






~~~~~~~~~~~~~~~~~~You only look ONCE~~~~~~~~~~~~~~~~~~
什么是YoloV5
YOLOv5 是一种目标检测模型,是由Alexey Bochkovskiy 和 YOLOv5 开发团队开发的。YOLO 是 “You Only Look Once” 的缩写,是一种单阶段(single-stage)目标检测算法,它通过一次前向传播来直接预测图像中所有目标的位置和类别。
YOLOv5 具有较高的检测速度和较好的检测性能,广泛应用于各种计算机视觉任务,如物体检测、行人检测、交通标志识别等。YOLOv5 提供了不同大小的预训练模型,以满足不同场景和硬件条件下的需求,用户可以根据自己的需求选择合适的模型进行训练和部署。
原理
YOLOv5 是一种单阶段目标检测模型,采用 CSPDarknet53 主干网络提取图像特征,结合特征金字塔网络获取多尺度特征信息,并通过无锚检测机制直接预测目标位置和类别,最后经过后处理步骤提高检测结果的准确性和稳定性,实现了高效、精确的目标检测,在各种计算机视觉任务中广泛应用。
结构
YOLOv5 的整体结构可以分为以下几个部分:
- Backbone Network: CSPDarknet53 是 YOLOv5 的骨干网络,用于提取输入图像的特征。
- Feature Pyramid Network (FPN): 在骨干网络之后,YOLOv5 使用 FPN 提取多尺度的特征图。
- Detection Head: YOLOv5 的检测头包括多个检测层,用于预测目标的位置和类别。这些检测层与不同尺度的特征图相连。
- Anchor-Free Detection: YOLOv5 不再依赖锚框,而是直接预测目标的位置和边界框。
- Post-processing: 检测后处理阶段用于过滤预测框、解码预测结果,并应用非极大值抑制(NMS)来提高检测结果的准确性。
实战前的准备
配置好Git
这是基本功就不必赘述了,在此基础之上转到YOLOv5的源码仓库:
https://github.com/ultralytics/yolov5
配置好Torch
torch简直太好用有没有,现在你还听说谁还在用复杂又麻烦的==TensorFlow==
没GPU的直接选择CPU Only

注意
使用Nvidia GPU需要提前配置好CUDA环境
让Yolo跑起来
完成上述准备后,直接把源码clone到本地
我这里用VSCode进行接下来的演示,当然也可以用Pycharm或者其他环境
使用虚拟环境的注意提前切环境哦
安装依赖
一个优秀的项目要想能够一键运行
requirements.txt必不可少
命令行输入:
pip install requirements.txt
就可以安装好所依赖的三方库
运行自带模型
Yolov5已经预训练了几个模型,主要包括
- yolov5s.pt
- yolov5m.pt
- yolov5l.pt
根据命名就可以猜到大概模型结构是逐渐变大变复杂的~
Run detect.py
在文件目录中找到detect.py
RUN!
yolov5默认检测的目标数据来自于coco128
此时有些小伙伴可能会卡住,因为系统会从遥远的地方
科学的传输所需要的模型权重文件
不会魔法的小伙伴留言私信~

效果图
Tips
运行时的一些参数含义:
–weights yolov5s.pt 指定检测模型
–source root/images 指定检测源,可以是单个图像文件,也可以是视频,摄像头
检测自己想要的目标
数据集准备
OK,那么现在how to find 哆啦A梦 in a picture???
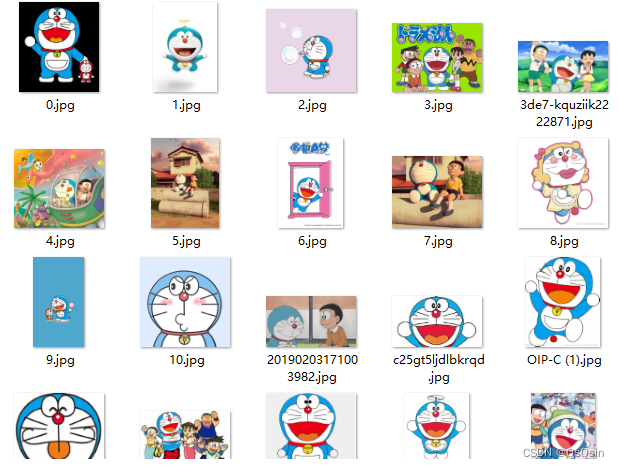
No.1 数据准备
到网上下载相关图片,这里可以使用spider加速
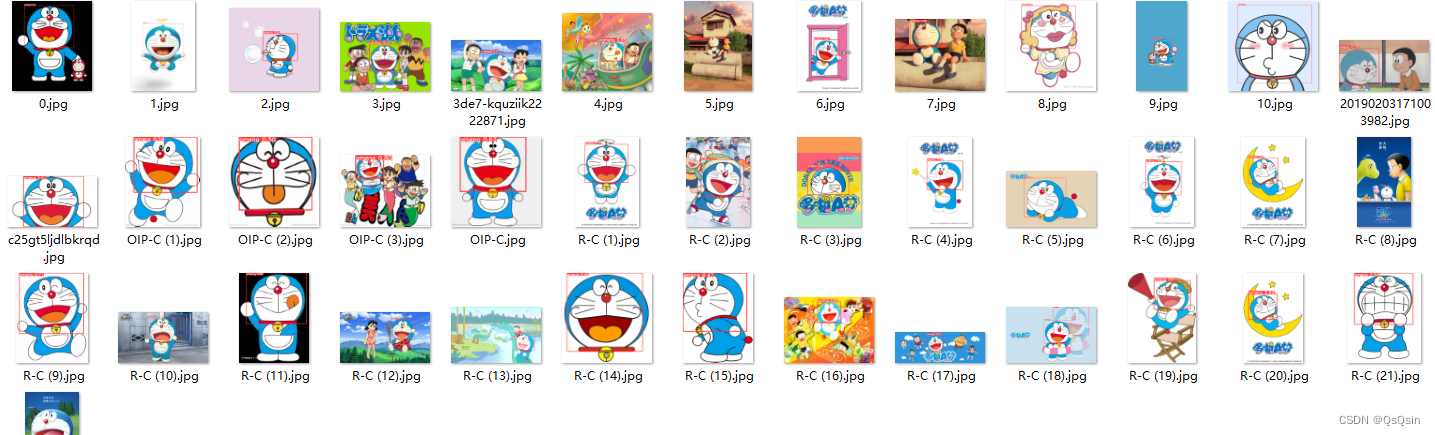
No.2 数据标注
使用labelimg对待检测目标进行标注
注意
这里需要安装相关依赖
pip install pyqt5
pip install lxml
pip install labelimg
模型训练
使用预训练模型对标注好的数据进行训练
python train.py --weights yolov5m.pt --data mydata/A.yaml
--workers 2 --batch-size 5 --epochs 100
效果展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









