







一、介绍
CogVideo 是一款在开源社区 GitHub 上备受瞩目的 AI 驱动视频生成解决方案,其核心技术依托于前沿的深度学习算法和模型架构。以下是对 CogVideo 的详细介绍:
CogVideoX 是 清影 同源的开源版本视频生成模型。
下表展示我们提供的视频生成模型相关基础信息:
| 模型名 | CogVideoX-2B | CogVideoX-5B |
|---|---|---|
| 模型介绍 | 入门级模型,兼顾兼容性。运行,二次开发成本低。 | 视频生成质量更高,视觉效果更好的更大尺寸模型。 |
| 推理精度 | FP16(推荐)* , BF16, FP32,FP8*(E4M3,E5M2),INT8,不支持 INT4 | BF16(推荐) , FP16, FP32,FP8*(E4M3,E5M2),INT8,不支持 INT4 |
| 单 GPU 显存消耗`` | FP16: 18GB usingSAT/12.5GB using diffusers*``INT8: 7.8GB using diffusers with torchao* | BF16: 26GB usingSAT/20.7GB using diffusers*``INT8: 11.4GB using diffusers with torchao* |
| 多 GPU 推理显存消耗 | FP16: 10GB using diffusers*`` | BF16: 15GB using diffusers*`` |
| 推理速度``(Step = 50) | FP16: ~90* s | BF16: ~180* s |
| 微调精度 | FP16 | BF16 |
