







一、 大模型 ChatGLM3 简介
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能 *。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。
二、大模型 ChatGLM3 微调步骤
1. 结束当前运行(按键盘上的 Ctrl + C)
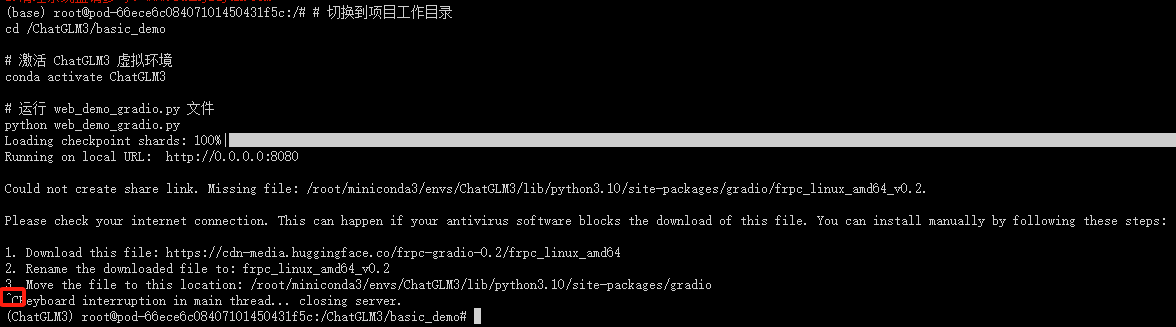
2. 安装模型依赖库
- 切换到项目目录、激活 ChatGLM3 虚拟环境、安装 requirements.txt 依赖
# 切换到 ChatGLM3 项目工作目录
cd /ChatGLM3/finetune_demo
# 激活 ChatGLM3 虚拟环境
conda activate ChatGLM3
# 在 ChatGLM3 环境中安装 requirements.txt 依赖
pip install -r requirements.txt
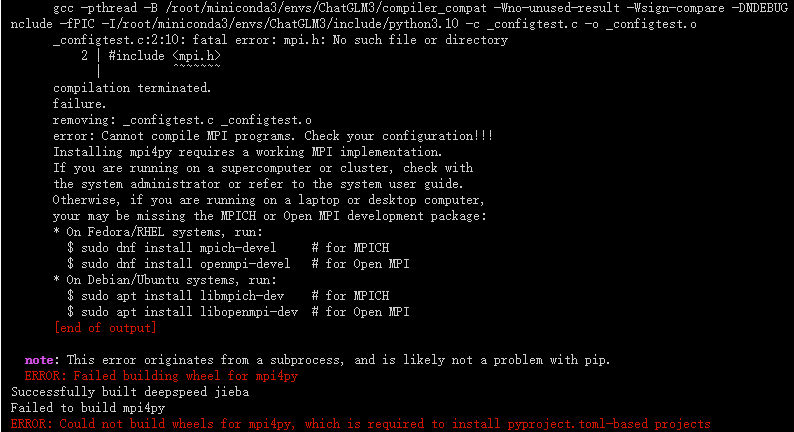
出现以上报错,需要修改 requirements.txt 文件
vim requirements.txt
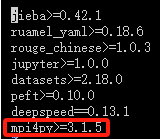
鼠标往下滑,找到最后一行 双击键盘上的 d 键,即可快速删除
继续执行依赖安装命令
# 在 ChatGLM3 环境中安装 requirements.txt 依赖
pip install -r requirements.txt

