 Linux内存管理核心机制解析
Linux内存管理核心机制解析








文章目录
preface
1、内存管理是Linux最复杂的模块(涉及计算机数学和ARM体系架构)- 适合图解法说明,但好在大部分工作由系统(软件操作集中在初始化部分)或硬件完成;比如比较复杂的内存模块MMU和cache
1)MMU软件工作:设置页表,开启
2)cache软件工作 :开启/关闭,强制刷新
2、另外开发者需要根据实际场景使用分配内存的接口(也本文主要解决的问题)
3、内存管理涉及CPU架构、内存架构、算法等知识,每个知识点展开都非常庞大,这里重点讨论系统(Linux)下内存管理;
1)内存的作用
1、ARM处理器程序运行的过程
https://blog.csdn.net/qq_43367829/article/details/124374722
2、程序是如何在CPU中运行的
https://www.cnblogs.com/wenziw5/p/12884142.html
3、程序在Flash和SRAM的空间分配:
https://www.cnblogs.com/39950436-myqq/p/11387179.html
从指令的运行过程来看内存的作用和地位,避免过度跑题,这里重点关注与内存相关的知识
1、以语句a=a*b; 为例,看看CPU与内存的交互过程
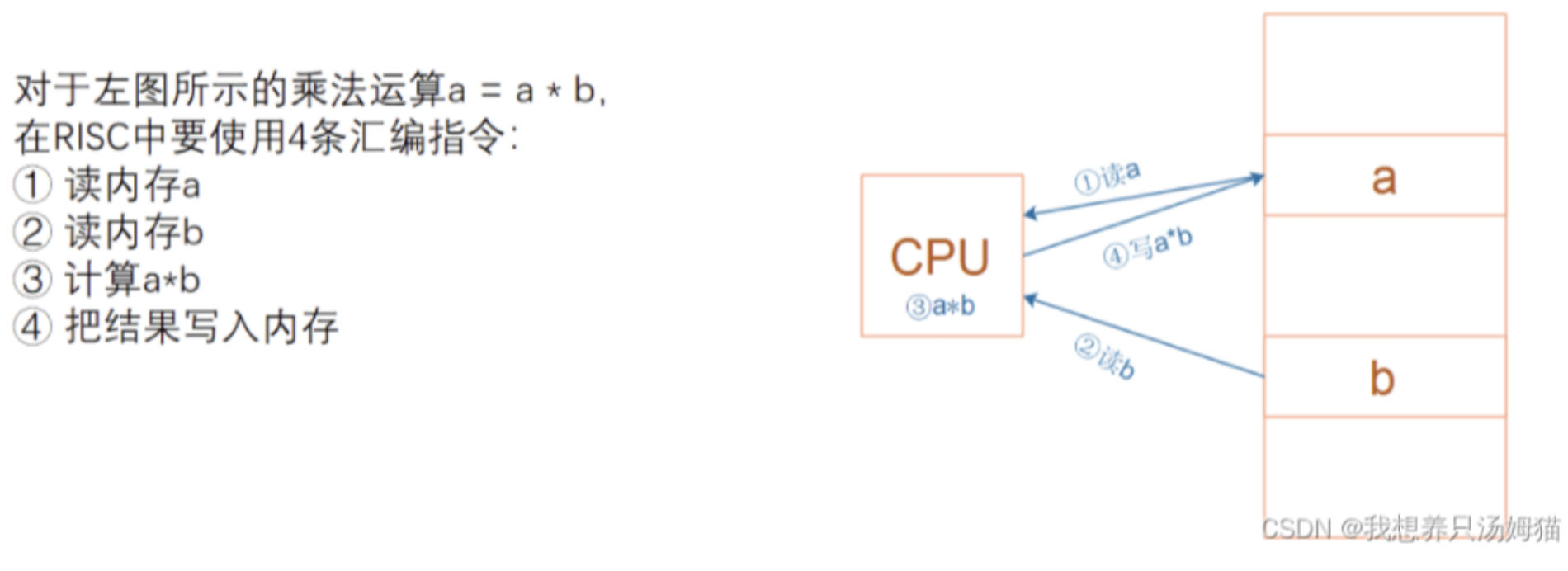
可以看到CPU每一条指令的执行,都依赖于内存,因此个人认为内存的作用是仅次于CPU的,存在的困境
1)当前CPU的速度是高于内存的,内存的速度是限制系统性能的主要因素;
2)其次由于内存的造价和特性 不同,因此造成一个系统里面存在很多类型的内存,各司其职,使其成本降至最低;
而内存管理的宗旨就是为了提高系统性能,合理利用内存资源,但也使其操作变得极其复杂。
2、程序的运行是顺序的吗?
答案是否定的,函数调用、条件分支等会导致程序跳转、读取变量也会使程序跳转,比如函数调用对应的跳转示意图
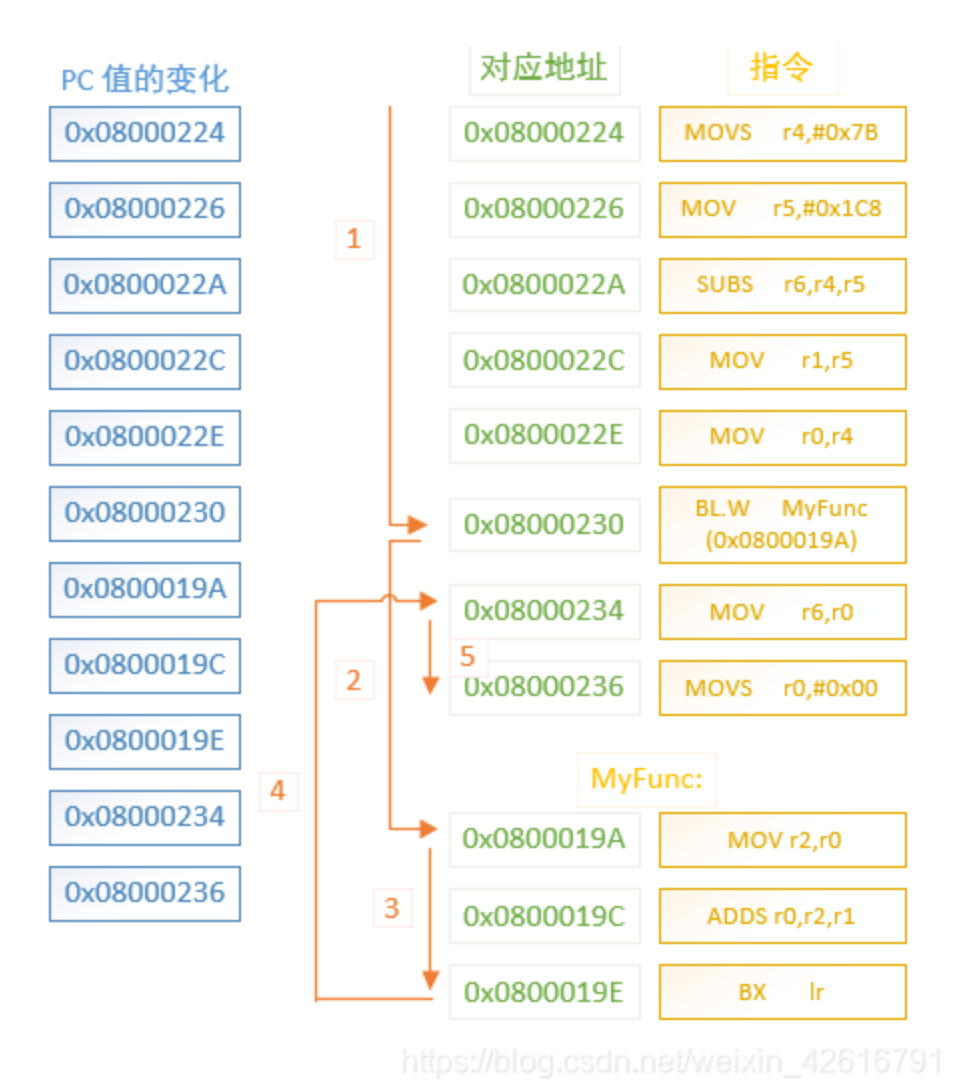
内存中一个储存单位存放一条汇编指令(实际内存是一串0和1组合的机器码);
关于汇编指令的跳转目的地,就意味着需要具体地址,汇编指令中会有相对地址/绝对地址的概念
有两种情况:
1)内部使用NOR FLASH的MCU(加载地址和运行地址是一样的);
2)大型系统中的程序的 加载地址(存储位置)和 运行地址往往是不同的;
这种情况开发者需要规划内存分区,确定程序的 加载地址/运行地址,在链接脚本中指定,然后编译器会给程序分配合适的地址;
可以参考STM32-内存运行原理与RAM执行实战
https://blog.csdn.net/2401_85638163/article/details/148628244
