









关键词:学生举手红点, 老师忽略消息去红点,允许学生发言去红点
一、一对多
1.1 学生举手提问
新的需求是右边的符号去掉,换成文字“忽略”,但符号一直去不掉,等前端来了请教一下吧。
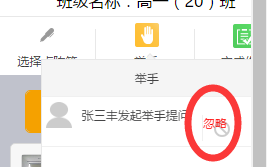
1)学生举手红点
开发完成,代码如下:
a.)新技术
这个替换图片是用位置替换,就是说所有的图标在一张图上,只是位置不同,如下:

b.)开始时,举手图标如下:
当学生举手时,把图片的位置变一下,加上红点,如下:
//学生举手提问老师端动态追加提示消息+并且举手图片换成加红点的
if(event.data.mobileName && event.data.raiHand){
var mobName = event.data.mobileName;
RHVA_id = event.data.video_Id;
raiHandId = 'VA'+RHVA_id;
$("#raHanQue").append("<li id = '" +raiHandId+"'class='clearfix'><img src='/static/img/end_s.png'οnclick='openSgVA(RHVA_id)' /><span>"+mobName+"发起举手提问</span><astyle='color:red;' οnclick='removeRH(raiHandId)'>忽略</a></li>");
$("li#hand").find("span").css("background-position","38px -159px");
}
注:上述标红代码,就是用改变位置的方法,把图片换成加红点的,有个小技巧是:可以在html中通过移动上下键来改变位置,进行定位。


注:这是在不连接学生端的情况下进行的。学生举手后,图标如下:
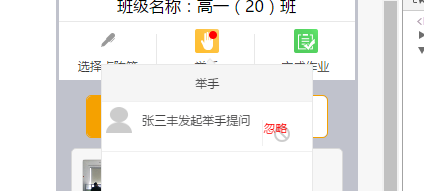
c.)当老师让学生发言或忽略消息后,红点消失,代码如下:
老师忽略消息更换红点图片:
//移除举手标签+去掉图片举手红点
function removeRH(id){
$("#"+id).remove();
$("li#hand").find("span").css("background-position","38px -116px");
}
老师让学生发言更换红点图片:
//学生举手提问老师端动态追加提示消息+并且举手图片换成加红点的
if(event.data.mobileName&& event.data.raiHand){
var mobName =event.data.mobileName;
RHVA_id =event.data.video_Id;
raiHandId ='VA'+RHVA_id;
$("#raHanQue").append("<li id = '" +raiHandId+"'class='clearfix'><img src='/static/img/end_s.png' οnclick='opnVAred(RHVA_id)'/><span>"+mobName+"发起举手提问</span><astyle='color:red;' οnclick='removeRH(raiHandId)'>忽略</a></li>");
$("li#hand").find("span").css("background-position","38px -159px");
}
opnVAred函数如下:
//打开单个学生的音视频+把红点举手图片替换成没红点的----------------------3.2.3
function opnVAred(stuIdVA){
connection.send({
action:"unsilent",
uid:stuIdVA
});
$("li#hand").find("span").css("background-position","38px -116px");
}
注:不能再用那个打开声音的了,并且这个不需要移除由点视频头像打开的框。

2017年4月1日星期六















 8027
8027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