3. 准备数据集
3.1 创建文件夹 data 以及 子文件夹 AdvertiseGen
- 创建 data 文件夹
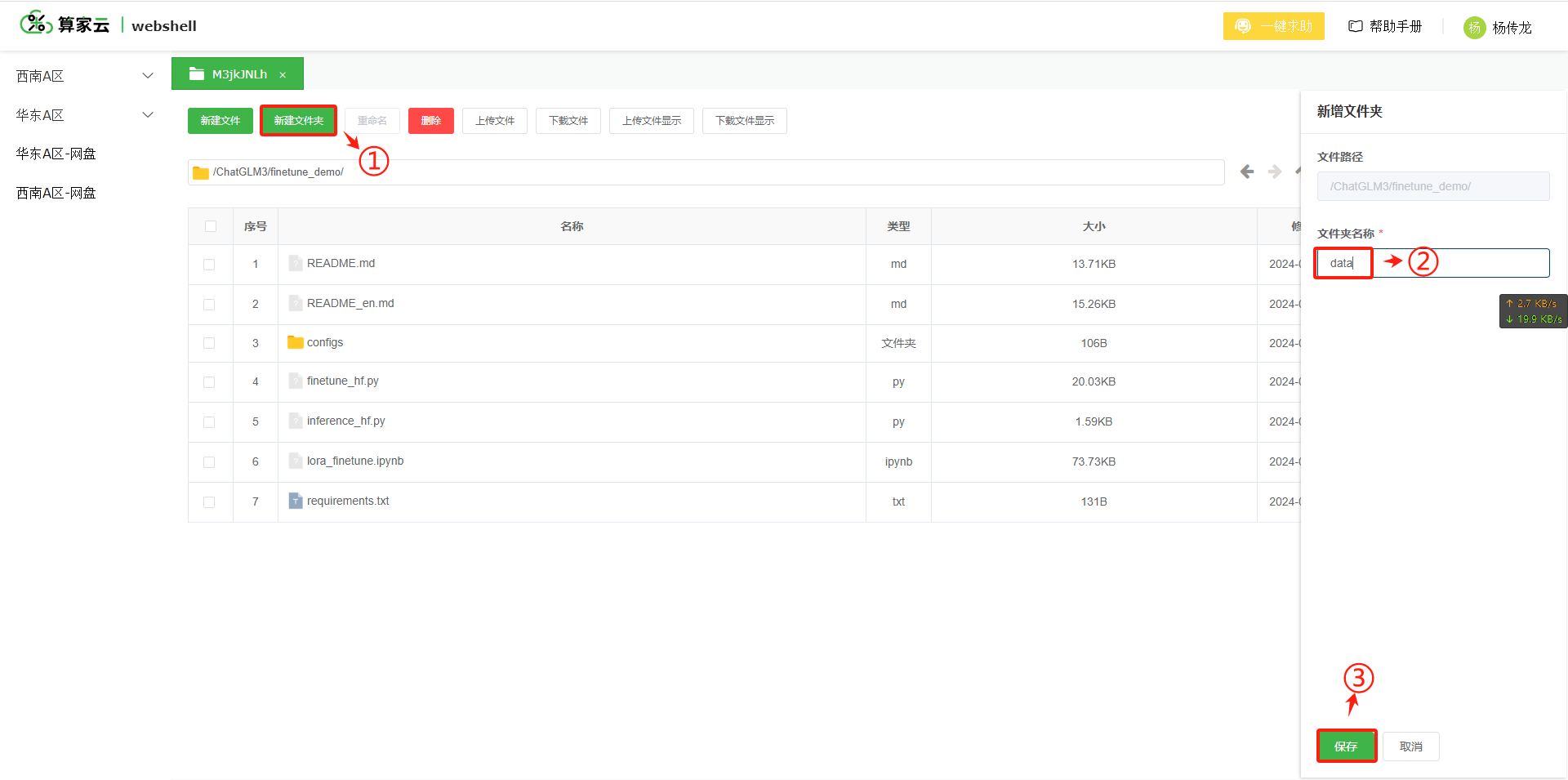
- 同样的方式创建 AdvertiseGen 子文件夹

3.2 上传数据集
我们使用 AdvertiseGen 数据集来进行微调。从 Google Drive 或者 Tsinghua Cloud 下载处理好的 AdvertiseGen 数据集,将解压后的 AdvertiseGen 目录放到本目录的 /data/ 下, 例如。/ChatGLM3/finetune_demo/data/AdvertiseGen
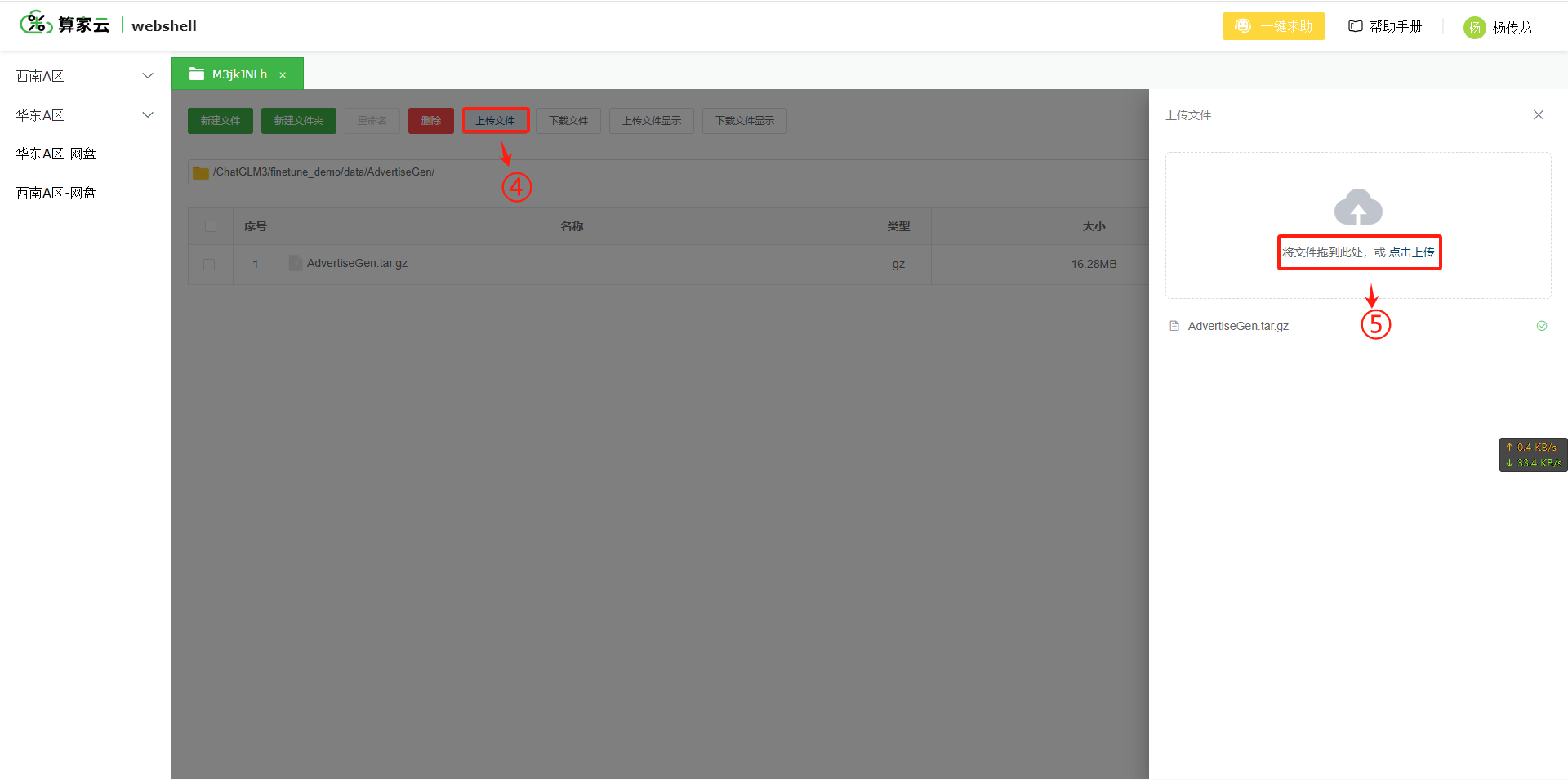
3.3 解压数据集
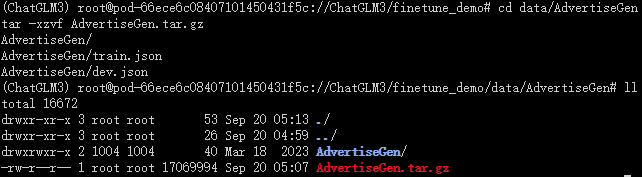
cd data/AdvertiseGen
tar -xzvf AdvertiseGen.tar.gz
这里的选项解释如下:
x代表解压。z代表 gzip 压缩(.gz)。v代表在解压时显示过程(verbose 模式)。f代表后面跟着的是文件名。
3.4 转换数据格式
- 创建 AdvertiseGen_fix.py 文件
# 切换到 ChatGLM3 项目工作目录
cd /ChatGLM3/finetune_demo
# 创建 AdvertiseGen_fix.py 文件
vim AdvertiseGen_fix.py
