







Week6:Advice for Applying Machine Learning&Machine Learning System Design
如果发现H(x)预测得不好
有几种方式
1. 使用更多训练样本
2. 减少特征数量
3. 增加特征的数量
4. 增加多项式特征
5. 增加或减少
λ
选择最正确的方法很重要
Machine Learning Diagnostic机器学习诊断法
通过它可以判断哪些对学习算法影响不大,以及找到合适的方式去改善学习算法
Evaluating a Hypothesis评估假设函数
MisclassificationError误分类错误

对Dataset进行拆分,拆成60%TrainingSet训练集 20%CrossValidationSet验证集 20%TestSet测试集
ModelSelection模型选择
- 在下图中,先根据 TrainingSet中的数据利用
minθJ(θ)
求得
d
次多项式中合适的
θ(i) 值 - 在这
d
个
i 次多项式的Model分别代入CrossValidationSet的值然后选择 Jcv(θ(i)) 值最小第 i 个模型作为合适的模型 - 假设现在选择了第4个模型
h(4)θ(x) 作为合适的模型,这个时候把TestSet中的数据代入 h(4)θ(x) 再估算 Jtest(θ(4)) 的值,这样子就可以测试该模型是否合理


高偏差与高方差
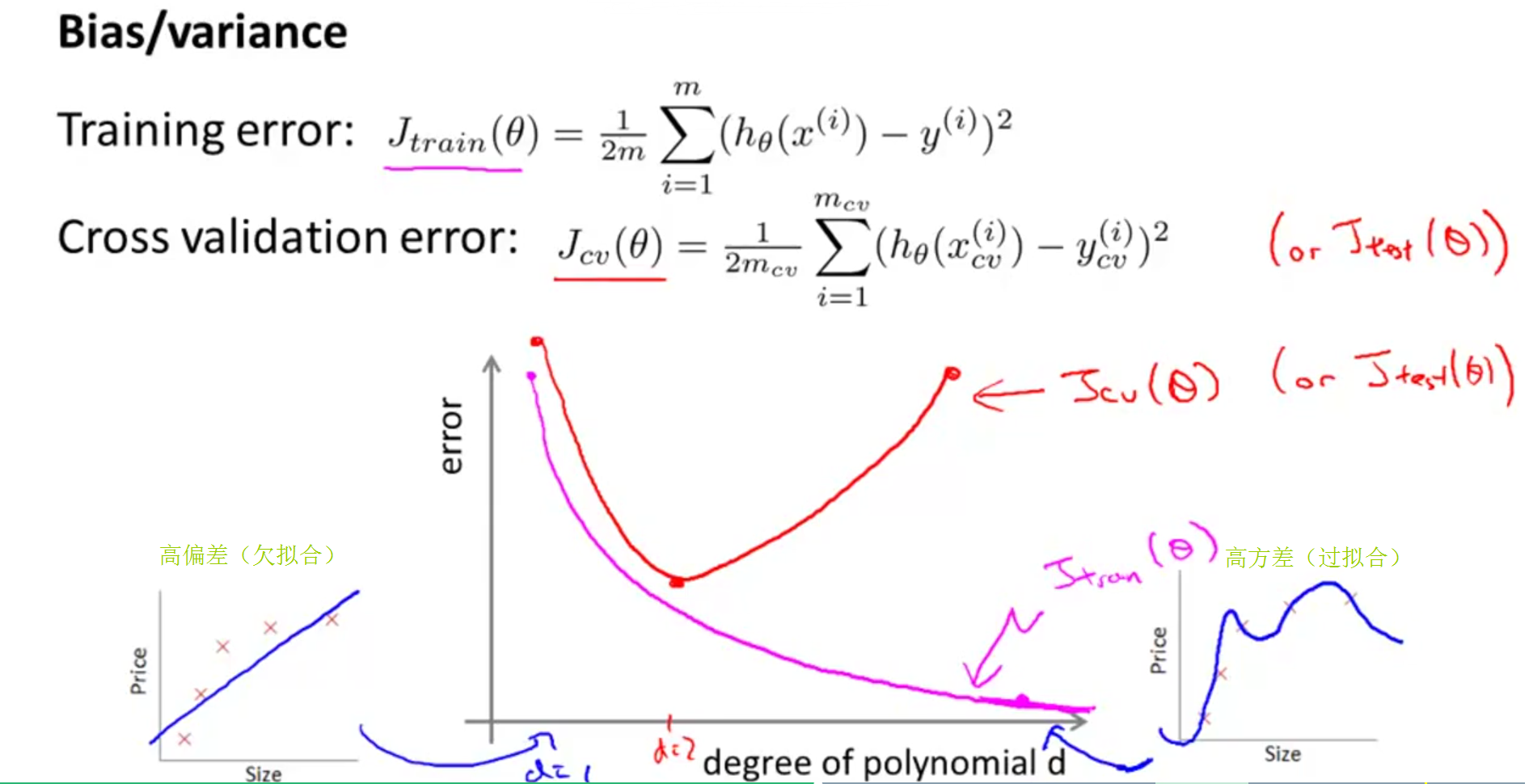
高偏差(欠拟合):
Jtrain(θ)
值比较大且
