







Logistic回归
1.Logistic回归概述
假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归。利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示要找到最佳拟合参数集。
训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法。
1.1Logistic回归的一般过程:

2.基于 Logistic 回归和 Sigmoid 函数的分类
2.1 Sigmoid函数
对于给定的一些数据集,我们想要得到一个函数,它能够接受所有的输入然后预测出类别。例如在两个类的情况下,函数输出0或1,该函数称为海维塞德阶跃函数(Heaviside step function),或者直接称为单位阶跃函数。但是海维塞德阶跃函数的问题在于:该函数在跳跃点上从0瞬间跳跃到1,这个瞬间跳跃过程有时很难处理。不过另外一个函数也有类似的性质,而且数学上更容易处理,它就是Sigmoid函数,具体公式如下:
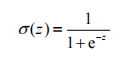
如下面两张图所示,这是Sigmoid函数在不同坐标尺度下的两条曲线图。当x为0时,Sigmoid函数值为0.5。
随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标
刻度足够大(图5-1下图),Sigmoid函数看起来很像一个阶跃函数。

为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
3. 基于最优化方法的最佳回归系数确定
Sigmoid函数的输入记为z,由下面公式得出:
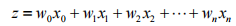
如果采用向量的写法,上述公式可以写成
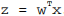
它表示将这两个数值向量对应元素相乘然后全部加起来即得到z值。其中的向量x是分类器的输入数据,向量w也就是我们要找到的最佳参数(系数),从而使得分类器尽可能地精确。为了寻找该最佳参数,需要用到最优化理论的一些知识。
3.1 梯度上升法
梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇,则函数f(x,y)的梯度由下式表示:
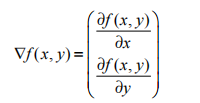
这个梯度意味着要沿x的方向移动 ,沿y的方向移动
,沿y的方向移动 。其中,函数f (x,y)必须要在待计算的点上有定义并且可微。
。其中,函数f (x,y)必须要在待计算的点上有定义并且可微。
一个具体的函数例子见图:

梯度上升算法到达每个点后都会重新估计移动的方向。从P0开始,计算完该点的梯度,函数就根据梯度移动到下一点P1。在P1点,梯度再次被重新计算,并沿新的梯度方向移动到P2。如此循环迭代,直到满足停止条件。迭代的过程中,梯度算子总是保证我们能选取到最佳的移动方向。
可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量来表示的话,梯度上升算法的迭代公式如下:
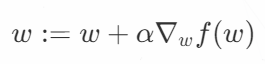
该公式将一直被迭代执行,直到达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
这里顺便提一嘴梯度下降算法,它与这里的梯度上升算法是一样的,只是公式中的加法需要变成减法。因此,对应的公式可以写成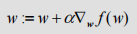 ,梯度上升算法用来求函数的最大值,而梯度下降算法用来求函数的最小值。
,梯度上升算法用来求函数的最大值,而梯度下降算法用来求函数的最小值。
4. 代码实现
4.1 数据集可视化
这里有一个数据集testSet.txt,样本总数为100个,每个点包含对应横纵坐标和类别标签,如图:

代码:
import numpy as np
import matplotlib.pyplot as plt
'''
函数说明:读取数据集
Returns:
dataMat:包含了数据特征值的矩阵
dataLabel:数据集的标签
'''
def loadDataSet():
dataMat = []
labelMat = []
fr = open('D:\迅雷下载\machinelearninginaction\Ch05\\testSet.txt')
for line in fr.readlines():
# strip()方法不传参时表示移除字符串首尾空格
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
fr.close()
return dataMat, labelMat
"""
函数说明:绘制数据集
Parameters:
无
Returns:
无
"""
def plotDataSet():
dataMat, labelMat = loadDataSet()
# 转换成numpy的array数组
dataArr = np.array(dataMat)
n = np.shape(dataMat)[0]
# 正样本
xcord1 = [];
ycord1 = []
# 负样本
xcord2 = [];
ycord2 = []
# 根据数据集标签进行分类
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]);
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1]);
ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5)
ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5)
plt.title('DataSet')
plt.xlabel('x');
plt.ylabel('y')
plt.show()
if __name__ == '__main__':
plotDataSet()
运行结果:

从上图可以看出我们采用的数据的分布情况。
4.2 使用梯度上升找到最佳参数
添加Sigmoid函数和Logistic回归梯度上升算法代码:
import numpy as np
import matplotlib.pyplot as plt
'''
函数说明:读取数据集
Returns:
dataMat:包含了数据特征值的矩阵
dataLabel:数据集的标签
'''
def loadDataSet():
dataMat = []
labelMat = []
fr = open('D:\迅雷下载\machinelearninginaction\Ch05\\testSet.txt')
for line in fr.readlines():
# strip()方法不传参时表示移除字符串首尾空格
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
fr.close()
return dataMat, labelMat
"""
函数说明:绘制数据集
Parameters:
无
Returns:
无
"""
def plotDataSet():
dataMat, labelMat = loadDataSet()
# 转换成numpy的array数组
dataArr = np.array(dataMat)
n = np.shape(dataMat)[0]
# 正样本
xcord1 = [];
ycord1 = []
# 负样本
xcord2 = [];
ycord2 = []
# 根据数据集标签进行分类
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]);
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1]);
ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5)
ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5)
plt.title('DataSet')
plt.xlabel('x');
plt.ylabel('y')
plt.show(< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