2)MCU与ARM的内存架构
1、存储介质
1)存储器分类
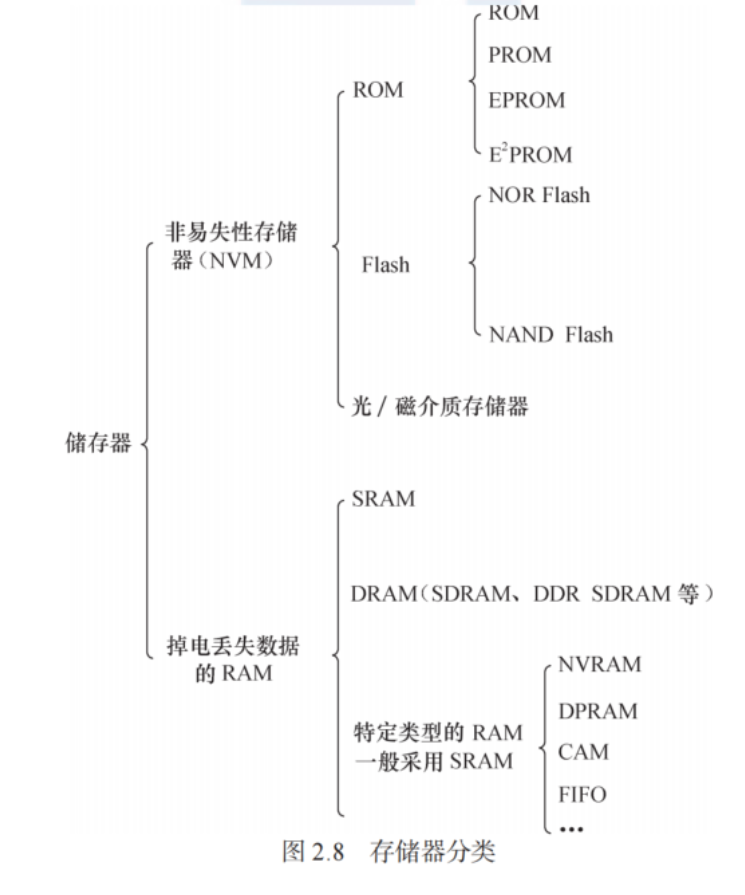
2)根据在系统中的用途分类
1、系统内存
1)系统内存是指CPU能通过系统内部总线发出一个寻址,储存器能返回一个数据,满足此要求即可成为系统内存
2)能够成为系统内存的储存器有ROM、NOR FLASH、SRAM、DDR,这些是属于内存管理 的对象,他们的差异是速度不同;NAND FALSH则不能成为系统内存。
3)我们常说的系统内存、运行内存,指的是系统中的主内存,主流是DDR(属于RAM的一种);
2、存储设备
PC上的磁盘,嵌入式设备中的EMMC/Nand FLASH属于外置存储设备,不属于系统内存,一般由文件系统负责管理;
2、MCU内存架构
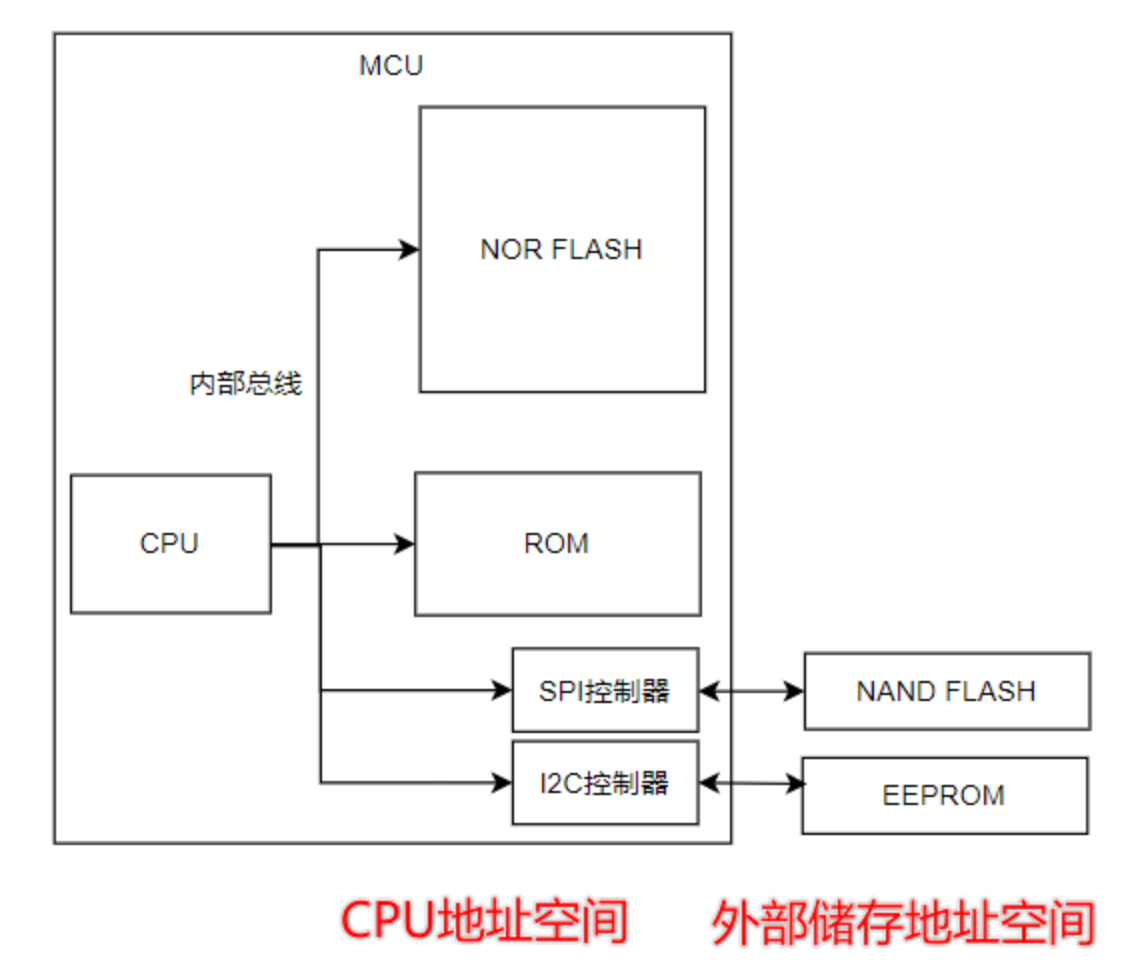
1)MCU中的FLASH属于NOR FLASH,可以直接运行程序;
2)属于CPU地址空间的片上外设 都属于 内存架构中的一员;
3)SPI控制器/I2C控制器 可以看做是内存设备;
比如STM8
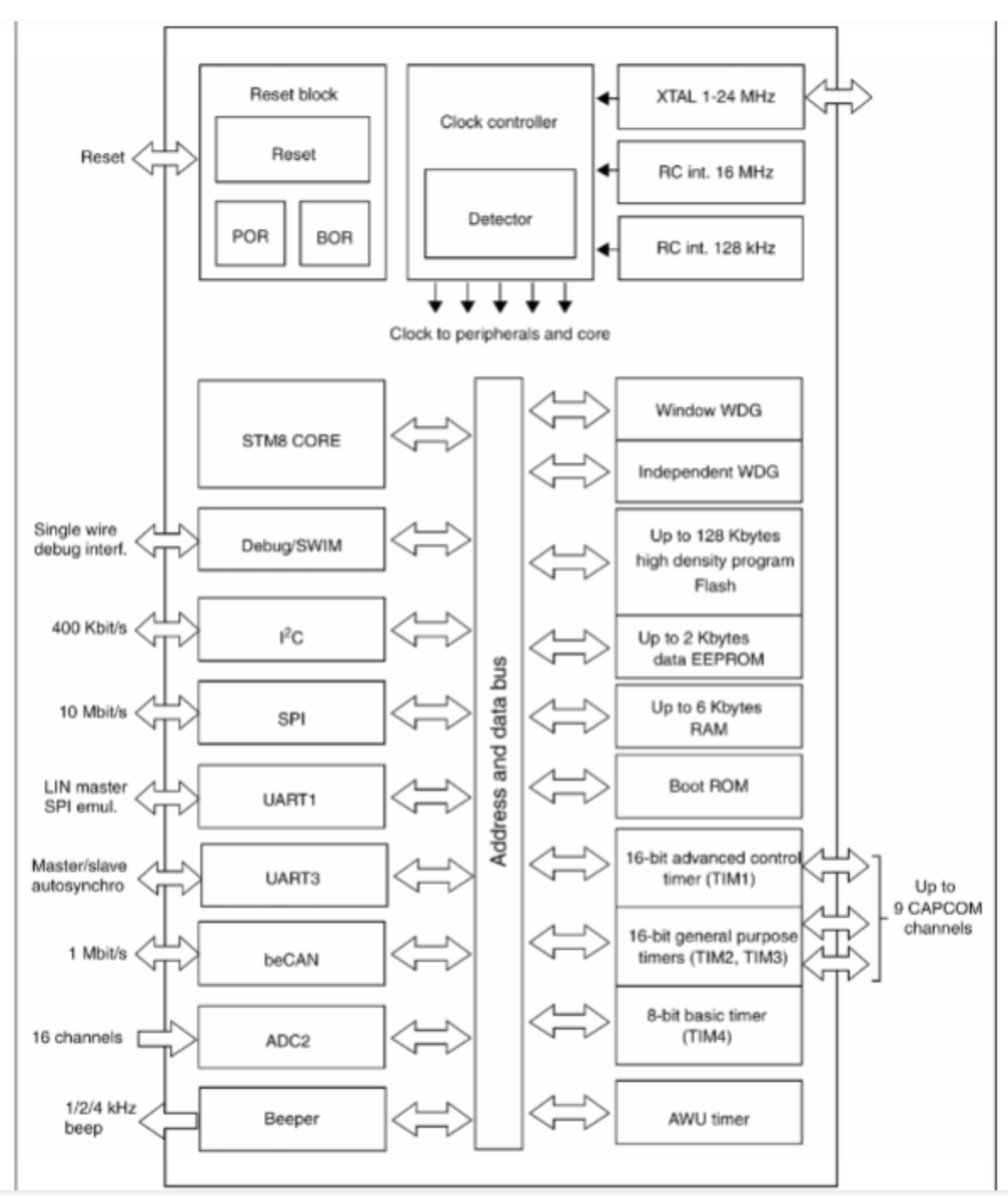
3、ARM内存架构
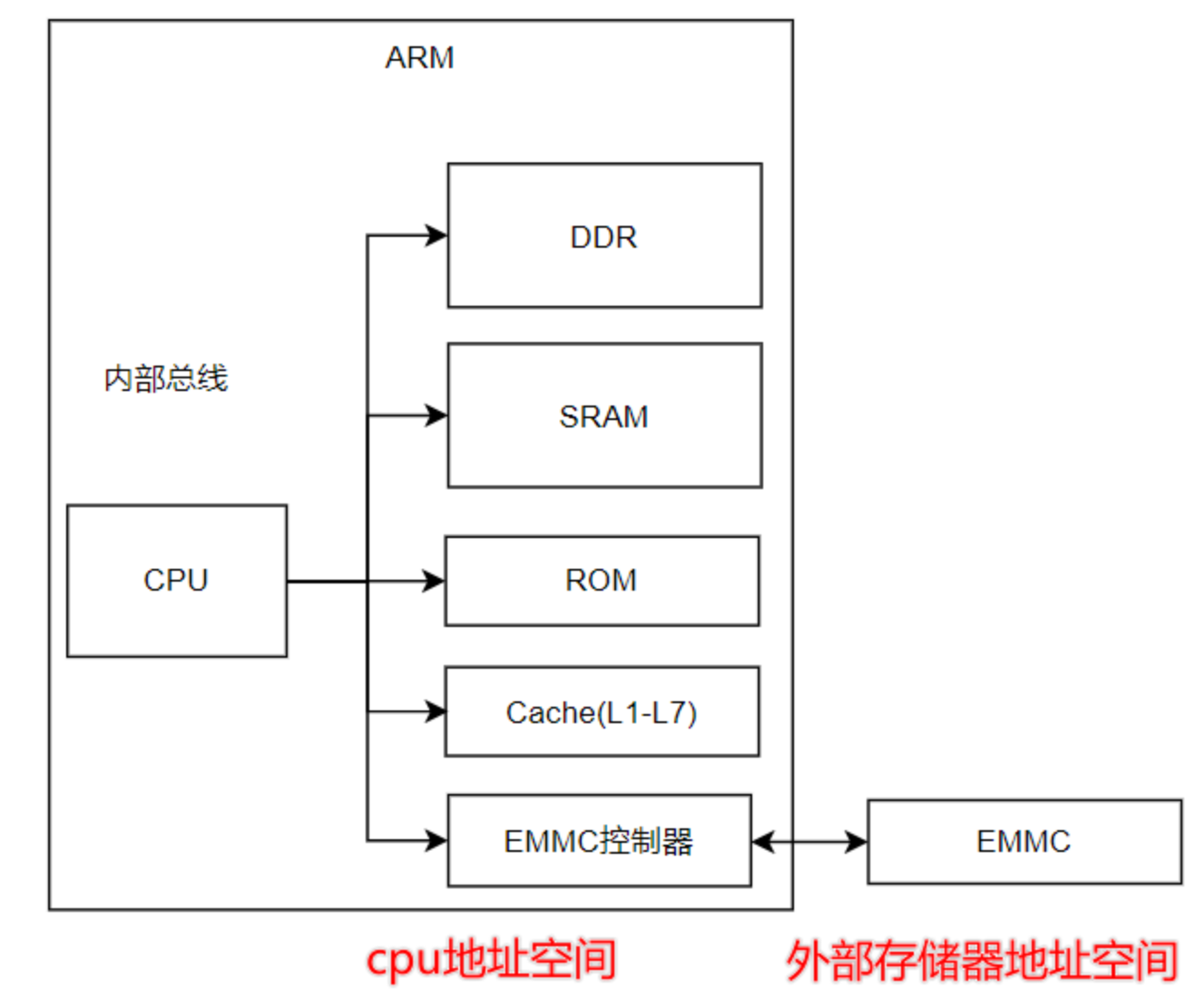
1)ARM相对MCU使用的内存设备更加丰富一些,架构也相对复杂一些;
2)属于CPU地址空间的片上外设都属于内存架构,都可以归内存管理负责;
3)EMMC属于外部存储器,归文件系统负责;
4)不同CPU的硬件底层设计细节差异巨大,但同一架构下对于程序的运行分析是相同的,需要辩证地看待;
5)STM32F4的内存与总线结构
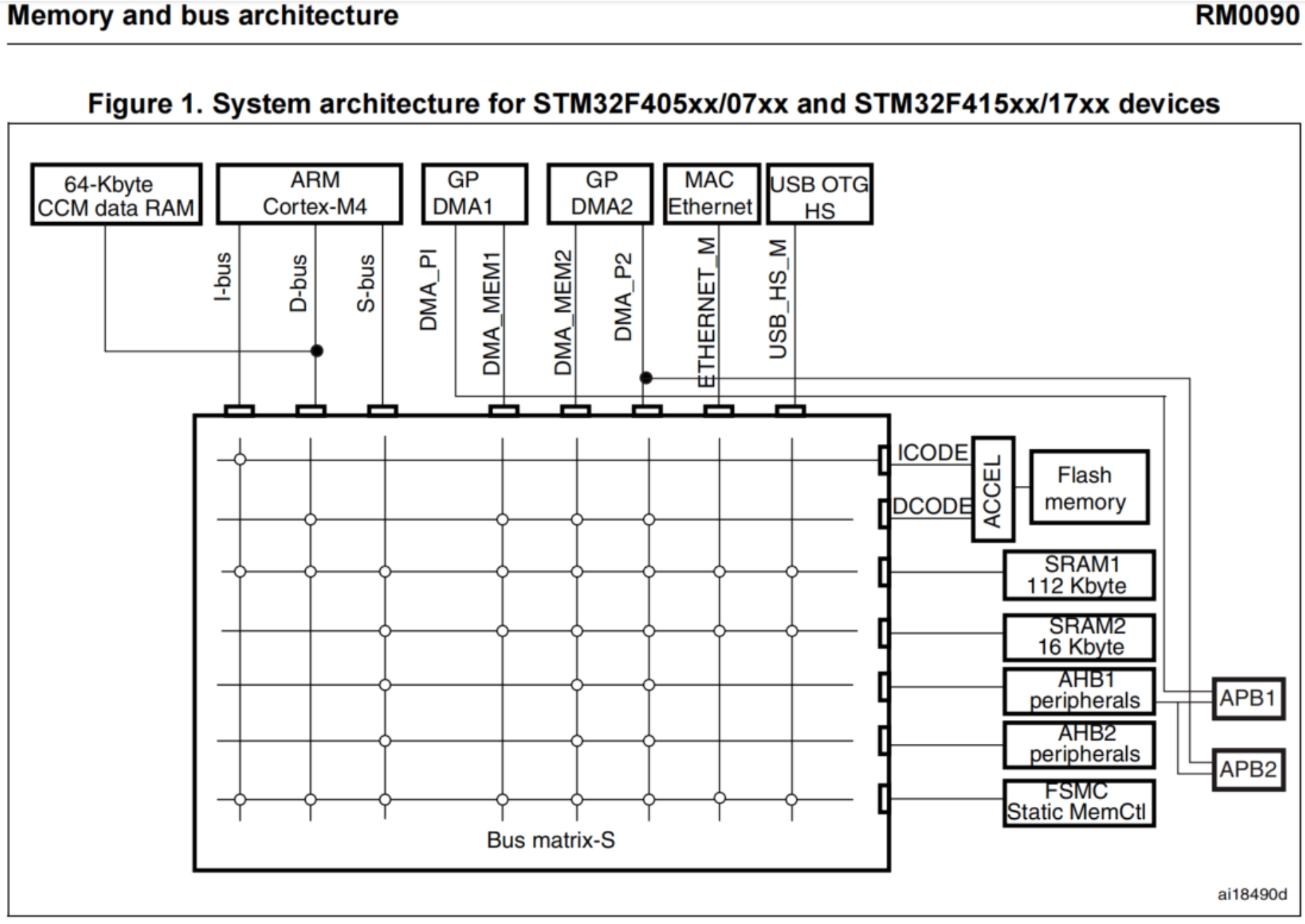
2)ARM统一内存管理架构(静态)
1)ARM Platform Memory Map
以IMX6ULL为例,32位CPU,架构是ARM Cortex A7
1、系统内存地址分配
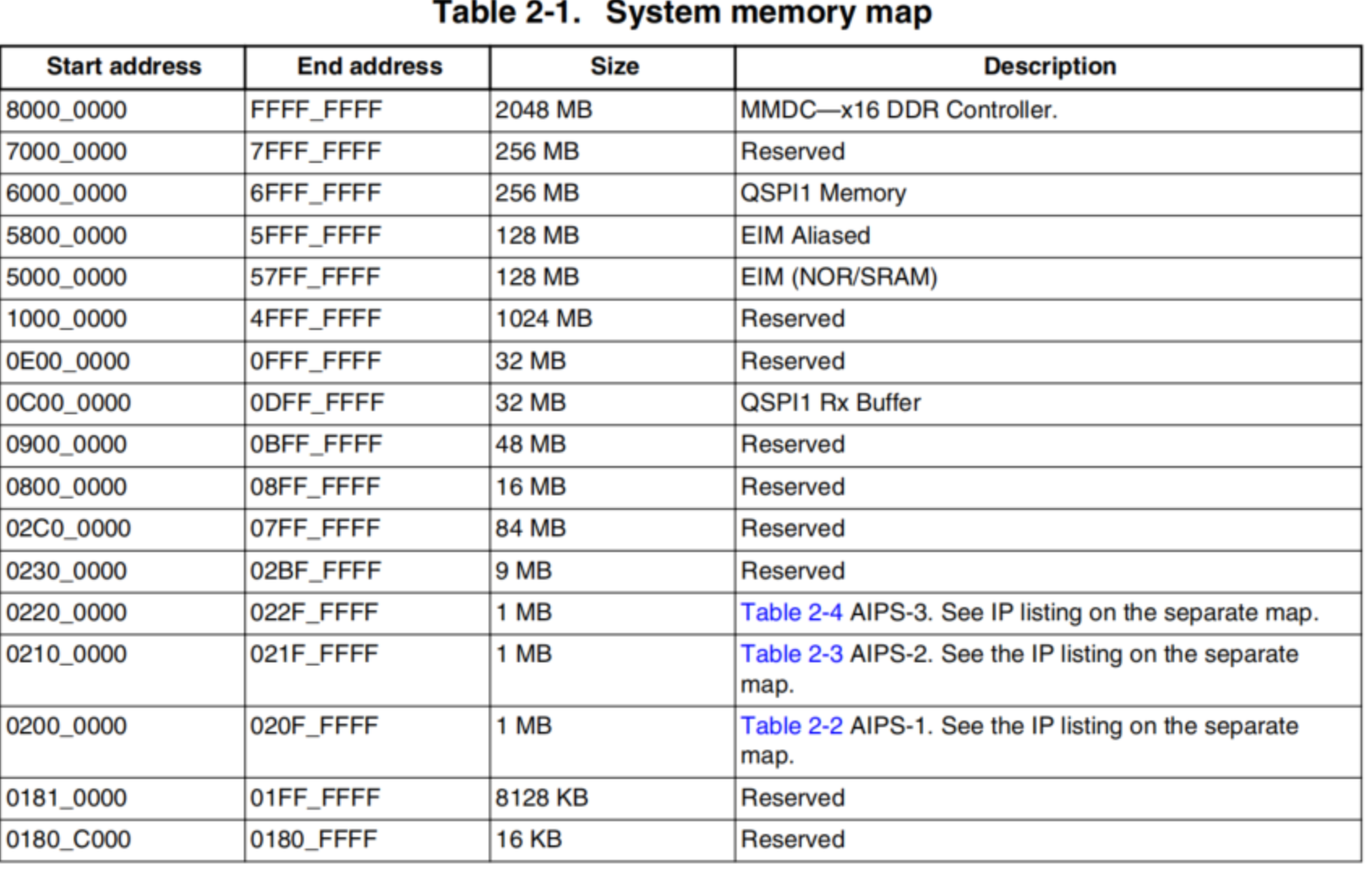
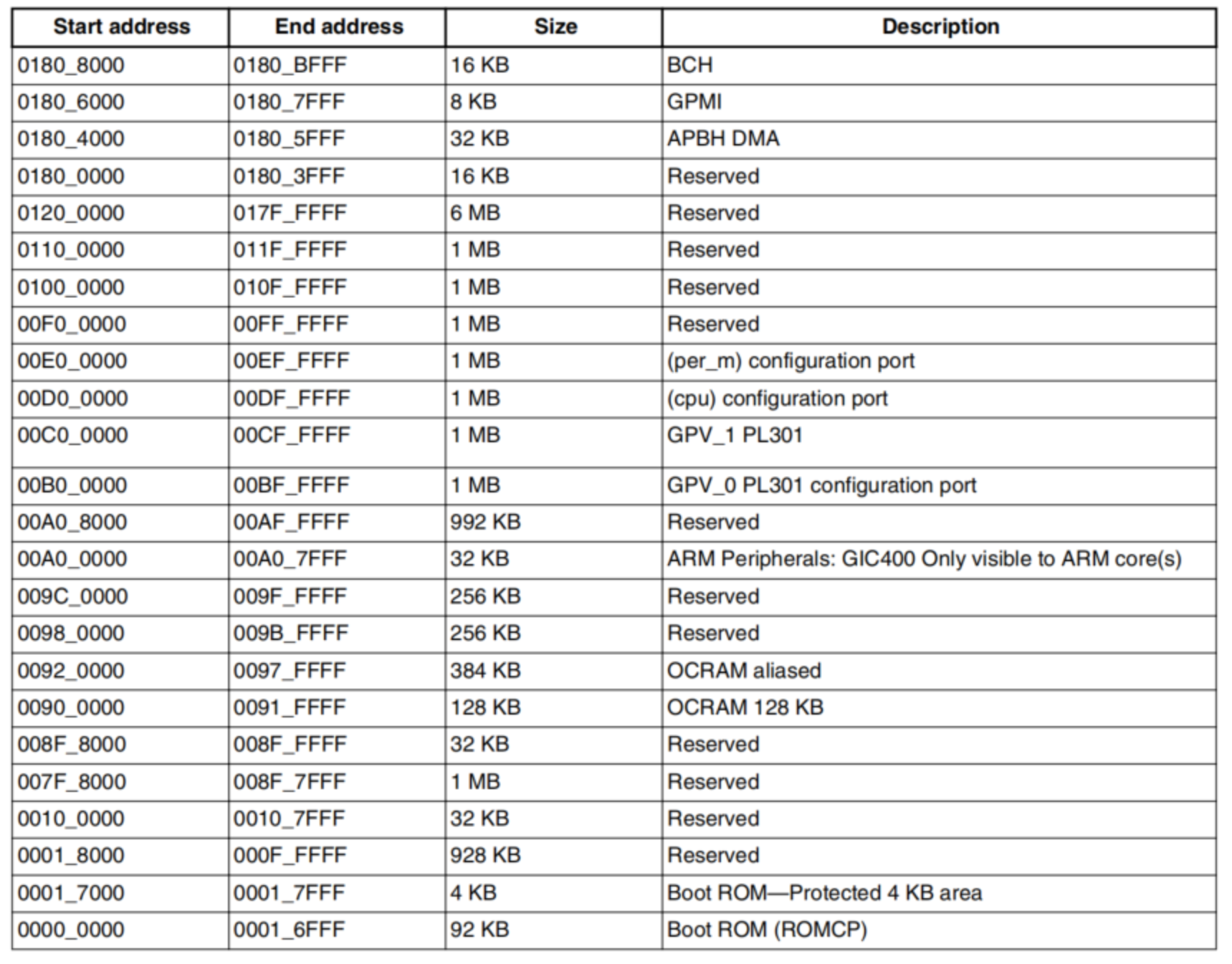
关键的系统内存的地址空间
1)DDR,最大支持2GB寻址;
2)SRAM,最大支持128Mb寻址;
3)ROM,最大支持92KB寻址;
2、外设内存地址分配
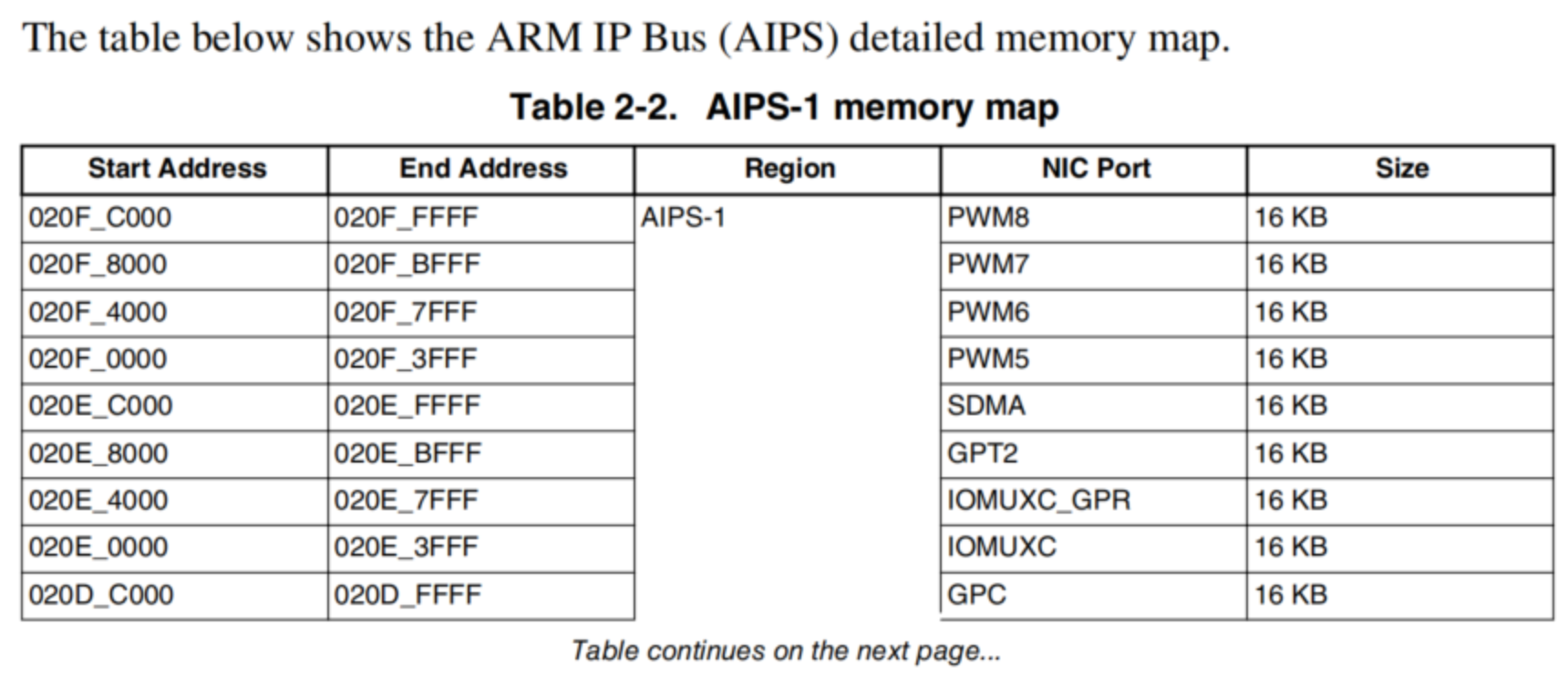
3、统一内存管理下,CPU访问过程
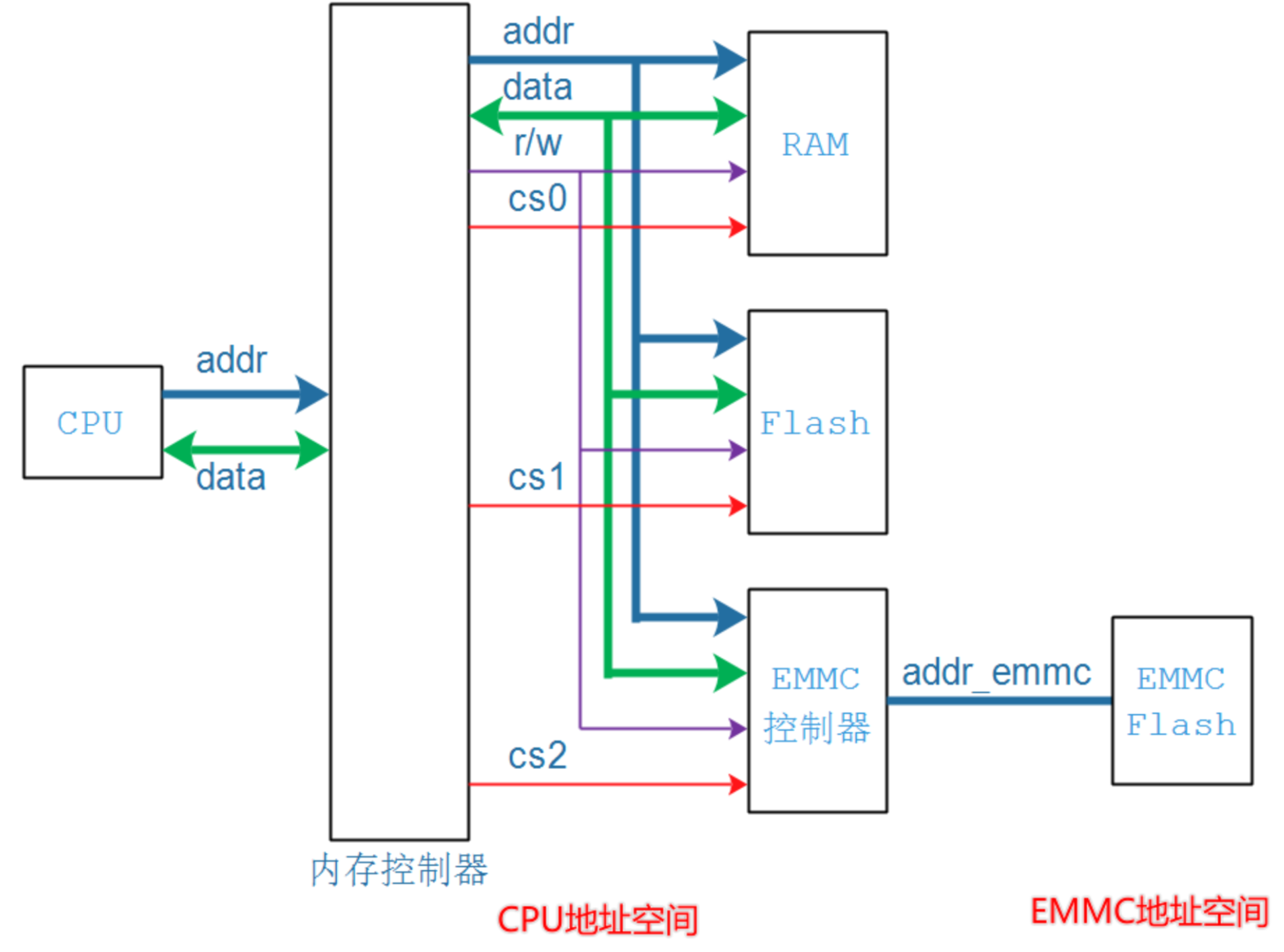
CPU下发的地址如何正确到达某个外设?
