







目录
(3)新建./config/st_gcn/kth/demo_kth.yaml文件
(4)新建./processor/demo_kth.py文件(参考demo_old.py文件)
(5)将yolo预测的json文件放到.\data\yolov8_estimation\data文件夹中
环境要求
python == 3.7.16
torch + cu116 == 1.13.1
torchaudio + cu116 == 0.13.1
torchvision + cu116 == 0.14.1
ultralytics == 8.0.145
stgcn
一、关节点骨架数据
1、姿态估计获取关节点数据
使用关节点追踪网络获取关节点数据,以yolo-v8网络为例,获取2D关节点数据。此次实验采用KTH动作识别数据集,包含人步行、慢跑、跑步、拳击、挥手和拍手等动作。
2、关节点数据格式处理
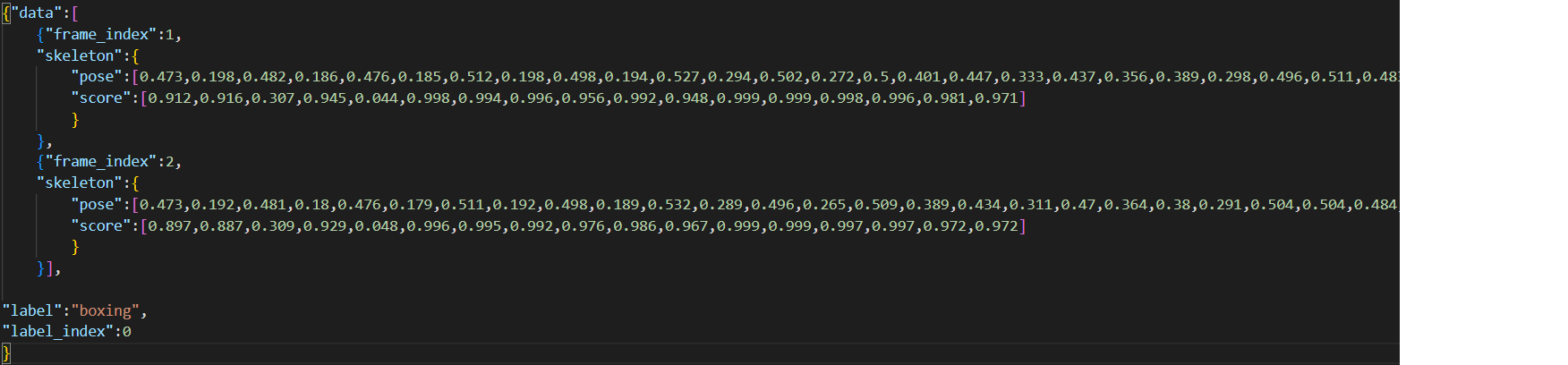
将每个视频的关节点数据打包成kinectics数据格式(此格式是kinectics数据集经过openpose输出的关节点格式数据,是stgcn默认使用的骨骼数据格式),其数据格式如图所示。其中:
frame_index是视频的帧索引
skeleton包含了关节点的坐标信息(pose)和置信度(score),逐一对应
label是整个视频的行为标签,
label_index是行为标签索引
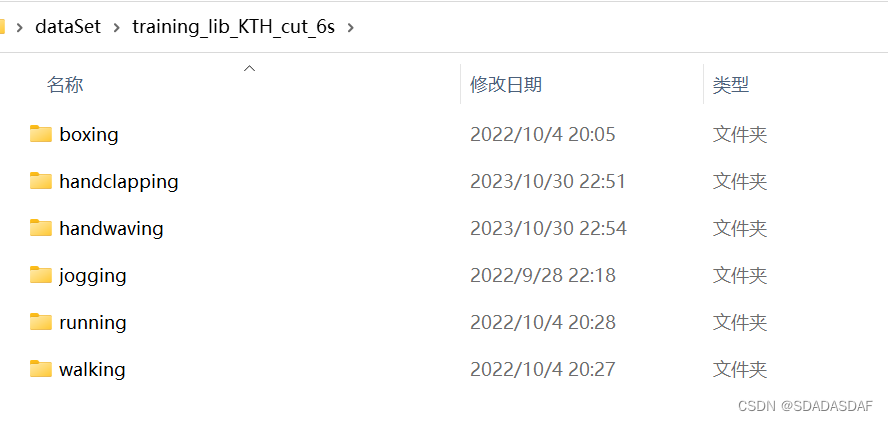
视频数据的存放如图:
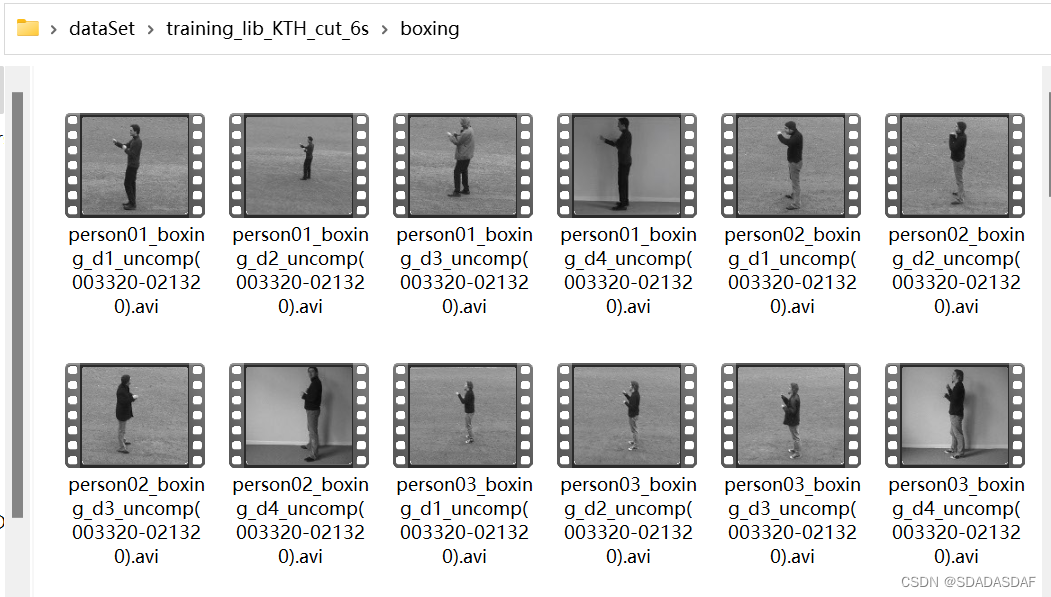
关节点识别和数据打包的完整代码如下:
#muti_video_generator.py
import ultralytics
from ultralytics import YOLO
import torch
import numpy as np
import cv2, time, os
import os
import custom
import json
def InputReader(path):
cap = cv2.VideoCapture("{}".format(path)) # 视频流读取
rate = cap.get(5) # 帧速率
FrameNumber = cap.get(7) # 视频文件的帧数
duration = FrameNumber / rate # 帧速率/视频总帧数 是时间,除以60之后单位是分钟
return cap, rate, FrameNumber, duration
def single_video_output(img, model):
result = model(img, imgsz=320, conf=0.5)[0]
