







 文章介绍了一种名为DepthAnything的方法,利用大规模无标注数据和数据增强技术,通过构建挑战性优化目标和引入语义辅助感知,提升模型的特征鲁棒性和泛化能力。实验表明,这种方法在度量深度估计和语义分割任务上优于现有SOTA模型。
文章介绍了一种名为DepthAnything的方法,利用大规模无标注数据和数据增强技术,通过构建挑战性优化目标和引入语义辅助感知,提升模型的特征鲁棒性和泛化能力。实验表明,这种方法在度量深度估计和语义分割任务上优于现有SOTA模型。
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
主要贡献:
- 数据集维度:一种数据引擎用于数据收集与自动标注,构建了~62M的大规模无标注数据据,极大程度提升了数据覆盖率、降低泛化误差
- 数据增强(强色彩失真,颜色失真、高斯模糊;强空域畸变,CutMix)构建更具挑战性的优化目标,促使模型主动探索额外的视觉知识,进而提升特征鲁棒性
- 一种辅助监督信息,迫使模型从预训练Encoder中继承丰富语义先验信息
Methods
Learning Labeled Images
采用MiDas的训练方式,从6个公共数据集中收集150万张标记图像来训练初始MDE模型。使用仿射不变损失来同时训练多个数据集:
L
l
=
1
H
W
∑
i
=
1
H
W
ρ
(
d
i
∗
,
d
i
)
\mathcal{L}_{l}=\frac{1}{H W} \sum_{i=1}^{H W} \rho\left(d_{i}^{*}, d_{i}\right)
Ll=HW1i=1∑HWρ(di∗,di)
其中
ρ
(
)
\rho()
ρ()表示仿射不变平均绝对误差损失,先将原深度和预测深度平移放缩到均值为0和单位比例,然后计算误差。
为了获得更强的教师模型,使用语义分割领域的DINOv2预训练权重初始化编码器,并使用预训练的语义分割模型识别天空区域且将天空区域视差值设为0.
Unleashing the Power of Unlabeled Images
使用教师模型为无标签数据集 D u \mathcal{D}^u Du分配伪标签,然后使用有标签数据集和无标签数据集的并集 D l ∪ D u \mathcal{D}^l \cup \mathcal{D}^u Dl∪Du训练学生模型。
注意:不是在教师模型 T T T上微调,而是从头开始训练学生模型 S S S,这样可以获得更好的表现。
单纯这样做,没有提高模型性能。这可能是因为在已经具有足够多的标记图像时,从额外的未标记图像中获得的额外知识是很有限的。特别是考虑到教师和学生共享相同的预训练和架构,即使没有明确的自训练过程,他们也倾向于对未标记的集 D u \mathcal{D}^u Du 做出类似的正确或错误预测。