| 微调显存消耗(每卡) | 47 GB (bs=1, LORA)61 GB (bs=2, LORA)62GB (bs=1, SFT) | 63 GB (bs=1, LORA)80 GB (bs=2, LORA)75GB (bs=1, SFT)`` |
| 提示词语言 | English* | |
| 提示词长度上限 | 226 Tokens | |
| 视频长度 | 6 秒 | |
| 帧率 | 8 帧 / 秒 | |
| 视频分辨率 | 720 * 480,不支持其他分辨率(含微调) | |
| 位置编码 | 3d_sincos_pos_embed | 3d_rope_pos_embed`` |
| 下载链接 (Diffusers) | 🤗 HuggingFace [🤖 ModelScope](https://gitee.com/link?target=https://modelscope.cn/models/ZhipuAI/CogVideoX-2b)🟣 WiseModel | 🤗 HuggingFace [🤖 ModelScope](https://gitee.com/link?target=https://modelscope.cn/models/ZhipuAI/CogVideoX-5b)🟣 WiseModel |
| 下载链接 (SAT) | SAT |
数据解释
- 使用 diffusers 库进行测试时,启用了
enable_model_cpu_offload()选项 和pipe.vae.enable_tiling()优化,该方案未测试在非
NVIDIA A100 / H100 外的设备上的实际显存 / 内存占用。通常,该方案可以适配于所有 NVIDIA 安培架构
以上的设备。若关闭优化,显存占用会成倍增加,峰值显存约为表格的 3 倍。 - 多 GPU 推理时,需要关闭
enable_model_cpu_offload()优化。 - 使用 INT8 模型会导致推理速度降低,此举是为了满足显存较低的显卡能正常推理并保持较少的视频质量损失,推理速度大幅降低。
- 2B 模型采用
FP16精度训练, 5B 模型采用BF16精度训练。我们推荐使用模型训练的精度进行推理。 - PytorchAO 和 Optimum-quanto
可以用于量化文本编码器、Transformer 和 VAE 模块,以降低 CogVideoX 的内存需求。这使得在免费的 T4 Colab 或更小显存的 GPU
上运行模型成为可能!同样值得注意的是,TorchAO 量化完全兼容torch.compile,这可以显著提高推理速度。在NVIDIA H100
及以上设备上必须使用FP8精度,这需要源码安装torch、torchao、diffusers和acceleratePython
包。建议使用CUDA 12.4。 - 推理速度测试同样采用了上述显存优化方案,不采用显存优化的情况下,推理速度提升约 10%。 只有
diffusers版本模型支持量化。 - 模型仅支持英语输入,其他语言可以通过大模型润色时翻译为英语。
更多详细信息见 Github 仓库。
二、部署
本文档针对ComfyUI进行部署使用,因此在正式部署之前需要部署ComfyUI
显存>=18G
CUDA版本>=11.8
1. 部署ComfyUI
