







 本文介绍了集成学习中的Gradient Boosting和随机森林,探讨了它们的基本原理和特点。Gradient Boosting通过迭代优化损失函数的梯度来提升模型性能。随机森林则在Bagging基础上引入属性随机选择,增强基学习器的多样性。此外,文章还阐述了集成学习的统计、计算和表现好处,并讨论了结合策略,如平均法和投票法,以及学习法中的Stacking和BMA。最后,指出在实际应用中Stacking通常优于BMA,因为它具有更好的鲁棒性。
本文介绍了集成学习中的Gradient Boosting和随机森林,探讨了它们的基本原理和特点。Gradient Boosting通过迭代优化损失函数的梯度来提升模型性能。随机森林则在Bagging基础上引入属性随机选择,增强基学习器的多样性。此外,文章还阐述了集成学习的统计、计算和表现好处,并讨论了结合策略,如平均法和投票法,以及学习法中的Stacking和BMA。最后,指出在实际应用中Stacking通常优于BMA,因为它具有更好的鲁棒性。
No4.Grandient Boosting
gradient boosting(又叫Mart, Treenet):Boosting是一种思想,Gradient Boosting是一种实现Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。loss function(损失函数)描述的是模型的不靠谱程度,损失函数越大,则说明模型越容易出错(其实这里有一个方差、偏差均衡的问题,但是这里就假设损失函数越大,模型越容易出错)。如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其Gradient(梯度)的方向上下降。
No5.Random Forest(随机森林)
Random Forest是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中悬着一个最优属性;而在RF中,对决策树的每一个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度:若k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,k取值为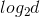
特点:
(1)随机森林简单、容易实现、计算开销小;
(2)随机森林对Bagging只做了小改动,但是于Bagging中基学习器的“多样性”仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间的差异度的增加而进一步提升;
(3)随机森林的收敛性与Bagging相似。不过随机森林的起始性能往往相对较差&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