为了迫使学生模型在 D u \mathcal{D}^u Du上学习到额外的视觉知识,作者给学生模型设置了更难的优化目标。在训练期间,给 D u \mathcal{D}^u Du注入强烈的扰动。一种是强烈的颜色扭曲,包括颜色抖动和高斯模糊;另一种是强烈的空间扭曲,即CutMix。
CutMix,在一张图像上抠出一个矩形区域,覆盖到另一张图像上。公式中的
M
M
M表示一个矩形区域,
u
a
b
=
u
a
⊙
M
+
u
b
⊙
(
1
−
M
)
u_{a b}=u_{a} \odot M+u_{b} \odot(1-M)
uab=ua⊙M+ub⊙(1−M)。
L
u
M
=
ρ
(
S
(
u
a
b
)
⊙
M
,
T
(
u
a
)
⊙
M
)
,
L
u
1
−
M
=
ρ
(
S
(
u
a
b
)
⊙
(
1
−
M
)
,
T
(
u
b
)
⊙
(
1
−
M
)
)
,
L
u
=
∑
M
H
W
L
u
M
+
∑
(
1
−
M
)
H
W
L
u
1
−
M
\begin{array}{l} \mathcal{L}_{u}^{M}=\rho\left(S\left(u_{a b}\right) \odot M, T\left(u_{a}\right) \odot M\right), \\ \mathcal{L}_{u}^{1-M}=\rho\left(S\left(u_{a b}\right) \odot(1-M), T\left(u_{b}\right) \odot(1-M)\right), \\ \mathcal{L}_{u}=\frac{\sum M}{H W} \mathcal{L}_{u}^{M}+\frac{\sum(1-M)}{H W} \mathcal{L}_{u}^{1-M} \end{array}
LuM=ρ(S(uab)⊙M,T(ua)⊙M),Lu1−M=ρ(S(uab)⊙(1−M),T(ub)⊙(1−M)),Lu=HW∑MLuM+HW∑(1−M)Lu1−M
Semantic-Assisted Perception
以往有工作引入辅助的语义分割任务提高深度估计的准确性。本文也认为语义相关的高级信息对深度估计有益,同时语义分割辅助监督信号也有助于对抗无标记集伪标签的潜在噪声。
最初的尝试:联合训练阶段,深度估计模型和语义分割模型共享Encoder,使用各自的Decoder。这种方法没有提升最初MDE模型的性能。本文猜测,将一张图片解码为离散的类别空间会损失过多的信息,剩下的有限信息很难再对深度估计任务有提升。
采用特征对齐的方法获得更加丰富且连续的语义信息。特征对齐损失(Feature Alignment Loss)的形式为:
L
feat
=
1
−
1
H
W
∑
i
=
1
H
W
cos
(
f
i
,
f
i
