上一个偏置项,共 289个参数。因此,总共是 64x289 = 18,496个参数。
self.pool2 = nn.MaxPool2d(2):
- 这是第二个最大池化层,同样使用 2x2 的池化窗口。池化层不引入任何参数。
self.fcl = nn.Linear(1600, 64):
- 这一层定义了一个全连接层,它接受 1600 维的输入,并输出 64 维的输出。这里的 1600 是通过计算前两层卷积和池化后的特征图尺寸得到的。对于 28x28 的输入图像,经过两次卷积和池化后,特征图的尺寸应该是5x5(假设没有使用填充)。因此,这里的 1600 应该是 5x5x64 = 1600。这层引入的参数包括权重和偏置,总共是 1600x64 + 64 = 102,464个参数。
self.fc2 = nn.Linear(64, num_classes):
- 这是第二个全连接层,它接受 64 维的输入,并输出
num_classes维的输出(在这个例子中是 10,因为有 10 个类别)。这层引入的参数包括权重和偏置,总共是 64x10 + 10 = 650个参数。 在forward方法中,输入x
通过卷积层和池化层进行前向传播,然后被展平(flatten)成一个一维向量,再通过两个全连接层,最后得到每个类别的分数。在
forward方法中,F.relu应用 ReLU 激活函数,它在每个卷积层和全连接层之后使用,以引入非线性。
为了解释特征图尺寸从 28x28 变为 5x5 的过程,我们需要考虑卷积层和池化层对输入图像尺寸的影响。以下是基于假设的卷积层和池化层的参数,对特征图尺寸变化的计算:
- 第一次卷积 (conv1): 假设输入图像大小为 28x28,使用 3x3 的卷积核,无填充(padding)和步幅(stride)为 1。这将导致特征图的尺寸减少。每个卷积核覆盖图像的一个 3x3
的区域,因此输出特征图的尺寸将是输入尺寸减去卷积核大小加一。对于 28x28 的输入和 3x3 的卷积核,输出尺寸将是 26x26。- 第一次池化 (pool1): 假设使用 2x2 的最大池化,步幅为 2。池化会减少特征图的尺寸,每个 2x2 的区域被减少到一个像素。因此,26x26 的特征图在池化后会变成 13x13。
- 第二次卷积 (conv2): 假设第二次卷积仍然使用 3x3 的卷积核,无填充和步幅为 1。对于 13x13 的输入,输出尺寸将是 11x11。
- 第二次池化 (pool2): 再次使用 2x2 的最大池化,步幅为 2。11x11 的特征图在池化后会变成 5.5x5.5。但是,特征图的尺寸必须是整数,所以我们需要向下取整,得到 5x5
import torch.nn.functional as F
num_classes = 10
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1,32,kernel_size = 3)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32,64,kernel_size = 3)
self.pool2 = nn.MaxPool2d(2)
#分类网络
self.fcl = nn.Linear(1600,64)
self.fc2 = nn.Linear(64, num_classes)
#前向传播
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = torch.flatten(x, start_dim = 1)
x = F.relu(self.fcl(x))
x = self.fc2(x)
return x
from torchinfo import summary
# 将模型转移到GPU中(我们模型运行均在GPU中进行)
model = Model().to(device)
summary(model)
输出

三、模型训练
1.设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-2 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2.编写训练函数
这段代码是一个简单的 PyTorch 训练循环,用于训练一个神经网络模型。
def train(dataloader, model, loss_fn, optimizer)::
- 定义了一个函数
train,它接受四个参数:dataloader(数据加载器,用于迭代数据集的批次)、model(神经网络模型)、loss_fn(损失函数,用于计算预测值和真实值之间的差异)和optimizer(优化器,用于更新模型参数)。size = len(dataloader.dataset):
- 计算训练集的大小,即数据加载器中数据集的长度。在这个例子中,假设数据加载器是从一个包含 60000 张图片的数据集构建的。
num_batches = len(dataloader):
- 计算批次数目,即数据加载器中的批次数量。这通常是通过将数据集的大小除以批大小来计算的。在这个例子中,假设批大小为 32,所以批次数目是 60000/32 = 1875。
train_loss, train_acc = 0, 0:
