






该系列又已经好久没有更新了....
之前有一篇文章介绍了可转债收益安全垫的计算方法,写的比较详细,还没看过的朋友可以先去看一下(传送门:可转债干货分享,包含收益安全垫计算方法)
计算方法虽然大家都清楚,计算一只或者两只可转债也还比较轻松,但是如果计算十几只、二十几只可转债就会特别麻烦,会浪费我们很多宝贵的时间,那么本期内容就来给大家分享下自动计算安全垫的python代码(该项目的代码需要经常更新优化,特别是对于可转债预测价格的计算,会直接影响到安全垫的大小,所以需要大家自己跟踪优化)。
如果大家觉得文章还不错,请不要吝啬你的点赞~
前四期内容传送门:
第一期:可转债代码交流第一期:利用Python获取宁稳网数据
(包含基本的环境搭建与Python编辑器安装方法)
第二期:可转债代码交流第二期:利用Python获取集思录数据
(包含基本的模拟登录方法)
第三期:可转债代码交流第三期:利用Python获取集思录可转债单独页面数据(包含页面跳转方法)
第四期:可转债代码交流第四期:利用Python获取理杏仁数据
本人并非计算机专业出身,所有python知识均为自学,所写代码如有不规范的地方,还望指正。
废话不多说,直接上代码!
第一步:导入库(导入各个模块,为了让代码成功运行)
ps:所有的库安装好之后先导入下试试,测试下是否安装成功
import selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
import time
from threading import Thread,Lock第二步:将获取数据的代码分别整理成不同的函数
1.获取未发布可转债的所属行业信息,并整理成Thelogin9()函数
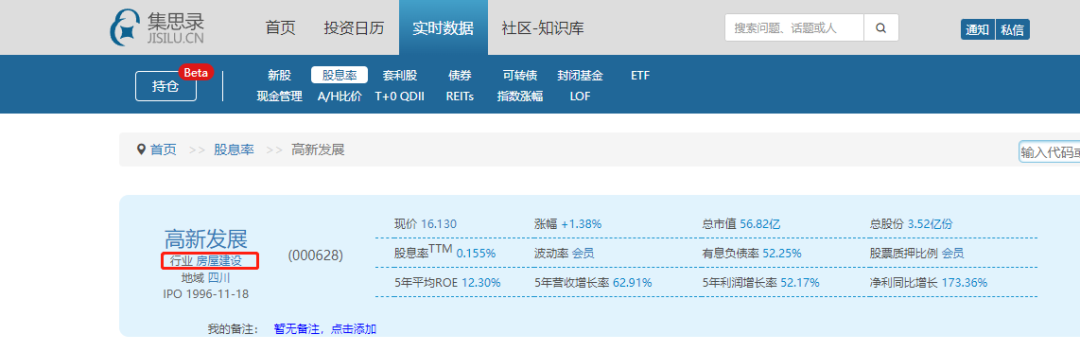
爬虫的代码之前有写过,获取的方法类似,只需要改变其中的元素即可。需要注意的是,考虑到不同平台对所属行业的划分有所区别,下面有对部分行业的名称进行重命名,方便后续数据处理。后续如果代码有报错,大概率就是新出现的公司中,存在行业不匹配的情况,需要在此将原本的行业名称进行重命名。
def Thelogin9():#集思录获取未发布可转债公告的可转债信息
chrome_options = Options()
url =f'https://www.jisilu.cn/web/data/cb/pre'
# 增加无头(不打开浏览器)
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 防止被网站识别(伪装)
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
#打开网页不加载图片
prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
chrome_options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(chrome_options = chrome_options)
browser.get(url)#打开网址
browser.maximize_window()#窗口最大化
browser.implicitly_wait(5)
time.sleep(1)#等待
list_name = []
list_industry = []
list_industry1 = []
#选择证监会核准的可转债
buttons1 = browser.find_elements_by_xpath('//span[@class="el-radio-button__inner"][1]')
button1 = buttons1[1]
button2 = buttons1[2]
time.sleep(0.5)#等待
browser.execute_script("arguments[0].click();", button1)
#获取可转债的链接信息
buttons2 = browser.find_elements_by_xpath('//*[contains(@href,"stock")]')
buttons2 = buttons2[2:]
for i in range(1,len(buttons2)+1,2):
for handle in browser.window_handles:
browser.switch_to.window(handle)
list_name.append(buttons2[i].text)#储存公司名称
browser.execute_script("arguments[0].click();", buttons2[i])
browser.implicitly_wait(5)
time.sleep(0.5)#等待
#定位到最新跳转出来的页面
for handle in browser.window_handles:
browser.switch_to.window(handle)
#开始获取行业信息
buttons3 = browser.find_elements_by_xpath('//td/div[@title][1]')
button3 = buttons3[0]
x1 = button3.get_attribute("title")
x= x1.split("-")[0] #部分名称需要改变,就在此进行重命名!!!
if x == "医药生物":
x = "医药"
elif x == "基础化工":
x = "化工"
elif x == "电力设备" or x == "公用事业":
x = "能源电力"
elif x == "纺织服饰":
x = "服装纺织"
elif x == "建筑装饰":
x = "建筑"
elif x == "机械设备":
x = "机械装备"
elif x == "国防军工":
x = "航空航天"
elif x == "计算机":
x = "计算机及"
elif x == "环保":
x = "城市公用"
elif x == "银行":
x = "金融"
elif x == "轻工制造":
x = "其他"
elif x == "家用电器":
x = "家电"
elif x == "建筑材料":
x = "建筑"
elif x == "美容护理":
x = "化工"
elif x == "农林牧渔":
x = "农业"
elif x == "传媒":
x = "传媒娱乐"
elif x == "商贸零售":
x = "商业零售"
elif x == "通信":
x = "通信互联"
elif x == "社会服务":
x = "其他"
list_industry.append(x)#储存公司行业信息
y= x1.split("-")[1]
if y[-1] == "Ⅱ" :
y = y.strip("Ⅱ") #去除行业名称中的符号
list_industry1.append(y)#储存公司子行业信息
time.sleep(0.5)
browser.close()#关闭当前网页
for handle in browser.window_handles:
browser.switch_to.window(handle)
#将获取到的数据整理,并存储到dict1中
dict1 = {}
dict1["正股名称"] = list_name
dict1["所属行业大类"] = list_industry
dict1["所属行业二类"] = list_industry1
list_columns2 = ["正股名称","所属行业大类","所属行业二类"]
df_data10 = pd.DataFrame(dict1,columns = list_columns2)
for handle in browser.window_handles:
browser.switch_to.window(handle)
print("未发布可转债的行业信息已获取完毕!")
time.sleep(2)#等待
browser.close()#关闭当前网页
browser.quit()#完全退出浏览器
return df_data102.未上市可转债预估公式优化,整理成optimize()函数
之前有分享过获取信息并计算未上市可转债预估价格的文章,但是直接获取到的数据并不能直接计算,得到的结果会有一些误差,需要对不同行业的计算公式进行优化。本来想优化这里的代码,用一个通用的公式进行计算,但是一直没有时间去做.....