1)硬件设计:各个设备的连线需按照要求与CPU连接;
2)内存控制器实现:
- CPU发出addr,到达内存控制器,也出现在RAM、Flash、GPIO等设备上
- 使能设备(内存控制器根据地址去 使能对应设备)
- 如果addr属于RAM的地址范围,cs0就被使能
- 如果addr属于Flash的地址范围,cs1就被使能
- 如果addr属于GPIO的地址范围,cs2就被使能
- 没有被使能的设备,就相当于没接上去一样,不会影响其他设备
- 读写数据
关键在于:内存控制器,它会根据地址范围发出对应的片选信号,选中对应的设备。
3)ARM的程序运行(动态)
1、先来看看MCU的程序运行
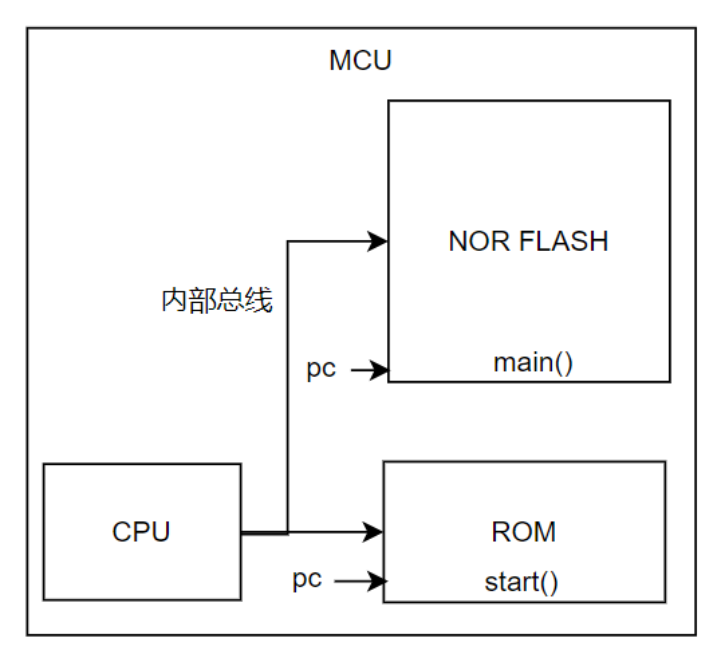
1)MCU程序运行过程较为简单,上电从ROM(厂商出厂固化的代码)开始,后续直接跳到FLASH运行;
2)值得注意,程序镜像的初始化部分和内存排布 需要根据硬件特性来适配;
这部分工作一般由IDE完成,比如keil(编译时需要选择对应型号);
2、ARM的程序运行
这里的ARM指的是能运行Linux系统的架构;
由于ARM能支持系统运行,当然架构上会更加复杂,用到更多内存种类,规模也更大,必然时候还会有专门的硬件机制支持;
对于裸机程序还是Linux系统,运行机制是一致的,裸机程序就相当于Linux的bootloader
1)以三星芯片为例
https://www.cnblogs.com/FORFISH/p/5188713.html
S3C6410 (ARM11) boot-up diagram
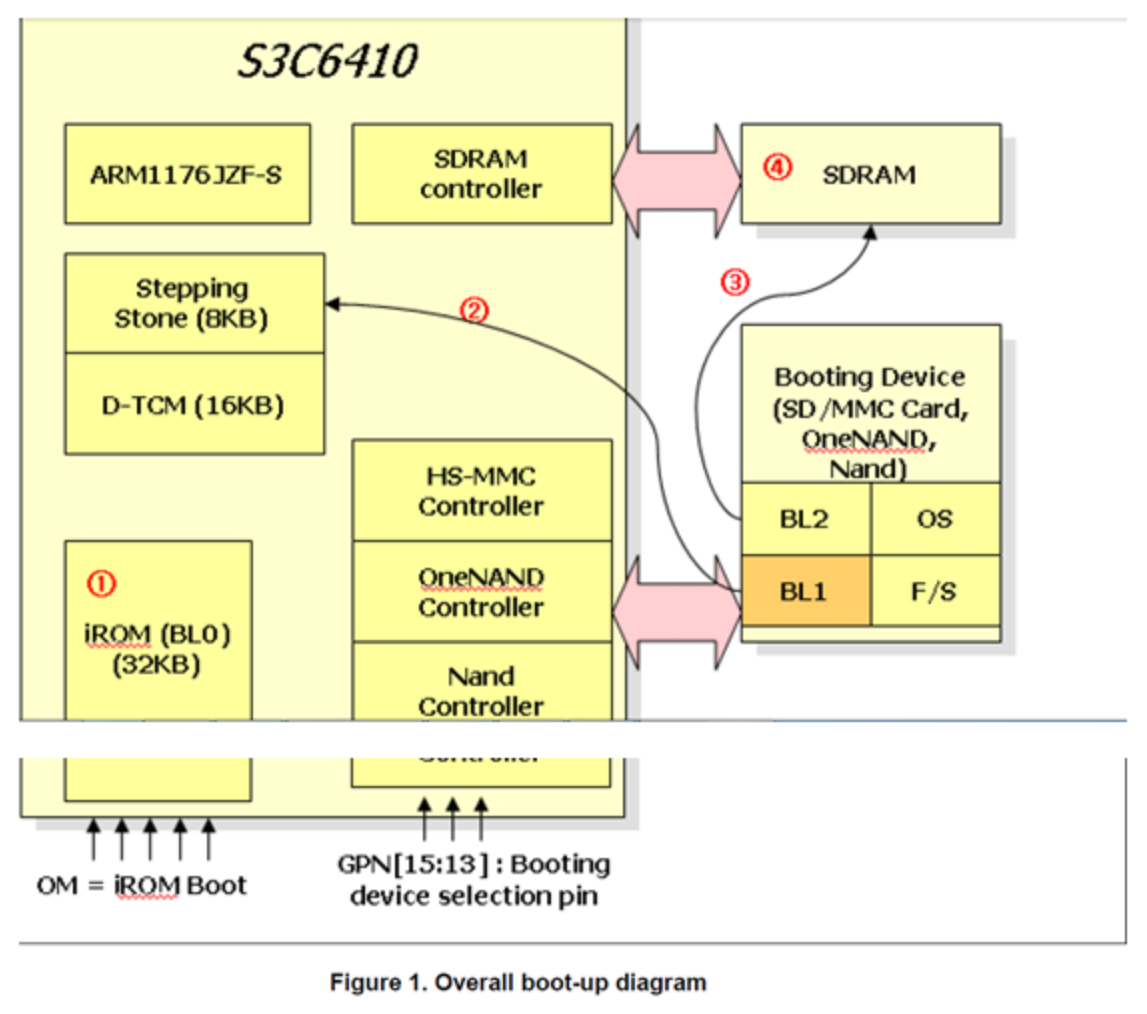
1、程序从厂家已烧录好程序的ROM启动;
2、从外部储存设备FLASH中取出8KB内容,放到芯片内部SRAM(三星的Steppping Stone技术,用于协助CPU从无法执行程序的NAND FLASH 执行启动程序的一种方法,换言之 如果系统镜像烧录在能直接运行程序的FLASH上,比如NOR FLASH,则无需Stepping Stone参与,灵活对待)运行,这个步骤是硬件自动完成(可能在固化的ROM里面),总之系统软件无需参与;
1、从哪种FLASH取出?芯片设计上预留外部GPIO,通过拉高拉低来选择从NAND FLASH或其它;
2、由于前8KB内容转移到其它内存运行(地址变化了),因此代码要求是与位置无关的,否则地址就对不上了;
3、在起始的8K代码中,需要完成工作:
1、初始化SDRAM(设置寄存器)
2、把bootLoader剩余部分搬到SDRAM中去;
3、最后跳到SDRAM中去运行;
4、后续系统程序就转到SDRAM持续运行,bootloader运行完之后,kernel/进程文件 谁负责搬运?
