







之前在考研,没有回复csdn,sorry啦,如何还有需要数据集的话,私聊就行,之前大家需要的昆虫数据集可以用类似的方爬取就行。
代码
可以爬取多页
#https://pic.netbian.com/4kmeinv/
#爬取图片
import requests
from bs4 import BeautifulSoup
def craw_html(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.status_code)
response.encoding = response.apparent_encoding
response = response.text
soup = BeautifulSoup(response, 'html.parser')
# tables = soup.find_all('ul', {'class': "clearfix"})
tables=soup.find_all('img')
print(tables)
count=0
for table in tables:
name=table['alt']
# print(table['alt']+','+table['src'])
pic_src='https://pic.netbian.com'+table['src']
dirs='E:/爬虫data/practice/pics/'+name + '.jpg'
with open(dirs, 'wb') as f:
f.write(requests.get(pic_src).content)
print(name+'+'+'保存成功')
count=count+1
print("成功爬取{}张图片".format(count))
except:
print("爬取失败")
def all_index():
#https://pic.netbian.com/4kmeinv/index_2.html
#https://pic.netbian.com/4kmeinv/index_3.html
index=int(input("共63页,请问要爬取多少页"))
url = 'https://pic.netbian.com/4kmeinv/'
craw_html(url)
for i in range(2,3+index):
url='https://pic.netbian.com/4kmeinv/'+'index_{}.html'.format(index)
craw_html(url)
print("总共成功爬取{}张图片".format(20*index))
if __name__ == '__main__':
all_index()
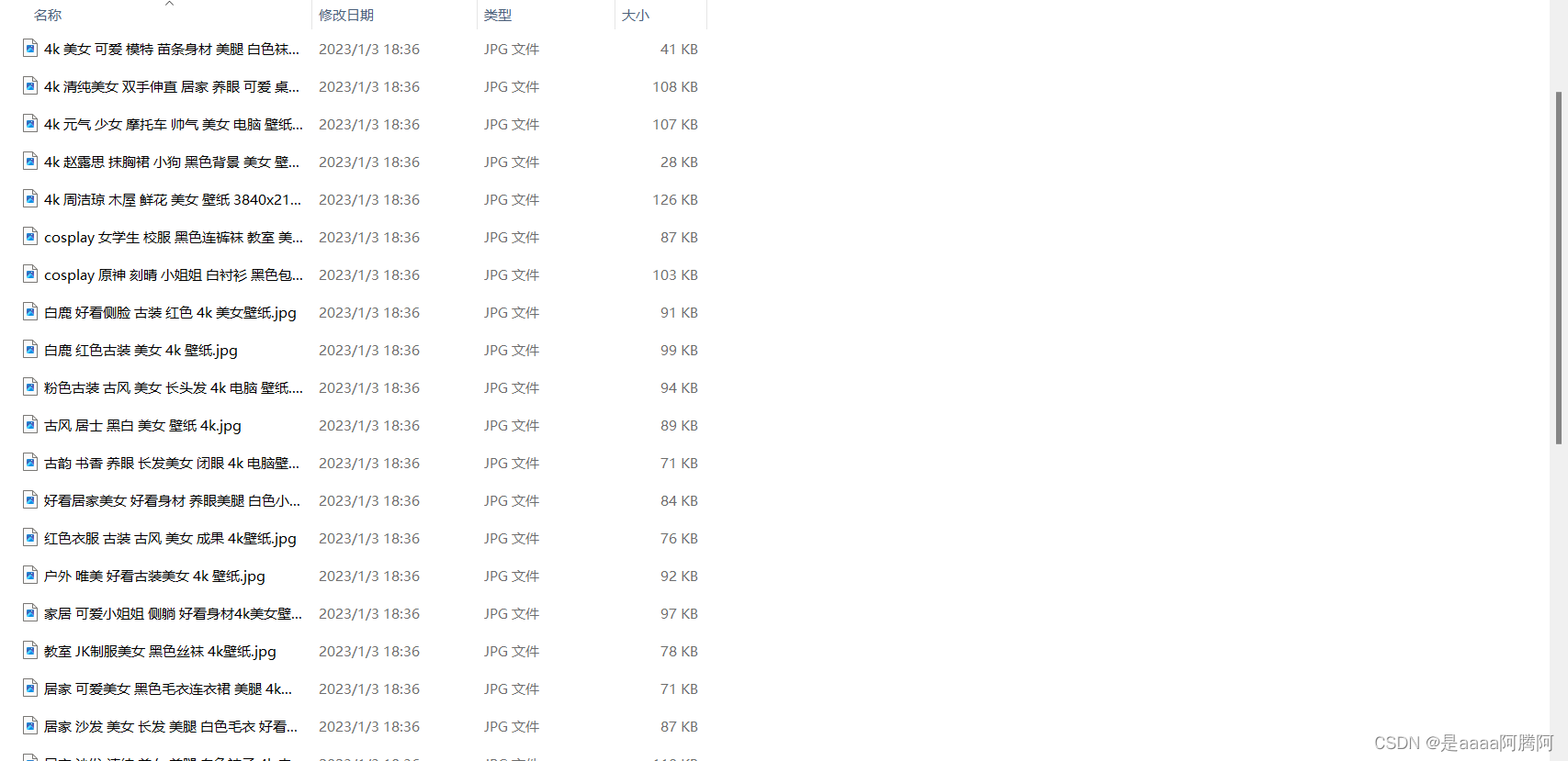
结果展示:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