- 初始化训练损失和正确率,设置为 0。这两个变量用于在整个训练过程中记录总的损失和正确率。
for X, y in dataloader::
- 开始一个 for 循环,用于遍历数据加载器的所有批次。
X包含当前批次的输入数据,而y包含当前批次的标签。X, y = X.to(device), y.to(device):
- 将当前批次的输入数据
X和标签y移动到指定的设备上。device通常是 ‘cuda’ 或 ‘cpu’,这取决于你的硬件配置。pred = model(X):
- 计算模型的预测输出。
model是之前定义的神经网络模型,它接受输入X并输出预测pred。loss = loss_fn(pred, y):
- 计算预测值
pred和真实值y之间的差异,得到损失loss。loss_fn是之前定义的损失函数,它接受预测和真实值作为输入,并返回损失值。optimizer.zero_grad():
- 清除优化器中所有参数的梯度。这是为了确保在反向传播过程中,梯度不会累积,从而影响模型的训练。
loss.backward():
- 进行反向传播,计算损失
loss关于模型参数的梯度。这个梯度会被存储在优化器中,以便在下一步更新模型参数时使用。optimizer.step():
- 根据当前的梯度信息更新模型参数。优化器会根据每个参数的梯度和学习率来计算每个参数的新值,并更新模型参数。
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item():
● pred.argmax(1) 返回数组 pred 在第一个轴(即行)上最大值所在的索引。这通常用于多类分类问题中,其中 pred 是一个包含预测概率的二维数组,每行表示一个样本的预测概率分布。
● (pred.argmax(1) == y)是一个布尔值,其中等号是否成立代表对应样本的预测是否正确(True 表示正确,False 表示错误)。
● .type(torch.float)是将布尔数组的数据类型转换为浮点数类型,即将 True 转换为 1.0,将 False 转换为 0.0。
● .sum()是对数组中的元素求和,计算出预测正确的样本数量。
● .item()将求和结果转换为标量值,以便在 Python 中使用或打印。
(pred.argmax(1) == y).type(torch.float).sum().item()表示计算预测正确的样本数量,并将其作为一个标量值返回。这通常用于评估分类模型的准确率或计算分类问题的正确预测数量。train_loss += loss.item():
- 累加当前批次的损失到总损失
train_loss中。train_acc /= size:
- 计算平均准确率。将
train_acc除以训练集的大小size,得到整个训练过程中的平均准确率。train_loss /= num_batches:
- 计算平均损失。将
train_loss除以批次数目num_batches,得到整个训练过程中的平均损失。return train_acc, train_loss:
- 返回平均准确率和平均损失。这两个值可以用于评估模型的训练效果。
optimizer.zero_grad()函数会遍历模型的所有参数,通过内置方法截断反向传播的梯度流,再将每个参数的梯度值设为0,即上一次的梯度记录被清空。
loss.backward()PyTorch的反向传播(即tensor.backward())是通过autograd包来实现的,autograd包会根据tensor进行过的数学运算来自动计算其对应的梯度。
具体来说,torch.tensor是autograd包的基础类,如果你设置tensor的requires_grads为True,就会开始跟踪这个tensor上面的所有运算,如果你做完运算后使用tensor.backward(),所有的梯度就会自动运算,tensor的梯度将会累加到它的.grad属性里面去。
更具体地说,损失函数loss是由模型的所有权重w经过一系列运算得到的,若某个w的requires_grads为True,则w的所有上层参数(后面层的权重w)的.grad_fn属性中就保存了对应的运算,然后在使用loss.backward()后,会一层层的反向传播计算每个w的梯度值,并保存到该w的.grad属性中。
如果没有进行tensor.backward()的话,梯度值将会是None,因此loss.backward()要写在optimizer.step()之前。
optimizer.step()step()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。注意:optimizer只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
3.编写测试函数
这段代码使用了 PyTorch 的
with torch.no_grad()
上下文管理器,用于在不需要计算梯度时执行代码。通常,这发生在一些不需要梯度信息的操作中,例如在验证或测试阶段,或者在某些预处理步骤中。
with torch.no_grad()::
- 这里使用了一个上下文管理器
