









论文要点
这篇文章应该是第一篇使用Transformer取得比较好效果的论文,分析了Transformer的特性,同时提出两种改进:
- 原本position embedding只体现了距离,但没有方向性,NER中方向性是非常重要的,故而使用相对距离的方法表示

- 【基于直觉】对于NER任务,可能几个上下文关键词就可以帮助判断,故而应该增强这些关键词的作用,而原始Transformer会有scale过程削弱这些词作用,故而使用un-scaled、sharp的Attention,增强稀疏性
模型框架:
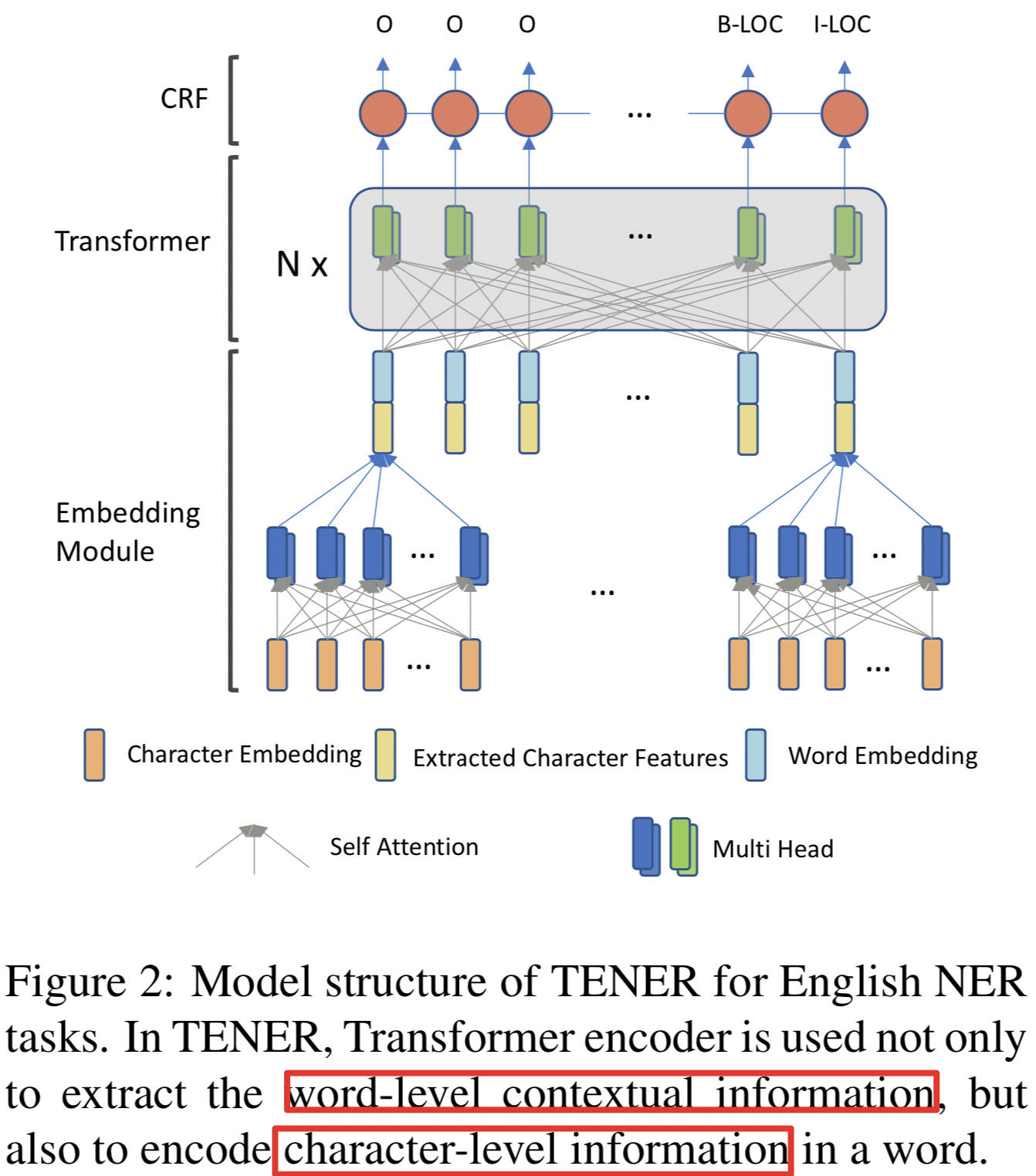