1、kernel由bootloader代码搬运和设置;
2、后续动态运行的程序/内核文件,就由kernel负责搬运和设置;
小结
1)不同芯片架构设计不同,提供的内存访问方式也有所不同;
2)不同厂商会根据芯片设计指南和产品特性来决定如何搭配;>> 此时开发者需要根据设计来适配对应系统代码
3)开发者 需要按照 硬件上的固有特性 进行合理的初始化代码设计(一般在bootloader中实现)和 系统镜像内容排布设计;
1、对于初始化代码设计,一般在bootloader中实现;
2、对于系统镜像内容排布设计 工作:开发者需要设计链接脚本,编译器会根据链接脚本生成针对此芯片平台的系统镜像;
4)为程序段分配运行时刻的地址的操作就被称为重定位(Relocation)操作;
3、一个程序可以分次加载到RAM吗?
1)运行前必须是一次性加载到RAM,因为程序的访问和跳转是随机的,必须完整加载到RAM,否则会有出现访问不到内容错误导致崩溃;
这样的特性也决定了,程序大小不能超过物理内存RAM的大小,否则无法被运行;
2)内核加载也要一次性加载到RAM中?
内核本身就是一个“特殊且庞大”的程序,需要一次性加载到RAM
从开发者角度均使用虚拟地址,如何映射到物理地址(在页表中记录,随系统动态变化而变化),由MMU硬件负责转换,很简单的操作:读取+换算,之所有给MMU处理,是因为硬件处理会很快,最大程度减少性能损耗;
4、嵌入式系统程序运行在FLASH还是RAM的系列问题探讨
https://zhuanlan.zhihu.com/p/652079555
4)程序文件的内存分布(静态)
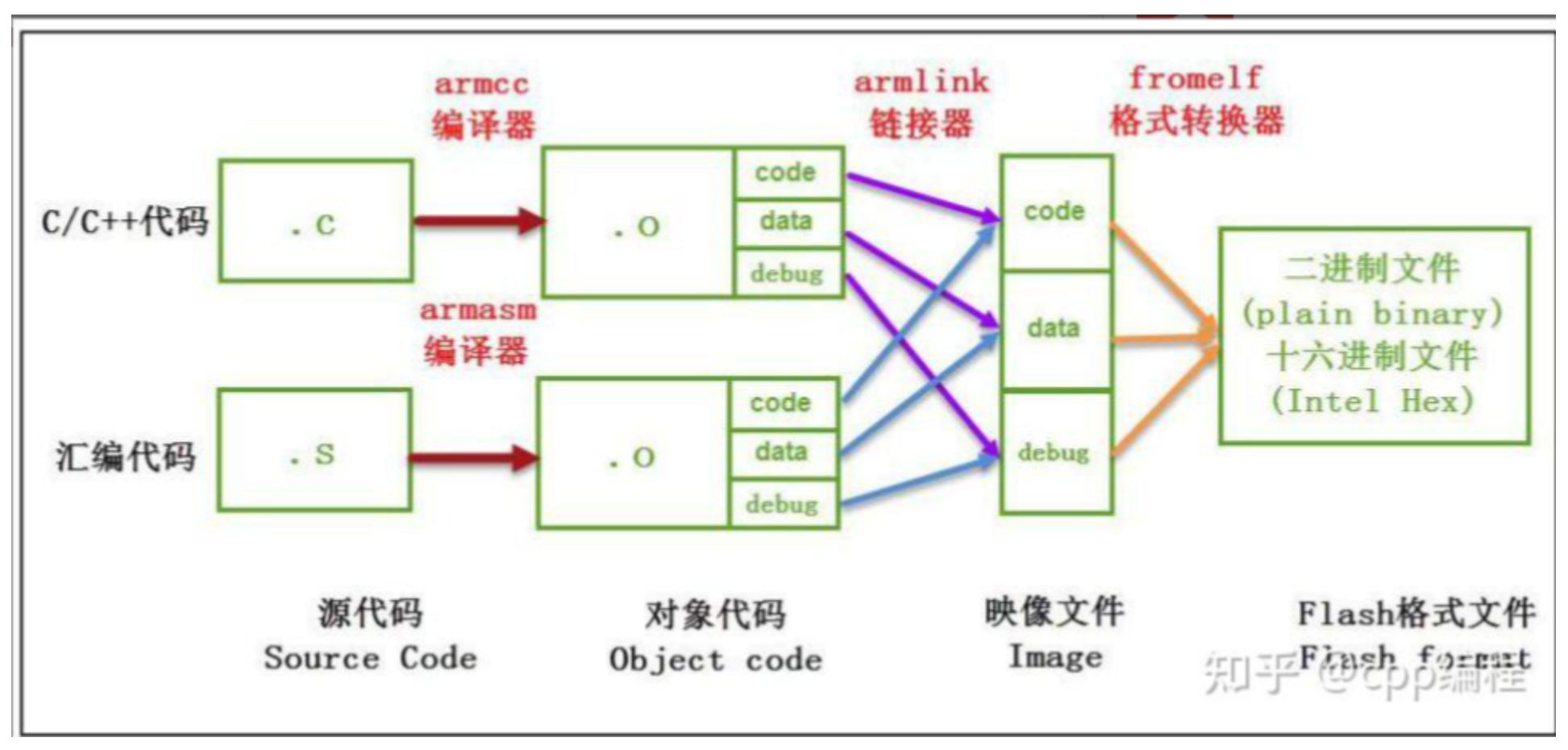
1)无操作系统的二进制文件内存分布(bin/hex)
1、源文件转化为二进制/十六进制文件过程
2、二进制/十六进制文件 加载到内存中运行
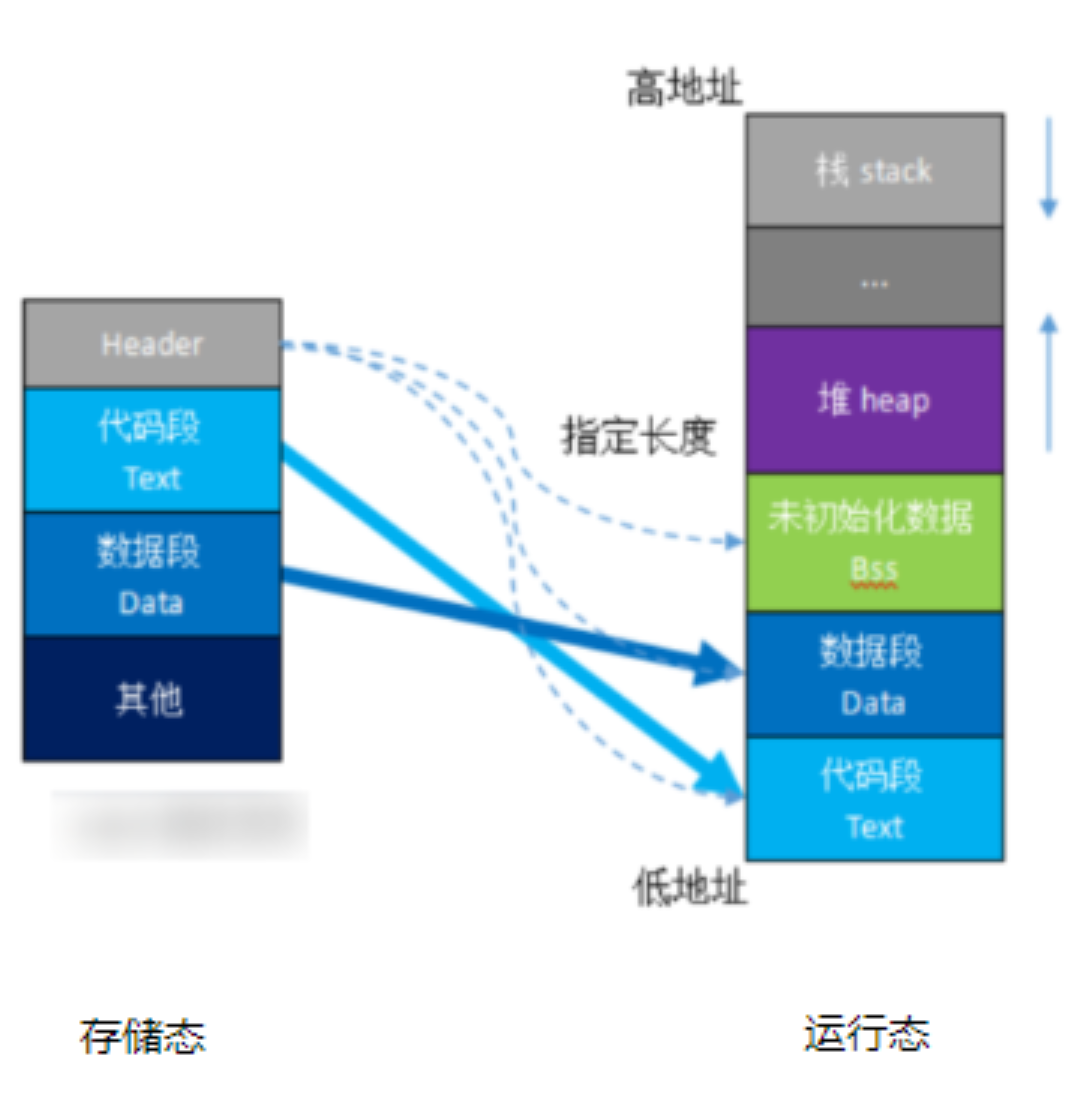
1)对于没有RAM的单片机,由于直接运行在NOR FLASH上,存储态=运行态;
2)程序文件为什么要区分代码段时数据段?
1、由于硬件架构设计如此,PC指针是自动增长的,代码段放在一起才能使得PC指向的都是指令。
3)BSS段和数据段的区别?
1、BSS (block started by symbol)段和数据段都是用于存放数据,BSS段存放的是没有初始值的数据,BSS段在实际文件中是不占内存的,只记录占据的长度,等到运行时再划分实际的地址空间给它,指令中只需要知道变量的地址;
2、换言之,BSS段和数据段本质上可以不划分,软件层面的优化措施,一来节省文件空间,二来可以统一初始化,提升效率,对于嵌入式系统而言,资源就是成本,成本就是竞争力,是有必要的;
2)Linux下的可执行程序的内存分布
1、数据段、代码段、BSS段以及堆和栈解析: https://zhuanlan.zhihu.com/p/348026261
2、程序在Flash和SRAM的空间分配:https://www.cnblogs.com/39950436-myqq/p/11387179.html
3、Linux下的程序文件格式为ELF,比如采用32位系统,4G物理内存,ELF文件的静态组成(存储态)和 加载到内存(运行态)如下
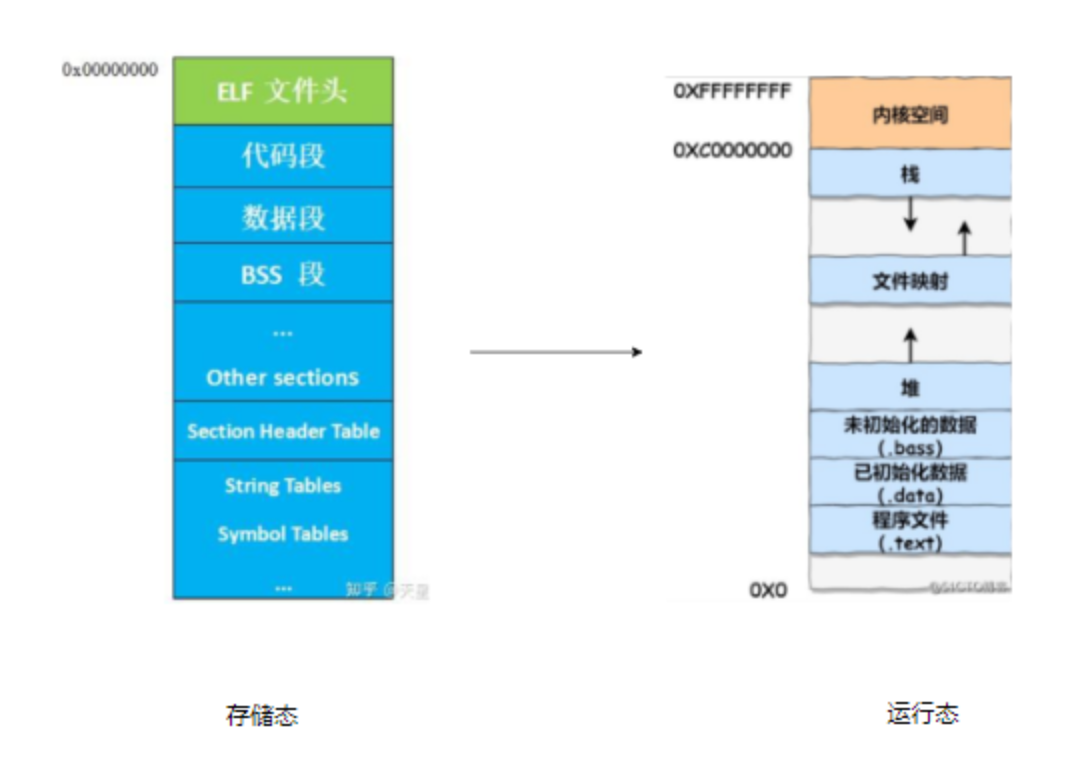
与没有操作系统的程序文件整体上是一样的,差异的地方
1、存储态的ELF格式加入更多的信息 - 操作系统管理所要求;
2、运行态,由Linux操作系统负责将ELF格式加载到RAM中,具备更多的功能,比如内核与进程分开存放,增加文件映射区等;
3)Linux系统镜像格式(内存分布)
1、链接脚本
android/kernel/fusion/4.19/arch/arm/kernel/vmlinux.lds.S
规划各个sections的分布
2、根据链接脚本,编译器生成的Linux kernel 内核镜像sections分布如下
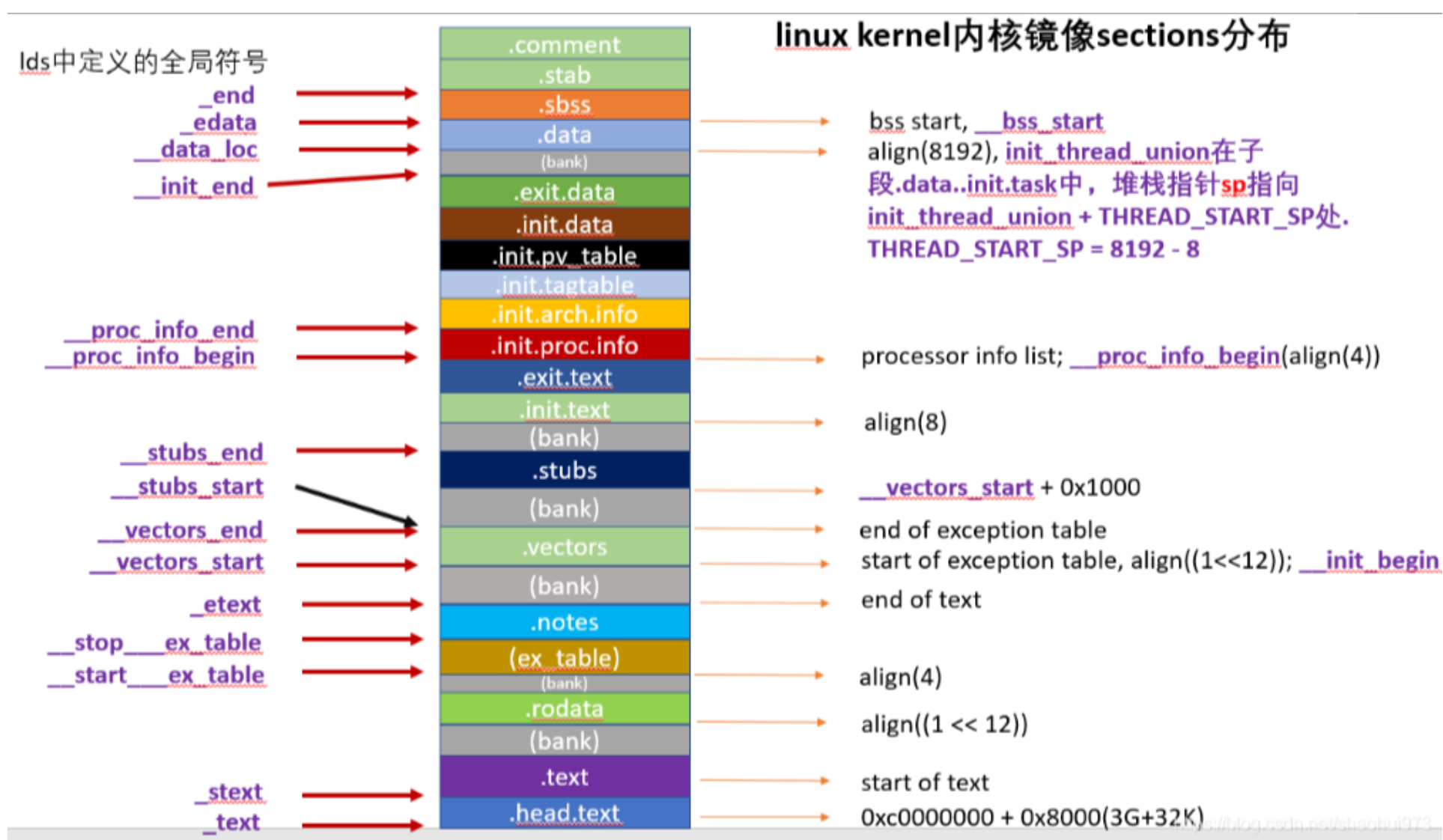
3、内核镜像在RAM中的布局如下(深入Linux内核架构)
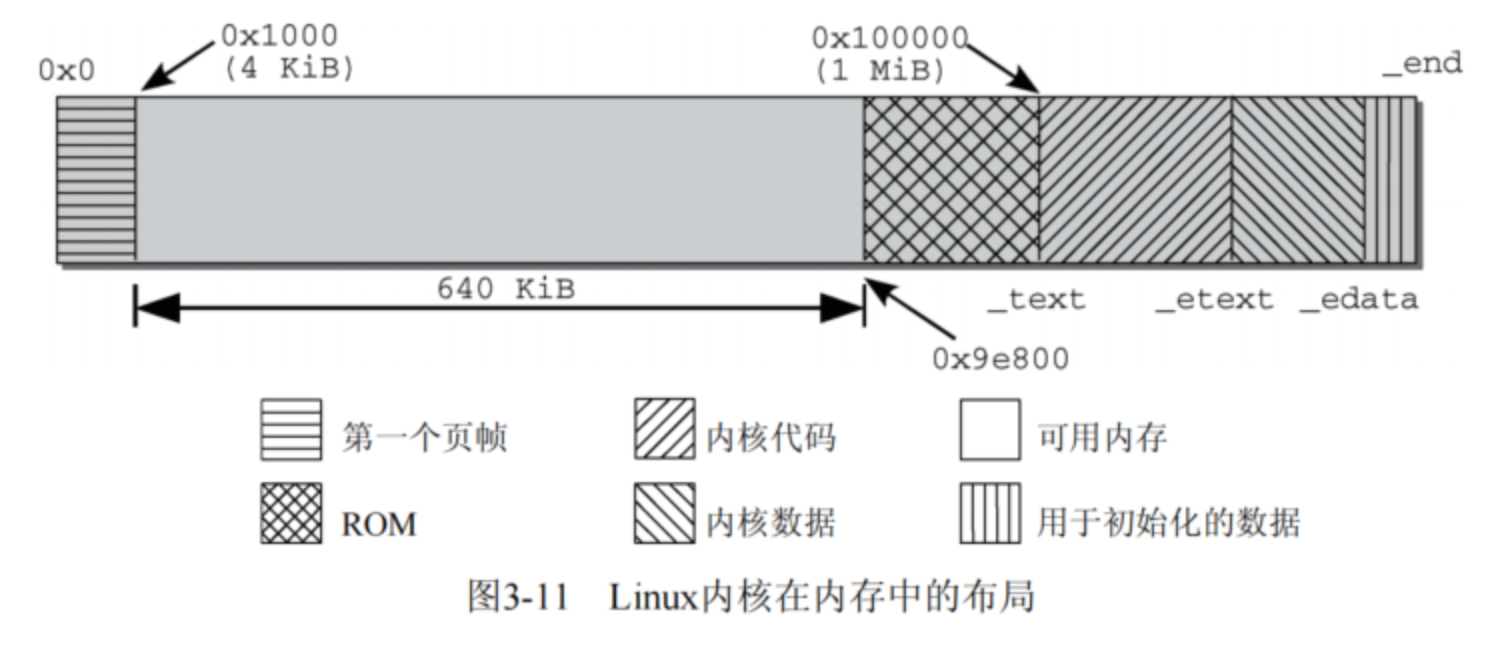
1)物理内存划分为系统预留部分(页帧、ROM等)和 内核;
2)可以看到大致上与普通程序的布局类似,代码段、数据段和BSS段;
3)查看系统内存的划分
1、cat /proc/iomem
00000000-0009e7ff : System RAM
0009e800-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000f0000-000fffff : System ROM
00100000-17ceffff : System RAM
00100000-00381ecc : Kernel code
00381ecd-004704df : Kernel data
2、cat System.map
5)Linux内存管理机制
Linux系统采用的虚拟内存策略(现代大型系统都基本采用虚拟化技术),要运行的Linux的芯片 硬件上必须要支持MMU,先来看MMU
1、MMU开启虚拟世界
1)原理框架
MMU的作用有三个:地址映射、控制memory的访问权限,控制memory attribute
高端芯片平台才会有MMU模块,没有MMU之前是如何进行memory访问权限的?
以uClinux系统为例,没有隔离,依赖软件约定和静态链接,非法访问会导致整个系统崩溃
Linux和uClinux详细对比
| 特性 | 有 MMU 的 Linux | 无 MMU 的 uClinux(1991年开发) |
