




 该博客通过MySQL分析京东用户行为,包括每日/每小时的uv和pv、用户画像、AARRR模型。发现uv低谷可能因节日或技术问题,男性用户活跃,年龄段5和6占比高。跳失率高,用户转化漏斗显示激活和购买环节是主要流失点,复购率低。建议优化商品推荐和用户激活策略,提升用户忠诚度。
该博客通过MySQL分析京东用户行为,包括每日/每小时的uv和pv、用户画像、AARRR模型。发现uv低谷可能因节日或技术问题,男性用户活跃,年龄段5和6占比高。跳失率高,用户转化漏斗显示激活和购买环节是主要流失点,复购率低。建议优化商品推荐和用户激活策略,提升用户忠诚度。
目录
数据文件链接:https://pan.baidu.com/s/12h0nckIE6qLMBy-ywzqf8w
提取码:i1q2
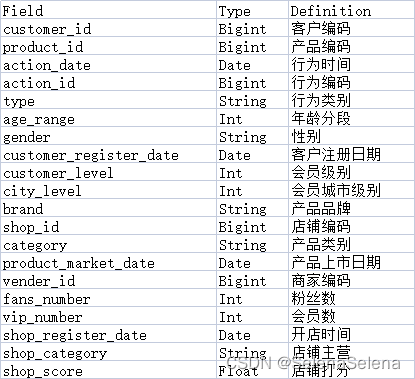
1.字段说明
数据共183828条数据,数据字段20个。
2.数据清理-excel
查看是否有缺失值
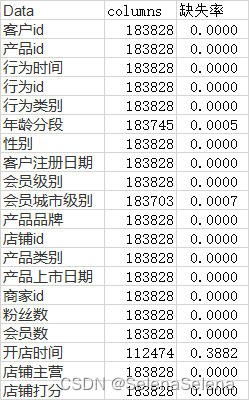
存在缺失值的有年龄分段、会员城市级别和开店时间,其中年龄分段和会员城市级别的缺失率很小,可以删除缺失值。而开店时间缺失率占比达到了0.3882,暂时保留数据,需要相关分析时再去除。
删除重复值
并未发现重复值,故无需处理。
异常值处理
对数据进行描述性分析,结果如下:
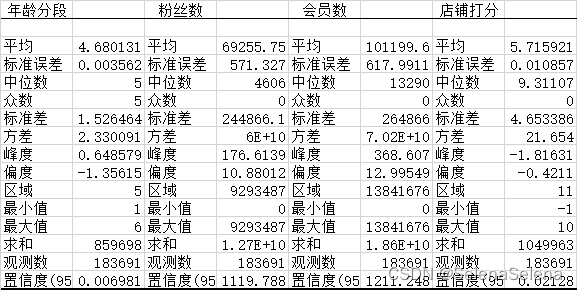
店铺打分最小值为-1,考虑到可能是差评,店铺打分一般是0-10,认定0分以及是差评了,负数总共有1524条,不是很多,故可以负数改为0。
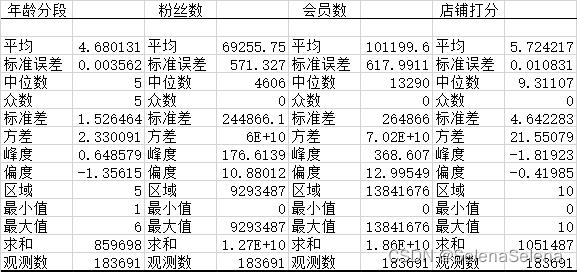
行为时间提取年份、月份、日、周、小时列,其中星期一到星期日为1-7。
将处理好的数据导入mysql。
二、用户分析
1.计算uv(访客数)和pv(访问量)
a 计算每日uv(访客数)和pv(访问量)
select 日期,count(distinct 客户编码) 日uv
from `京东消费者行为分析数据`
group by 日期 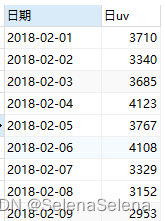
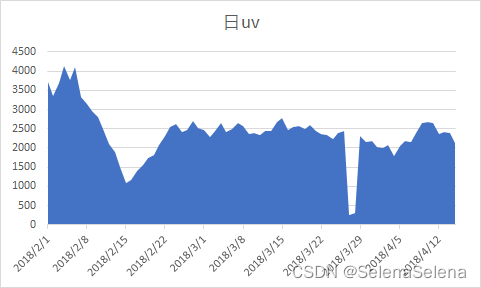
二月上旬属于平台高峰期,且在15号达到了最低谷,大概率是因为2月14号为情人节,二月上旬在搞情人节活动,很多情侣购买礼品的原因。
3月27号和28号两日的uv出现了异常,出现断崖式低峰,而在3月29日又恢复了正常,需要重点查明uv低下的原因,暂时分析可能的原因是数据出错或者这两日平台的技术出现了问题,导致用户无法登录。
其他日期的数据变化相对比较平稳,属于正常趋势。
select 日期,count(客户编码) 日pv
from `京东消费者行为分析数据`
group by 日期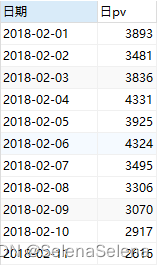
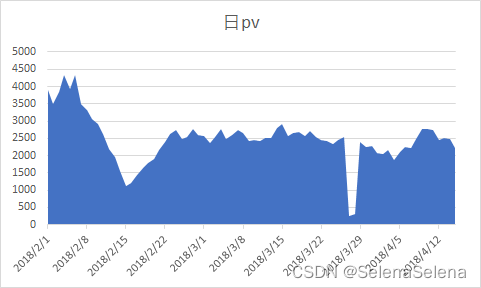
日pv跟日uv变化趋势一致,就不一 一叙述了。
b 计算每小时uv(访客数)和pv(访问量)
select 小时,count(distinct 客户编码) 日uv
from `京东消费者行为分析数据`
group by 小时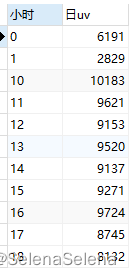
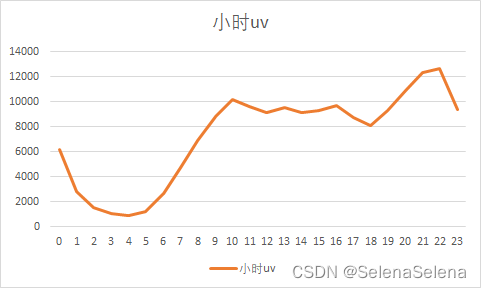
每小时uv低谷出现在1-6点,该时间段为休息时间,所以是正常的。高峰出现在21-22点,比其他时间高不了多少,建议在19-23点这个时间段为主要推送活动等信息的时间段,这段时间相当于高峰期,但9-18点应该适当推送。
select 小时,count(客户编码) 小时pv
from `京东消费者行为分析数据`
group by 小时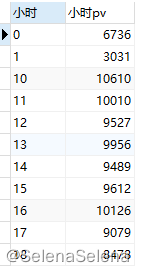
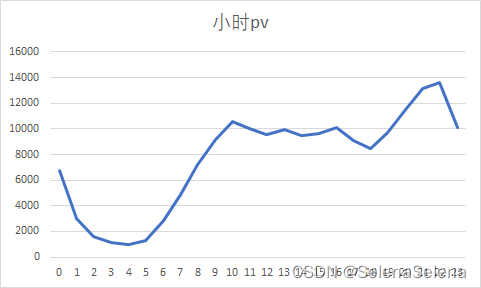
跟每小时uv趋势一样,就不多分析了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7782
7782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