本篇的模型部署是在ComfyUI的基础上进行,如果没有部署过ComfyUI,请按照下面流程先进行部署,如已安装请跳过该步:
(1)使用命令克隆 ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
(2)安装 conda(如已安装则跳过)
下面需要使用 Anaconda 或 Mimiconda 创建虚拟环境,可以输入 conda --version 进行检查。下面是 Mimiconda 的安装过程:
- 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
- 遵循安装提示并初始化
按 Enter 键查看许可证条款,阅读完毕后输入 yes 接受条款,安装完成后,脚本会询问是否初始化 conda 环境,输入 yes 并按 Enter 键。
- 运行
source ~/.bashrc命令激活 conda 环境 - 再次输入
conda --version命令来验证是否安装成功,如果出现类似conda 4.10.3这样的输出就成功了。
(3)创建虚拟环境
输入下面的命令:
conda create -n comfyui
conda activate comfyui
(4)安装 pytorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
(5)安装项目依赖
pip install -r requirements.txt
此时所需环境就已经搭建完成,通过下面命令进行启动:
python main.py
访问网址得到类似下图界面即表示成功启动:

到这里Comfy UI就初步搭建好了(这里只是简单实现ComfyUI的基础功能,如果想要安装更多细节,请看我“Comfy UI”部署教程)