|---|---|---|
| 地址空间 | 每个进程有独立的虚拟地址空间 | 所有进程共享单一物理地址空间 |
| 隔离性 | 硬件强制隔离,进程无法互相访问 | 无隔离,依赖软件约定和静态链接 |
| 权限控制 | 精细的硬件权限控制(R/W/X, U/S) | 几乎无权限控制 |
| 错误处理 | 非法访问触发 Segfault,仅崩溃违规进程 | 非法访问可能导致整个系统崩溃 |
| 内存管理 | 支持虚拟内存、按需分页、交换 | 只有物理内存,静态分配 |
fork() | 支持 Copy-on-Write | 被 vfork() 替代 |
mmap() | 支持 | 不支持 |
| 适用场景 | 服务器、桌面、手机等通用计算 | 低成本、低功耗、深嵌入式设备 |
MMU是现代操作系统多任务安全和稳定运行的基石,没有MMU的CPU只能跑裸机、RTOS、uClinux,无法多进程任务(RTOS)或有限的多进程任务(uClinux);
2、虚拟内存与物理内存的映射关系
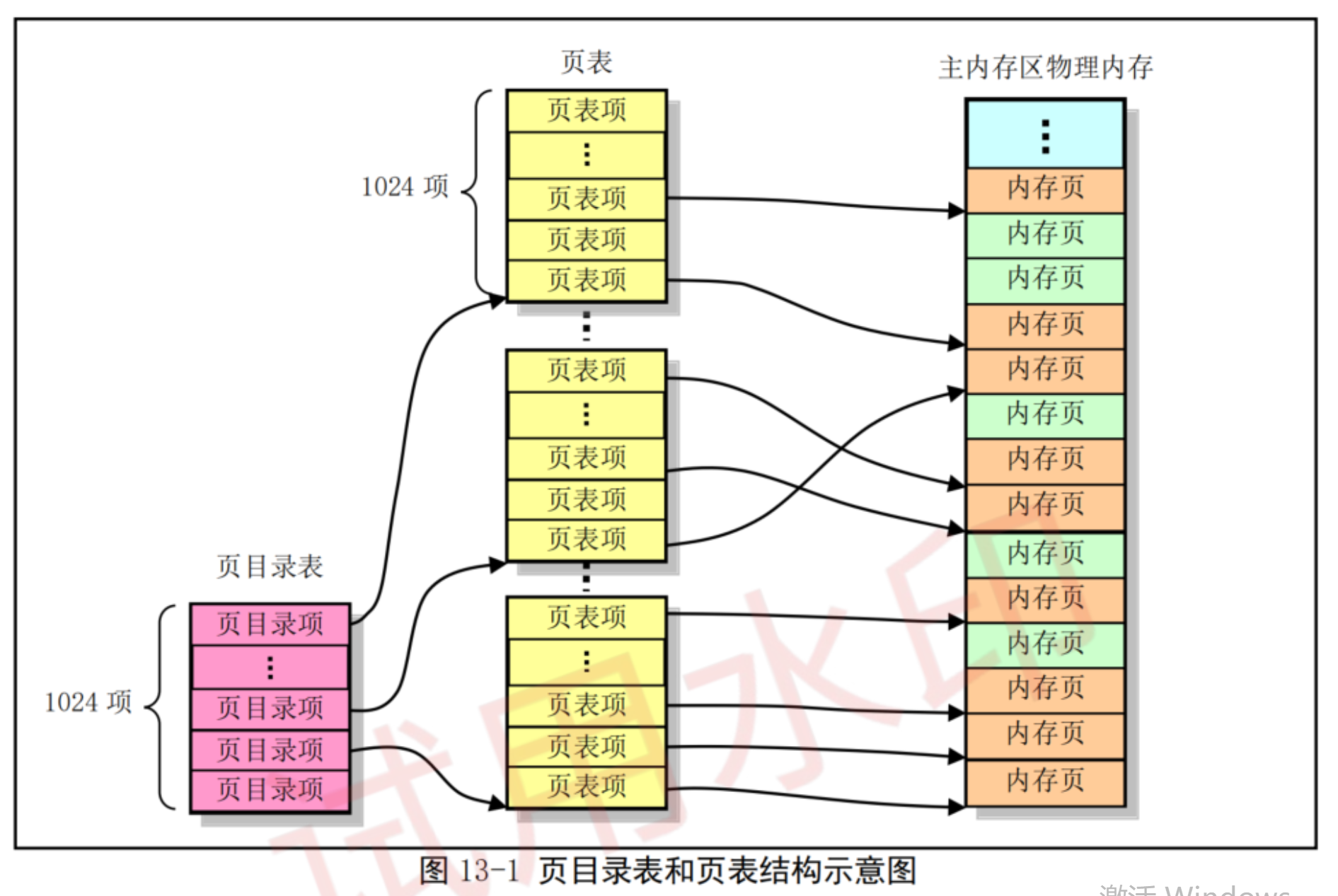
1)将虚拟内存切分成页,每一页都使用页表结构体记录;
2)内存页是一块连续地址的物理内存块;
3、哪些是硬件做的,哪些是软件做的?
代码中如何设置?
4、什么时候开启?启动内核初期
/android/kernel/fusion/4.19/arch/arm/kernel/head.S
1. 创建页表(运算)
__create_page_tables:
pgtb1 r4, r8
ENDPROC(__create_page_tables)
2. 打开mmu
__enable_mmu:
b __turn_mmu_on
ENDPROC(__enable_mmu)
主要工作,
1)先禁止Icache/Dcache,避免数据混乱,等开启MMU后再打开;
2)设置页表寄存器;
3)打开MMU;
3.__turn_mmu_on
ENTRY(__turn_mmu_on)
mov r0, r0
instr_sync
mcr p15, 0, r0, c1, c0, 0 @ write control reg
mrc p15, 0, r3, c0, c0, 0 @ read id reg
instr_sync
mov r3, r3
mov r3, r13
ret r3
__turn_mmu_on_end:
ENDPROC(__turn_mmu_on)
5、打开MMU后的内存布局
http://www.wowotech.net/linux_kenrel/turn-on-mmu.html
6、常见问答
1)为什么不在bootloader打开MMU?
1)对于ARM架构,内核文档明确要求 Bootloader 在跳转到内核入口点时,MMU必须为关闭状态 - 目的是保证了内核在启动时从一个“纯净”的、未开启MMU的物理地址世界开始,从头构建完全属于自己的、可控的虚拟地址空间;
2)bootloader本身是单线程任务(宗旨是保持简单和轻量),并且运行时间短,使用MMU带来的效益极小,反而使用MMU大大增加复杂度和移植难度;
2)ARM为什么不默认开启MMU,在linux上可以默认打开,但ARM不单单只运行Linux,还需兼容其它OS!
3)系统如何识别物理地址(PA)和虚拟地址(VA)?
开启MMU后,CPU发出的均是虚拟地址,并且会经过MMU(因为设置enable了),如何转换物理地址并存取CPU是不管;
2、Cache提高系统性能
1、原理框架
https://zhuanlan.zhihu.com/p/37749443
2、主要是硬件和系统共同工作
3、如何解决cache一致性问题?存在于SMP架构中
一般而言内核会自动完成对Cache的操作,但内核仍然提供了一些命令,可以直接作用于处理器的高速缓存和TLB。但这些命令并
非用于提高系统的效率,而是用于维护缓存内容的一致性,确保不出现不正确和过时的缓存项。
如果你必须保证不能出现过时或不正确的缓存项,就应该使用他们,操作系统有时也会失灵或处理不及时。
4、方法
1、内核提供以下接口供开发者调用
1)flush_tlb_all/flush_cache_all 影响所有进程和所有处理器;
2)flush_tlb_mm/flush_cache_mm 影响属于地址空间mm;
3)flush_tlb_range(vma, start, end)/flush_cache_range(vma, start, end)
4) flush_tlb_page/flush_cache_page
5)icache/dcache独立刷新接口 :flush_icache_*/flush_icache_*
2、flush_cache_和flush_tlb_一般是成对使用
flush_cache_mm(oldmm);
...
/* 操作页表 */
...
flush_tlb_mm(oldmm);
操作的顺序是:刷出高速缓存、操作内存、刷出TLB。这个顺序很重要,有下面两个原因。
1、如果顺序反过来,那么在TLB刷出之后、正确信息提供之前,多处理器系统中的另一个CPU
可能从进程的页表取得错误的信息。
2、在刷出高速缓存时,某些体系结构需要依赖TLB中的“虚拟->物理”转换规则(具有该性质
的高速缓存称之为严格的)。flush_tlb_mm必须在flush_cache_mm之后执行,以确保这一点。
6)Linux内存管理子系统(虚拟内存)
1、正式进入虚拟内存世界
1)从Linux内存管理机制可以看到,在系统启动后(启动MMU),我们看到的都是虚拟内存,用的都是虚拟地址(也称逻辑地址),从这里开始所有的理论都基于虚拟内存来讨论;
2、内存管理子系统做什么?