这部分代码会比较关键,直接影响到预估价格的高低,也就会影响到安全垫的大小,后续大家需要优化的话,就在这里进行修改。下面已经对部分行业进行了优化计算(仍需要跟踪优化),大家可以自行更改,如果需要增加其他行业的优化,模仿下面的语句就可以了。
def optimize(df_data):#未上市可转债预估公式优化
#list_values0 = []
list_values1 = []
list_values2 = []
list_values3 = []
list_values4 = []
list_values5 = []
list_values6 = []
list_values7 = []
list_values8 = []
list_values9 = []
list_values10 = []
list_values11 = []
list_values12 = []
list_values13 = []
list_values14 = []
list_values15 = []
list_values16 = []
list_values17 = []
list_values18 = []
list_values19 = []
list_values20 = []
list_values21 = []
list_values22 = []
list_values23 = []
list_values24 = []
list_values25 = []
#预估价格小于110的提高价格
for i in range(df_data.shape[0]):
if df_data.at[i,"上市价格预估2"] < 110:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]+5
if df_data.at[i,"上市价格预估1"] < 110:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]+8
#获取转债规模大于等于4.1亿的行号,价格高于130打96折
list_values1 = list(df_data.loc[df_data["转债规模"]>4.1,].index.values)
for i in list_values1:
if df_data.at[i,"上市价格预估2"] > 130:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.96
if df_data.at[i,"上市价格预估1"] > 130:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.96
#获取转债规模大于等于22亿的行号,价格高于135打97折
list_values1 = list(df_data.loc[df_data["转债规模"]>22,].index.values)
for i in list_values1:
if df_data.at[i,"上市价格预估2"] > 115:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.97
if df_data.at[i,"上市价格预估1"] > 115:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.97
#获取转债规模大于等于40亿的行号,价格高于135打97折
list_values1 = list(df_data.loc[df_data["转债规模"]>40,].index.values)
for i in list_values1:
if df_data.at[i,"上市价格预估2"] > 120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.97
if df_data.at[i,"上市价格预估1"] > 120:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.97
#获取转债规模小于3.6亿的行号
list_values2 = list(df_data.loc[df_data["转债规模"]<3.6,].index.values)
for i in list_values2:
if df_data.at[i,"上市价格预估2"] < 133:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.03
if df_data.at[i,"上市价格预估1"] < 130:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.03
#获取金融类(银行)的转债,价格打85折
list_values3 = list(df_data.loc[df_data["所属行业大类"]=="金融",].index.values)
for i in list_values3:
if df_data.at[i,"上市价格预估2"] > 120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.85
if df_data.at[i,"上市价格预估1"] > 120:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.85
#获取化工和航空航天的转债,价格乘以1.08
list_values4 = list(df_data.loc[df_data["所属行业大类"]=="航空航天",].index.values)
for i in list_values4:
if df_data.at[i,"上市价格预估2"] < 125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.08
if df_data.at[i,"上市价格预估1"] < 125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.08
list_values5 = list(df_data.loc[df_data["所属行业大类"]=="化工",].index.values)
for i in list_values5:
if df_data.at[i,"上市价格预估2"] < 108:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.08
elif df_data.at[i,"上市价格预估2"] > 122:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.93
if df_data.at[i,"转债规模"] >= 30:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.94
if df_data.at[i,"上市价格预估1"] < 110:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.08
elif df_data.at[i,"上市价格预估1"] > 125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.93
if df_data.at[i,"转债规模"] >= 30:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.94
#获取医药行业的转债,价格打9折
list_values6 = list(df_data.loc[df_data["所属行业大类"]=="医药",].index.values)
for i in list_values6:
if df_data.at[i,"上市价格预估2"] >130:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.88
if df_data.at[i,"转债规模"] <= 3.4:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.07
if df_data.at[i,"上市价格预估1"] >130:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.83
if df_data.at[i,"转债规模"] <= 3.4:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.07
#获取计算机及应用行业的转债,价格打9折
list_values7 = list(df_data.loc[df_data["所属行业大类"]=="计算机及应用",].index.values)
for i in list_values7:
if df_data.at[i,"上市价格预估2"] <131:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.02
if df_data.at[i,"转债规模"] <2.9:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.05
if df_data.at[i,"上市价格预估1"] <131:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.02
if df_data.at[i,"转债规模"] <2.9:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.05
#获取能源电力行业的转债,价格乘以1.05
list_values8 = list(df_data.loc[df_data["所属行业大类"]=="能源电力",].index.values)
for i in list_values8:
if df_data.at[i,"上市价格预估2"] <115:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.08
if df_data.at[i,"转债规模"] <3.6:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.05
if df_data.at[i,"上市价格预估1"] <115:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.08
if df_data.at[i,"转债规模"] <3.6:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估2"]*1.05
#获取交通运输行业的转债,价格乘以1.05
list_values9 = list(df_data.loc[df_data["所属行业大类"]=="交通运输",].index.values)
for i in list_values9:
if (df_data.at[i,"上市价格预估2"] <125) & (df_data.at[i,"转债规模"] <= 10):
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.05
else:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"上市价格预估1"] <125 & (df_data.at[i,"转债规模"] <= 10):
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.05
else:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
#获取机械装备制造行业的转债,价格乘以0.95
list_values10 = list(df_data.loc[df_data["所属行业大类"]=="机械装备制造",].index.values)
for i in list_values10:
if df_data.at[i,"上市价格预估2"] >133:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"转债规模"] >= 30:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.97
if df_data.at[i,"上市价格预估1"] >133:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
if df_data.at[i,"转债规模"] >= 30:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.97
#获取城市公用设施行业的转债,价格打95折
list_values11 = list(df_data.loc[df_data["所属行业大类"]=="城市公用设施",].index.values)
for i in list_values11:
if df_data.at[i,"上市价格预估2"] >125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"上市价格预估1"] >125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
#获取服装纺织行业的转债,价格打9折
list_values12 = list(df_data.loc[df_data["所属行业大类"]=="服装纺织",].index.values)
for i in list_values12:
if df_data.at[i,"上市价格预估2"] >135:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.86
if df_data.at[i,"上市价格预估1"] >135:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.75
#获取家电行业的转债,价格打95折
list_values13 = list(df_data.loc[df_data["所属行业大类"]=="家电",].index.values)
for i in list_values13:
if df_data.at[i,"上市价格预估2"] >120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.03
if df_data.at[i,"上市价格预估1"] >120:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.03
#获取电子行业的转债,价格打93折
list_values14 = list(df_data.loc[df_data["所属行业大类"]=="电子",].index.values)
for i in list_values14:
if df_data.at[i,"上市价格预估2"] >130:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"上市价格预估1"] >130:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
#获取通信互联网行业的转债,价格打75折
list_values15 = list(df_data.loc[df_data["所属行业大类"]=="通信互联网",].index.values)
for i in list_values15:
if df_data.at[i,"上市价格预估2"] >120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.75
if df_data.at[i,"上市价格预估1"] >120:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.75
#获取其他行业的转债,价格打75折
list_values16 = list(df_data.loc[df_data["所属行业大类"]=="其他",].index.values)
for i in list_values16:
if df_data.at[i,"上市价格预估2"] >122:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.82
if df_data.at[i,"上市价格预估1"] >122:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.82
#获取机械装备行业的转债,价格乘以0.95
list_values17 = list(df_data.loc[df_data["所属行业大类"]=="机械装备",].index.values)
for i in list_values17:
if df_data.at[i,"上市价格预估2"] >133:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"上市价格预估1"] >133:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
#获取汽车行业的转债,价格乘以1.04
list_values18 = list(df_data.loc[df_data["所属行业大类"]=="汽车",].index.values)
for i in list_values18:
if df_data.at[i,"上市价格预估2"] <125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.04
if df_data.at[i,"上市价格预估1"] <125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.04
#获取造纸包装印刷行业的转债,价格乘以1.04
list_values19 = list(df_data.loc[df_data["所属行业大类"]=="造纸包装印刷",].index.values)
for i in list_values19:
if df_data.at[i,"上市价格预估2"] <125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.08
if df_data.at[i,"上市价格预估1"] <125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.08
#获取有色金属行业的转债,价格乘以1.05
list_values20 = list(df_data.loc[df_data["所属行业大类"]=="有色金属",].index.values)
for i in list_values20:
if df_data.at[i,"上市价格预估2"] <120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.05
if df_data.at[i,"上市价格预估1"] <130:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.03
#获取农业行业的转债,价格乘以1.08
list_values21 = list(df_data.loc[df_data["所属行业大类"]=="农业",].index.values)
for i in list_values21:
if df_data.at[i,"上市价格预估2"] <120:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1
if df_data.at[i,"上市价格预估1"] <120:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1
#获取建筑行业的转债,价格乘以0.96
list_values22 = list(df_data.loc[df_data["所属行业大类"]=="建筑",].index.values)
for i in list_values22:
if df_data.at[i,"上市价格预估2"] >125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.96
if df_data.at[i,"上市价格预估1"] >125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.96
#获取食品饮料行业的转债,价格乘以0.91
list_values23 = list(df_data.loc[df_data["所属行业大类"]=="食品饮料",].index.values)
for i in list_values23:
if df_data.at[i,"上市价格预估2"] >125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.91
if df_data.at[i,"上市价格预估1"] >125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.91
#获取钢铁行业的转债,价格乘以0.95
list_values24 = list(df_data.loc[df_data["所属行业大类"]=="钢铁",].index.values)
for i in list_values24:
if df_data.at[i,"上市价格预估2"] >125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.95
if df_data.at[i,"上市价格预估1"] >125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.95
#获取商业零售行业的转债
list_values25 = list(df_data.loc[df_data["所属行业大类"]=="商业零售",].index.values)
for i in list_values25:
if df_data.at[i,"上市价格预估2"] >125:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*0.99
if df_data.at[i,"上市价格预估1"] >125:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*0.75
#获取转债规模小于4亿的行号,
list_values1 = list(df_data.loc[df_data["转债规模"]<4,].index.values)
for i in list_values1:
if df_data.at[i,"上市价格预估2"] < 145:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.03
