






注:本文中提到的ICE为一Android工程,对应Linux内核版本为2.6.29。
为了合理快速的获取内存,Linux分多层管理结构以适应不同架构及不同的使用方式。图2-1描述了内存管理的架构(注意一个系统中并不一定是2个node,一般情况下UMA只使用1个node,而NUMA最多使用8个或16个)。
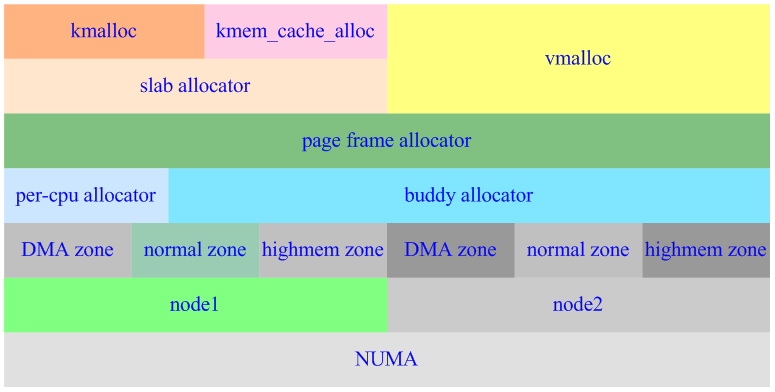
图2-1:内存管理架构
下面将依据此图由底向上依次介绍各功能块的作用。
2.1 节点描述符(node)
NUMA(Non-Uniform Memory Access)即非一致内存访问。在多CPU系统中有可能出现给定CPU对不同内存单元访问的时间不同。为了让指定CPU总能最先使用访问时间最短的内存,Linux把物理内存分成几块并以节点(node)标识。这样一来,每个CPU都有最快访问内存的节点,但并不等于只能访问这个节点。下表中node_zonelists将其他节点的各管理区也链了进来,但均排在本节点管理区之后,以示其它节点优先级低于本节点。
在ARM体系下不会出现这种情况,但为了统一代码,Linux仍然使用这种管理方式,只是所有内存都归一个节点管理,比如都在上图的node1中。
内核中用struct pglist_data结构体来存放节点信息,各成员解释如下:
| 类型 | 名字 | 说明 |
| struct zone [] | node_zones | 节点中管理区描述符的数组,参考下一节 |
| struct zonelist [] | node_zonelists | zone表,页分配器获取内存的入口 |
| int | nr_zones | 节点中管理区的个数 |
| struct page * | node_mem_map | 节点中页描述符数组 |
| struct bootmem_data * | bdata | 内核初始化阶段内存管理入口 |
| unsigned long | node_start_pfn | 节点中第一个叶框下标 |
| unsigned long | node_present_pages | 属于本节点的内存的页框数(不包括洞) |
| unsigned long | node_spanned_pages | 属于本节点的内存的页框数(包括洞) |
| int | node_id | 节点标识符 |
| wait_queue_head_t | kswapd_wait | kswapd页换出守护进程使用的等待队列 |
| struct task_struct * | kswapd | 指针指向kswapd内核线程的进程描述符 |
| int | kswapd_max_order | kswapd将要创建空闲块大小取对数的值 |
表2-1:节点描述符
2.2 管理区描述符(zone)
出于各种原因,Linux把每个节点内的内存划分成下面三个管理区:
ZONE_DMA
有些体系的DMA总线只能访问内存的前16M,因此将内存的前16M分出,优先给直接内存访问使用。在ARM体系中不存在这种情况,所以也没有DMA管理区。
ZONE_HIGHMEM
如果内存足够大(比如用户:内核线性空间=3:1,内核就只能访问线性空间的第4GB内容,如果物理内存超过1GB则视为足够大),内核线性空间无法同时映射所有内存。这就需要将内核线性空间分出一段不直接映射物理内存,而是作为窗口分时映射使用到的未映射的内存。在ICE平台上用户:内核线性空间是2:2,即用户和内核均拥有2G的线性空间,而物理内存只有464M给Linux使用,所以无需高端内存管理区。
ZONE_NORMAL
除去上面两个区的内存,剩下的放到ZONE_NORMAL区中。在ICE平台上,所有内存都在该区。
内核用struct zone来管理内存区,各成员解释如下:
| 类型 | 名字 | 说明 |
| unsigned long | pages_min | 管理区中保留页的数目 |
| unsigned long | pages_low | 回收页框时使用的下界,同时也被管理区分配器作为阈值使用 |
| unsigned long | pages_high | 回收页框时使用的上界,同时也被管理区分配器作为阈值使用 |
| unsigned long [] | lowmem_reserve | 指明在处理内存不足的临界情况下管理区必须保留的页框数 |
| struct per_cpu_pageset [] | pageset | 用于实现单一页框的特殊高速缓存 |
| spinlock_t | lock | 保护该描述符的自旋锁 |
| struct free_area [] | free_area | 标识出管理区中的空闲页框 |
| spinlock_t | lru_lock | 活动以及非活动链表使用的自旋锁 |
| struct lru [] | lru | 活动以及非活动链表 |
| unsigned long | flags | 管理区标志 |