1、面向系统功能:
1)由于增加了虚拟内存技术,第一任务当然是完成虚拟内存到物理内存的映射(内存分页管理机制),其次是当实际程序段不在内存时应,处理缺页异常,从FLASH里搬到物理内存(Load on demand)。
2)写时复制机制(copy on write) - 用于fork进程时,为了加快进程创建,与父进程共用内存空间;等到需要改动时再去拷贝内存空间;
3)合理使用物理内存等;
2、面向开发者:实现内核的内存分配方法提供给开发者调用;
3、Linux用户空间和内核空间的内存划分(虚拟内存)
1)先来看看如果不采用虚拟内存,则内存划分如下

1、这种情况视乎物理内存大小,程序大小,容纳有限的内容;
2)采用虚拟化内存技术,系统中运行多个程序时,内存划分如下
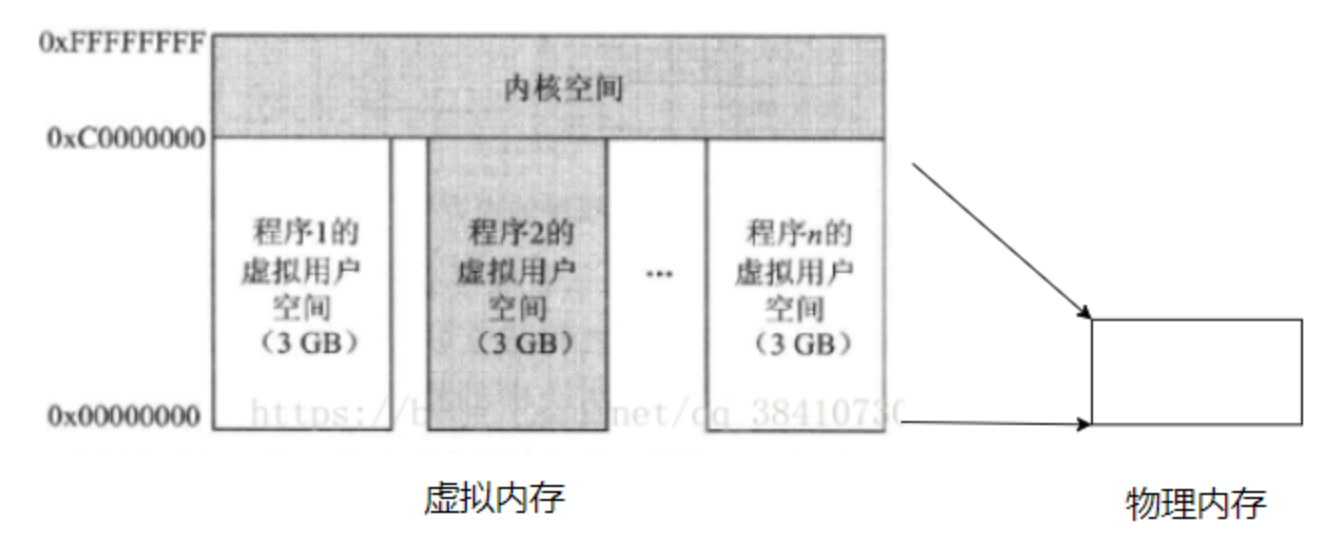
1、在一个32位系统中,一个程序的虚拟空间最大可以是4GB,那么最直接的做法就是,把内核也看作是一个程序,使它和其他程序一样也具有4GB空间。但是这种做法会使系统不断的切换用户程序的页表和内核页表,以致影响计算机的效率。解决这个问题的最好做法就是把4GB空间分成两个部分:一部分为用户空间,另一部分为内核空间,这样就可以保证内核空间固定不变,而当程序切换时,改变的仅是程序的页表。这种做法的唯一缺点便是内核空间和用户空间均变小了。
2、程序1、2……n共享内核空间。当然,这里的共享指得是分时共享,因为在任何时刻,对于单核处理器系统来说,只能有一个程序在运行
3、相较于直接运行在物理内存,本质上是效率换空间;
4、框架源码分析
Linux内存管理大部分工作在实现虚拟化技术,比如分页管理、交换内存等
1、架构相关实现
1、android/kernel/fusion/4.19/arch/arm/mm
/android/kernel/fusion/4.19/arch/arc/mm/init.c
void __init mem_init(void)
{
#ifdef CONFIG_HIGHMEM
unsigned long tmp;
reset_all_zones_managed_pages();
for (tmp = min_high_pfn; tmp < max_high_pfn; tmp++)
free_highmem_page(pfn_to_page(tmp));
#endif
free_all_bootmem();
mem_init_print_info(NULL);
}
2、内存管理子系统
1、源码位置
android/kernel/fusion/4.19/mm/*
2、android/kernel/fusion/4.19/mm/memory.c
Linux 内核中内存管理子系统的重要文件,主要实现了虚拟内存管理的核心功能
1)页错误处理核心路径
handle_mm_fault()
├── __handle_mm_fault()
│ ├── handle_pte_fault()
│ │ ├── do_anonymous_page() # 匿名页面处理
│ │ ├── do_fault() # 文件映射页面处理
│ │ ├── do_swap_page() # 交换页面处理
│ │ └── do_numa_page() # NUMA 页面迁移
│ └── 透明大页面处理
└── hugetlb_fault() # 大页面处理
2.写时复制
do_wp_page()
├── wp_page_reuse() # 复用页面
└── wp_page_copy() # 复制页面
├── anon_vma_prepare()
├── alloc_page_vma()
└── cow_user_page()
3.页表操作
__pte_alloc() # 分配 PTE
__pmd_alloc() # 分配 PMD
__pud_alloc() # 分配 PUD
free_pgd_range() # 释放页表范围
4.页面分配和映射
vm_insert_page() # 插入单个页面
vm_insert_pfn() # 插入 PFN 映射
remap_pfn_range() # 重新映射 PFN 范围
apply_to_page_range() # 对页表范围应用操作
5.TLB管理
tlb_gather_mmu() # 开始 TLB 收集
tlb_finish_mmu() # 完成 TLB 操作
tlb_flush_mmu() # 刷新 TLB
__tlb_remove_page() # 从 TLB 移除页面
3、android/kernel/fusion/4.19/mm/swap.c
将内容从磁盘交换到内存
void __init swap_setup(void)
void __put_page(struct page *page)
1、android/kernel/fusion/4.19/include/linux/mm_types.h
struct page {
unsigned long flags;
union {
struct { /* Page cache and anonymous pages */
struct list_head lru;
struct address_space *mapping;
pgoff_t index;
unsigned long private;
}
struct { /* 用于 slab, slob and slub 内存管理算法 */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next
short int pages;
short int pobjects;
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
unsigned long counters; /* SLUB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
....
}
union {
unsigned int page_type;
unsigned int active; //SLAB
int units; //SLOB
}
atomic_t refcount;
}
5、Linux系统内存中的程序(虚拟内存)
深度解析内存中的程序(运行):
https://www.jianshu.com/p/0f66c406c0f7
进程在内存中的样子(调度):
https://zhuanlan.zhihu.com/p/401087855
6、32位系统,可以外接超过4G的内存条?
可以接,需要使用硬件技术PAE/LPAE支持,PAE(x86架构)/LPAE(ARM架构)
为什么32位CPU通常不能支持超过4GB RAM?
https://blog.csdn.net/weixin_52631945/article/details/146438850
它将 CPU 可以寻址的物理地址线从 32 位(4GB)扩展到了 36 位。36 位地址意味着可以管理 236=64GB236=64GB 的物理内存。
PAE 并没有改变虚拟地址空间的大小! 虚拟地址仍然是 32 位,所以单个进程仍然被限制在 4GB 的虚拟地址空间内(因为一个LPAE技术中的Paging最大仍然是4GB)。CPU 的 MMU 使用了一种新的、支持 36 位物理地址的页表结构来翻译地址。
值得注意的是32 位系统能支持超过 4GB 的物理内存,是一个 “系统级” 的特性,而不是 “进程级” 的特性。它允许操作系统更有效地利用物理资源(例如,在内存中缓存更多磁盘数据,从而加快系统整体速度),但无法突破单个应用程序 4GB 内存的限制。
这正是推动 64 位计算普及的根本原因:64 位系统不仅支持巨大的物理内存,更重要的是为每个进程提供了近乎无限的虚拟地址空间(通常是 128TB),彻底打破了这一瓶颈。
7)Linux内核空间的虚拟内存划分
1、内核里分配内存与用户态的区别
1)内核空间 较于 用户空间,能用的内存不多;比如内核栈只有4K/8K,为什么分配给内核这么少的内存空间?
2)内核一般不能睡眠等严格要求;
用户空间分配内存仅用malloc即可,而内核分配内存需要细分用途,按需分配;
2、不同体系结构的机器由于硬件实现导致内存分配会有所不同,接下来使用常用的x86体系,32位机器来说明Linux内核空间的内存分配!
1)内核空间中“区”的概念(基于虚拟内存)
由于硬件限制,内核并不能对所有虚拟内存的页一视同仁,Linux系统将内核空间划分为不同的区(zone)

1)ZONE_DMA/ZONE_NORMAL称为低端内存,ZONE_HIGHMEM称为高端内存;
2)区的概念只针对内核空间,用户空间不区分;用户进程最多只可以访问3G物理内存,而内核进程必须可以访问所有物理内存;
3)只有物理内存超过内核地址空间范围,才会存在高端内存。对于32位系统,超过1G内存才会产生高端内存;
4)理解区的划分机制,才能更好地掌握内核的各种内存分配方式;
5)每个区使用struct zone表示
/android/kernel/fusion/4.19/include/linux/mmzone.h
struct zone {
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
struct free_area free_area[MAX_ORDER];
unsigned long flags;
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
}
2)深化Linux内核空间的虚拟内存划分
1)Linux的内核空间(低端内存、高端内存)由来和解析
https://blog.csdn.net/qq_38410730/article/details/81105132
2)linux 用户空间与内核空间——高端内存详解
https://blog.csdn.net/Tommy_wxie/article/details/17122923
3)高端内存映射之kmap持久内核映射–Linux内存管理(二十)
https://cloud.tencent.com/developer/article/1381079?policyId=1003
按照虚拟化的定义,虚拟内存与物理内存的映射关系是非线性的、随机的,但这种随机映射,在访问内存效率上会低一些,由于内核在系统运行周期是一个最高等级的常驻“进程”,并且资源是紧张的,因此内核建立一套自己”特殊“的映射规则,大大增加了软件复杂度,但为了提高效率,软件如何复杂都是有意义的!
1、内核空间映射到物理内存的高效策略
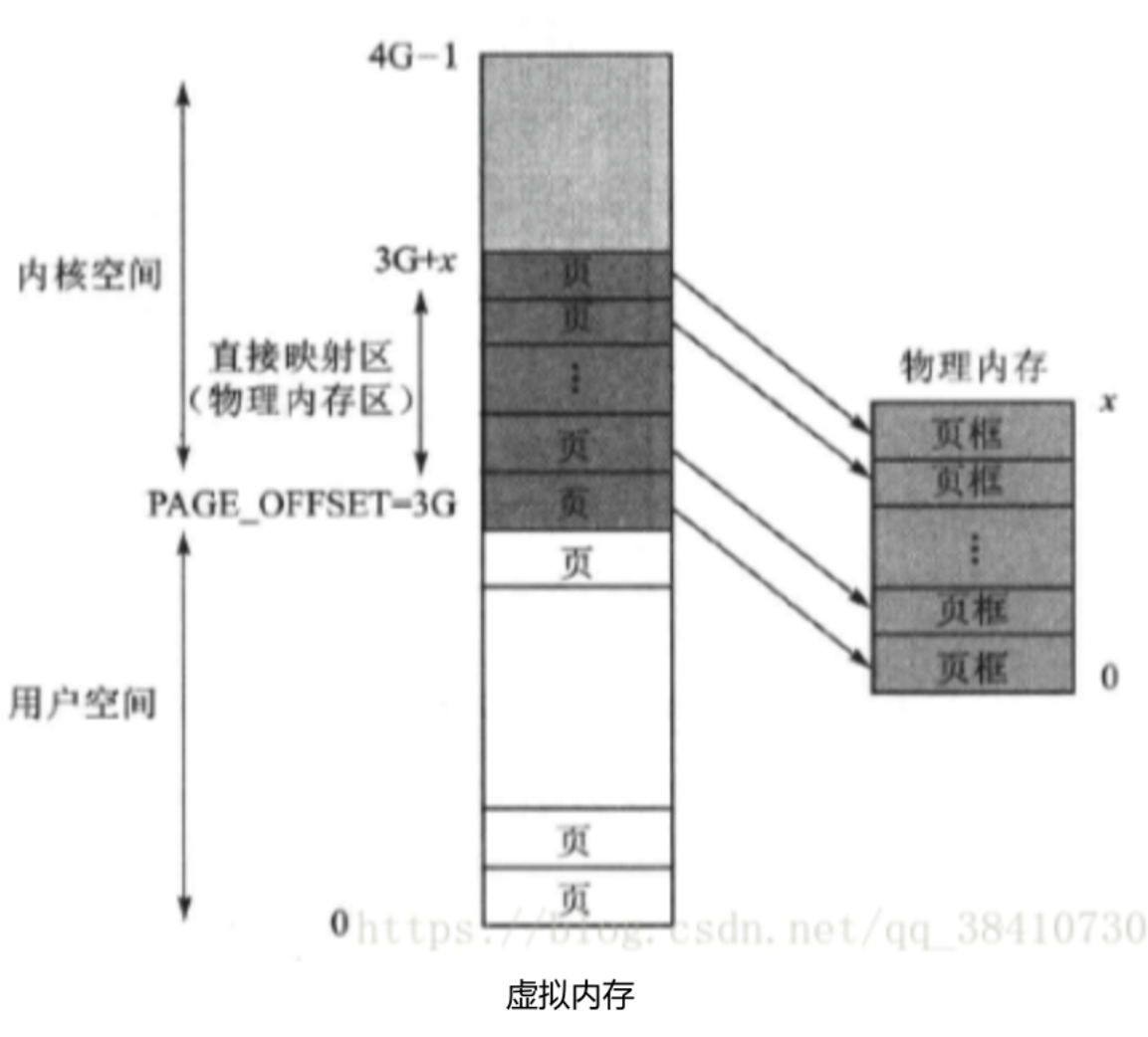
1)直接映射区(虚拟内存中的物理内存区)
也称为固定映射区、永久映射区
为了提高内核通过虚拟地址访问物理地址内存的速度,内核空间的虚拟地址与物理内存地址采用了一种从低地址向高地址依次一一对应的固定映射方式,当内存小于1G时,直接映射区=物理内存;
1、这里的映射只是“预定占用”,即当CPU使用内核页1的代码时,交换到物理内存的页框1中,不使用时会腾出空间给用户进程等使用;
2、此区域可以使用kmalloc来获得连续地址空间的动态内存,注意由于虚拟地址和实际的物理地址都是线性的,因此被冠名为在“物理内存”上分配内存,不要混淆,当开启了MMU后,我们看到的都是虚拟地址空间,我们都应该站在虚拟空间来思考问题;
2)vmalloc映射区(纯粹虚拟内存区)
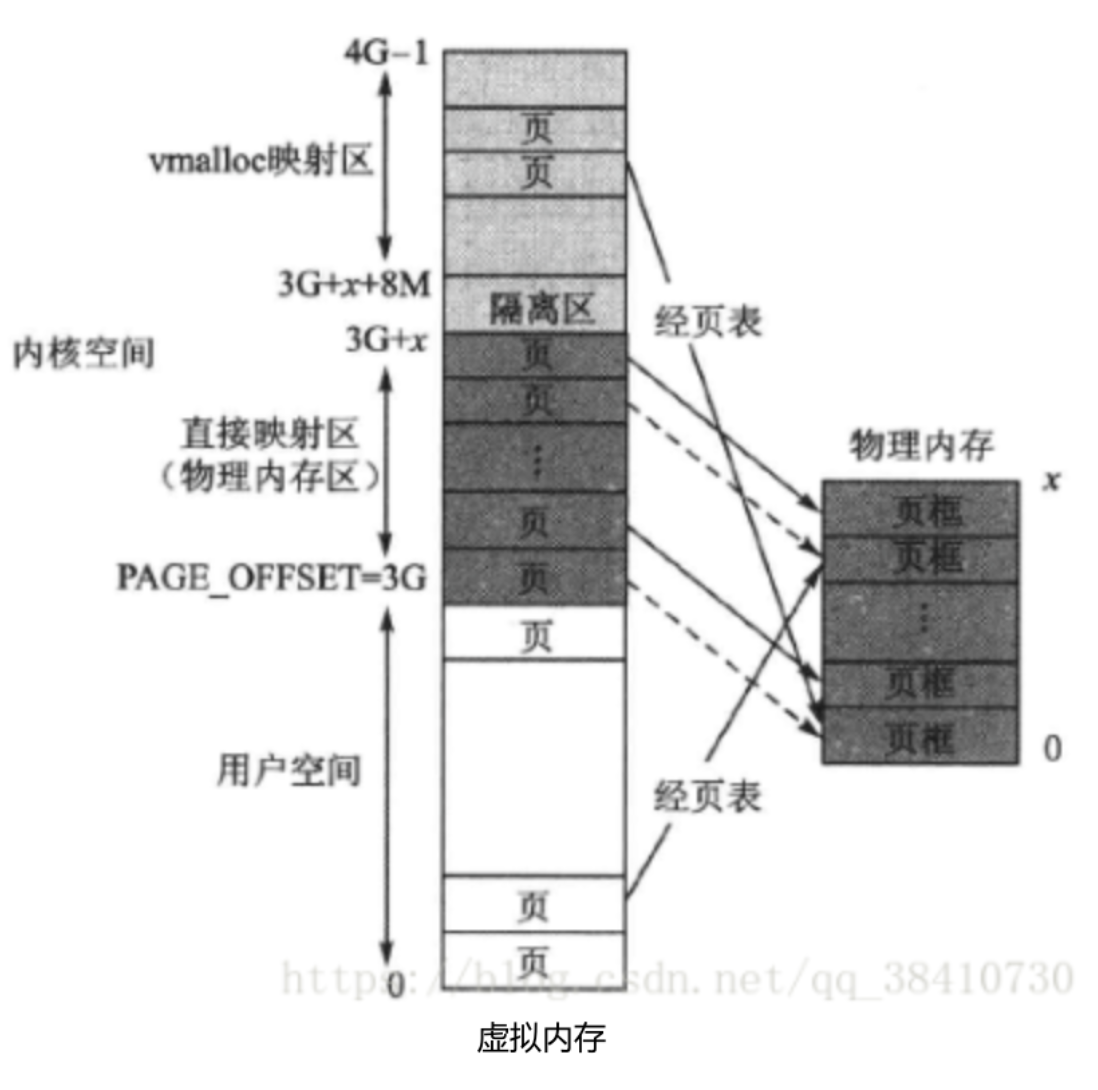
除去直接映射区,那么内核空间剩余的内核虚拟空间怎么办呢?