Jcv(θ)≈Jtrain(θ)
高方差(过拟合):
Jtrain(θ)
值比较小且
Jcv(θ)>>Jtrain(θ)

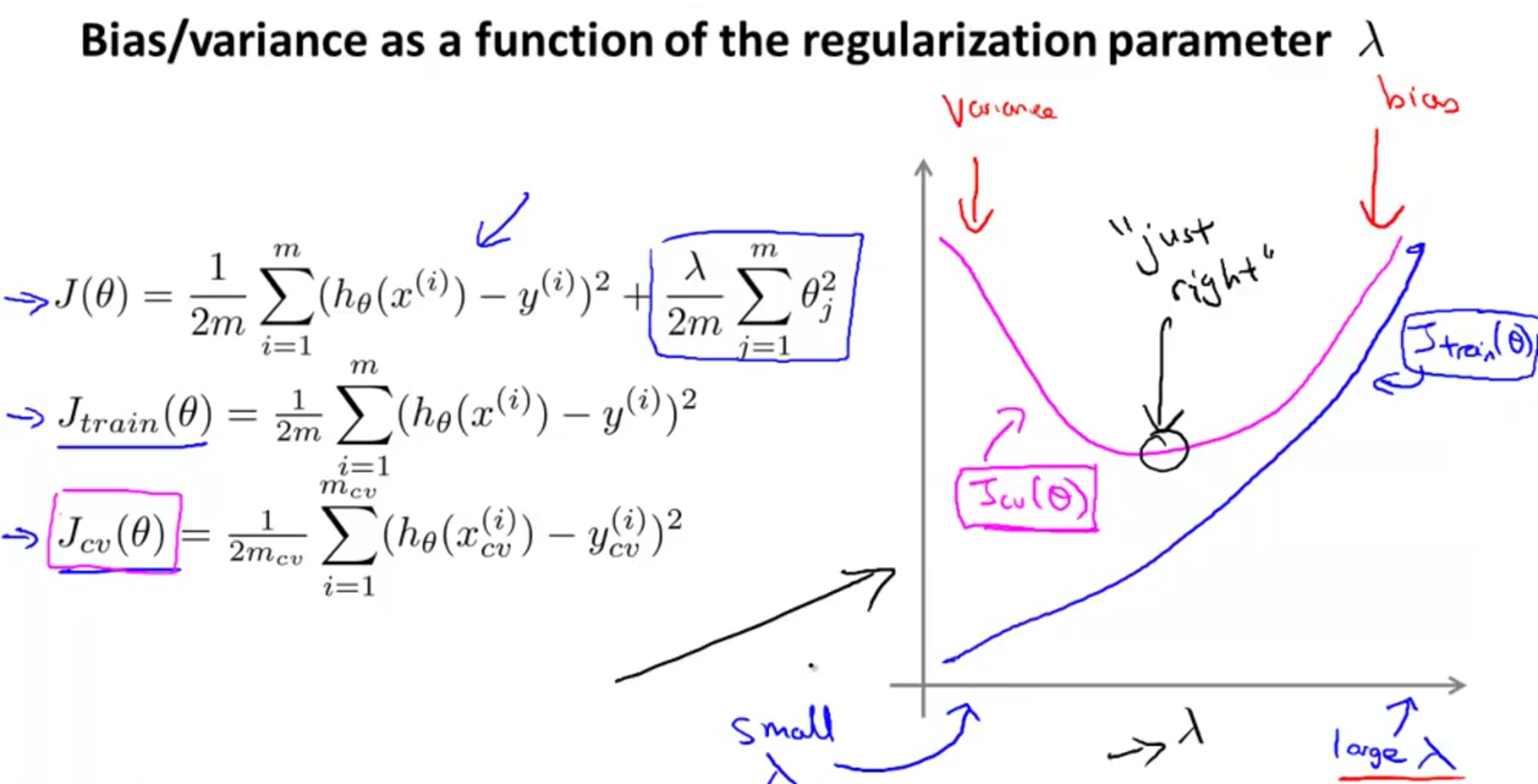
正则化的时候
当
λ
值太小时,虽然最后的结果拟合的比较好,但variance(方差)会比较大
当
λ
值太大时,
θj
的值都会比较小,会导致最后的
hθ(x)
的函数近似为常函数,即bias(偏差)比较大
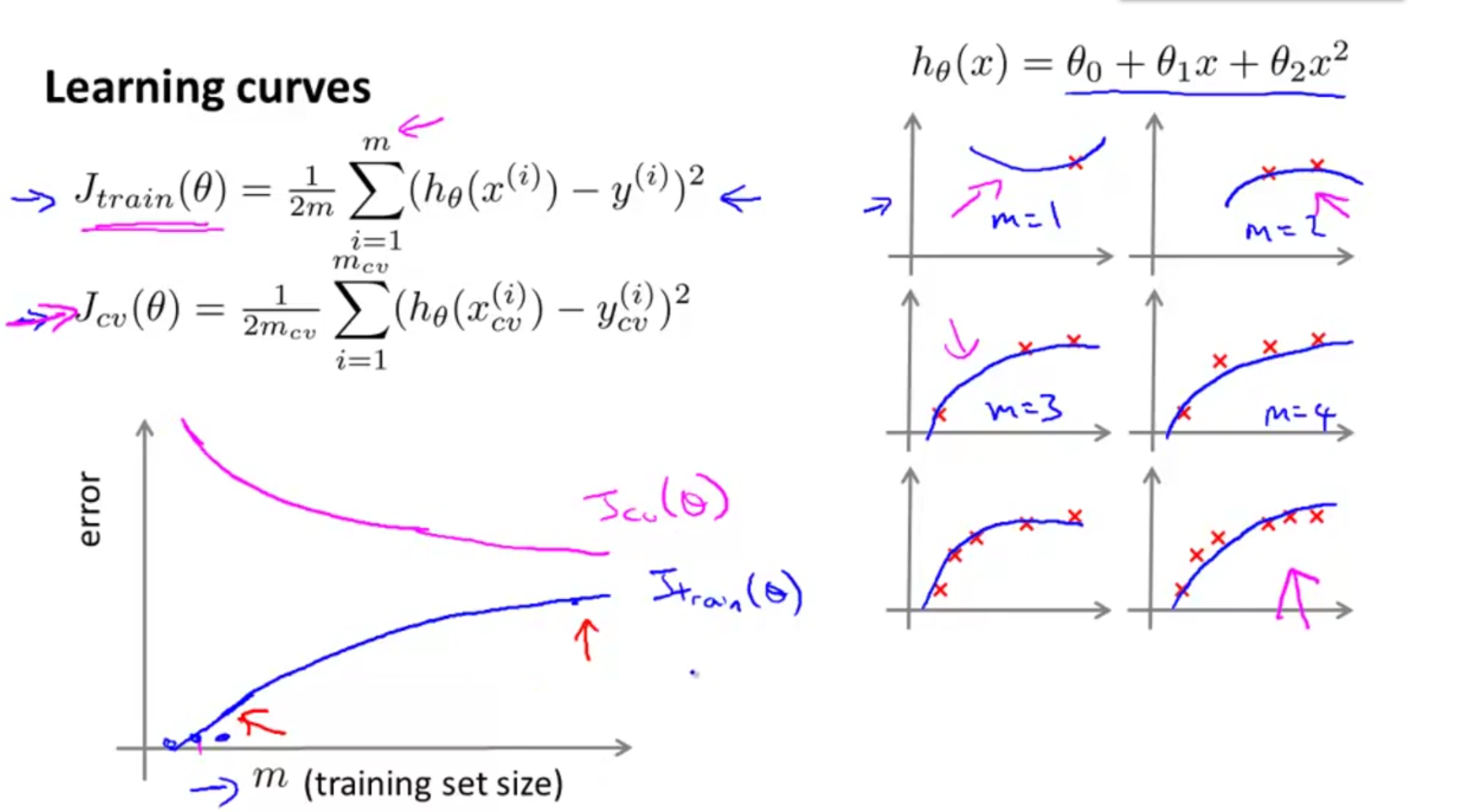
Learning Curves学习曲线
这是一个随着m变化的图像
正常情况下,m增大,
Jtrain(θ)
的值增大
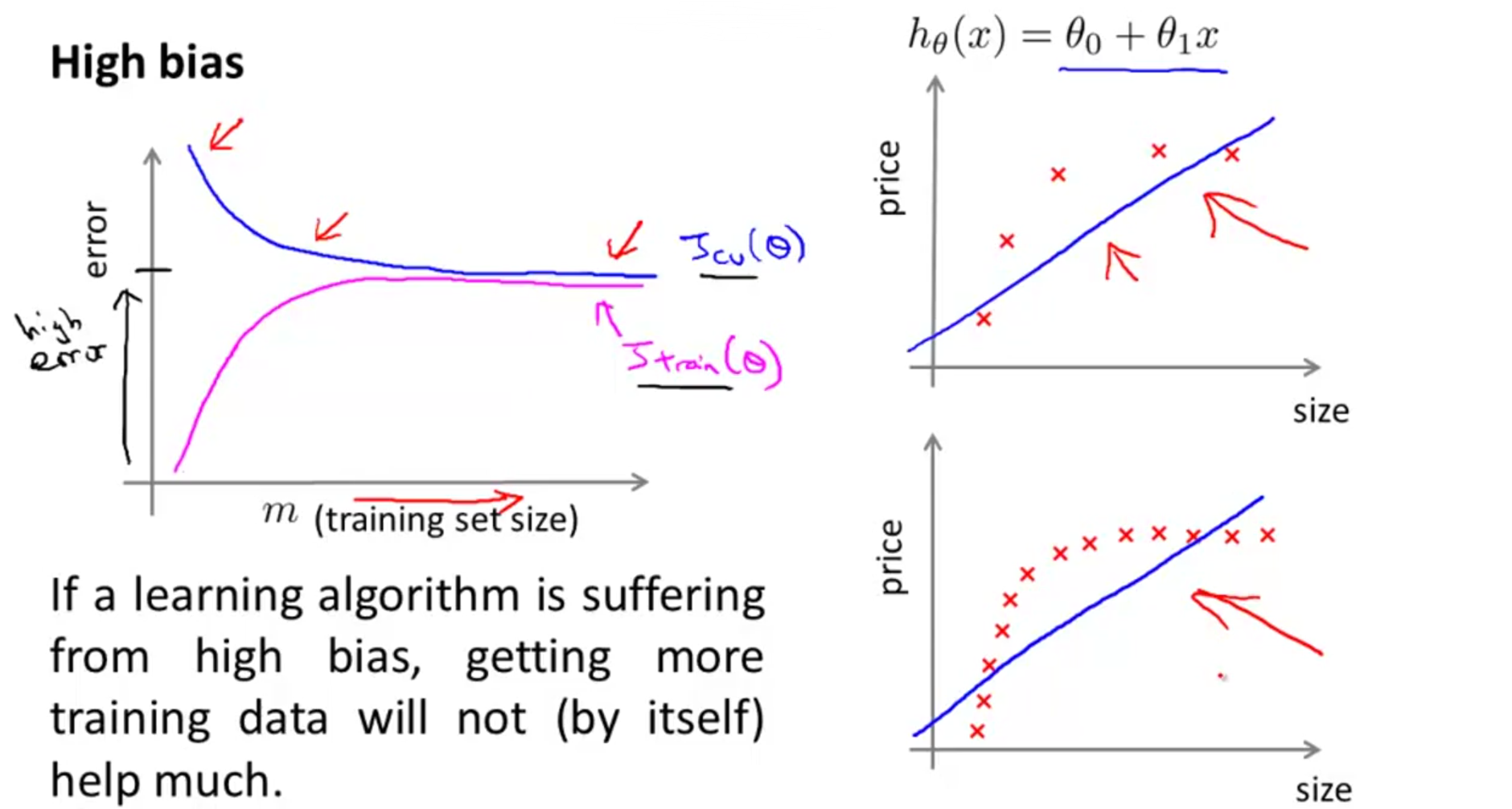
HighBias高偏差时