if df_data.at[i,"上市价格预估1"] < 145:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.03
#获取转债规模小于4亿的行号,
list_values1 = list(df_data.loc[df_data["转债规模"]<3,].index.values)
for i in list_values1:
if df_data.at[i,"上市价格预估2"] < 145:
df_data.at[i,"上市价格预估2"] = df_data.at[i,"上市价格预估2"]*1.03
if df_data.at[i,"上市价格预估1"] < 145:
df_data.at[i,"上市价格预估1"] = df_data.at[i,"上市价格预估1"]*1.03
#print(df_data)
return df_data3.未上市可转债价格计算,整理成Thelogin1()函数
之前有分享过,不过多累赘了,如有问题,可参考可转债代码交流第一期文章
#预测未上市可转债价格
def Thelogin1():
wait_time = 180
chrome_options = Options()
url =f'https://www.ninwin.cn/index.php?m=cb&show_cb_only=Y&show_listed_only=Y'
# 增加无头(不打开浏览器)
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 防止被网站识别(伪装)
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
browser = webdriver.Chrome(chrome_options = chrome_options)
browser.get(url)#打开网址
#browser.maximize_window()#窗口最大化
browser.implicitly_wait(5)
time.sleep(2)
#获取所有可转债的溢价率
buttons = browser.find_elements_by_xpath('//td[@class="cb_premium_id"]')
list_premiumrate = []
for i in buttons:
list_premiumrate.append(i.text)
time.sleep(1)
#获取转债所属行业大类
buttonss1 = browser.find_elements_by_xpath('//td[@class="bond_code_id industry"][1]')
#print(buttonss1)
list_industry1 = []
for i in buttonss1:
text = i.get_attribute("innerText")#如果获取的内容在网页上没有显示,那就是隐藏内容,无法通过.text来转换
list_industry1.append(text)#需要通过.get_attribute("innerText")来获取
time.sleep(1)
#获取转债所属行业二类
buttonss2 = browser.find_elements_by_xpath('//td[@class="bond_code_id industry"][2]')
list_industry2 = []
for i in buttonss2:
text = i.get_attribute("innerText")
list_industry2.append(text)
time.sleep(1)
#获取申购页面网址并打开
button1 = browser.find_element_by_xpath('//a[@href="index.php?m=cb&a=cb_subs"]')
link_url2 = button1.get_attribute('href')#获取节点下的新网址
#print(link_url2)
browser.get(link_url2)#打开新网址
browser.implicitly_wait(5)
#获取申购下的全部信息
buttons2 = browser.find_elements_by_xpath('//td[@class="cb_name_id"]')
list_name = []
for i in buttons2:
list_name.append(i.text)
buttons3 = browser.find_elements_by_xpath('//td[@class="bond_date_id"]//span')
list_state = []
for i in buttons3:
list_state.append(i.text)
buttons4 = browser.find_elements_by_xpath('//td[@class="bond_rating_id rating"]')
list_rating = []
for i in buttons4:
list_rating.append(i.text)
buttons5 = browser.find_elements_by_xpath('//td[@class="stock_price_id"][1]')
list_size = []
for i in buttons5:
list_size.append(i.text)
buttons6 = browser.find_elements_by_xpath('//td[@class="cb_value_id"]')
list_2 = []
for i in buttons6:
list_2.append(i.text)
#获取申购下的行业信息
list_industry = []
list_industry11 = []
list_company = []
buttons2 = browser.find_elements_by_xpath("//td[@class='stock_name_id stock_name']")
for i in buttons2:
list_company.append(i.text)
information = i.get_attribute('title').split("—")#获取title标签中的内容
information1 = information[1]
list_industry11.append(information1)
information = information[0].split(":")
information = information[2]
list_industry.append(information)
dictall = {}
dict2 = {}
dictall["转债名称"] = list_name
dictall["正股名称"] = list_company
dictall["转债规模"] = list_size
dictall["转债评级"] = list_rating
dictall["转债上市情况"] = list_state
dictall["转股价值"] = list_2
dictall["所属行业大类"] = list_industry
dictall["所属行业二类"] = list_industry11
dict2["溢价率"] = list_premiumrate
dict2["所属行业大类"] = list_industry1
dict2["所属行业二类"] = list_industry2
list_columns = ["转债名称","正股名称","转债上市情况","转债规模","转债评级","转股价值","所属行业大类","所属行业二类"]
df_data = pd.DataFrame(dictall,columns = list_columns)
df_data['转股价值'] = df_data['转股价值'].astype('float')
df_data['转债规模'] = df_data['转债规模'].astype('float')
list_columns2 = ["所属行业大类","所属行业二类","溢价率"]
df_data2 = pd.DataFrame(dict2,columns = list_columns2)
df_data2['溢价率'] = df_data2['溢价率'].str.strip('%').astype('float')
df_data2['溢价率'] = df_data2['溢价率']/100
#df_data['上市价格预测'] = df_data['溢价率'] * df_data['转股价值'] + df_data['转股价值']
#计算行业大类下的平均溢价率
df_data22 = df_data2.groupby("所属行业大类").mean()
df_data22 = df_data22.reset_index()
df_data22 = df_data22.rename(columns = {"溢价率":"平均数溢价率"})
#计算行业大类下的中位数溢价率
df_data33 = df_data2.groupby("所属行业大类").median()
df_data33 = df_data33.reset_index()
df_data33 = df_data33.rename(columns = {"溢价率":"中位数溢价率"})
#合并表格
df_premiumrate = pd.merge(df_data22,df_data33,on= '所属行业大类', how = 'left')
#平均数溢价率
list_price1 = []
for i in df_data["所属行业大类"]:
i = " "+ i
if len(i) > 4:
i = i[0:5]
premiumrate1 = df_premiumrate[df_premiumrate["所属行业大类"] == i].iat[0,1]
list_price1.append(premiumrate1)
#中位数溢价率
list_price2 = []
for i in df_data["所属行业大类"]:
i = " "+ i
if len(i) > 4:
i = i[0:5]
premiumrate2 = df_premiumrate[df_premiumrate["所属行业大类"] == i].iat[0,2]
list_price2.append(premiumrate2)
df_data["平均数溢价率"] = list_price1
df_data["中位数溢价率"] = list_price2
df_data["上市价格预估1"] = df_data["转股价值"] * df_data["平均数溢价率"] + df_data["转股价值"]
df_data["上市价格预估2"] = df_data["转股价值"] * df_data["中位数溢价率"] + df_data["转股价值"]
#将数据改成百分数显示
df_data["平均数溢价率"] = df_data["平均数溢价率"].map(lambda x: format(x, '.2%'))
df_data["中位数溢价率"] = df_data["中位数溢价率"].map(lambda x: format(x, '.2%'))
#预测价格优化
df_data = optimize(df_data)
df_data = df_data.round(2)
print("未上市可转债价格已预测完毕!")
