







Coursera
Week1:Linear Regression with One Variable
Cost Function 代价函数
代价函数:用来描述h(x)的精确度
平方误差代价函数(Squared error function)是解决回归最常用的手段,特别是对线性回归(LinearRegression)

Gradient Descent Algorithm 梯度下降算法

其中α为学习速率,且α>0,他可以控制θ的变化量

将梯度下降算法运用在代价函数上

主要要同时更新θj

该算法又称为批量梯度下降算法(“Batch” Gradient Descent)
Week2:
Multivariate Linear Regression 多元线性回归

Gradient Descent for Multiple Variables 多元梯度下降算法

Feature Scaling 特征缩放法
特征缩放是用来标准化数据特征的范围,它是缩放变量的取值范围到相似的区间大小,有时能提高算法的收敛速度
http://blog.csdn.net/u012717411/article/details/50481400
http://blog.csdn.net/u012328159/article/details/51030366
一般的均值归一化(Mean Normalization)公式为:
,其中
为训练集中所有
的平均值,s为特征

虽然图中x2的max-min应该为4,但是分母用5其实也没关系,因为最后结果的取值范围都是一个近似的结果,只要把特征转化为相似的范围,有利于提高收敛速度即可,特征缩放其实不需要太精确,只要让梯度下降算法运行速度可以更快,让梯度下降收敛所需的循环次数更少即可
选择合适的学习速率α
方式有两种:
1. 通过绘制J(θ)的值随算法迭代次数变化的曲线,去判断J(θ)是否converge
2. 自动检测
确定完α的区间之后选取最大或最大值略小的那个α
If α is too small: slow convergence
If α is too large: may not decrease on every iteration and thus may not converge
如果α太小:收敛很慢
如果α太大:可能每次迭代J(θ)的值不会减小因此最后不会收敛
Polynomial regression多项式回归
如果你想用一元高次多项式做拟合函数去拟合离散数据,比如h(x)=θ0+θ1*x+θ2*x^2+θ3*x^3,那么,有一种简单的作法,可以实现一元非线性回归问题转化为多元线性回归问题,从而用gradient decent algorithm解决,这种方法叫多项式回归Polynomial regression.
原理:分别把x^2、x^3看成另外两个特征变量x2,x3,则假设函数h(x)=θ0+θ1*x1+θ2*x2+θ3*x3,通过扩元实现降幂。

但是降幂之后的会出现X1、X2、X3的取值范围有很大不同,这个时候就需要对他们使用特征缩放法
Normal Equation正规方程
不是迭代而是直接通过分析一步得到最优的
θ
,使用正规方程的时候也不需要特征缩放法
θ
的计算式子为
θ=(XTX)−1XTy


coursera里面对于推导好像没有详细说明,可以参考Normal Equation推导
矩阵
(XTX)
不可逆的时候,先删除一些线性相关的特征变量,再删除过多的特征变量或者利用正则化方法
Week3:Logistic Regression 逻辑回归
在这一节里面讲的问题均为Binary Classification Problem也就是预测结果y只有0和1
Hypothesis Representation 逻辑回归的假设函数表示

hθ(x)
就是给了我们
y=1
的可能性
For example, hθ(x)=0.7 gives us a probability of 70% that our output is 1. Our probability that our prediction is 0 is just the complement of our probability that it is 1 (e.g. if probability that it is 1 is 70%, then the probability that it is 0 is 30%).
有的时候以0为阈值,即
CostFunction 逻辑回归的损失函数
由于
y
可能的取值只有0和1
而且