当m增大的时候,会很快就找到一个相对而言最合适的函数去拟合,但在那个达到m之后,继续增大m,
Jcv(θ)
的值会基本上趋于水平,几乎不变,这就是当前最合适的一个
hθ(x)
Jtrain(θ)
一开始也特别小,但随着m增大,他开始增大直到逐渐趋近于
Jcv(θ)
的值,这两个函数的预测结果最后将会非常接近
HighBias有一个明显特征是,
Jtrain(θ)
和
Jcv(θ)
的值最后都会比较大
也就是说如果一个函数是HighBias的,如果这个时候增加训练样本m的值,我们会发现
Jcv(θ)
不会有明显的下降,而是最后趋于水平。简单点讲就是,如果函数是HighBias的,增加m对改善算法无用,因为最后得到的
hθ(x)
相差可能不会太多
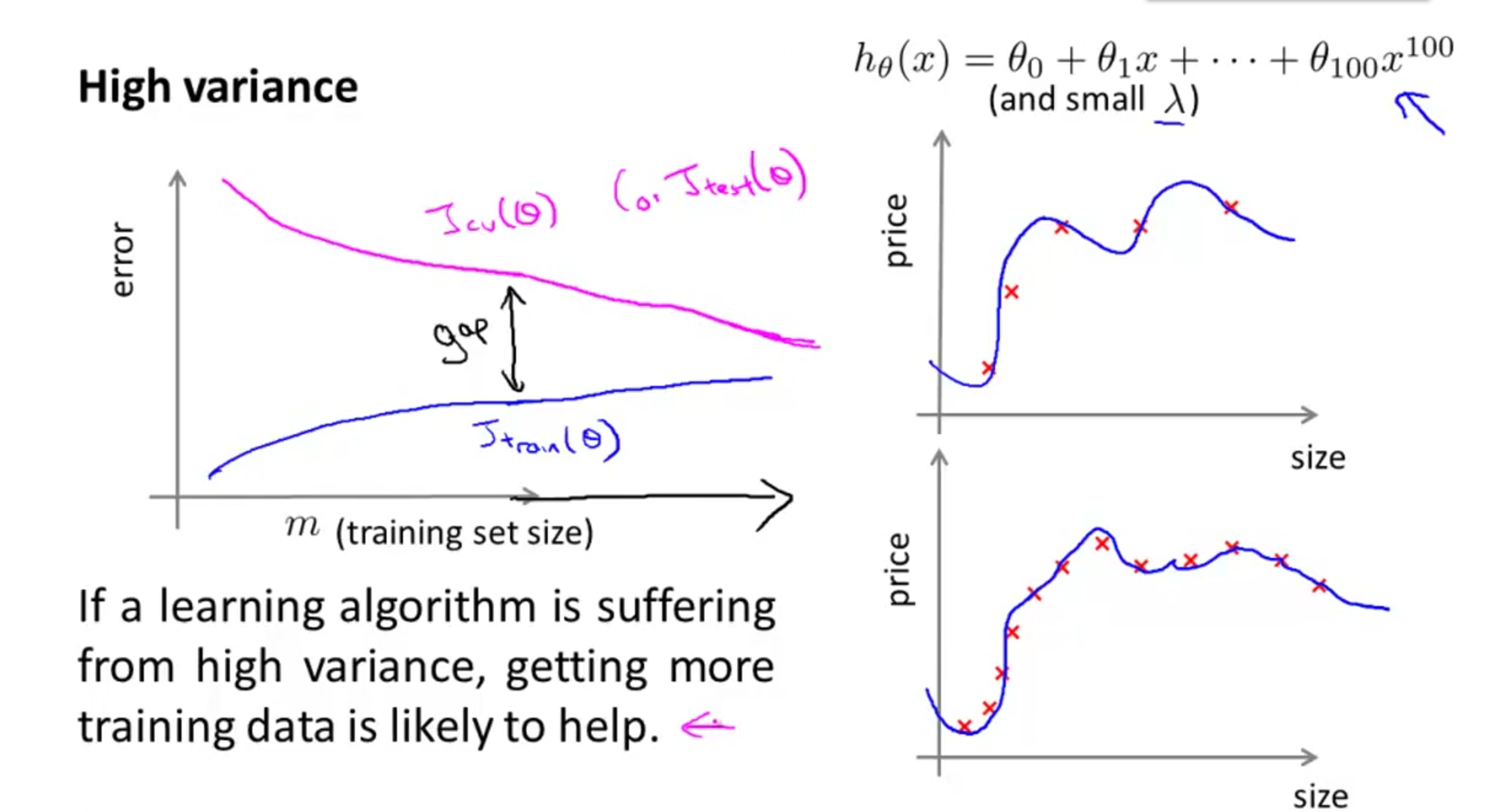
