









细节:
1.一块好的GPU相比CPU可以提升大约20-50倍的速度
2.使用relu而不使用sigmoid的原因主要是1)sigmoid求导比较麻烦。2)当网络比较深时,容易出现梯度消失的问题
3.过拟合现象

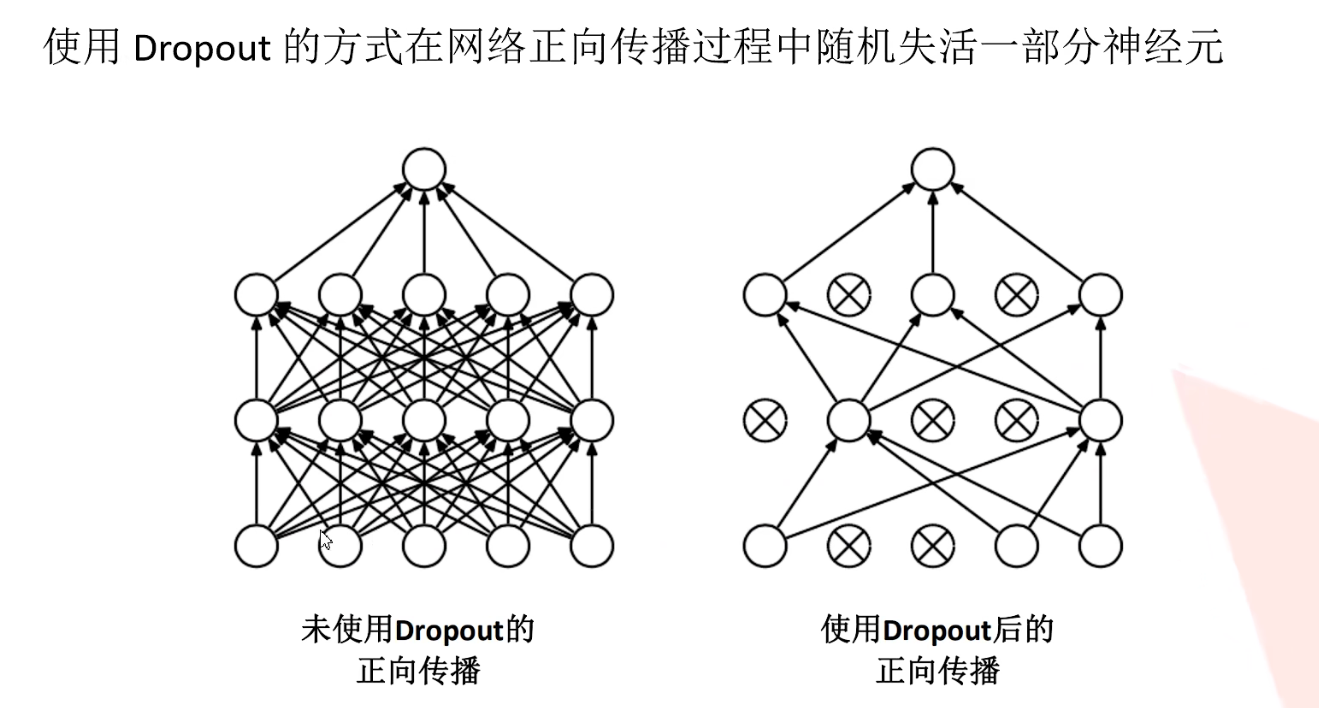
使用dropout可以减小参数来防止过拟合
二、AlexNet网络结构

这个网络可以分成两个部分,主要是由于作者当前使用了两块GPU,进行了并行计算,我们可以只看一部分。另一部分相同
1.conv1(网络第一个卷积层)

根据作者论文给的图可以看到输入特征图大小为[224, 224, 3],卷积层大小为[11 * 11* 96],这里步长为4,上面和左边padding =1, 下面和右边padding = 2,因此输出为 N = [224 - 11 + (1 + 2)] / 4+ 1 = 55,则输出为[55 * 55 * 96]

第一个maxpooling层,这一层,卷积核大小为3 * 3,步长为2,计算后输出特征图大小为(55 - 3) / 2 + 1 = 27
以下不再用图,我们画表格来描述网络结构
操作 | 大小 | 输入特征图大小 | 输出特征图大小 |
Conv1 | 卷积层为:96个11 * 11 * 3的卷积核 步长F:2 Padding:上面与左边padding = 1 下面与右边padding = 2 | 224 *224 *3 | 55 * 55 *96 |
Maxpool1 | 大小为3 * 3 步长:2 | 55 * 55 * 96 | 27 * 27 * 96 |
Conv2 | 卷积层:256个5 * 5 * 96的卷积核 步长:1 Padding = 2 | 27 * 27 * 96 | 27 * 27 * 256 |
Maxpool2 | 大小为3 * 3 步长:2 | 27 * 27 * 256 | 13 * 13 * 256 |
Conv3 | 卷积层:384个3 * 3 * 256的卷积核 步长为:1 Padding = 1 | 13 * 13 * 256 | 13 * 13 * 384 |
Conv4 | 卷积层:384个3 * 3 * 384的卷积核 步长:1 Padding = 1 | 13 * 13 * 384 | 13 * 13 * 384 |
Conv5 | 卷积层:256个3 * 3 * 256的卷积核 步长:1 Padding = 1 | 13 * 13 * 384 | 13 * 13 * 256 |
Maxpool3 | 大小为:3 * 3 步长:2 | 13 * 13 * 256 | 6 * 6 * 256 |
Dense1 |
| 6 * 6 * 256 | 4096 |
Dense2 |
| 4096 | 4096 |
Dense3 |
| 4096 | 1000 |
以上就是AlexNet的网络结构
二、花数据集
接下来我们下载数据集
下载地址: https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz

划分数据集
运行split_data.py即可
可以设定训练集和测试集比例大小
split.py代码如下:
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()















 6245
6245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