| atomic_long_t [] | vm_stat | 管理区内各类型内存统计 |
| int | prev_priority | 管理区优先级,由回收页框算法使用 |
| wait_queue_head_t * | wait_table | 进程等待队列的散列表,这些进程正在等待管理区中的某项。 |
| unsigned long | wait_table_bits | 等待队列散列表数组大小,置位2的order幂 |
| struct pglist_data * | zone_pgdat | 包含该管理区的节点指针 |
| unsigned long | zone_start_pfn | 管理区的起始页框号 |
| unsigned long | spanned_pages | 管理区的页框数,包括洞 |
| unsigned long | present_pages | 管理区的页框数,不包括洞 |
| const char * | name | 指向管理区名字,一般为"DMA" "Normal" "HighMem" |
表2-2:管理区描述符
2.3 页描述符(page)
内核必须记录每个页框当前的状态。例如,内核必须能区分哪些页框包含的是属于进程的页,而哪些页框包含的是内核代码或内核数据。类似地,内核还必须能够确定动态内存中的页框是否空闲。如果动态内存中的页框不包含有用的数据,那么这个页框就是空闲的。在以下情况下页框是不空闲的:包含用户态进程的数据、某个软件高速缓存的数据、动态分配的内核数据结构、设备驱动程序缓冲的数据、内核模块的代码等等。
页框的状态信息保存在一个类型为page的页描述符中,其中的字段如下表所示。所有的页描述符存放在mem_map数组中。因为每个描述符长度为32字节,所以mem_map所需要的空间略小于整个内存的1%。virt_to_page(addr)宏产生线性地址addr对应的页描述符地址。pfn_to_page(pfn)宏产生与页框号pfn对应的页描述符地址。
页描述符,在内核中表示为struct page:
| 类型 | 名字 | 说明 |
| unsigned long | flags | 页标志,包括所在的节点及管理区编号(高位上) |
| atomic_t | _count | 页框的引用计数器 |
| atomic_t | _mapcount | 页框中的页表项数目,如果没有则为-1 |
| unsigned long | private | 可用于正在使用页的内核成分(例如,在缓冲页的情况下它是一个缓冲器头指针)。如果页是空闲的,则该字段由伙伴系统使用(存放order值) |
| struct address_space * | mapping | 当页被插入页高速缓存中时使用,或者当页属于匿名区时使用 |
| pgoff_t | index | 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像或匿名区中标识存放在页框中的数据的位置,或者它存放一个换出页标识符 |
| struct list_head | lru | 包含页的最近最少使用(LRU)双向链表的指针 |
表2-3:页描述符
下面这两个字段非常重要,需作重点描述:
_count
页的引用计数器。如果该字段为-1,则相应页框空闲,并可被分配给任一进程或内核本身;如果该字段的值大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放一些内核数据结构。page_count()函数返回_count加1后的值,也就是该页的使用者的数目。
flags
包含多达32个用来描述页框状态的标志,如下表。对于每个PG_xyz标志,内核都定义了操作其值的一些宏。通常,PageXyz宏返回标志的值,而SetPageXyz和ClearPageXyz宏分别设置和清除相应的位。页标志32位分布如下:
Page flags: | [SECTION] | [NODE] | ZONE | ... | FLAGS |
| 标志名 | 含义 |
| PG_locked | 页被锁定。例如,在磁盘I/O操作中涉及的页 |
| PG_error | 在传输页时发生I/O错误 |
| PG_referenced | 刚刚访问过的页 |
| PG_uptodate | 在完成读操作后置位,除非发生磁盘I/O错误 |
| PG_dirty | 页已经被修改 |
| PG_lru | 页在活动或非活动页链表中 |
| PG_active | 页在活动页链表中 |
| PG_slab | 包含在slab中的页框 |
| PG_highmem | 页框属于ZONE_HIGHMEM管理区 |
| PG_checked | 由一些文件系统(如Ext3)使用的标志 |
| PG_reserved | 页框留给内核代码或没有使用 |
| PG_private | 页描述符的private字段存放了有意义的数据 |