custom.visiualize(img, result)
a = result.keypoints.conf
b = result.keypoints.xyn
#如果预测结果为空,则补0;a补n*1,b补n*2,n为关节点数目
if a == None:
a = torch.zeros(17).unsqueeze(0)
b = torch.zeros(34).unsqueeze(0).unsqueeze(0) # 需要 扩维度
# 输出 关键点
np1 = b[0].cpu().numpy()
np2 = np.around(np1, 3).flatten()
# 输出 置信度
conf1 = a.cpu().numpy()
conf2 = np.around(conf1, 3)[0]
point = [round(i, 3) for i in np2]
conf = [round(i, 3) for i in conf2]
return point, conf
class single_video_json_output():
def __init__(self):
self.model = YOLO('../YOLOV8/yolov8m-pose.pt') # 此处修改 model路径
self.capture = 'test.mp4'
self.class_name = 'none'
def _inference(self, name):
cap, rate, FrameNumber, duration = InputReader(self.capture)
labels = ['boxing', 'handclapping', 'handwaving', 'jogging', 'running', 'walking']
# json存储
frame_index = 0
jsdata = []
while cap.isOpened():
rec, img = cap.read()
if rec == False:
break
frame_index += 1
pose_data = {"pose": '', "score": ''}
frame_data = {"frame_index": 0, "skeleton": []}
point, conf = single_video_output(img, self.model)
point = [round(float(x), 3) for x in point] #数据保留小数点位数
conf = [round(float(x), 3) for x in conf]
# 字典内部存储 此处需要修改 因为有多个人的视频
pose_data = {"pose": point, "score": conf}