time.sleep(2)#等待
#browser.close()#关闭浏览器
browser.quit()#完全退出
return df_data,df_premiumrate
4.获取待发可转债的基础信息,整理成Thelogin7()函数
也就是下图中的各项数据
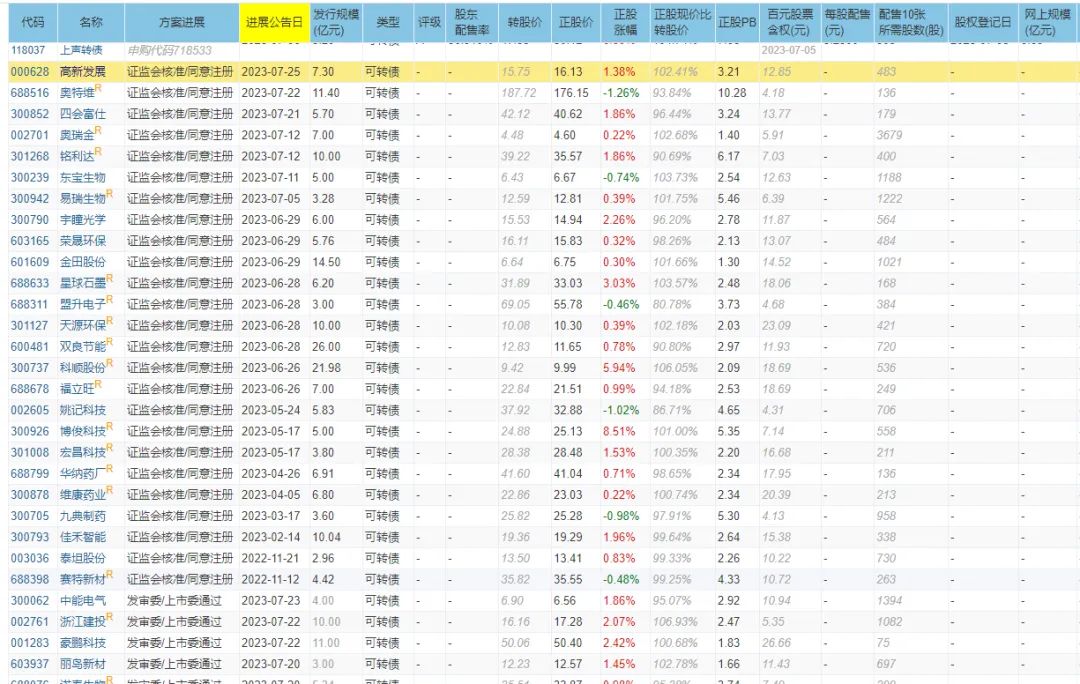
该页面下有需要用到的可转债配售计算数据,本来需要找其他途径进行获取,这里全部都有了,省了不少时间。这里获取数据的页面和上面获取行业信息的页面其实是同一个,为什么没有写在一起,因为我懒.....懒得改了
def Thelogin7():#集思录获取待发可转债的基础信息
chrome_options = Options()
url =f'https://www.jisilu.cn/data/cbnew/#pre'
# 增加无头(不打开浏览器)
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 防止被网站识别(伪装)
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
#打开网页不加载图片
prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
chrome_options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(chrome_options = chrome_options)
browser.get(url)#打开网址
browser.maximize_window()#窗口最大化
browser.implicitly_wait(5)
#browser.delete_all_cookies()#删除原来的cookies
time.sleep(1.5)#等待
list_all = []
list_name = []#可转债名称
list_compay = []#公司名称
list_code = []#公司代码
list_price = []#公司股价
list_progress = []#进展
list_Placement = []#配售比
list_size = []#剩余规模
list_num = []#股数
list_Fprice = []#转股价
#获取所有可转债的公司名称和代码
buttonss2 = browser.find_elements_by_xpath('//a[@target="_stock"]')
for i in buttonss2:
itext = i.text
if itext[-1] == "R":
itext=itext.strip("R")
itext=itext.strip()
list_code.append(itext)
list_compay = list_code[1::2]
list_code1 = list_code[0::2]
#print(list_compay)
print(len(list_compay))
#获取所有可转债的进展
buttonss3 = browser.find_elements_by_xpath('//td[@data-name="progress_nm"]')
for i in buttonss3:
itext = i.text
list_progress.append(itext)
#print(list_progress)
print(len(list_progress))
#获取所有可转债的规模
buttonss4 = browser.find_elements_by_xpath('//td[@data-name="amount"]')
for i in buttonss4:
itext = i.text
list_size.append(itext)
#print(list_size)
print(len(list_size))
#获取所有可转债的转股价
buttonss41 = browser.find_elements_by_xpath('//td[@data-name="convert_price"]')
for i in buttonss41:
itext = i.text
list_Fprice.append(itext)
#print(list_Fprice)
print(len(list_Fprice))
##获取所有可转债发行公司的股价
buttonss41 = browser.find_elements_by_xpath('//td[@data-name="price"]')
for i in buttonss41:
itext = i.text
list_price.append(itext)
#print(list_price)
print(len(list_price))
#获取所有可转债的配售比
buttonss5 = browser.find_elements_by_xpath('//td[@data-name="ration"]')
for i in buttonss5:
itext = i.text
list_Placement.append(itext)
#print(list_Placement)
print(len(list_Placement))
#配售1000元可转债所需股数
buttonss6 = browser.find_elements_by_xpath('//td[@data-name="apply10"]')
for i in buttonss6:
itext = i.text
list_num.append(itext)
#print(list_num)
print(len(list_num))
dict_all = {}
dict_all["正股名称"]=list_compay
dict_all["公司代码"]=list_code1
dict_all["转股价"]=list_Fprice
dict_all["公司股价"]=list_price
dict_all["进展"]=list_progress
dict_all["转债规模"]=list_size
dict_all["配售比"]=list_Placement
dict_all["配售1000元的股数"]=list_num
list_columns = ["正股名称","公司股价","转股价","公司代码","进展","转债规模","配售比","配售1000元的股数"]
df_data = pd.DataFrame(dict_all,columns = list_columns)
#剔除"-"
list_values1 = []
list_values1 = list(df_data.loc[df_data["配售1000元的股数"].str.contains("-"),].index.values)
print(list_values1)
for i in list_values1:
df_data.at[i,"配售1000元的股数"] = 0
df_data['配售1000元的股数'] =df_data['配售1000元的股数'].astype('float')
df_data['公司股价'] =df_data['公司股价'].astype('float')
df_data3 = df_data.copy()
print("申购方案已爬取完毕!")