| PG_writeback | 正在使用writepage方法将页写到磁盘上 |
| PG_nosave | 系统挂起/唤醒时使用 |
| PG_compound | 通过扩展分页机制处理页框 |
| PG_swapcache | 页属于对换高速缓存 |
| PG_mappedtodisk | 页框中的所有数据对应于磁盘上分配的块 |
| PG_reclaim | 为回收内存对页已经做了写入磁盘的标记 |
| PG_nosave_free | 系统挂起/恢复时使用 |
表2-4:页标志
2.4 伙伴系统算法
伙伴系统(buddy system)算法及下节要讲的slab分配器是Linux内存分配的两大核心算法。它们的目的都是提高内存分配效率的同时降低内存碎片。
其实解决内存碎片有两种办法:
I 将不连续的内存页映射到连续的线性地址区间;
II 将大内存分成各种固定大小的块,每次分配时,尽量使用最接近申请大小的那一块,尽量避免为满足小块内存的申请而分拆大的块。
办法I即是vmalloc的思想,但有时后要求申请到内存必须是连续,这就需要方法II。其实方法I还有一个缺点:它需要修改页表,需要硬件的频繁动作,这增加了内存申请和使用的时间。因此多数情况都采用方法II来申请内存。伙伴系统算法即是方法II的一个使用算法。
伙伴系统特征如下:
I 把所有的空闲页框分组为MAX_ORDER(ICE为11)个块链表,每个块链表分别包含大小为2n(n为0~10的整数)个连续的页框,即1、2、4、6、8、16、32、64、128、256、512和1024个连续的页框。
II 每个块的第一个页框的物理地址是该块大小的整数倍。
下图显示了伙伴系统内存组织图,对应着管理区结构中的free_area数组,它们通过页描述符中的list_head链在一起。页描述符首地址放在节点结构的node_mem_map,也可通过全局变量mem_map访问。free_area结构中还有一个nr_free字段,表示各个链表中空闲块的数目。
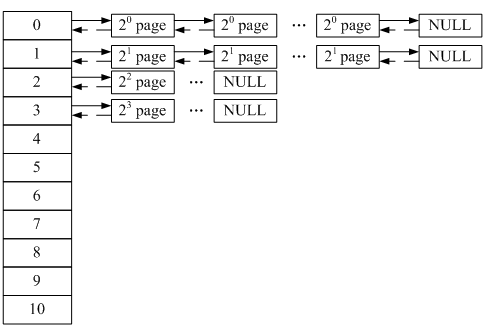
图2-2:伙伴系统内存组织图
只以这两个特性不足以表现伙伴系统的强大。它的卓越点在动态管理上。比如要申请一页内存,但0链表中的块已经全部用完了。一般系统通常的做法是到1链表中找一个块给申请者。这无疑浪费了一页的内存。伙伴系统的做法是将这个块分成两个一页的块,一块给申请者,另一块插到0链表中。同样,如果1链表中的块也用完了,就会到2链表中找,找到后会将该块分成三块:两个一页的块和一个两页的块。一个一页的块给申请者,另一个插入到0链表,两页的块插入到1链表。依此类推,直到查到10链表,仍然没有空闲块,才会返回出错。
同样原理用在释放内存上。假设有一页的块要释放,伙伴系统会把它插入到0链表的相应位置,同时查看与前后块是否为伙伴(地址是否连续,如连续再查看排在前面的块的地址是否是两页的整数倍)。如果是,则将这两块合并成一个两页的块插入到1链表的相应位置,然后再查看与前后块是否是伙伴,依此递归,直到已不是伙伴或到10链表。
伙伴系统用__rmqueue()函数实现对空闲块的分配,它的行为远远比上面分析的复杂。它主要通过两个函数来实现:__rmqueue_smallest()和__rmqueue_fallback()。上面描述的其实只是__rmqueue_smallest()的行为,当__rmqueue_smallest()获取不到块时,会继续执行__rmqueue_fallback()来拆分大的块。这就有个疑问了,不是说获取不到块了吗?又哪来的大块?事实上图2-2并没有把细节画出来,把它再放大,如下图:
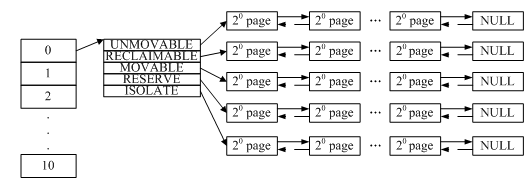
图2-3:zone的free_area分解
事实上11个块链表中的每一个又分成了五种类型的块表,每个表中包含了n个块。我们使用__rmqueue()函数申请块时要指定块的类型,当__rmqueue_smallest()从指定的类型块中找不到块,将会执行__rmqueue_fallback()从其他类型块表中借块来使用,这些都是细节的东西,也比较复杂,不再细述。
释放申请的块的函数是free_pages_bulk()。它是__rmqueue()的逆过程,不再分析。
2.5 页框分配器
页框分配器核心函数是__alloc_pages_internal()它主要调用的函数是__rmqueue()。简单的说页框分配器是对伙伴系统的一种封装。我们常用的页框分配函数又是对__alloc_pages_internal()的封装,如:alloc_pages_node()。alloc_pages_node()返回给调用者的是页框描述符。下面slab分配器使用的kmem_getpages()仅是将alloc_pages_node()返回的页框描述符转换成了线性地址。















 8782
8782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