HighVariance高方差时
当m增大的时候,
Jtrain(θ)
增大,但这个误差值还是比较小
Jcv(θ)
的值会一直都比较大
HighVariance有一个明显特征就是
Jcv(θ)
与
Jtrain(θ)
在m增大一点的时候仍然有比较大的gap,但随着m增大,他们之间的gap会逐渐变小
也就是说如果一个函数是HighVariance的,那么这个时候增加训练样本m的值,对改善算法是有效果的
在实际中画出来的LearningCurves可能会有一些噪声之类的,但基本上和上面所述的相同,有利于看出Bias和Variance的问题
处理HighBias/HighVariance的方法

Machine Learning System Design
Error Analysis误差分析(根据分类错误处分析)
Skewed Classes偏斜类问题(两个类所占的比例相差特别大,如0.5%与99.5%,这个时候就需要一个新的误差度量方式,而不是纯粹使用预测正确的概率)
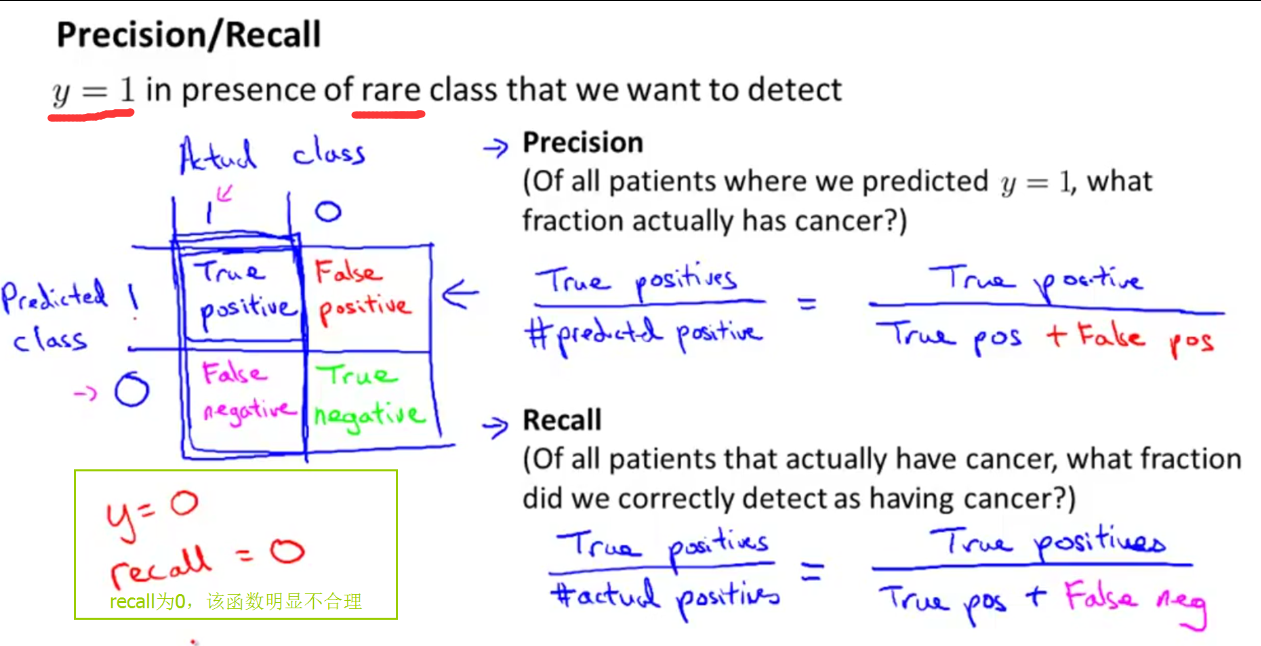
一种评估误差度量值叫做查准率(Precision)和召回率(Recall)
此时y=1应该是相对而言是rare的即较少出现的那个类
拥有High Precision和High Recall说明这个算法表现得很好
所以对于偏斜类问题,查准率(Precision)和召回率(Recall)是一种检测和评估学习算法表现的标准(要好于只用分类误差或分类精度)
运用Precision和Recall
