







朴素贝叶斯
1.朴素贝叶斯概述
贝叶斯分类算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Naïve Bayes,NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。
那么,什么是贝叶斯算法呢?这里我将会进行详细的解释。
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
那么在掌握朴素贝叶斯算法之前,我们必须了解条件概率和全概率。
1.1 条件概率
假设现在有一个装了7块石头的罐子,其中3块是灰色的,4块是黑色的。如果从罐子中随机取出一块石头,那么是灰色石头的可能性是多少?由于取石头有7种可能,其中3种为灰色,所以取出灰色石头的概率为3/7。那么取到黑色石头的概率又是多少呢?很显然,是4/7。我们使用P(gray)来表示取到灰色石头的概率,其概率值可以通过灰色石头数目除以总的石头数目来得到。
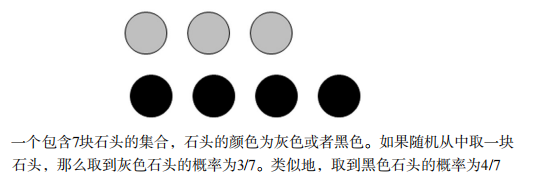
如果这7块石头如图所示放在两个桶中,那么上述概率应该如何计算?

要计算P(gray)或者P(black),事先得知道石头所在桶的信息会不会改变结果?你有可能已经想到计算从B桶中取到灰色石头的概率的办法,这就是所谓的条件概率(conditional probability)。假定计算的是从B桶取到灰色石头的概率,这个概率可以记作P(gray|bucketB),我们称之为“在已知石头出自B桶的条件下,取出灰色石头的概率”。不难得到,P(gray|bucketA)值为2/4,P(gray|bucketB) 的值为1/3。 条件概率的计算公式如下所示:
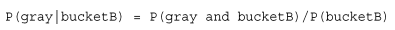
另一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中
的条件与结果,即如果已知P(x|c),要求P(c|x),那么可以使用下面的计算方法:
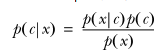
1.2 全概率公式
指若事件{A1,A2,…,An}构成一个完备事件组且都有正概率,则对任意一个事件B都有:

则有: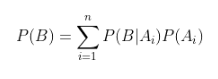
1.3 贝叶斯推论
结合条件概率可推导出如下公式:
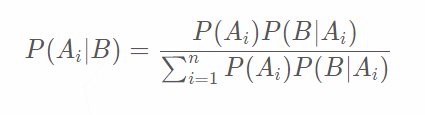
即为贝叶斯公式。把P(A)称为先验概率(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为后验概率(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为可能性函数(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以条件概率可以理解为:后验概率 = 先验概率 × 调整因子
- 如果"可能性函数">1,意味着先验概率被增强,事件A的发生的可能性变大;
- 如果"可能性函数"=1,意味着B事件无助于判断事件A的可能性;
- 如果"可能性函数"<1,意味着"先验概率"被削弱,事件A的可能性变小。
2.朴素贝叶斯分类器应用
下面举一个用西瓜数据集训练一个朴素贝叶斯分类器,对如下测试例进行分类。


可以由以下公式求出:
P(好瓜)=8/17=0.471,P(坏瓜)=9/17=0.529
P(色=青|好)=3/8=0.375,P(色=青|坏)=3/9=0.333
P(根=卷|好)=5/8=0.625,P(根=卷|坏)=3/9=0.333
P(敲=浊|好)=6/8=0.75,P(敲=浊|坏)=4/9=0.444
P(纹=清|好)=7/8=0.875,P(纹=清|坏)=2/9=0.222
P(脐=凹|好)=5/8=0.625,P(脐=凹|坏)=2/9=0.222
P(触=硬|好)=6/8=0.75,P(触=硬|坏)=6/9=0.667
P(密度=0.697|好瓜)=1.959,P(密度=0.697|坏瓜)=1.203
P(糖度=0.46|好瓜)=0.788,P(糖度=0.46|坏瓜)=0.066
P1(好瓜|色=青,根=卷,敲=浊,纹=清,脐=凹,触=硬,密度=0.697,糖度=0.46)=6.3X10^-2
P2(坏瓜|色=青,根=卷,敲=浊,纹=清,脐=凹,触=硬,密度=0.697,糖度=0.46)=6.8X10^-5
P1>P2,所以最终结果为好瓜
3.使用朴素贝叶斯过滤垃圾邮件
基本流程:

数据集中有两个文件夹ham和spam,spam文件下的txt文件为垃圾邮件。
3.1 准备数据:切分文本
代码:
# -*- coding: UTF-8 -*-
import re
# 函数说明:接收一个大字符串并将其解析为字符串列表
def textParse(bigString): # 将字符串转换为字符列表
listOfTokens = re.split(r'\W', bigString) # 将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] # 除了单个字母,例如大写的I,其它单词变成小写
# 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
def createVocabList(dataSet):
vocabSet = set([]) # 创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) # 取并集
return list(vocabSet)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