time.sleep(1)#等待
browser.close()#关闭当前网页
browser.quit()#完全退出浏览器
return df_data35.获取近期热门行业,整理成Thelogin5()函数
涉及到的行业信息还是需要进行优化,之前也有提过,不同平台对不同行业的命名有所区别,需要统一成相同的名称,才能进行比对计算。热点行业的获取代码也还不够完善,仍需要进行优化
def Thelogin5():#获取热点行业
wait_time = 180
chrome_options = Options()
url =f'http://quote.eastmoney.com/center/boardlist.html#industry_board'
# 增加无头(不打开浏览器)
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 防止被网站识别(伪装)
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
#打开网页不加载图片
prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
chrome_options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(chrome_options = chrome_options)
browser.get(url)#打开网址
browser.maximize_window()#窗口最大化
browser.implicitly_wait(5)
list_industry = []#热门行业
#获取热门行业
buttonss1 = browser.find_elements_by_xpath('//*[contains(@href,"unify")] ')
time.sleep(3)#等待
for index,i in enumerate(buttonss1):
if index % 3 == 0:
industry0 = i.text
if industry0[-2:] == "行业":
industry0 = industry0.strip("行业")
if industry0 =="水泥建材":
industry0 = "建筑材料"
elif industry0 =="化学制药"or industry0 =="生物制品"or industry0 =="医药商业"or industry0 =="医疗服务":
industry0 = "医药生物"
elif industry0 =="酿酒":
industry0 = "食品饮料"
elif industry0 =="航运港口"or industry0 =="航空机场"or industry0 =="铁路公路":
industry0 = "交通运输"
elif industry0 =="旅游酒店":
industry0 = "社会服务"
elif industry0 =="电源设备":
industry0 = "电力设备"
elif industry0 =="汽车整车":
industry0 = "汽车"
elif industry0 =="造纸印刷":
industry0 = "造纸"
elif industry0 =="贵金属":
industry0 = "有色金属"
elif industry0 =="航天航空" or industry0 =="船舶制造":
industry0 = "国防军工"
elif industry0 =="石油" or industry0 =="采掘":
industry0 = "石油石化"
elif industry0 =="化肥":
industry0 = "基础化工"
elif industry0 =="交运设备":
industry0 = "机械设备"
elif industry0 =="工程建设":
industry0 = "建筑装饰"
elif industry0 =="农牧饲渔":
industry0 = "农林牧渔"
elif industry0 =="商业百货":
industry0 = "商贸零售"
elif industry0 =="保险":
industry0 = "非银金融"
elif industry0 =="文化传媒":
industry0 = "传媒"
elif industry0 =="纺织服装":
industry0 = "纺织服饰"
elif industry0 =="包装材料":
industry0 = "轻工制造"
elif industry0 =="互联网服务":
industry0 = "计算机"
list_industry.append(industry0)
#print(list_industry)
time.sleep(1)#等待
browser.close()#关闭当前网页
browser.quit()#完全退出浏览器
return list_industry6.重写多线程函数
自带的多线程函数有个弊端,不能获取各个函数返回的结果,所以需要重新编辑,使其能够返回结果
# 定义一个MyThread.py线程类(加入get_result()方法)
class MyThread(Thread):
def __init__(self, func, args=()):
super(MyThread, self).__init__()
self.func = func
self.args = args
def run(self):
time.sleep(2)
self.result = self.func(*self.args)
def get_result(self):
Thread.join(self) # 等待线程执行完毕
try:
return self.result
except Exception:
return None第三步:将上面所有的函数汇总并运行
这里为了提升代码的获取效率,需要用到多线程,即几个获取数据的代码同时运行,大大减少了等待时间。执行完全部代码,大概需要一分钟左右,大家耐心等待。
if __name__ == '__main__':
list_thread = []
dict_thread = {"thread1":Thelogin1,"thread5":Thelogin5,"thread7":Thelogin7,"thread9":Thelogin9}#将线程和对应的函数存入字典
for x,y in dict_thread.items():
x = MyThread(y)#调用线程,并传入相应函数
x.start()#开始线程
list_thread.append(x)
count = 1
for z in list_thread:
z.join()#线程等待,即:所有线程都运行完毕,才会执行之后的代码
if count == 1:
df_data,df_premiumrate= z.get_result()#预测未上市可转债价格
elif count ==2:
list_industry = z.get_result()#获取热点行业
elif count ==3:
df_data3 = z.get_result()#集思录获取待发可转债的基础信息
elif count ==4:
df_data10 = z.get_result()#集思录获取未发布可转债的行业信息
count += 1
print("已成功调用....")第四步:使用数据
1.未上市可转债价格预估表
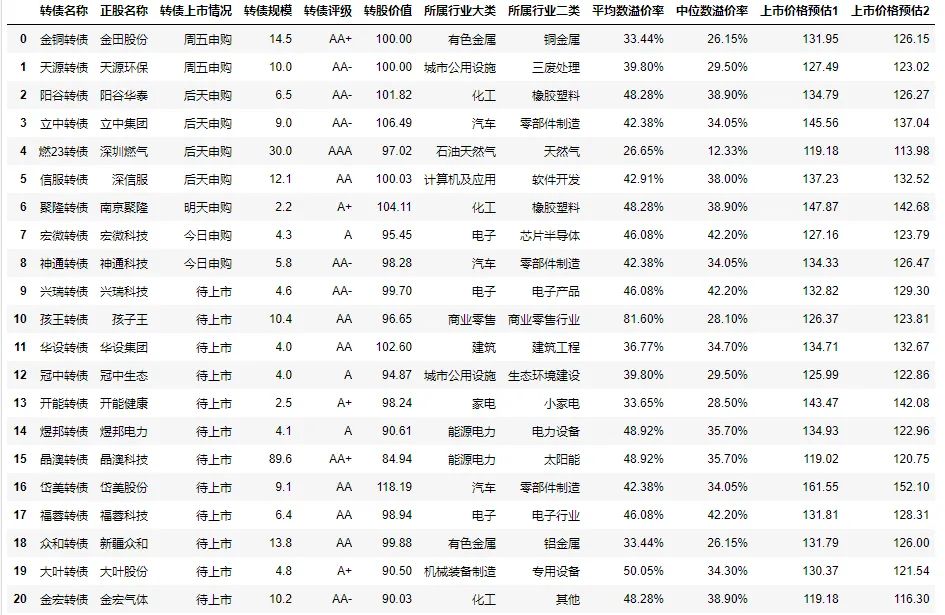
#df_data中就是存储了未上市可转债的预估价格,单独执行可见
df_data2."证监会核准/同意注册"安全垫表
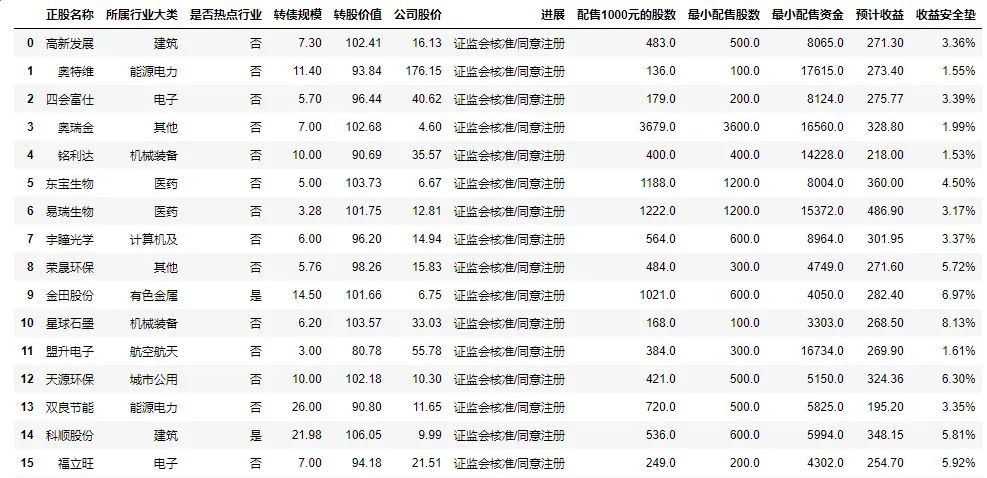
这个表格目前还不能直接得到,需要再编写一点点函数...