改变threshold可能会影响Precision和Recall的值

在下面这种情况下,我们需要一个合理的方式去权衡P和R,根据某一个特定的权衡值选取最合适的算法。
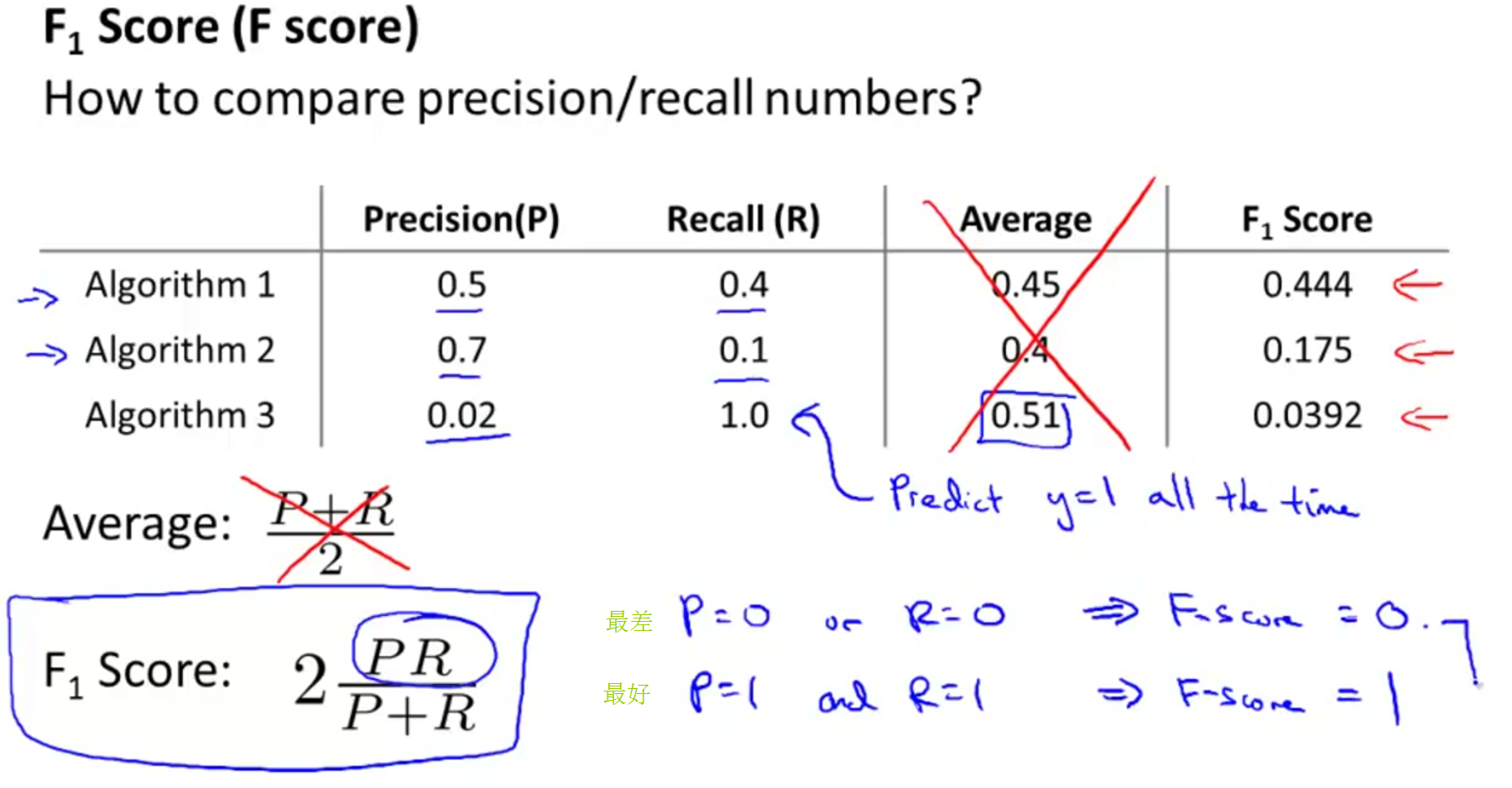
在Coursera中举了一个例子是
F1Score
具体为
F1Score:2PRP+R
根据
F1Score
这个度量值的大小去判断选取哪一个
Algorithm
自动选择Threshold:可以尝试不同Threshold,然后计算得到不同的Precision和Recall的值,最后根据F值的大小筛选出某个Threshold并使用















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