所以costfunction为
也可以向量化(在此不展开)
GradientDescent的方式也和前面大同小异(用与上面梯度下降算法相同适当的微分运算即可验证下式正确)
Advanced Optimization高级优化
普通的有GradientDescent
高级的有
* Conjugate gradient
* BFGS
* L-BFGS
Multiclass Classification: One-vs-all一对多分类问题
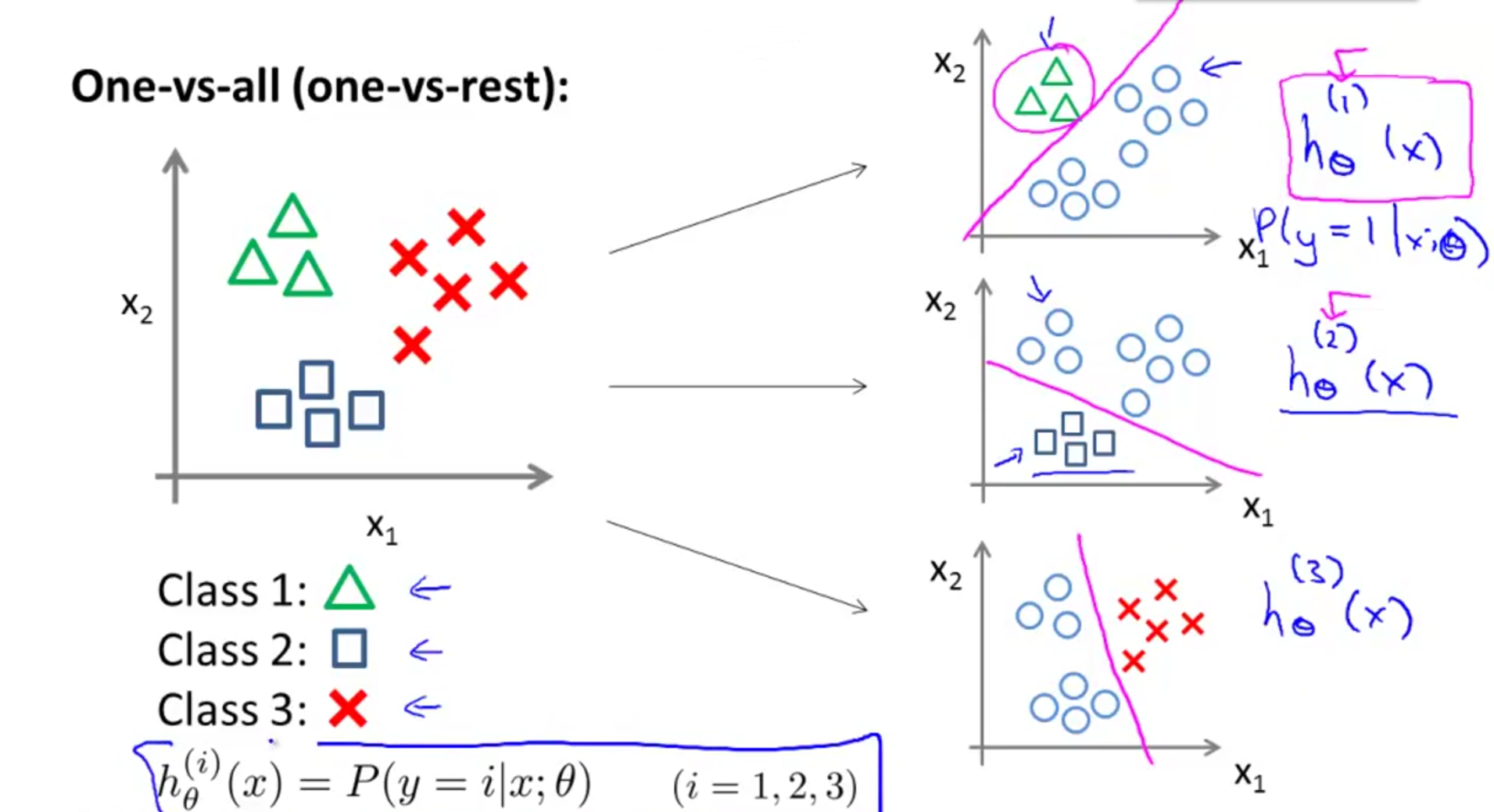
输入一个数据x之后,对于
h(i)θ(x)=P(y=i|x;θ)(i=1,2,3)
因为i不同
h(i)θ(x)
函数也不同,所以得到的预测值也不同,我们在其中挑选出值最大的即
maxih(i)θ(x)