- 插入以下代码
import json
from typing import Union
from pathlib import Path
def _resolve_path(path: Union[str, Path]) -> Path:
return Path(path).expanduser().resolve()
def _mkdir(dir_name: Union[str, Path]):
dir_name = _resolve_path(dir_name)
if not dir_name.is_dir():
dir_name.mkdir(parents=True, exist_ok=False)
def convert_adgen(data_dir: Union[str, Path], save_dir: Union[str, Path]):
def _convert(in_file: Path, out_file: Path):
_mkdir(out_file.parent)
with open(in_file, encoding='utf-8') as fin:
with open(out_file, 'wt', encoding='utf-8') as fout:
for line in fin:
dct = json.loads(line)
sample = {'conversations': [{'role': 'user', 'content': dct['content']},
{'role': 'assistant', 'content': dct['summary']}]}
fout.write(json.dumps(sample, ensure_ascii=False) + '\n')
data_dir = _resolve_path(data_dir)
save_dir = _resolve_path(save_dir)
train_file = data_dir / 'train.json'
if train_file.is_file():
out_file = save_dir / train_file.relative_to(data_dir)
_convert(train_file, out_file)
dev_file = data_dir / 'dev.json'
if dev_file.is_file():
out_file = save_dir / dev_file.relative_to(data_dir)
_convert(dev_file, out_file)
convert_adgen('data/AdvertiseGen/AdvertiseGen', 'data/AdvertiseGen_fix')
- 运行 AdvertiseGen_fix.py 文件
# 运行 AdvertiseGen_fix.py 文件
python AdvertiseGen_fix.py
4. 使用命令行开始微调,我们使用 lora 进行微调
接着,我们仅需要将配置好的参数以命令行的形式传参给程序,就可以使用命令行进行高效微调。