with torch.no_grad(),它会在代码块执行期间禁用梯度计算。这意味着在这个代码块中进行的任何操作都不会更新模型参数,因为梯度不会被计算。for imgs, target in dataloader::
- 开始一个 for 循环,遍历数据加载器中的每个批次。
dataloader是之前定义的数据加载器,它负责从数据集中加载批次数据。imgs, target = imgs.to(device), target.to(device):
- 将当前批次的输入图像
imgs和标签target移动到指定的设备上。device通常是 ‘cuda’ 或 ‘cpu’,这取决于你的硬件配置。 在这个上下文管理器中,imgs.to(device)和target.to(device)操作不会计算梯度,因为它们在with torch.no_grad()上下文管理器内部。这通常用于在不需要梯度信息的操作中,例如在验证或测试阶段,或者在某些预处理步骤中。
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
‘’
‘’ ‘’ ‘’ test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4.正式训练
这段代码是一个简单的 PyTorch 训练循环,用于训练和评估一个神经网络模型。
for epoch in range(epochs)::
- 开始一个 for 循环,遍历预定的 epochs(通常表示训练周期或迭代次数)。
epochs是一个整数,表示训练过程中要进行的完整迭代次数。model.train():
- 将模型设置为训练模式。在训练模式下,模型会使用正确的激活函数和损失函数,以及任何其他训练相关的设置。
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt):
- 调用
train函数,使用训练数据加载器train_dl、模型model、损失函数loss_fn和优化器opt来计算当前 epoch 的训练准确率和损失。train_dl是之前定义的训练数据加载器,它负责从训练数据集中加载批次数据。opt是之前定义的优化器,用于更新模型参数。model.eval():
- 将模型设置为评估模式。在评估模式下,模型会使用正确的激活函数和损失函数,但不进行反向传播和参数更新。
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn):
- 调用
test函数,使用测试数据加载器test_dl、模型model和损失函数loss_fn来计算当前 epoch 的测试准确率和损失。test_dl是之前定义的测试数据加载器,它负责从测试数据集中加载批次数据。train_acc.append(epoch_train_acc):
- 将当前 epoch 的训练准确率
epoch_train_acc追加到train_acc列表中。train_acc是一个列表,用于存储每个 epoch 的训练准确率。train_loss.append(epoch_train_loss):
- 将当前 epoch 的训练损失
epoch_train_loss追加到train_loss列表中。train_loss是一个列表,用于存储每个 epoch 的训练损失。test_acc.append(epoch_test_acc):
- 将当前 epoch 的测试准确率
epoch_test_acc追加到test_acc列表中。test_acc是一个列表,用于存储每个 epoch 的测试准确率。test_loss.append(epoch_test_loss):
- 将当前 epoch 的测试损失
epoch_test_loss追加到test_loss列表中。test_loss是一个列表,用于存储每个 epoch 的测试损失。template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}'):
- 定义了一个字符串模板,用于格式化打印信息。
{:2d}表示整数,占位符宽度为 2,不足部分用空格填充;{:.1f}%表示浮点数,保留一位小数,并转换为百分比形式;{:.3f}表示浮点数,保留三位小数。print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss)):
- 使用定义的模板格式化并打印当前 epoch 的训练和测试准确率以及损失。
epoch+1表示当前 epoch 的编号,epoch_train_acc*100和epoch_test_acc*100分别将准确率转换为百分比形式,epoch_train_loss和epoch_test_loss保持原样。print('Done'):
- 打印字符串 ‘Done’,表示训练过程已经完成。 这个循环会重复执行,直到达到预定的 epochs 次数。每个 epoch 都会执行一次训练和一次测试,并将结果存储在列表中。最后,打印出每个 epoch 的训练和测试准确率以及损失,以及训练过程完成的提示。
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
输出
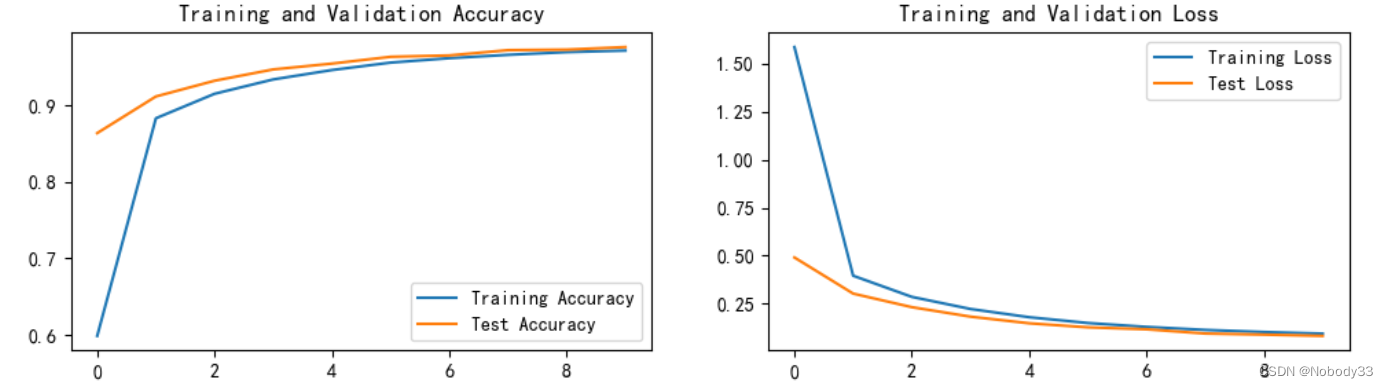