当然还是按照普通虚拟空间的管理方式,以页表的非线性映射方式使用物理内存。具体来说,在整个1GB内核空间中去除固定映射区,然后在剩余部分中再去除其开头部分的一个8MB隔离区,余下的就是映射方式与用户空间相同的普通虚拟内存映射区。在这个区,虚拟地址和物理地址不仅不存在固定映射关系,而且通过调用内核函数vmalloc()获得动态内存,故这个区就被称为vmalloc分配区;
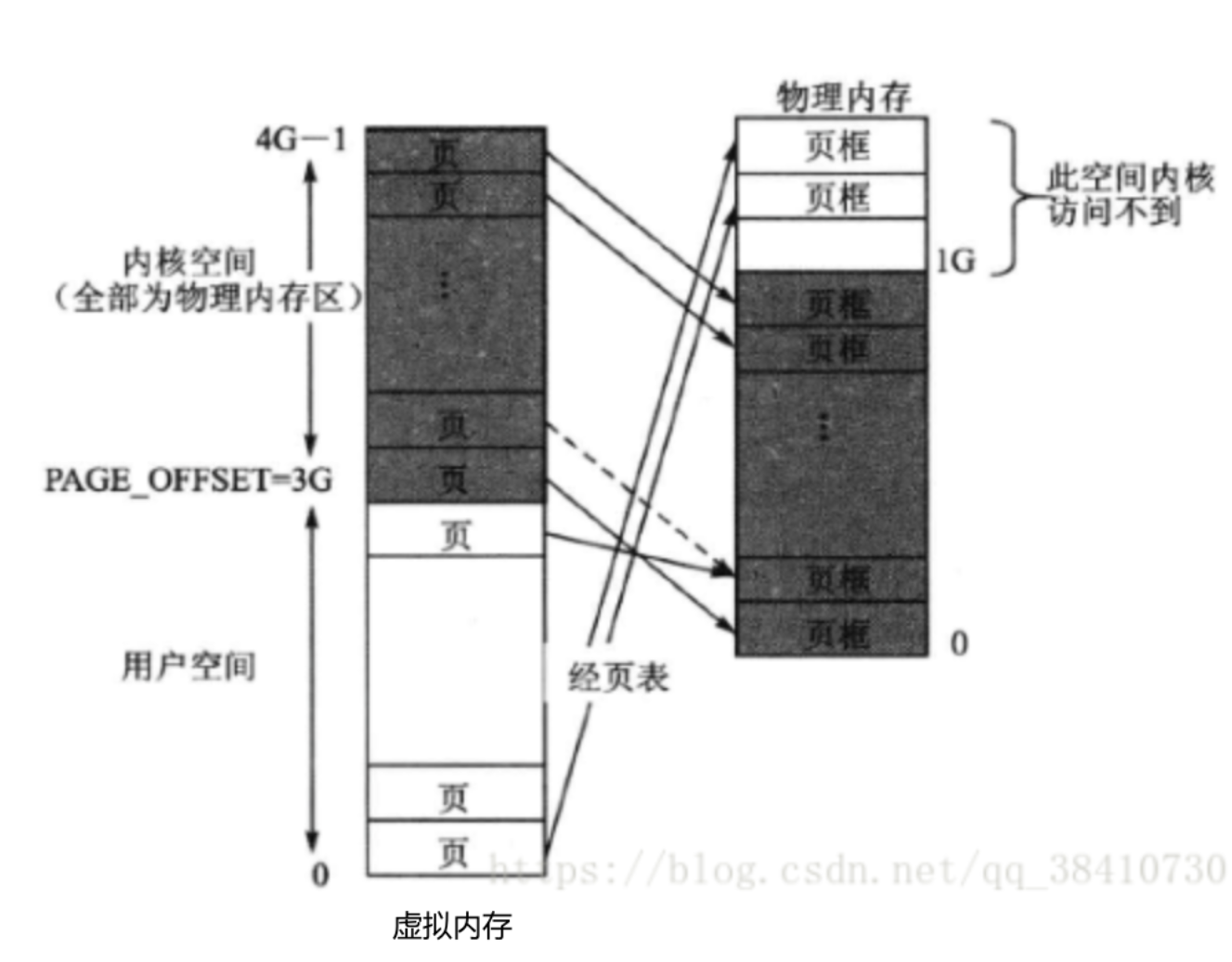
3)高端内存(用于随机映射到物理内存)
随着计算机技术的发展,计算机的实际物理内存越来越大,从而使得内核固定映射区(线性区)也越来越大。显然,如果不加以限制,当实际物理内存达到1GB时,vmalloc分配区(非线性区)将不复存在。于是以前开发的、调用了vmalloc()的内核代码也就不再可用,显然为了兼容早期的内核代码,这是不能允许的。
1、现状
2、解决办法
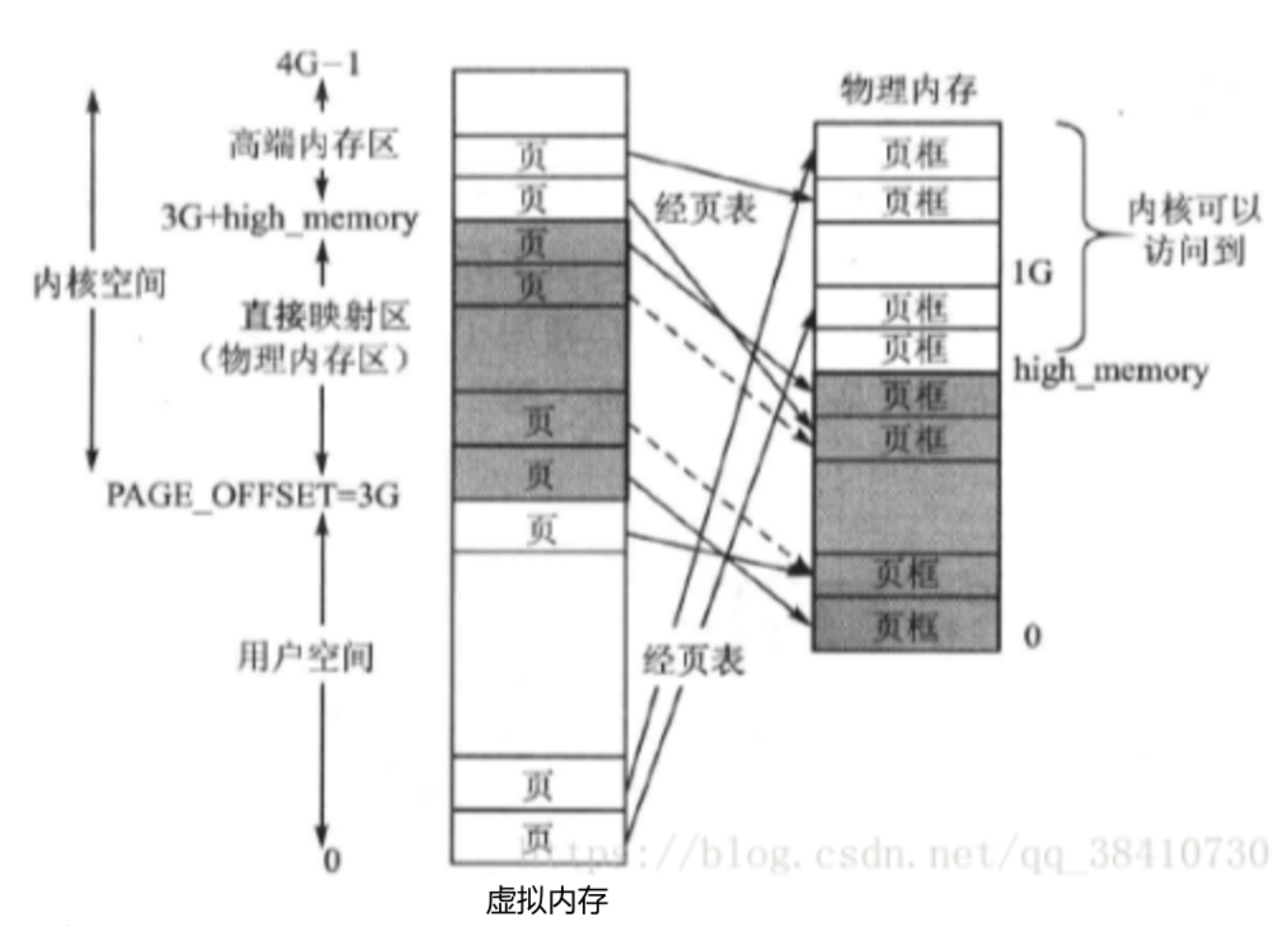
预留128M空间用于随机映射物理内存;
3、内核空间的最终布局
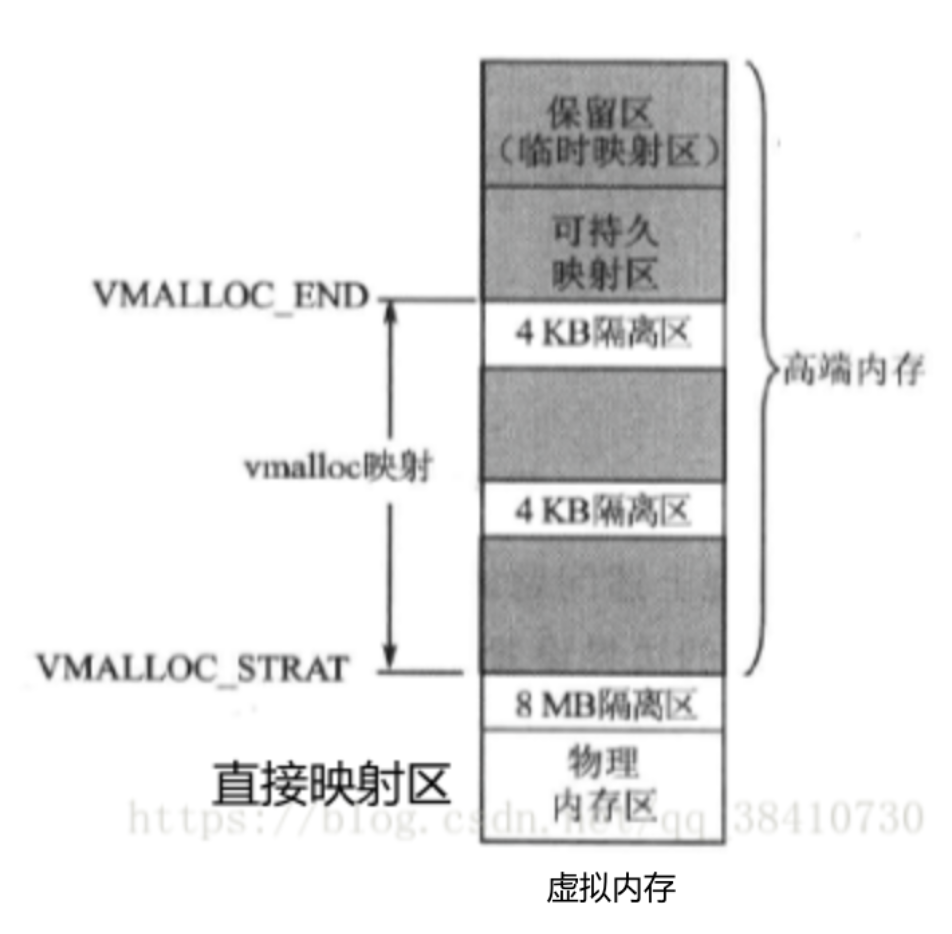

1)直接映射区和vmalloc映射区不变,开辟新的内存区域:可持久映射区和临时映射区
2)物理内存低于1G,还会有高端内存吗?还会有可持久映射区和临时映射区吗?
是否存在使用宏控制CONFIG_HIGHMEM,高端内存是内核空间的虚拟地址划分,与实际物理内存是多大没有关系;这种设计确保了内核无论物理内存大小如何,都能以统一的方式管理内存访问。
3)接下来我们均以这种划分模型来进行学习讨论;
4)VMALLOC_START - VMALLOC_END只能是vmalloc使用吗?
alloc_pages(GFP_HIGHMEM, 0); 可以用到
5)永久内存映射区和临时映射区,两块小内存的作用和用途?
1、如果使用了alloc_pages() 从高端内存中的动态内存映射区获得了内存空间,此时根据定义,此处空间对应的物理内存不是线性的,如果需要线性的物理内存,则可以通过kmap接口映射到 永久内存映射区;但这个空间通常为4MB,最多能映射1024个页框,数量较为稀少,需要尽快使用完并释放。
2、进一步地如果不仅需要物理线性地址,并且还不能睡眠,就映射到临时映射区;
临时映射区具有如下特点(实现原子操作的原理):
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
1、在x86结构的内核空间,三种类型的区域如下:
ZONE_DMA:内核空间开始的16MB
ZONE_NORMAL:内核空间16MB~896MB(称为固定映射、永久映射、直接映射)
ZONE_HIGHMEM :内核空间896MB ~ 结束(1G)(非永久映射区)
2、VMALLOC区域大小的定义
/android/kernel/fusion/4.19/arch/arm/include/asm/pgtable.h
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
#define VMALLOC_END 0xff800000UL
3、在X86体系结构上,高于896MB的所有物理内存的范围大都是高端内存,它并不会永久地或自动地映射到内核地址空间
1)如何理解永久映射到内核地址空间?
永久映射(Permanent Mapping)指的是物理内存页与内核虚拟地址之间建立固定、长期的映射关系,即虚拟内存和物理内存一一对应,相当于直接使用物理内存,比如直接映射区,永久和非永久有什么区别影响?只涉及效率,永久映射效率更佳!