def judgee1(df_data) :#取出较小的预估价格
if (df_data["上市价格预估1"] < df_data["上市价格预估2"]) or df_data["上市价格预估2"]<100:
x = df_data["上市价格预估1"]
else:
x = df_data["上市价格预估2"]
return x
def judgee(df_data) :#最优配售股数计算
if df_data["type1"] == 1:
temp=round(df_data['配售1000元的股数']/100/2+0.5)*100
if temp/df_data['配售1000元的股数'] < 0.565:#太接近0.5的配售概率较小,需要再加100股
temp = temp+100
else:
if (df_data['配售1000元的股数']//100*100) / df_data['配售1000元的股数'] >= 0.96:
temp = df_data['配售1000元的股数']//100*100
else:
temp=round(df_data['配售1000元的股数']/100+0.5)*100
return temp
def judgee01(df_data) :#根据股票数量计算配售的可转债张数
if df_data["type1"] != 1:#深市股票
temp = round(df_data["最小配售股数"]/df_data["配售1000元的股数"]*10,2)
test = temp - int(temp)
if test >=0.565:
temp = int(temp)+1
else:
temp = int(temp)
else:#沪市股票
temp = round(df_data["最小配售股数"]/df_data["配售1000元的股数"],2)
if temp <0.565:
temp = 0
else:
if temp <= 1:
temp = 1
else:
test = temp - int(temp)
if test >=0.565:
temp = int(temp)+1
else:
temp = int(temp)
temp = temp*10
return temp
def allotment(df2_data00):
df2_data0001 = df2_data00.loc[:,["公司股价",
"配售1000元的股数",
"转债规模",
"type1",
"最小上市预估价"]]
#df2_data0001
for i in range(6):
df2_data0001 = df2_data0001.append(df2_data0001)
df2_data0001.reset_index(drop=True)
list10 = [0]*len(df2_data0001)
list10[0]=100
for i in range(1,len(df2_data0001)):
list10[i] =list10[i-1] + 100
df2_data0001["股票数量"]=list10
df2_data0001
df2_data0001["买入资金"]=df2_data0001["公司股价"]*df2_data0001["股票数量"]
df2_data0001["获配数量(张)"]=df2_data0001.apply(judgee01,axis = 1)
df2_data0001["需缴纳金额"]=df2_data0001["获配数量(张)"]*100
df2_data0001["预计收益"] = (df2_data0001["最小上市预估价"]-100)*df2_data0001["获配数量(张)"]
df2_data0001["安全垫"] = df2_data0001["预计收益"] / df2_data0001["买入资金"]
df2_data0001["安全垫"]=df2_data0001["安全垫"].map(lambda x: format(x, '.2%'))
return df2_data0001
在进行计算之前,先把热点行业判断一下
df_data10["是否热点1"] = df_data10["所属行业大类"].apply(lambda x:1 if x in list_industry else 0)
df_data10["是否热点2"] = df_data10["所属行业二类"].apply(lambda x:1 if x in list_industry else 0)
df_data10["是否热点"] = df_data10["是否热点1"] + df_data10["是否热点2"]
df_data10["是否热点行业"] = df_data10["是否热点"].apply(lambda x:"是" if x >=1 else "否")到此,准备工作已经做完,接下来就可以进行计算了!