python finetune_hf.py /ChatGLM3/finetune_demo/data/AdvertiseGen_fix /ChatGLM3/basic_demo/THUDM/ZhipuAI/chatglm3-6b configs/lora.yaml

出现以上问题,需要安装 nltk 依赖
# 安装 nltk 依赖
pip install nltk

再次执行微调命令
python finetune_hf.py /ChatGLM3/finetune_demo/data/AdvertiseGen_fix /ChatGLM3/basic_demo/THUDM/ZhipuAI/chatglm3-6b configs/lora.yaml
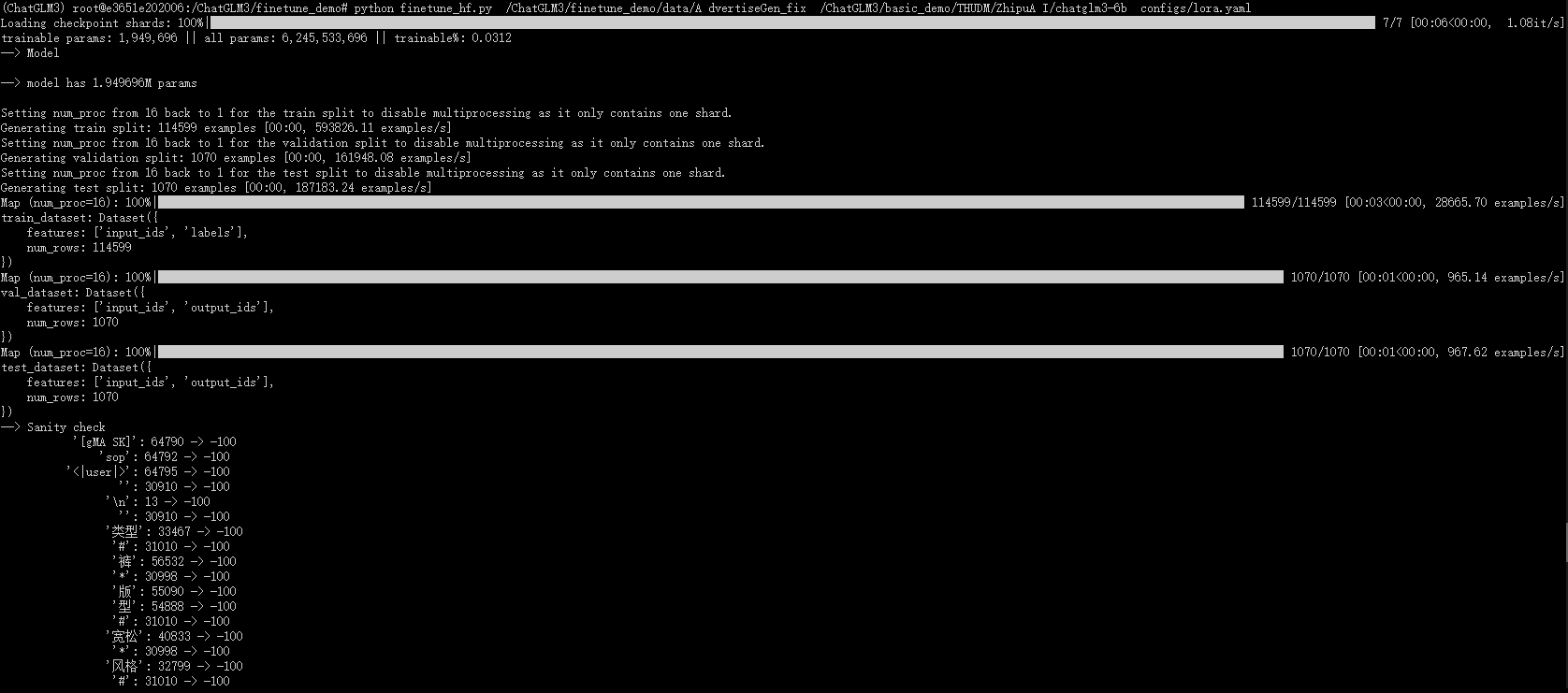
微调完成

5. 微调验证以及推理
- 找到模型保存点路径
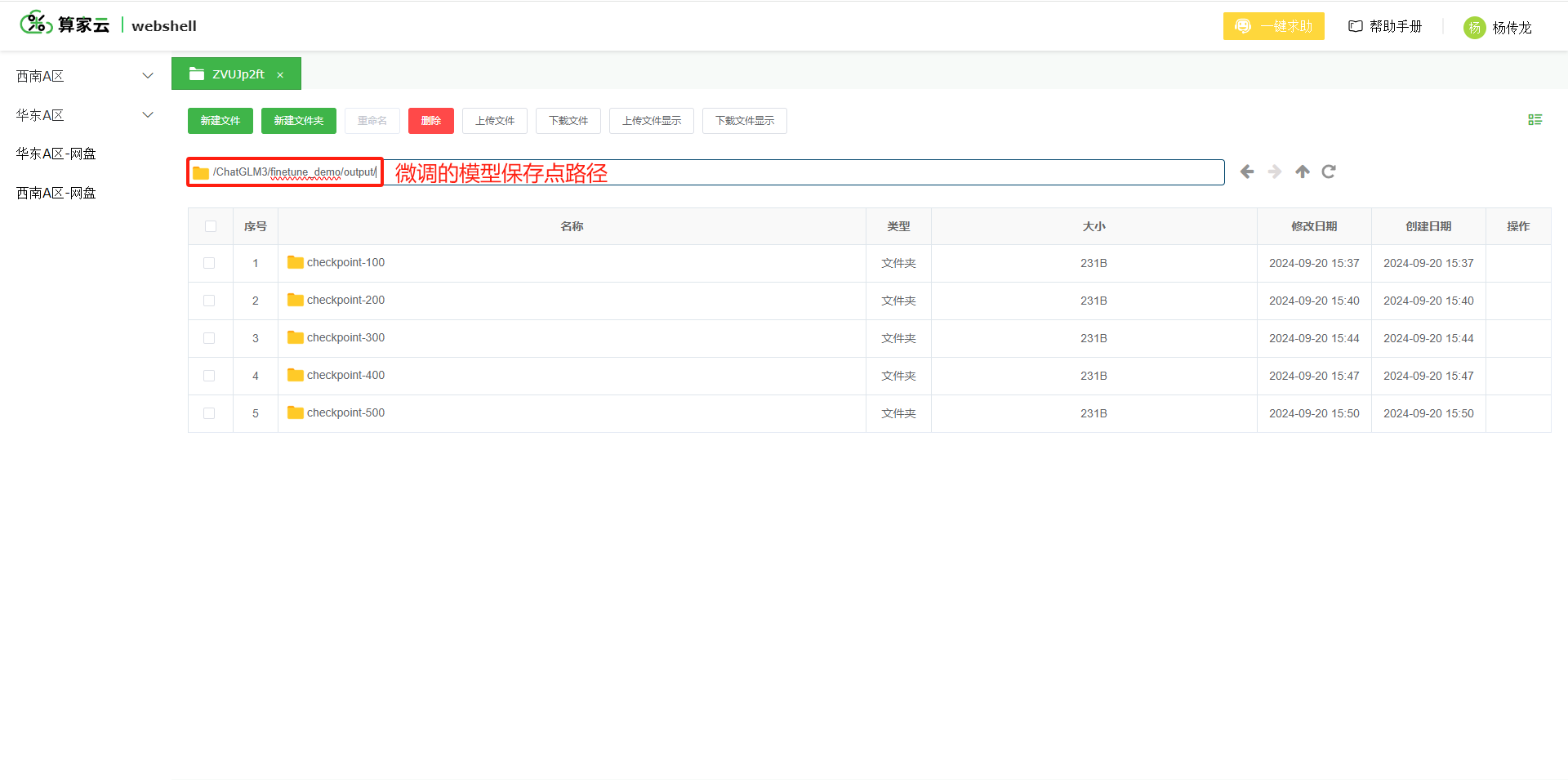
- 执行推理命令
python inference_hf.py output/checkpoint-500/ --prompt "类型#裙*版型#显瘦*材质#网纱*风格#性感*裙型#百褶*裙下摆#压褶*裙长#连衣裙*裙衣门襟#拉链*裙衣门襟#套头*裙款式#拼接*裙款式#拉链*裙款式#木耳边*裙款式#抽褶*裙款式#不规则"



















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