2)持久映射?永久映射在编译阶段就已经确定,持久映射则从kmap()开始,直到umkmap()结束;
kmap可以用到低端和高端内存,但里面的操作不同,对于低端内存(因为低端内存本身就是永久映射区,相当于空操作),直接返回虚拟地址,对于高端内存,先建立永久映射,再返回虚拟地址;
3)临时映射(也称为原子映射),用在不能睡眠的地方,比如中断处理程序可以使用,比如kmap_atomic();
4、不同映射区,采用不同的内存分配函数,后面会详解;
3)内核内存分配接口
1、一文搞懂Linux内核内存常见分配方式
https://zhuanlan.zhihu.com/p/667864363
2、详解kmalloc、vmalloc、__get_free_pages、mempoll_alloc
https://blog.csdn.net/liangzc1124/article/details/120837260
先来了解内存分配算法slab和gfp_mask,这些是内核内存分配接口的核心
内存分配算法slab
1)preface
1)名字的由来slab(石板),形容算法过程的一块块内存砖块;
2)由于slab的代码量和复杂性都太高,衍生出slob和slub
1、slob( Simple List of Blocks,特点是低代码量),代码量只有600多行
2、slub(Unqueued Slab,特点是最小化内存开销);
3)Linux默认使用slab算法,开发者可以修改MK,选择最合适的算法;
2)slab的实现原理
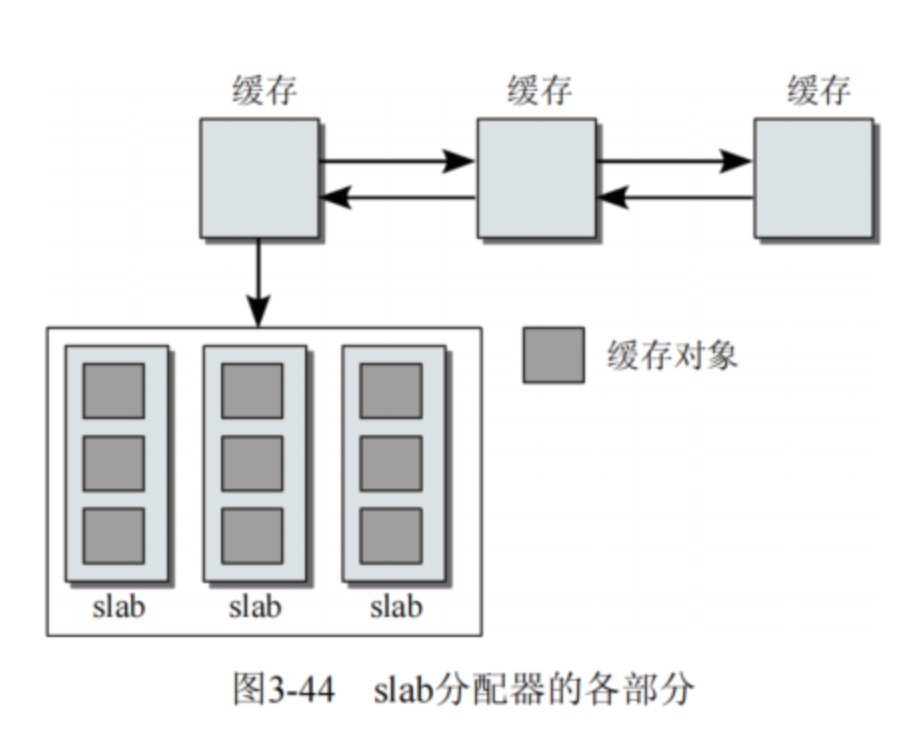
slab分配器(内存管理算法),表示一种小对象高效内存分配机制,缓存分配器(Cache Allocator),本质上通过预分配和对象复用解决传统内存分配的碎片和性能问题,每块石板切割成多个等大的对象槽(Object)。
3)slab算法的位置
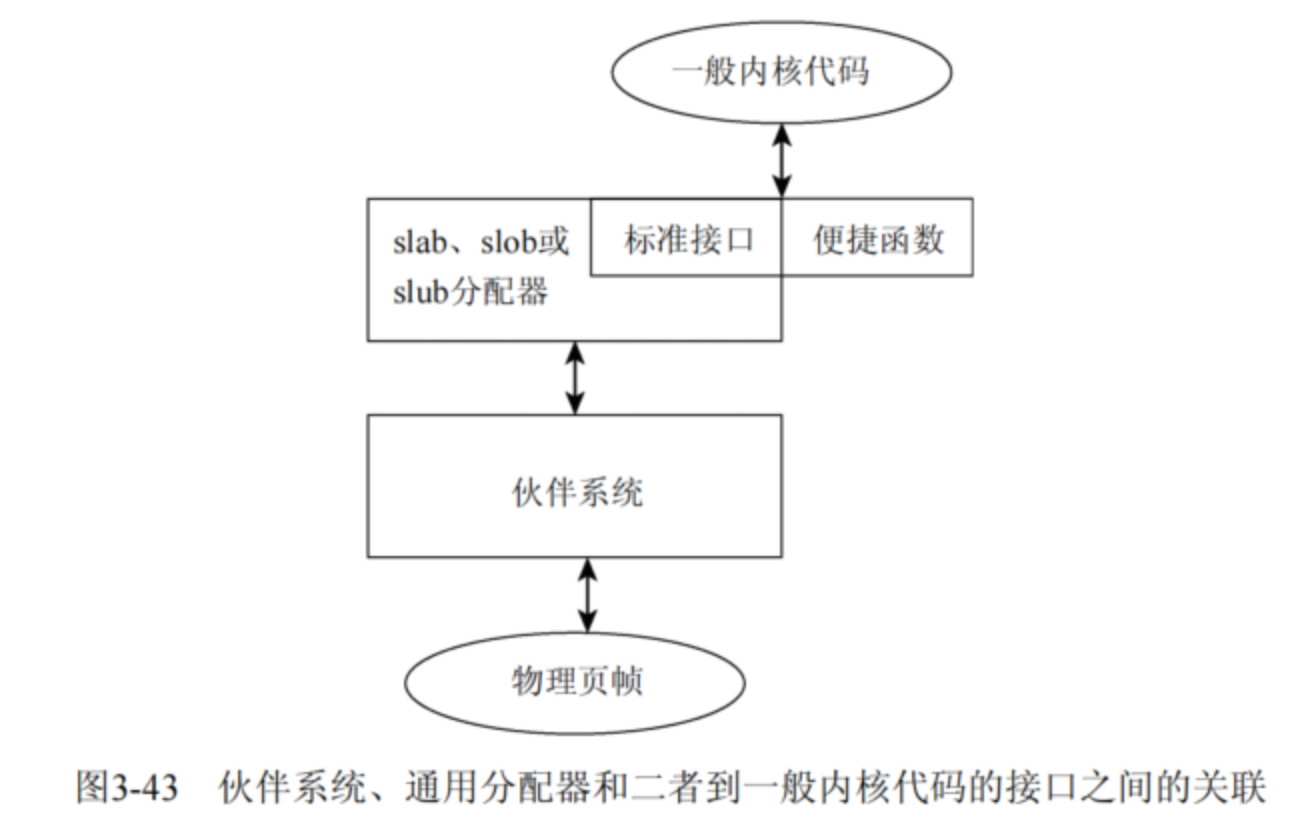
1、在实际使用内存分配接口时,会对接到slab算法来实现底层分配操作。
2、哪些接口使用了slab算法?kmalloc\kmem_cache_create\kmem_cache_alloc
3、源码实现
#include <linux/slab.h>
/android/kernel/fusion/4.19/mm/slab_common.c
/android/kernel/fusion/4.19/mm/slab.c
/android/kernel/fusion/4.19/mm/slob.c
/android/kernel/fusion/4.19/mm/slub.c
丰富的gfp_mask标志
分为三类:行为修饰符、区修饰符及类型
1)行为修饰符

2)区修饰符

1、指定了__GFP_HIGHMEM,优先从HIGHMEM处分配内存,一般情况下,默认使用ZONE_NORMAL;
3)类型标记

标志可以互相组合,最常用的是GFP_KERNEL(会睡眠,优先使用),与之相反的是GFP_ATOMIC(不会睡眠,适合中断处理程序、软中断和tasklet)
1、kmalloc
/android/kernel/fusion/4.19/mm/slab_common.c
1、kmalloc()是内核一个最常用的内核分配函数,以字节为单位,它可以分配一段未清零的连续物理内存页,返回值为直接映射地址。
2、由kmalloc()可分配的内存最大不能超过32页。其优点是分配速度快,缺点是不能分配大于128KB的内存页(出于跨平台考虑),但满足绝大多数的内存分配需求!
3、硬件设备需要得到物理地址连续的内存,因此只能从低端内存里分配内存,kmalloc是其中之一,还有__get_free_pages,与kmalloc的差异是以页为单位分配。
4、kmalloc源码
/android/kernel/fusion/4.19/include/linux/slab.h
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
return kmem_cache_alloc_trace(
kmalloc_caches[kmalloc_type(flags)][index],
flags, size);
#endif
}
return __kmalloc(size, flags);
}
/android/kernel/fusion/4.19/mm/slab.c
__kmalloc()
--__do_kmalloc()
----kmalloc_slab()
----slab_alloc()
----kasan_kmalloc()
/android/kernel/fusion/4.19/mm/slab_common.c
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
--kmalloc_caches[kmalloc_type(flags)][index]
2、vmalloc
1、vmalloc()一般用在为只存在于软件中(没有对应的硬件意义,硬件设备的内存都要求物理地址连续)的较大的顺序缓冲区分配内存,当内存没有足够大的连续物理空间可以分配时,可以用该函数来分配虚拟地址连续但物理地址不连续的内存。
2、vmalloc()用在为活动的交换区分配数据结构,为某些I/O驱动程序分配缓冲区,或为模块分配空间。
3、由于需要建立新的页表,所以它的开销要远远大于kmalloc及后面将要讲到的__get_free_pages()函数。且vmalloc()不能用在原子上下文中,因为它的内部实现使用了标志为 GFP_KERNEL 的kmalloc()。
/android/kernel/fusion/4.19/mm/vmalloc.c
void *valloc(unsigned long size)
--__vmalloc_node_flags(size, NUMA_NO_NODE, GFP_KERNEL)
----__vmalloc_node()
------__vmalloc_node_range()
--------__get_vm_area_node()
--------__vmalloc_area_node()
3、页分配和kmap
1、页分配内存接口,顾名思义,以页为单位进行分配,32位机中一页为4KB,64位机中,一页为8KB,但具体还有根据平台而定;
2、与kmalloc/vmalloc在虚拟空间分配内存的函数不同,alloc_pages()是在物理内存空间分配物理页框的函数,它既可以在内核空间分配,也可以在用户空间分配;
3、alloc_pages参数
1)入参order表示所分配页框的数目,该数目为2^order,order 允许的最大值是 10(即 1024 页)或者 11(即 2048 页),依赖于具体的硬件平台;
2)函数返回值为页框块的第一个页框page结构的地址,还需要使用函数page_address()获取页框的虚拟地址,__get_free_page就是alloc_pages的经典使用;
4、alloc_pages搭配kmap/kmap_atomic还可以利用高端内存的持久映射区和临时映射区;
5、alloc_page/alloc_pages //可以用于低端内存(默认优先)和高端内存
/android/kernel/fusion/4.19/include/linux/gfp.h
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define alloc_pages(gfp_mask, order) alloc_pages_node(numa_node_id(), gfp_mask, order)
struct page * alloc_pages_node(gfp_mask, order)
--__alloc_pages_node()
----__alloc_pages()
/android/kernel/fusion/4.19/mm/page_alloc.c
------__alloc_pages_nodemask()
--------prepare_alloc_pages()
--------get_page_from_freelist()
2、get_zeroed_page/__get_free_page/__get_free_pages //只用于低端内存
/android/kernel/fusion/4.19/mm/page_alloc.c
__get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order)
return (unsigned long) page_address(page);
}
页分配函数用于低端内存还是哪里?
1、alloc_page 都可以,使用标志来选择;
2、__get_free_pages内部使用~__GFP_HIGHMEM,限定了只能用于低端内存,即直接映射区;
3、kmap
/android/kernel/fusion/4.19/arch/arm/mm/highmem.c
void *kmap(struct page *page)
{
might_sleep();
if (!PageHighMem(page))
return page_address(page); //如果是低端内存走这里
return kmap_high(page); //如果是高端内存走这里
}
EXPORT_SYMBOL(kmap);
kmap_high()
--page_address()
----pas = page_slot(page)
----list_for_each_entry(pam, &pas->1h, list)
alloc_pages搭配kmap/kmap_atomic的使用
// 分配高端内存页面
struct page *high_page = alloc_pages(GFP_HIGHMEM, 0);
// 需要映射到内核地址空间才能访问
void *vaddr = kmap(high_page); // 映射到 vmalloc 区域或持久映射区
// 或者
void *vaddr = kmap_atomic(high_page); // 映射到临时映射区
当直接映射区充足时,还会用到高端内存中的持久映射区吗?
kmap_atomic 方法相较于kmap不会阻塞,它也禁止内核抢占
4、slab缓存
1、当在驱动程序中,遇到反复分配、释放同一大小的内存块时(例如,inode、task_struct等),建议使用内存池技术(对象在前后两次被使用时均分配在同一块内存或同一类内存空间,且保留了基本的数据结构,这大大提高了效率)。在linux中,有一个叫做slab分配器的内存池管理技术,内存池使用的内存区叫做后备高速缓存。
2、kmem_cache结构体
/android/kernel/fusion/4.19/mm/slab.h
struct kmem_cache {
unsigned int object_size;/* The original size of the object */
unsigned int size; /* The aligned/padded/added on size */
unsigned int align; /* Alignment as calculated */
slab_flags_t flags; /* Active flags on the slab */
unsigned int useroffset;/* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
const char *name; /* Slab name for sysfs */
int refcount; /* Use counter */
void (*ctor)(void *); /* Called on object slot creation */
struct list_head list; /* List of all slab caches on the system */
};
3、slab缓存
/android/kernel/fusion/4.19/mm/slab_common.c
struct kmem_cache *kmem_cache_create(name, size, align, flags, ...)
--kmem_cache_create_usercopy
----create_cache(name, size)
------kmem_cache_zalloc(kmem_cache, GFP_KERNEL)
/android/kernel/fusion/4.19/mm/slab.c
------__kmem_cache_create(s, flags)
/android/kernel/fusion/4.19/mm/slab.c
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
--slab_alloc(cachep, flags, ...)
----__do_cache_alloc(cachep, flags);
------____cache_alloc(cache, flags);
4、使用实例
/* 创建slab缓存 */
static struct kmem_cache *thread_info_cache;
thread_info_cache = kmem_cache_create("thread_info", sizeof(struct thread_info), \
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
/* 分配slab缓存 */
struct thread_info *ti;
ti = kmem_cache_alloc(thread_info_cache, GFP_KERNEL);
/* 使用slab缓存 */
...
/* 释放slab缓存 */
kmem_cache_free(thread_info_cache, ti);
kmem_cache_destroy(thread_info_cache);
5、mempool内存池
1、与slab缓存类似,在 Linux 内核中还包含对内存池的支持,内存池技术也是一种非常经典的用于分配大量小对象的后备缓存技术。
2、mempool
1)
/android/kernel/fusion/4.19/mm/mempool.c
mempool_create()
--mempool_create_node()
----kzalloc_node()
/android/kernel/fusion/4.19/include/linux/slab.h
------kmalloc_node()
--------__kmalloc_node()
/android/kernel/fusion/4.19/mm/slab.c
----------__kmalloc()
------------__do_kmalloc() //最终调用__kmalloc实现
----mempool_init_node()
2)mempool_alloc()
3) mempoll_free()
小结
1)内存分配接口如何对应到内核空间的虚拟内存?
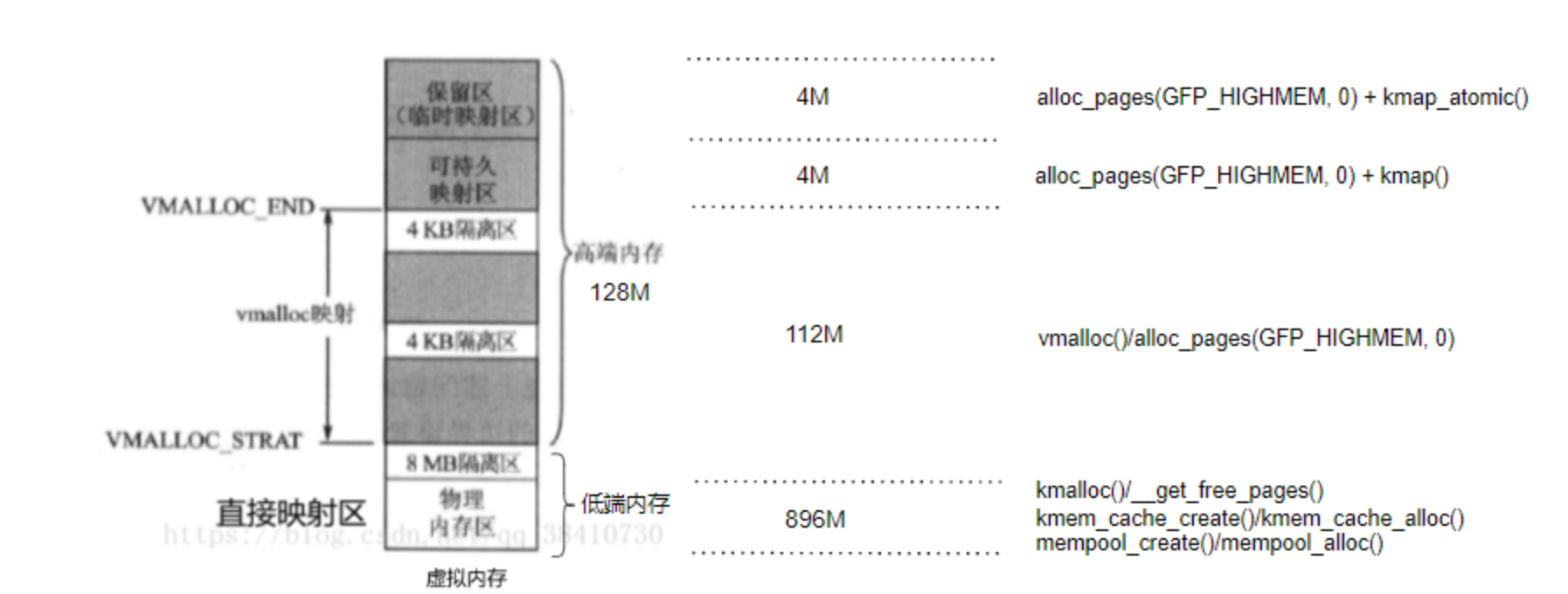
2)扩展:用户空间的内存分配
1、malloc() : 相当于内核空间的kmalloc()
2、mmap() : mmap一般用于用户程序分配内存,读写大文件,链接动态库,多进程内存共享等;

















 3839
3839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









