







k-means 算法:
在不带标签的多维数据集中寻找确定数量的簇。最优的聚类结果需要符合以 下两个假设。
• “簇中心点”(cluster center)是属于该簇的所有数据点坐标的算术平均值。
• 一个簇的每个点到该簇中心点的距离,比到其他簇中心点的距离短。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
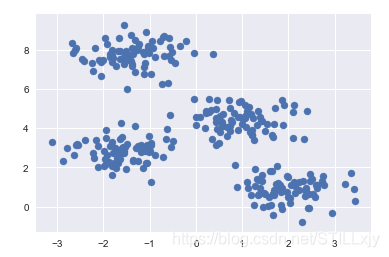
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
plt.scatter(X[:,0], X[:,1], s=50)
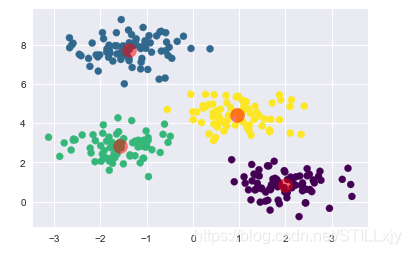
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:,0], X[:,1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:,0], centers[:,1], c='red', s=200, alpha=0.5)
k-means算法: 期望最大化
(1) 猜测一些簇中心点。
(2) 重复直至收敛。
a. 期望步骤(E-step):将点分配至离其最近的簇中心点。
b. 最大化步骤(M-step):将簇中心点设置为所有点坐标的平均值。
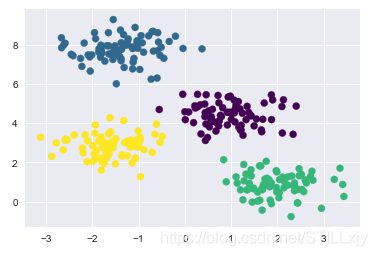
from sklearn.metrics import pairwise_distances_argmin
def find_clusters(X, n_clusters, rseed=2):
# 1.随机选择簇中心点
rng = np.random.RandomState(rseed)
i = rng.permutation(X.shape[0])[:n_clusters]
centers = X[i]
while True:
# 2a.基于最近的中心指定标签
labels = pairwise_distances_argmin(X, centers)
# 2b.根据点的平均值找到新的中心
new_centers = np.array([X[labels == i].mean(0)
for i in range(n_clusters)])
# 2c.确认收敛
if np.all(centers == new_centers):
break
centers = new_centers
return centers, labels
centers, labels = find_clusters(X, 4)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');
使用期望最大化算法时的注意事项
(1)可能不会达到全局最优结果:
最终的聚类结果,非常依赖于初始化时的选定的初试聚类中心。(优化:KMeans++算法)
(2)簇数量必须事先定好:
它无法从数据中自动学习到簇的数量,簇数量必须认为预先给定
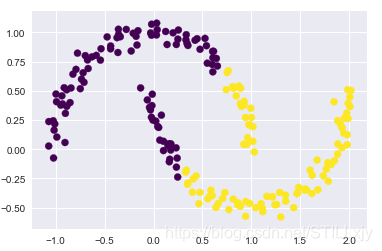
(3)k-means 算法只能确定线性聚类边界:
k-means 的基本模型假设(与其他簇的点相比,数据点更接近自己的簇中心点)表明, 当簇中心点呈现非线性的复杂形状时,该算法通常不起作用。
from sklearn.datasets import make_moons
X, y = make_moons(200, noise=.05, random_state=0)
labels = KMeans(2, random_state=0).fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=labels, s=50, cmap='viridis')
这个情形让人想起线性回归中的处理,当时我们通过一个核变换将数据投影到更高维的 空间,投影后的数据使线性分离成为可能。或许可以使用同样的技巧解决 k-means 算法 无法处理非线性边界的问题。
这种核 k-means 算法在 Scikit-Learn 的 SpectralClustering 评估器中实现,它使用最近 邻图(the graph of nearest neighbors)来计算数据的高维表示,然后用 k-means 算法分配 标签
from sklearn.cluster import SpectralClustering
model = SpectralClustering(n_clusters=2, affinity='nearest_neighbors', assign_labels='kmeans')
labels = model.fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=labels, s=50, cmap='viridis')
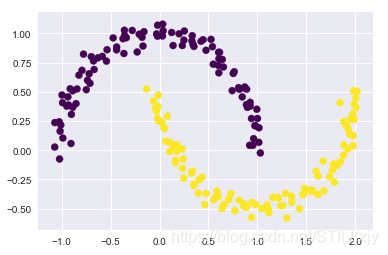
(4)当数据量较大时, k-means 会很慢:
由于 k-means 的每次迭代都必须获取数据集所有的点,因此随着数据量的增加,算法 会变得缓慢。你可能会想到将“每次迭代都必须使用所有数据点”这个条件放宽,例 如每一步仅使用数据集的一个子集来更新簇中心点。这恰恰就是批处理(batch-based) k-means 算法的核心思想,该算法在 sklearn.cluster.MiniBatchKMeans 中实现。
案例: 将k-means用于色彩压缩
聚类算法的一个有趣应用是图像色彩压缩。设想你有一幅包含几百万种颜色的图像,但 其实大多数图像中的很大一部分色彩通常是不会被眼睛注意到的,而且图像中的很多像素 都拥有类似或者相同的颜色。
from sklearn.datasets import load_sample_image
china = load_sample_image("china.jpg")
ax = plt.axes(xticks=[], yticks=[])
ax.imshow(china)

