







决策树
决策树概述

如上图所示,该图就是一个决策树。长方形代表判断模块(decision block),椭圆形代表终止模块(terminating block),表示已经得出结论,可以终止运行。
从判断模块引出的左右箭头称作分支(branch),它可以到达另一个判断模块或者终止模块。
以作者本人的想法来看:决策树就是一系列的选择,即决策,每次进行决策后进行后续的决策。
决策树的构造
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据类型:数值型和标称型。
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集。这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则当前无需阅读的垃圾邮件已经正确地划分数据分类,无需进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。如何划分数据子集的算法和划分原始数据集的方法相同,直到所有具有相同类型的数据均在一个数据子集内。
决策树的一般流程:

信息增益
概念:在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以
计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测哪种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德·香农。
克劳德·香农被公认为是二十世纪最聪明的人之一,威廉·庞德斯通在其2005年出版的《财富公式》一书中是这样描写克劳德·香农的:“贝尔实验室和MIT有很多人将香农和爱因斯坦相提并论,而其他人则认为这种对比是不公平的——对香农是不公平的。”
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事
务可能划分在多个分类之中,则符号xi的信息定义为
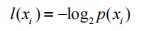
其中p(xi)是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
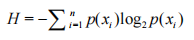
其中n是分类的数目。
那么如何计算给定的数据集的香农熵呢?
给定一个数据集dataSet,其中的数据由下图得到:

那么就可以得到一个简易的数据集了。
然后将数据集用下面这段代码实现:
from math import log
def calcShannonEnt(dataSet):
# 返回数据集的行数
numEntries = len(dataSet)
# 保存每个标签(Label)出现次数的字典
labelCounts = {
}
# 对每组特征向量进行统计
for featVec in dataSet:
# 提取标签(Label)信息
currentLabel = featVec[-1]
# 如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
# Label计数
labelCounts[currentLabel] += 1
# 香农熵
shannonEnt = 0.0
# 计算香农熵
for key in labelCounts:
# 选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntries
# 利用公式计算香农熵
shannonEnt -= prob * log(prob, 2)
# 返回香农熵
return shannonEnt
def createDataSet():
# 数据集
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
# 分类属性
labels = ['no surfacing', 'flippers']
# 返回数据集和分类属性
return dataSet, labels
if __name__ == '__main__':
dataSet, labels = createDataSet()
print(dataSet)
print(calcShannonEnt(dataSet))
首先,计算数据集中实例的总数。我们也可以在需要时再计算这个值,但是由于代码中多次用到这个值,为了提高代码效率,我们显式地声明一个变量保存实例总数。然后,创建一个数据字典,它的键值是最后一列的数值 。如果当前键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。最后,使用所有类标签的发生频率计算类别出现的概率。我们将用这个概率计算香农熵 ,统计所有类标签发生的次数。
运行结果:

最后一行即为该数据集的信息熵。
熵越高,则混合的数据也越多,我们可以在数据集中添加更多的分类,观察熵是如何变化的。添加第三个名为maybe的分类,测试熵的变化:
if __name__ == '__main__':
dataSet, labels = createDataSet()
dataSet[0][-1] = 'leiwenhui'
print(dataSet)
print(calcShannonEnt(dataSet))
运行结果:

如上图所示,将dataSet数据集中添加一个分类leiwenhui,会导致最后的信息熵增大。
得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集。
划分数据集
分类算法除了需要测量信息熵,还需要划分数据集,度量划分数据集的熵,以便判断当前是否正确地划分了数据集。对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。
给定特征划分:
def splitDataSet(dataSet, axis, value):
# 创建返回的数据集列表
retDataSet = []
# 遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
# 去掉axis特征
reducedFeatVec = featVec[:axis]
# 将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
# 返回划分后的数据集
return retDataSet
def createDataSet():
# 数据集
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
# 分类属性
labels = ['no surfacing', 'flippers']
# 返回数据集和分类属性
return dataSet, labels
if __name__ == '__main__':
dataSet, labels = createDataSet()
print(dataSet)
print(splitDataSet(dataSet, 0, 1))
print(splitDataSet(dataSet, 0, 0))
选择最好的数据集划分方式:
from math import log
def calcShannonEnt(dataSet):
# 返回数据集的行数
numEntries = len(dataSet)
# 保存每个标签(Label)出现次数的字典
labelCounts = {
}
# 对每组特征向量进行统计
for featVec in dataSet:
# 提取标签(Label)信息
currentLabel = featVec[-1]
# 如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
# Label计数
labelCounts[currentLabel] += 1
# 香农熵
shannonEnt = 0.0
# 计算香农熵
for key in labelCounts:
# 选择该标签(Label)的概率
prob = float(labelCounts[key])/numEntries
# 利用公式计算香农熵
shannonEnt -= prob * log(prob, 2)
# 返回香农熵
return shannonEnt
def splitDataSet(dataSet, axis, value):
# 创建返回的数据集列表
retDataSet = []
# 遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
# 去掉axis特征
reducedFeatVec = featVec[:axis]
# 将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
# 返回划分后的数据集
return retDataSet
def chooseBestFeatureToSplit(dataSet):
# 特征数量
numFeatures = len(dataSet[0]) - 1
# 计算数据集的香农熵
baseEntropy = calcShannonEnt(dataSet)
# 信息增益
bestInfoGain = 0.0
# 最优特征的索引值
bestFeature = -1
# 遍历所有特征
for i in range(numFeatures):
# 获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
# 创建set集合{},元素不可重复
uniqueVals = set(featList)
# 经验条件熵
newEntropy = 0.0
# 计算信息增益
for value in uniqueVals:
# subDataSet划分后的子集
subDataSet = splitDataSet(dataSet, i, value)
# 计算子集的概率
prob = len(subDataSet) / float(len(dataSet))
# 根据公式计算经验条件熵
newEntropy += prob * calcShannonEnt(subDataSet)
# 信息增益
infoGain = baseEntropy - newEntropy
# 打印每个特征的信息增益
print("第%d个特征的增益为%.3f" % (i, infoGain))
# 计算信息增益
if (infoGain > bestInfoGain):
# 更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
# 记录信息增益最大的特征的索引值
bestFeature = i
# 返回信息增益最大的特征的索引值
return bestFeature
def createDataSet():
# 数据集
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
# 分类属性
labels = ['no surfacing', 'flippers']
# 返回数据集和分类属性
return dataSet, labels
if __name__ == '__main__':
dataSet, labels = createDataSet()
print(dataSet)
print(chooseBestFeatureToSplit(dataSet))
运行结果:

可以发现第一个特征的信息增益最大,也就是第一个特征是最好的用于划分数据集的特征。
递归构建决策树
目前我们已经学习了从数据集构造决策树算法所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据将被向下传递到树分支的下一个节点,在这个节点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。
import operator
from math import log
def calcShannonEnt(dataSet):
# 返回数据集的行数
numEntries = len(dataSet)
# 保存每个标签(Label)出现次数的字典
labelCounts = {
}
# 对每组特征向量进行统计
for featVec in dataSet:
# 提取标签(Label)信息
currentLabel = featVec[-1]
# 如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









