







北京时间 4 月 15 日凌晨,GPT-4.1 系列模型悄然上线,以百万 token 上下文处理能力和 26% 的成本降幅,直接宣告了 GPT-4.5 的“死刑”。同时,GPT-4.1 以更低的成本、更长的记忆、更精准的指令控制,全面碾压 GPT-4o。
目前,该系列包含了三个模型,分别是 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano,已向所有开发者开放,但只能通过 API 调用,不过 GPT-4o 已经加入了GPT-4.1的部分功能。
GPT-4.1 系列最引人瞩目的,是其 100 万 token 的上下文窗口。这相当于同时塞进 8 套 React 源码或上千页法律文档,解决了长文本处理中的记忆碎片化难题。

在 OpenAI 的演示中,模型仅用 15 秒便从 45 万 token 的 NASA 日志中精准定位异常记录,而同类模型要么遗漏细节,要么因延迟过高而丧失了实用性。汤森路透测试显示,GPT-4.1 在多文档审查中的准确率比 GPT-4o 提升 17%,直接影响到数亿美元级法律纠纷的研判效率。
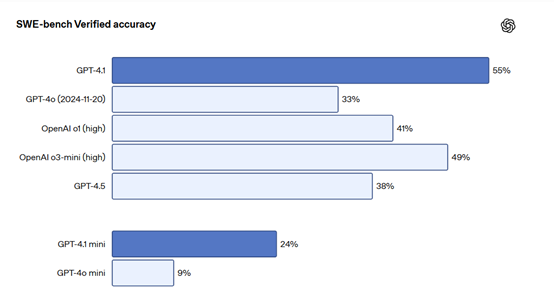
在 SWE-bench 测试中,GPT-4.1 的编码准确率高达 55%,远超 GPT-4o 的 33 %,甚至能以两倍效率完成跨语言代码优化。
在成本方面,GPT-4.1 系列通过提示缓存优化与推理栈重构,将中等规模查询成本降低 26%,而轻量版 GPT-4.1 nano 的每百万 token 成本仅为 12 美分,比谷歌 Gemini Flash 还低20%。
更狠的是,OpenAI 同步宣布将于三个月后的 7 月 14 日下线 GPT-4.5 预览版,开发者 API 的核心模型也将逐步替换成 GPT-4.1,这将吸引更多开发者接入 API,推动相关应用开发和业务拓展,提升 OpenAI 市场竞争力。
GPT-4.1 的发布,正在引发开发者生态的连锁反应。目前,Windsurf 等开发工具平台已宣布免费提供一周 GPT-4.1 体验;微软 Azure 则火速上线新模型,吸引企业用户迁移。
AI未来:场景穿透力成关键
OpenAI 的突袭,标志着 AI 竞争进入深水区——技术优势已从参数规模转向场景穿透力。

过去几年,科技巨头们围绕模型参数量展开激烈角逐,从 GPT-3 的 1750 亿参数到谷歌 PaLM 的 5400 亿参数,参数竞赛曾被视为衡量 AI 实力的核心指标。然而,随着通用大模型进入商业化落地阶段,行业逐渐意识到:参数规模的边际效益正在递减,真正决定技术价值的已转变为场景穿透能力。
一方面,参数竞赛带来的成本困境日益凸显。训练千亿级模型需要消耗数百万美元计算资源和数万度电力,但商业场景中 80% 的需求并不需要天文数字级的参数量。
其次,垂直领域的应用需求正呈现碎片化特征。例如,医疗影像识别和工业质检等场景对 AI 的实战能力要求远高于单纯的参数规模。
未来的模型策略可能将从“大而全”向“精细化、多层次”演进。大模型仍是基础,但围绕具体场景的轻量模型将成为未来生态的核心。这一转变或将重塑 AI 行业竞争格局,推动技术从云端向边缘设备渗透。


















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