该图像存储在一个三维数组 (height, width, RGB) 中,以 0~255 的整数表示红 / 蓝 / 绿信息:
china.shape
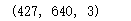
图片像素颜色由R,G,B三个数值组成。所以我们可以将一张图片看成三维(RGB)空间汇总的一群数据点。
先将数据变形为 [n_samples × n_features],然后缩放颜色至其取值为 0-1:
data = china / 255.0
data = data.reshape(427 * 640, 3)
data.shape
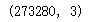
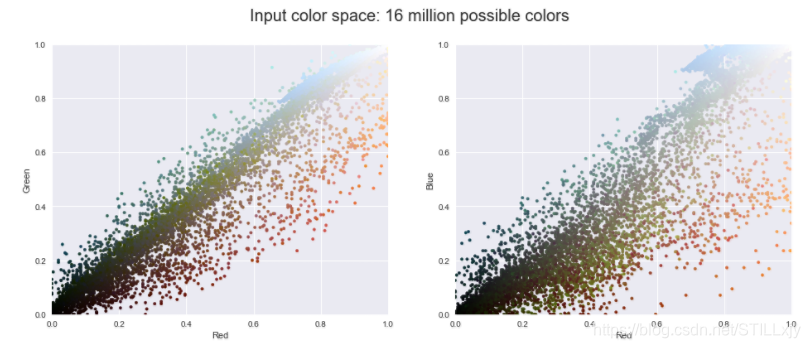
在颜色空间中对前 10 000 个像素的子集进行可视化。
def plot_pixels(data, title, colors=None, N=10000):
if colors is None:
colors = data
#随机选择一个子集
rng = np.random.RandomState(0)
i = rng.permutation(data.shape[0])[:N]
colors = colors[i]
R, G, B = data[i].T
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
ax[0].scatter(R, G, color=colors, marker='.')
ax[0].set(xlabel='Red', ylabel='Green', xlim=(0,1), ylim=(0,1))
ax[1].scatter(R, B, color=colors, marker='.')
ax[1].set(xlabel='Red', ylabel='Blue', xlim=(0,1), ylim=(0,1))
fig.suptitle(title, size=20)
plot_pixels(data, title='Input color space: 16 million possible colors')
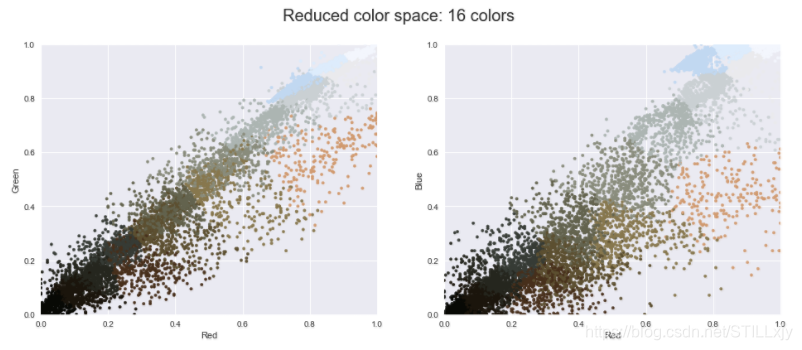
现在对像素空间(特征矩阵)使用 k-means 聚类,将 1600 万种颜色(255 × 255 × 255 = 16 581 375)缩减到 16 种颜色。因为我们处理的是一个非常大的数据集,所以将使用 MiniBatchKMeans 算法对数据集的子集进行计算。这种算法比标准的 k-means 算法速度更快
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(16)
kmeans.fit(data)
#每个像素,新的颜色为new_colors
new_colors = kmeans.cluster_centers_[kmeans.predict(data)]
plot_pixels(data, colors=new_colors, title='Reduced color space: 16 colors')
计算出每个像素的新的颜色后,调整数组尺寸后就可以显示重新着色后的图片了
china_recolored = new_colors.reshape(china.shape)
fig, ax = plt.subplots(1, 2, figsize=(16, 6), subplot_kw=dict(xticks=[], yticks=[]))
fig.subplots_adjust(wspace=0.05)
ax[0].imshow(china)
ax[0].set_title('original image: ', size=16)
ax[1].imshow(china_recolored)
ax[1].set_title('16-color image: ', size=16)
















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