- emb由两部分组成,char_emb经过Self-Attention,然后与word emb拼接到一起
- 拼接结果再经过多层Transformer,然后CRF预测
- Transformer改进:
- position emb改进:
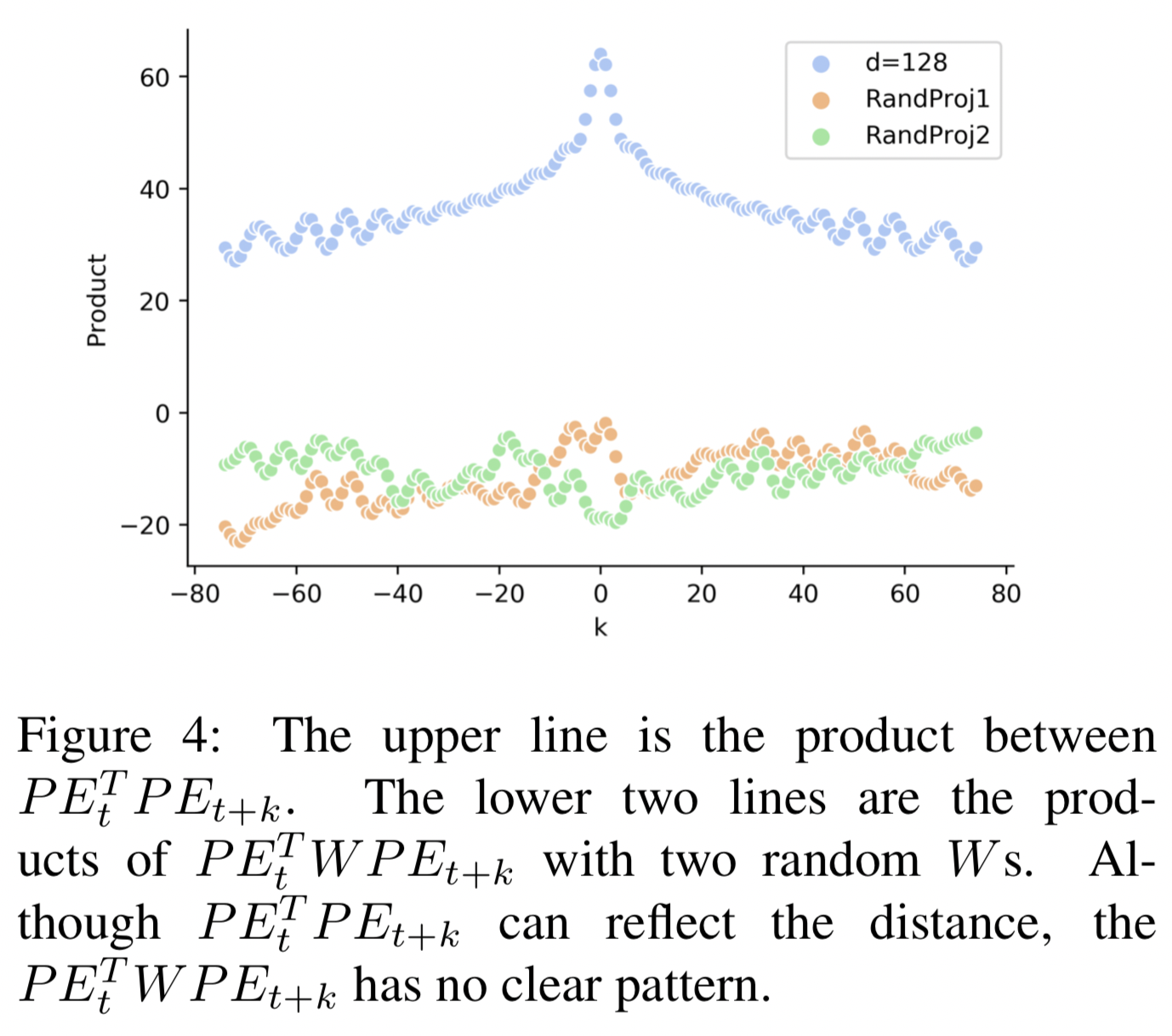
- 原公式中,若以Q·K计算,pos emb部分计算结果只与绝对距离有关,而以QWK计算,则没什么直观意义:
- position emb改进:
改进该部分公式为:
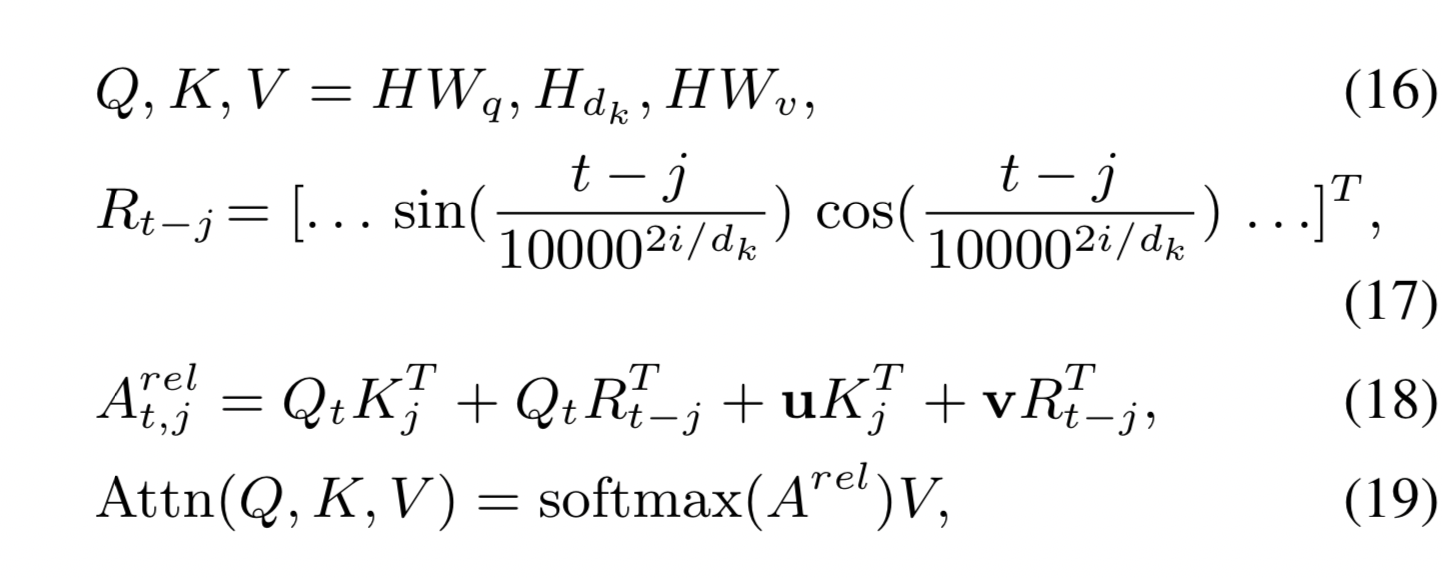
其中:R_{t-j}直接计算了两个token相对距离关系,t-j 是相对距离存正负,cos(-x) = cos(x)捕捉绝对距离关系,sin(-x) = -sin(x)捕捉方向性