2. 部署CogVideoX模型
(1)下载模型
CogVideoX-5b
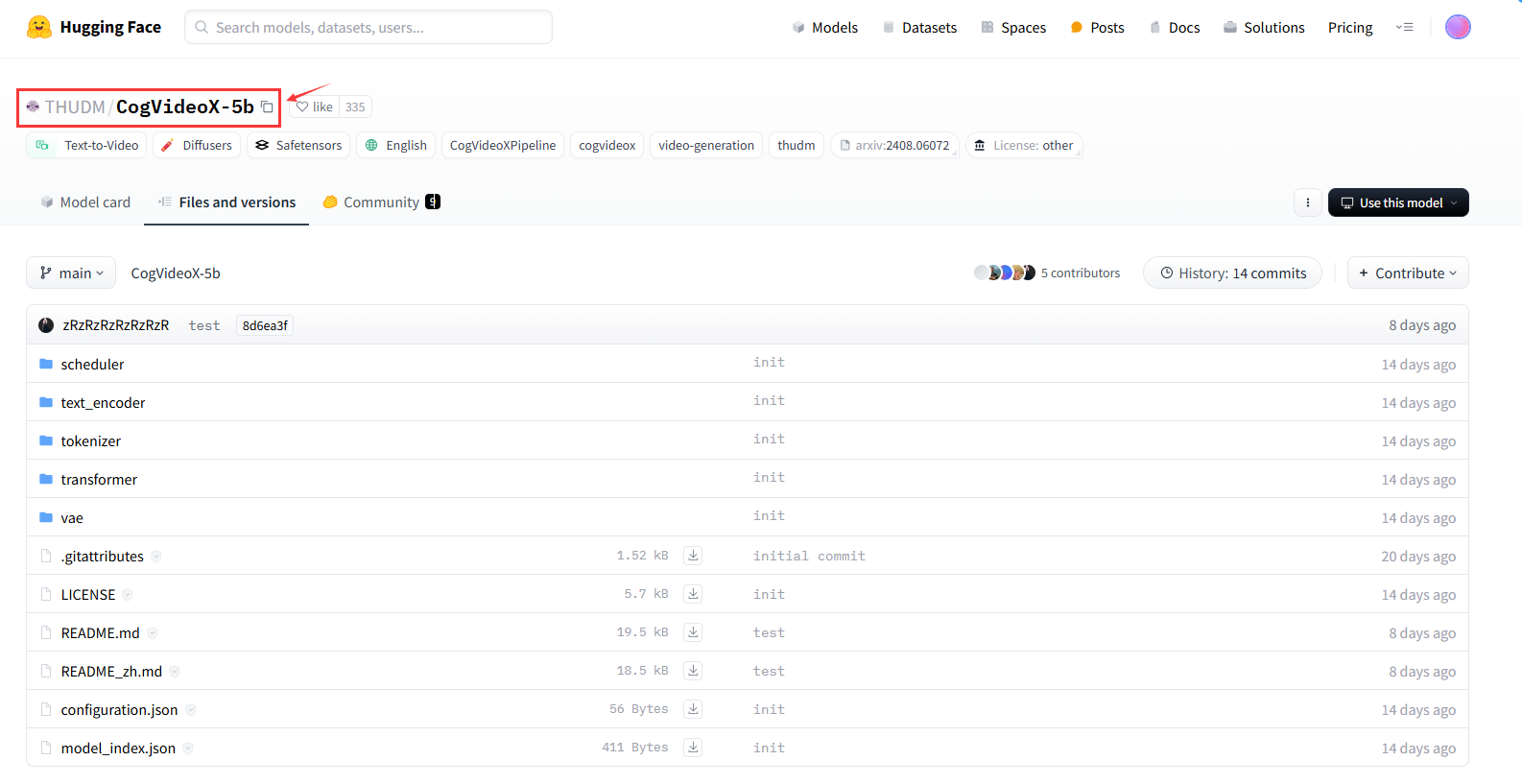
在hugging face搜索“THUDM/CogVideoX-5b”然后下载文件夹到 ComfyUI/models/CogVideo/CogVideoX-5b 下,如下图:
CLIP模型
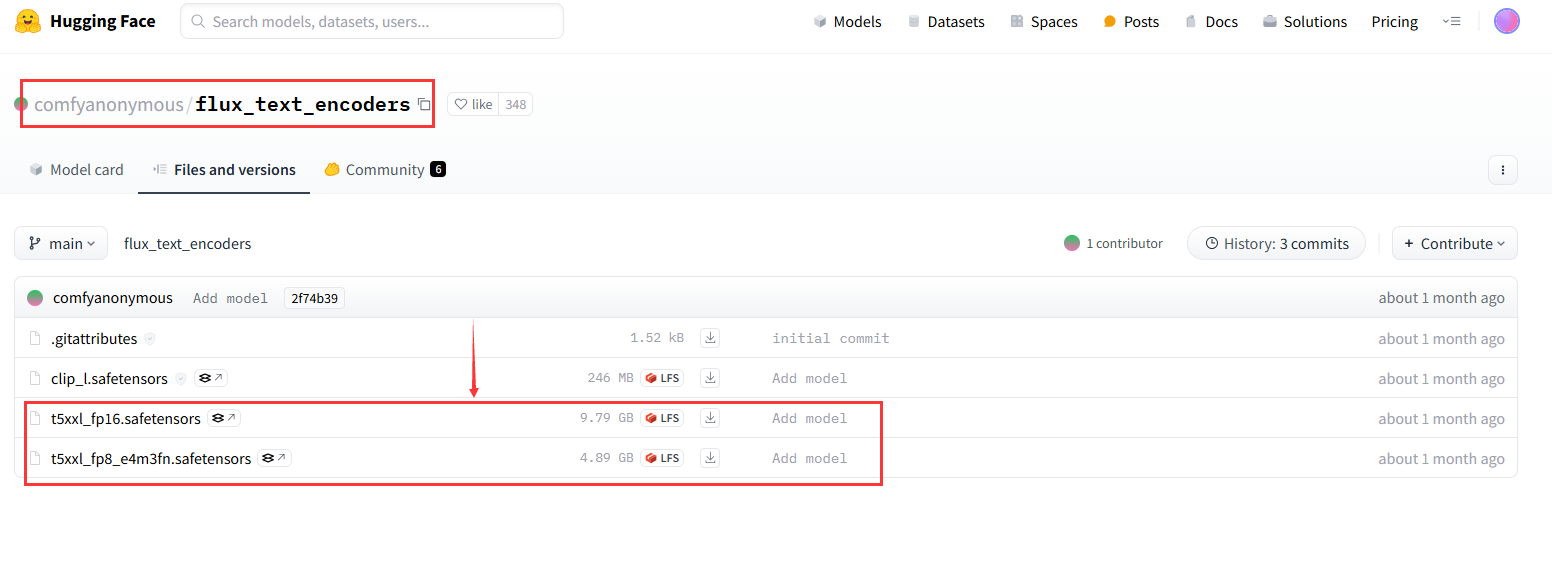
在hugging face搜索“comfyanonymous/flux_text_encoders”点击进入,下载t5xx模型到 /ComfyUI/model/clip/下,下图显示有两个模型,根据自己情况选择下载:
(2)安装项目
如果已经安装“ComfyUI-Manager”管理器,则可通过该节点安装项目,如下图:
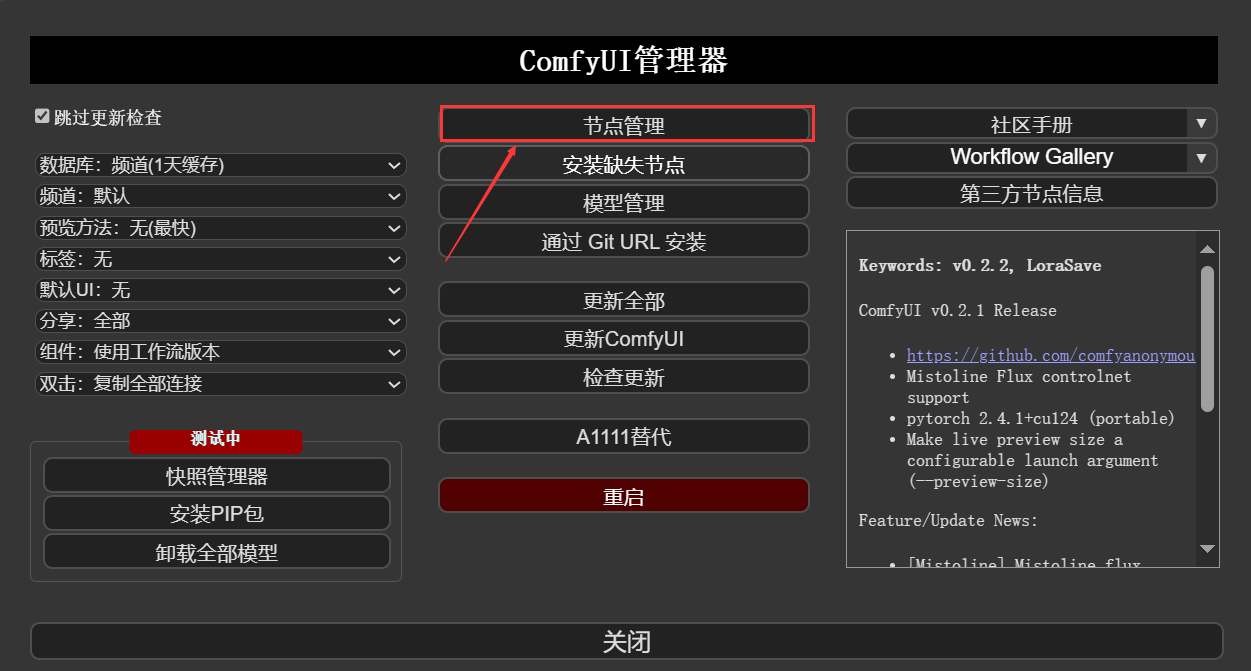
点击进入后搜索下面节点进行安装:


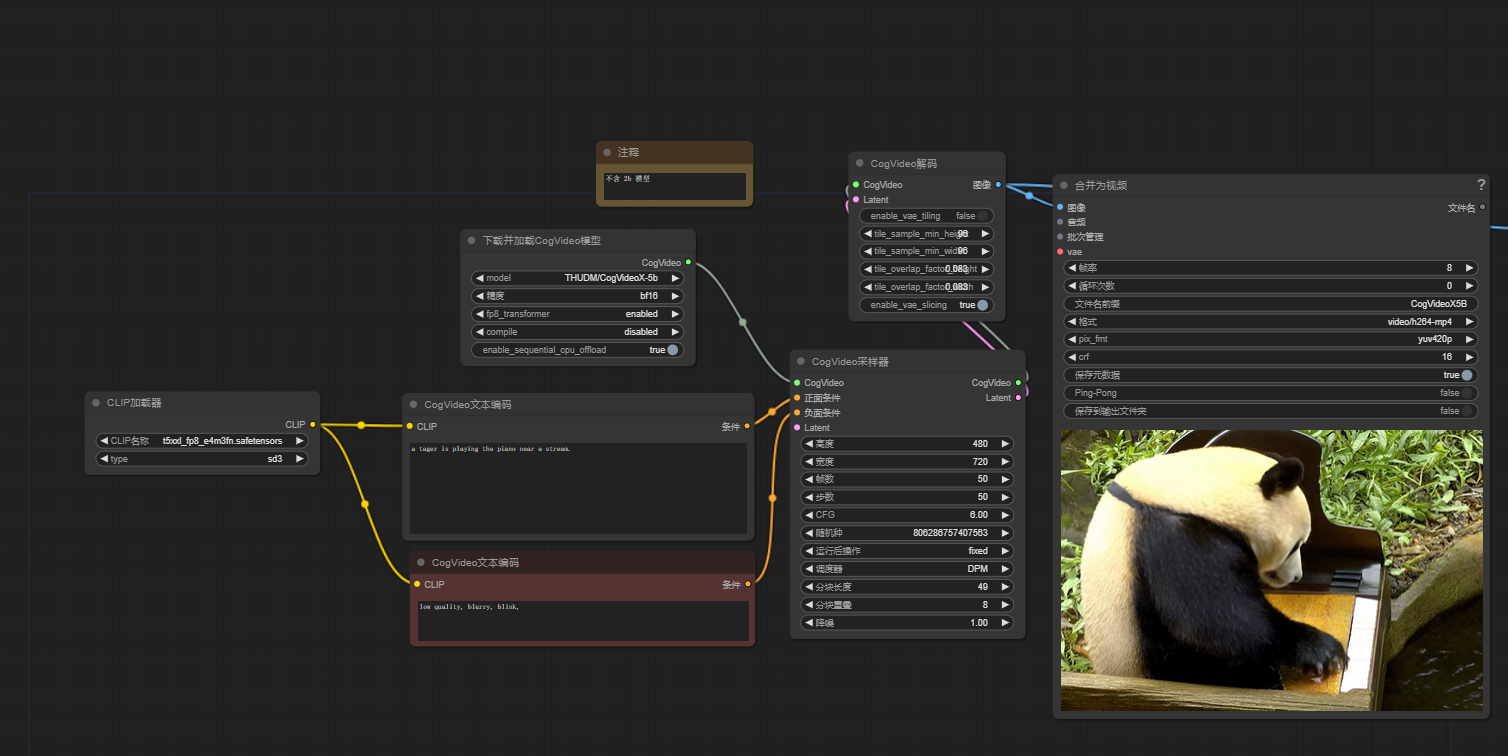
安装完成之后在路径 /ComfyUI/custom_nodes/ComfyUI-CogVideoXWrapper/examples/ 中可找到官方的工作流: cogvideox_5b_example_01.json下载(Ctrl+C和Ctrl+V粘贴也可)拖入界面即可,类似下图:
至此模型就部署完成


















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