frame_data = {"frame_index": frame_index, "skeleton": [pose_data]} # 注意加个括号
if sum(point)==0:
frame_data = {"frame_index": frame_index, "skeleton": []}
jsdata.append(frame_data)
cv2.imshow('1', img)
del img
# 按q结束
if cv2.waitKey(1) == ord('q'):
break
output_data = {
"data": jsdata,
"label": self.class_name,
"label_index": labels.index(self.class_name)
}
# 拼接文件路径
file_path = '../data/KTH_original/' + self.class_name + '/' + name.split('.')[0] + '.json'
# 确保目录存在
directory = os.path.dirname(file_path)
os.makedirs(directory, exist_ok=True)
with open(file_path, "w") as json_file:
json.dump(output_data, json_file, indent=None, separators=(',', ':'))
# 运行 所有类别
if __name__ == '__main__':
all_path = '../dataSet/training_lib_KTH_cut_6s/' # 视频文件夹总路径
classes = os.listdir(all_path)
for single_class in classes:
PATH = all_path + single_class + '/'
a = single_video_json_output()
videos = os.listdir(PATH)
for video_name in videos:
a.class_name = single_class
a.capture = PATH + video_name
a._inference(video_name)
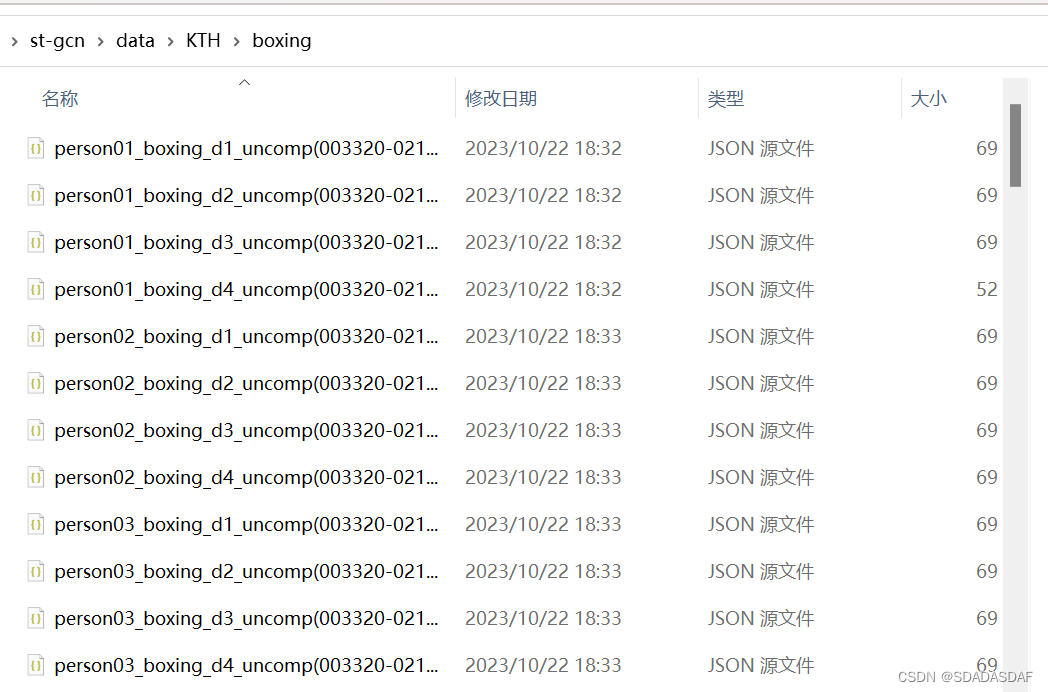
运行后,数据文件如下所示,每个视频对应一个json文件
(!注意:视频名称不要带.或空格,否则后续运行会出错)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6269
6269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









