







1、基本属性
a、算法名称
英文名:AdaBoost
中文名:
b、属于分类、回归或其它算法中的哪种类别
属于分类算法
c、属于有监督、无监督、半监督的哪种类别
属于有监督
d、对于数据分布是否有要求,如果有,要求是哪种分布?
e、是否属于集成学习方法,如果是,基学习器是否可以并行运行
属于集成学习方法;不可以并行运行,只可以串行运行
f、适应于哪种类型的数据集(如 数值型、标称型)?
g、是否可以处理数据集有缺失值的情况?
h、是否可以处理数据集有异常值的情况?
i、对异常值是否敏感?
j、数据抽样方式(如自助采样(有放回采样)、无放回采样等)
k、是否会改变训练集的样本分布?
会
2、什么是 AdaBoost 算法
AdaBoost 算法是针对同一训练集训练出不同的弱分类器,然后通过集成的方法,得到一个最终的强分类器。
3、工作原理
先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,
然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值 T ,最终将这 T 个基学习器进行加权结合
4、算法伪代码 (非 latent 版)
输入:训练集 D = {(x1, y1), (x2, yx), ... , (xm, ym)};
注:xm 是个向量
基学习算法 a
训练轮数 T
过程:
1: D1(x) = 1 / m
2:f or t = 1, 2, ... , T do
3: ht = a(D, Dt) ; 注:Dt 是样本分布
4: et = Px ~ Dt(ht(x) ≠ f(x));
5: if et > 0.5 then break
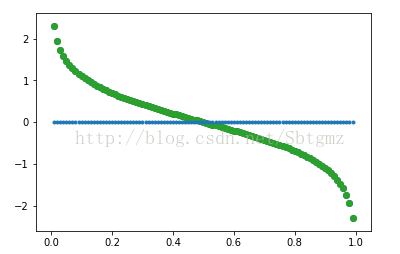
6: αt = 1/2 ln((1 - et) / et);
7:
步骤 6 的图像















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