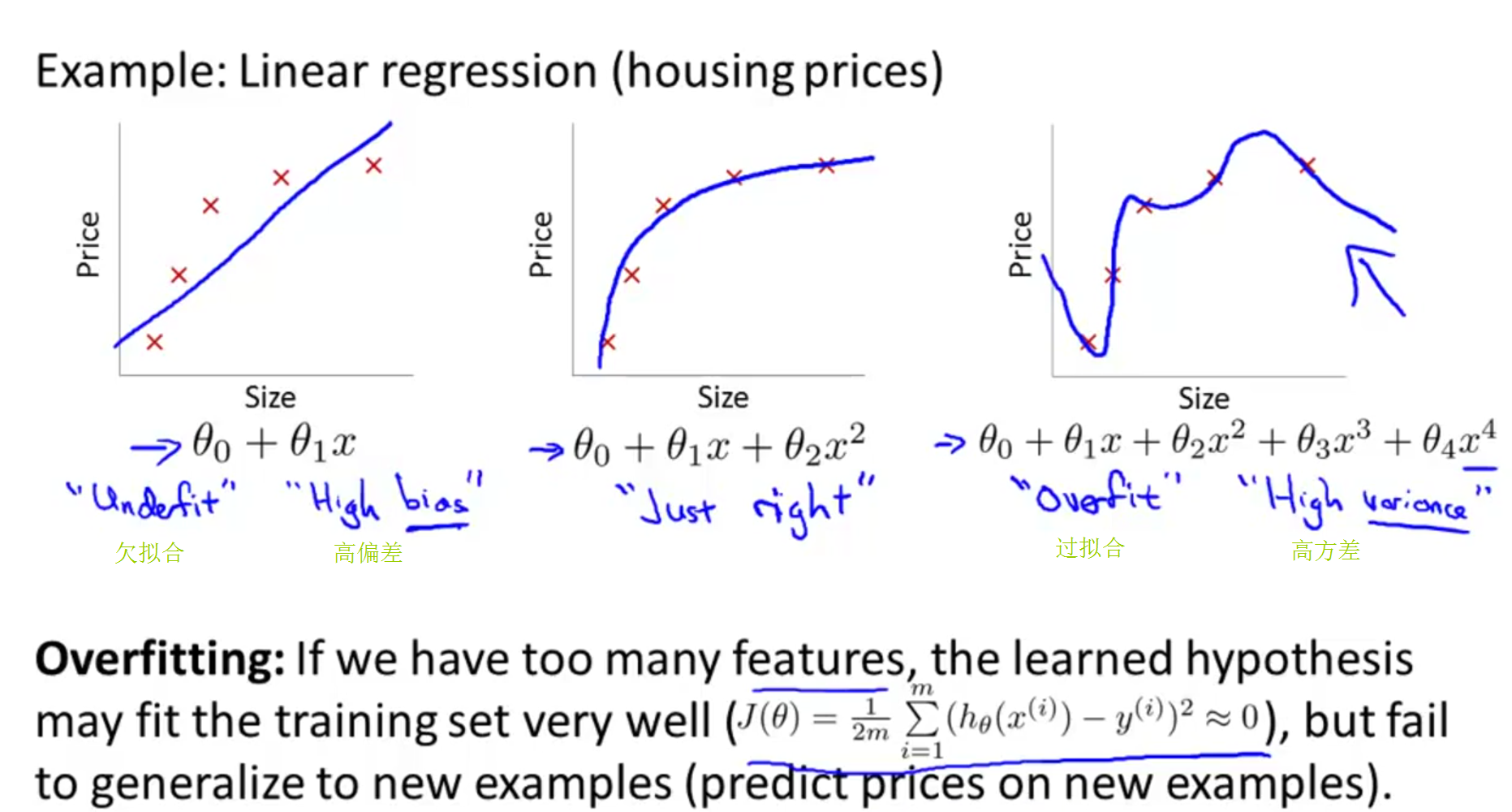
Overfitting过拟合
作为一个函数应该有泛化能力(generalize),即对没有出现在训练集的数据也有比较好的预测效果,而不是一味地去苛求使训练集的所有数据都拟合但最后却出现过拟合的情况
Regularization正则化
J(θ)=12m∑i=1m(hθ(x(i))−y(i))2+λ∑j=1nθ2j
在原来的CostFunction对特定的
θi
添加penalize(惩罚项)
λ∑j=1nθ2j
是正则化项(Regularization Term),
λ
是正则化参数(Regularization Parameter)
注意正则化项中这里的j是从1到n变化而不是0到n变化,实际使用中, θ0 加入其中对结果影响也不大,只是从1到n变化是一种约定俗成
选择一个合适的 λ 很重要,太大容易underfitting,太小容易overfitting, λ 在正则化中的作用特别大
再谈寻找合适的theta
CostFunction两种计算最合适\theta的方法
* 梯度下降
* 正规方程
先讲梯度下降


正则化
其中L是一个(n+1)*(n+1)的矩阵
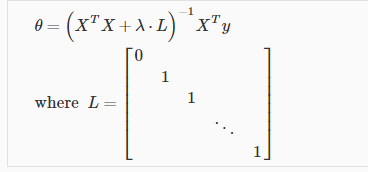

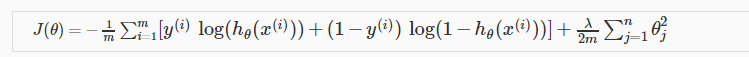















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









