







在人工智能领域,大模型参数规模已成为衡量技术实力的核心指标之一。
当全球科技巨头仍在为训练万亿参数模型寻求硬件突破时,华为昇腾团队凭借6000+块国产NPU集群,成功实现7180亿参数MoE模型的稳定训练,这一成就不仅标志着中国在AI算力领域迈入全球第一梯队,更预示着国产AI算力格局的深刻变革。

技术突破:从架构优化到系统协同的创新
华为此次突破的核心,在于构建了算法、框架、硬件深度协同的创新体系。
面对MoE模型特有的负载均衡难题,团队首创动态路由与静态架构融合设计:通过细粒度专家与共享专家的混合架构,结合TP8×EP4超融合并行策略,既保证了模型表达能力,又避免了传统MoE架构因专家资源分配不均导致的效率损耗。
在通信瓶颈攻坚中,研发团队针对万亿参数模型训练中"通信墙"问题,独创分级EP通信机制,通过机内AlltoAll与机间Allgather的混合调度,将跨机通信量降低。配合自适应前反向掩盖策略,实现计算与通信的完全重叠。
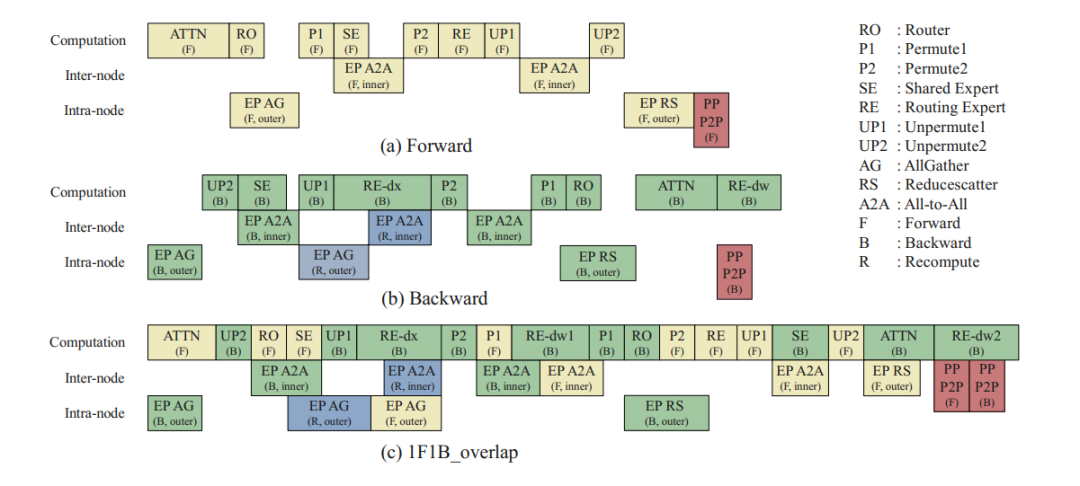
这种将通信开销隐藏于计算周期内的设计,打破了分布式训练的扩展性天花板。
硬件适配层面,则通过将张量对齐至256维度以匹配昇腾NPU的16×16矩阵计算单元,使硬件算力释放效率直线提升。
更值得关注的是动态负载均衡机制:规划器基于历史负载预测进行专家迁移,执行器以分钟级频率调整参数分布,这种软硬件协同的动态调度,使设备间任务均衡度达到95%以上,空泡率从18.98%骤降至10.49%。
国产算力突破的多维影响
这项技术突破的战略意义远超技术本身。
当全球AI产业面临英伟达GPU供应不确定性时,华为昇腾平台展现出自主可控的独特优势。
华为开创的建模仿真工具链,将模型结构、并行策略、硬件特性解构为可配置参数,通过算子级模拟实现性能预估,使参数搜索空间压缩99.9%。这种"软件定义硬件"的研发模式,将模型迭代周期从数月缩短至周级,为AI大模型快速进化提供了基础设施保障。
对于AI科研范式而言,这种建模仿真工具链具有革命性意义。
而技术报告披露的TP-extend-EP技术、VPP流水线调度等创新,本质上构建了AI训练系统的"方法论体系"。
当这些技术细节通过开源社区扩散,将加速培养既懂算法又精通系统的复合型人才,或许将推动中国形成完整的AI基础设施创新生态。
万亿参数时代的算力重构
全球AI算力市场正经历着根本性转折。据IDC预测,2025年全球AI服务器市场规模将突破1587亿美元,其中生成式AI服务器占比将达到29.6%。
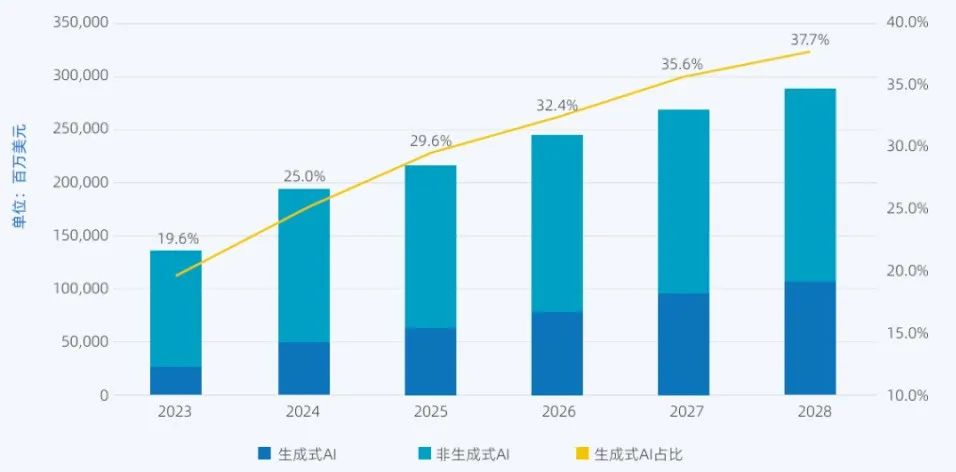
【图片来源:IDC,2025】
国产算力的崛起正在改写全球竞争规则。
在这场改变人类生产方式的算力革命中,华为昇腾团队用代码书写了中国创新的新范式。
当6000块国产NPU组成的集群点亮准万亿参数模型的训练之光时,我们看到的不仅是技术突破,更是一个科技强国在AI时代的战略定力——这种定力,终将转化为重塑全球产业格局的磅礴力量。


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