Epoch: 1, Train_acc:59.8%, Train_loss:1.585, Test_acc:86.4%,Test_loss:0.491
Epoch: 2, Train_acc:88.3%, Train_loss:0.396,
Test_acc:91.1%,Test_loss:0.303 Epoch: 3, Train_acc:91.5%,
Train_loss:0.286, Test_acc:93.2%,Test_loss:0.233 Epoch: 4,
Train_acc:93.4%, Train_loss:0.223, Test_acc:94.7%,Test_loss:0.183
Epoch: 5, Train_acc:94.6%, Train_loss:0.180,
Test_acc:95.5%,Test_loss:0.149 Epoch: 6, Train_acc:95.6%,
Train_loss:0.150, Test_acc:96.3%,Test_loss:0.128 Epoch: 7,
Train_acc:96.2%, Train_loss:0.130, Test_acc:96.5%,Test_loss:0.117
Epoch: 8, Train_acc:96.6%, Train_loss:0.114,
Test_acc:97.2%,Test_loss:0.095 Epoch: 9, Train_acc:97.0%,
Train_loss:0.103, Test_acc:97.3%,Test_loss:0.090 Epoch:10,
Train_acc:97.2%, Train_loss:0.095, Test_acc:97.6%,Test_loss:0.083 Done
四、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
五、神经网络构架解构
在神经网络构建中,网络层是实现特定功能的关键组成部分。以下是对核心层、嵌入层、卷积层、池化层、局部连接层、循环层、融合层、高级激活层、噪声层、标准化层等常见网络层的详细解释:
- 核心层(Core Layer):
核心层通常指的是神经网络中的隐藏层,它们位于输入层和输出层之间。核心层可以包含多个隐藏层,每个隐藏层由一定数量的神经元组成。核心层的作用是从输入数据中学习特征,并将这些特征传递到下一层。 - 嵌入层(Embedding Layer):
嵌入层通常用于处理离散型输入数据,如文本或类别特征。嵌入层将这些离散型数据映射到连续的数值空间,使得神经网络可以更好地学习这些特征。嵌入层通常用于自然语言处理任务中的词向量表示。 - 卷积层(Convolutional Layer):
卷积层主要用于处理图像数据,它通过卷积操作提取图像的局部特征。卷积层中的神经元只与输入数据的一部分连接,这样可以减少参数的数量,同时保持对图像局部结构的敏感性。卷积层在图像识别和计算机视觉任务中非常重要。 - 池化层(Pooling Layer):
池化层用于减小数据的维度,同时保留重要的特征信息。它通过对输入数据进行下采样操作,例如最大池化或平均池化,来降低数据的空间分辨率。池化层可以减少过拟合的风险,提高模型的泛化能力。 - 局部连接层(Locally Connected Layer):
局部连接层与卷积层类似,但它为输入数据的每个局部区域分别学习一组独立的过滤器。这意味着每个局部区域都有自己的权重和偏置参数,从而增加了模型的复杂度和参数数量。局部连接层在某些特定的任务中可能有用,但通常不如卷积层常用。 - 循环层(Recurrent Layer):
循环层用于处理序列数据,如时间序列数据或文本数据。循环层中的神经元不仅与输入数据连接,还与前一时刻的自身状态连接。这种循环结构使得循环层能够捕捉序列中的时间依赖关系,常用于自然语言处理和语音识别任务。 - 融合层(Fusion Layer):
融合层用于将来自不同来源或不同类型的数据进行整合。例如,在多模态学习任务中,融合层可以将图像和文本数据融合在一起,以便更好地学习跨模态的特征表示。 - 高级激活层(Advanced Activation Layer):
高级激活层用于引入非线性变换,以提高神经网络的表示能力。常见的激活函数包括ReLU、Sigmoid和Tanh等。高级激活层可以堆叠在核心层或卷积层之后,以增加模型的非线性。 - 噪声层(Noise Layer):
噪声层用于向输入数据添加噪声,以提高模型的鲁棒性和泛化能力。常见的噪声层包括Dropout层和Drop Connect层等。噪声层通过随机丢弃一部分神经元或连接,减少模型的过拟合风险。 - 标准化层(Normalization Layer):
标准化层用于对输入数据进行归一化处理,以加速神经网络的训练过程。常见的标准化方法包括批量归一化(Batch Normalization)和层归一化(Layer Normalization)等。标准化层有助于稳定梯度下降过程,提高模型的收敛速度。
这些网络层可以根据具体任务和需求进行组合和调整,以构建适合特定问题的神经网络模型。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