′
)
\mathcal{L}_{\text {feat }}=1-\frac{1}{H W} \sum_{i=1}^{H W} \cos \left(f_{i}, f_{i}^{\prime}\right)
Lfeat =1−HW1i=1∑HWcos(fi,fi′)
其中,
f
i
f_i
fi是学生深度模型S提取的特征,
f
i
′
f_i^{'}
fi′是冻结的DINOv2 encoder提取的特征。
一个关键点:语义分割任务要求同一物体的不同部分应该有相同的特征,对深度估计而言他们可能有不同的深度。所以不能强制深度模型产生与冻结编码完全相同的特征。本文设计了一个公差冗余度 α \alpha α,当余弦相似度超过 α \alpha α时, L feat \mathcal{L}_{\text {feat }} Lfeat 将不会考虑该像素。
Ablation Studies
不同数据集的泛化能力
在一个数据集上训练相对的深度模型,在六个未见过的数据集上进行评估,以此比较不同数据集训练对模型泛化能力的影响。
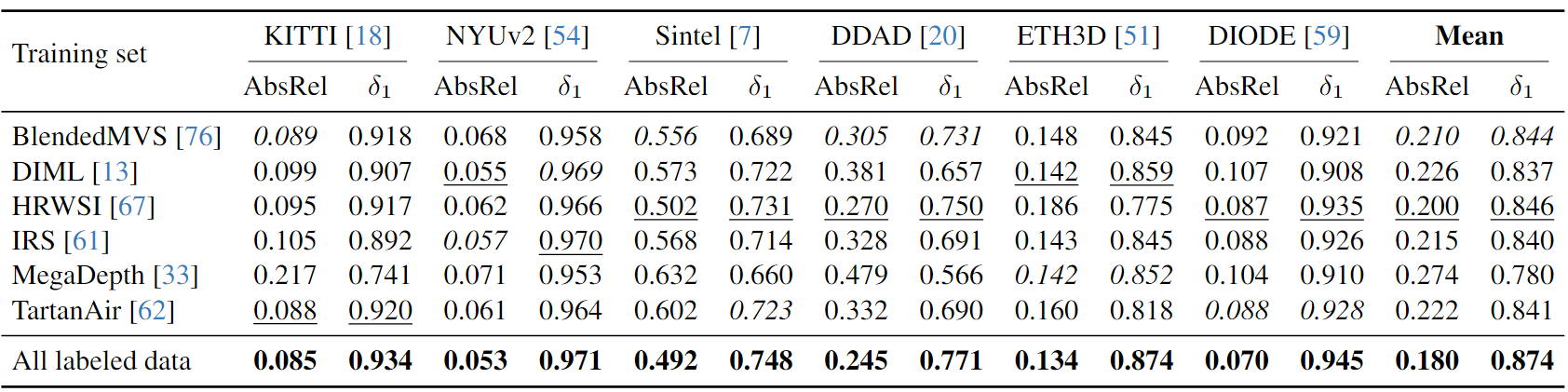
HRWSI虽然只有20K的图像,但是它提供了最强的模型泛化能力,这说明了数据集中数据的多样性对模型泛化能力的重要性。
联合训练时扰动 D u \mathcal{D}^u Du 和 语义特征约束
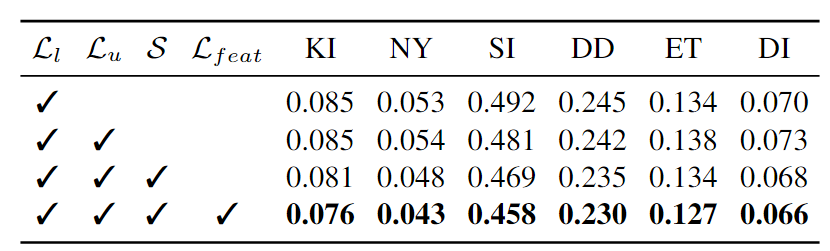
如果不添加扰动S,单纯使用无标签数据参与训练(
L
u
\mathcal{L}_u
Lu)不会对模型性能有提升。但是增加扰动S和语义特征约束(
L
f
e
a
t
\mathcal{L}_{feat}
Lfeat)均对模型性能有显著提升。此外,语义特征约束可以使编码器能够作为中高级感知的多任务视觉系统的关键组件。
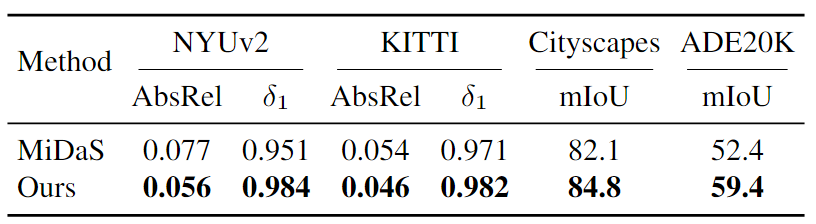
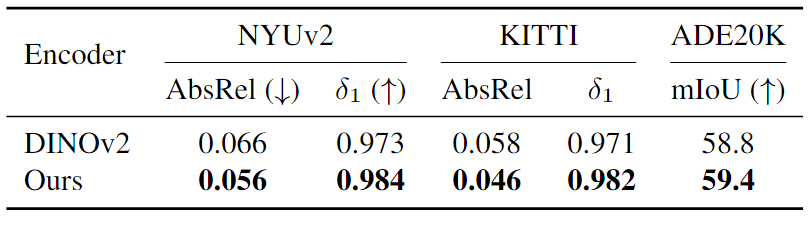
编码器在下游应用中的性能
比较编码器在下游度量深度估计任务和语义分割任务的性能。将Depth Anything分别与MiDaS和DINOv2进行比较。MiDaS是在多个有标签的数据集上训练的相对深度估计模型,是Depth Anything之前的SOTA;DINOv2是语义分割领域的SOTA,Depth Anything使用DINOv2的编码器参数进行初始化,并与之计算语义特征对齐损失。
结果发现,Depth Anything在度量深度估计和语义分割任务上的表现均优于MiDaS和DINOv2。















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