- 原始Transformer公式中,会在Softmax时作一个缩放,但这篇论文表明,没有这个缩放效果会更好
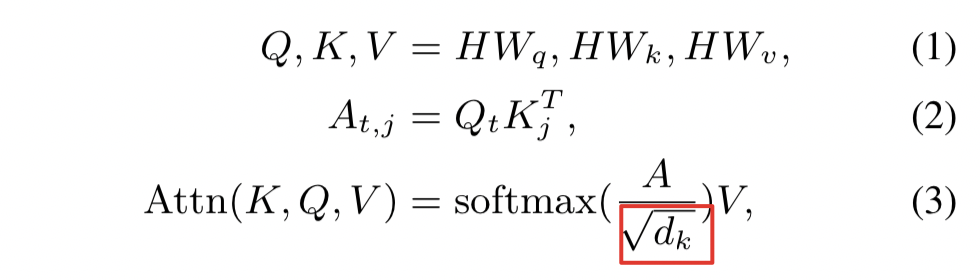
模型效果:
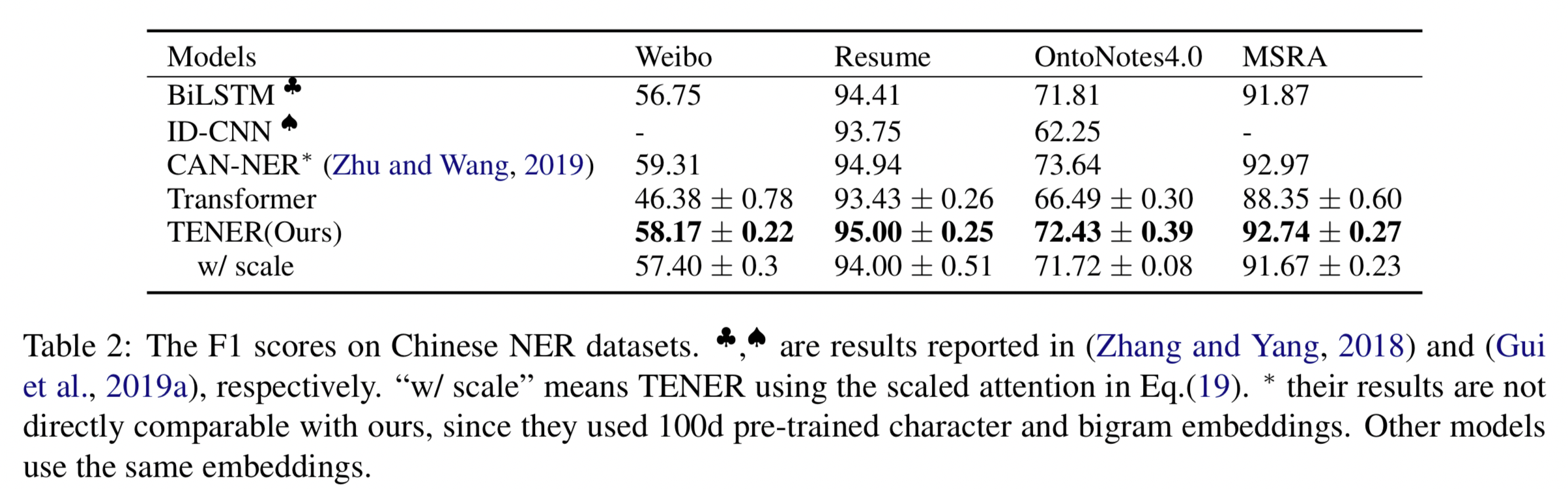
模型缺点:
- 模型输入为char+word的形式,需要分词、word_emb,词部分存OOV
- QV 方向















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