#公司发布可转债审核通过名单
criteria1 = (df_data3['进展'] == "证监会核准/同意注册")
df_temp = df_data3[criteria1].copy()
#获取对应的平均数溢价率
list_price1 = []
for i in df_data10["所属行业大类"]:
i = " "+ i
premiumrate1 = df_premiumrate[df_premiumrate["所属行业大类"] == i].iat[0,1]
list_price1.append(premiumrate1)
#获取对应的中位数溢价率
list_price2 = []
for i in df_data10["所属行业大类"]:
i = " "+ i
premiumrate2 = df_premiumrate[df_premiumrate["所属行业大类"] == i].iat[0,2]
list_price2.append(premiumrate2)
df_data10["平均数溢价率"] = list_price1
df_data10["中位数溢价率"] = list_price2
#合并两个表格
df2_data002 = pd.merge(df_temp,df_data10,on = '正股名称', how = 'left')
#转换数据格式
df2_data002["转股价"]=df2_data002["转股价"].astype('float')
df2_data002["公司股价"]=df2_data002["公司股价"].astype('float')
df2_data002["转债规模"]=df2_data002["转债规模"].astype('float')
#计算转股价值
df2_data002["转股价值"]=round(100/df2_data002["转股价"]*df2_data002["公司股价"],2)
#计算上市预估价格
df2_data002["上市价格预估1"] = df2_data002["转股价值"] * df2_data002["平均数溢价率"] + df2_data002["转股价值"]
df2_data002["上市价格预估2"] = df2_data002["转股价值"] * df2_data002["中位数溢价率"] + df2_data002["转股价值"]
#对价格进行优化
df2_data002 = optimize(df2_data002)
df2_data003 = df2_data002.loc[:,["正股名称",
"所属行业大类",
"公司股价",
"公司代码",
"进展",
"转债规模",
"配售1000元的股数",
"转股价值",
"平均数溢价率",
"中位数溢价率",
"上市价格预估1",
"上市价格预估2",
"是否热点行业"]]
df2_data003 = df2_data003.round(2)
#取出股票代码的前两位
df2_data003["type"] = df2_data003.loc[:,"公司代码"].map(lambda x: x[:2])
#上交所的可转债(股票60或68开头)标记为“1”
df2_data003['type1'] = df2_data003["type"].map(lambda x: 1 if x == "60" or x=="68" else 10)
df2_data003['最小配售股数'] = df2_data003.apply(judgee,axis = 1)
df2_data003["最小配售资金"] = df2_data003["公司股价"]*df2_data003["最小配售股数"]
#取出较小的预估价格
df2_data003["最小上市预估价"] = df2_data003.apply(judgee1,axis = 1)
#计算预计收益(分沪市和深市场)------------
df2_data003["股票数量"]=df2_data003["最小配售股数"]
#取出股票代码的前两位
df2_data003["type"] = df2_data003.loc[:,"公司代码"].map(lambda x: x[:2])
#上交所的可转债(股票60或68开头)标记为“1”
df2_data003['type1'] = df2_data003["type"].map(lambda x: 1 if x == "60" or x=="68" else 10)
df2_data003["获配数量(张)"]=df2_data003.apply(judgee01,axis = 1)
df2_data003["预计收益"] = round((df2_data003["最小上市预估价"] - 100)*df2_data003["获配数量(张)"],2)
df2_data0031 = df2_data003.copy()
#----------------------------------------------
#计算收益安全垫
df2_data003["收益安全垫"] = df2_data003["预计收益"] / df2_data003["最小配售资金"]
#将数据改成百分数显示
df2_data003["收益安全垫"] = df2_data003["收益安全垫"].map(lambda x: format(x, '.2%'))
df2_data003 = df2_data003.loc[:,["正股名称",
"所属行业大类",
"是否热点行业",
"转债规模",
"转股价值",
"公司股价",
"进展",
"配售1000元的股数",
"最小配售股数",
"最小配售资金",
"预计收益",
"收益安全垫"
]]
# df2_data003中就是存储了"证监会核准/同意注册"安全垫表,单独执行可见
df2_data003可能有朋友发现,上面的"证监会核准/同意注册"安全垫表只显示了每个公司可转债的一手(10张)的配售方案,并没有平时分享中单只可转债那么多的配售数据,因为数据太多没有汇总在一起,如果想显示单个的详细配售情况,可运行以下代码:
#计算一个公司的配售策略,因为列名不同,重写了judgee01()函数
def judgee01(df_data) :#根据股票数量计算配售的可转债张数
if df_data["type1"] != 1:#深市股票
temp = round(df_data["股票数量"]/df_data["配售1000元的股数"]*10,2)
test = temp - int(temp)
if test >=0.565:
temp = int(temp)+1
else:
temp = int(temp)
else:#沪市股票
temp = round(df_data["股票数量"]/df_data["配售1000元的股数"],2)
if temp <0.565:
temp = 0
else:
if temp <= 1:
temp = 1
else:
test = temp - int(temp)
if test >=0.565:
temp = int(temp)+1
else:
temp = int(temp)
temp = temp*10
return temp
#---------------------------------------------
#优选公司计算配售方案,只需更改公司名称!!!
#---------------------------------------------
df2_data0032 = df2_data0031[df2_data003["正股名称"]=="盟升电子"].copy()
df2_data0001 = allotment(df2_data0032)
df2_data0001 = df2_data0001.loc[:,["配售1000元的股数",
"转债规模",
"股票数量",
"买入资金",
"获配数量(张)",
"需缴纳金额",
"预计收益",
"安全垫"
]]
df2_data0001.reset_index(drop=True).head(50)能得到以下结果:
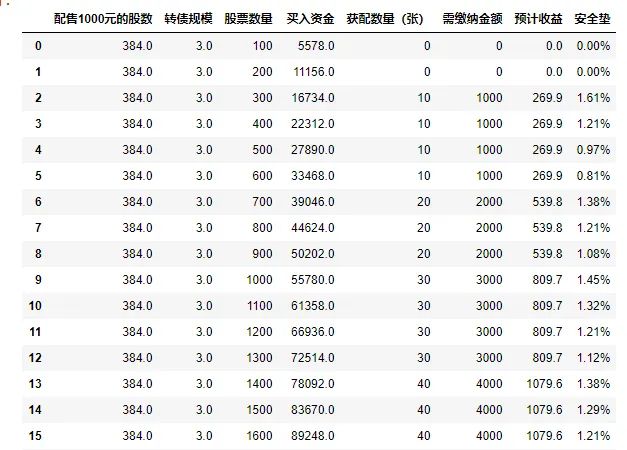
为了方便大家获取,上述所有代码都保存在了txt文件中,如需获取完整代码,请在公众号回复“安全垫计算代码”
本期内容的代码其实还不够稳定,目前还处于跟踪优化阶段,近期询问的朋友比较多,所以先拿出来和大家分享一下,该项目代码后续会继续跟踪优化,一点点完善内容,进一步提升代码的稳定性,提高估值的准确性。
其实完整代码不只是上面的内容,还有很多功能没有加入,比如“发审委/上市委通过”后的数据计算,最新的雷达图绘制等等。如果全部加入的话,本期内容也太长了....现在就已经有将近3万字了(包含代码),后续大家感兴趣的话,再继续更新
您的点赞分享就是我更新的动力















 2645
2645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









